词间相关性的CMRM图像标注方法
2011-08-18刘咏梅代丽洁
刘咏梅,代丽洁
(哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨 150001)
词间相关性的CMRM图像标注方法
刘咏梅,代丽洁
(哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨 150001)
自动图像标注因其对图像理解和网络图像检索的重要意义,近年来已成为新的热点研究课题.在图像标注的CMRM模型基础上,提出了一种基于词间相关性的CMRM标注方法.该方法提取了标注字之间的词间相关关系,并利用图学习算法,通过将词间相关性矩阵叠加到初始标注矩阵的方法对标注结果进行了改善.利用Corel5k标注图像库中的自然场景图像进行实验.实验结果表明,该方法很好地完成了对测试集图像的自动标注,在查全率与查准率上较CMRM模型有所提高.
图像标注;CMRM模型;相关关系;词间相关性矩阵
有效的图像描述方法[1]是图像数据管理的基础.目前图像描述方法主要采用人工标注的方式进行,但是由于人工方式耗时费力而且缺乏客观性,因此需要对图像进行自动标注.
此外,对图像进行自动的语义标注是图像检索中重要且非常具有挑战性的工作[2].对于提高检索系统的效率有着重要的意义.因此如何快速有效地进行自动的图像标注就变得异常重要.
通过对CMRM算法的研究发现,该模型只考虑了视觉特征与标注关键字之间的对应关系,却忽略了关键字本身所具有的相关性,因此,提出了一种基于词间相关性的CMRM图像标注方法.首先利用CMRM模型对图像进行标注,然后从训练集中提出关键字之间的相关关系,并利用图学习算法,将这种相关关系在各个关键字之间进行传播,从而得到新的图像标注关键字.
1 CMRM图像标注方法
联合媒体相关模型(cross-media relevance models,CMRM)将相关语言模型(relevance-based language model)[3-4]应用到图像标注中,通过对训练图像集的学习获取图像的视觉词元与关键字的联合概率分布.利用概率统计方法,获得每个关键字作为图像标注的概率,并以此作为选择标注的依据.该模型在图像标注领域取得了较好的成绩,现在已经成为各种新图像标注方法进行性能对比的标准方法.
在利用CMRM算法对图像进行标注过程中常用的图像描述方法如下:
1)关键字记为wi,i=1,2,…,n.
2)视觉词元记为bi,i=1,2,…,m.并用它对图像进行表示.
3)训练图像记为Ji={b1,b2,…,bm,w1,w2,…,wn},其中i为图像的编号.
4)测试图像记为I={b1,b2,…,bm}.
1.1 CMRM标注的基本原理
CMRM模型采用一种生成式的语言建模方法[4-5],该方法认为每幅图像的视觉特征与标注关键字之间都有一种潜在概率分布P(·|I),并且将这个分布看作是I的相关模型[4-6].可以将图像的视觉词元表示{b1,b2,…,bm}看作是从P(·|I)中进行m次随机采样得到的.同理,很自然地想到对图像I进行标注可以看作是从它的相关模型P(·|I)中随机抽样n次得到了n个关键字.为了能对相关模型进行抽样需要对标注集中每个关键字都估计概率.
由于P(·|I)本身是未知的,因此可以考虑利用条件概率P(w|b1,b2,…,bm)近似P(w|I)[6],即

对于式(1)等号右边的概率,可以首先利用已标注的训练图像集来估计在一幅图像中同时观察到关键字w和视觉词元b1,b2,…,bm的联合分布,然后对该分布按w进行边缘化得到.而联合分布可以利用训练集中的图像J的期望得到

假设某一幅训练图像J被选定后,关键字w和视觉词b1,b2,…,bm是否出现是相互独立的[4-6].因此可以将式(2)重写为
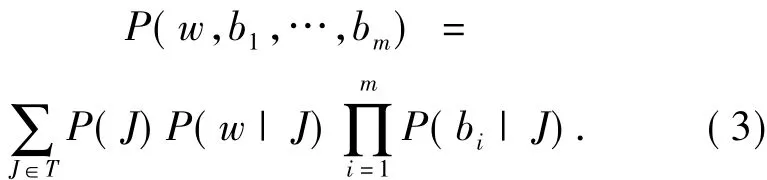
式中:P(J)可以对训练集中的所有图像保持一致.由于J中同时包含了全部视觉词元与关键字,因此可以利用平滑的期望最大化算法对式(3)中的概率进行估计,当给定一幅训练图像J时,可以同时观察到关键字w和视觉词元b的概率由式(4)、(5)给出.

式中:#(w,J)表示w出现在图像J的标注中的次数,因为同一个词很少会多次出现在同一个标题中,所以该值一般取为0或1;#(w,T)表示w出现在训练集T中的总次数,它等于用该关键字标注的训练图像的总数;同理,#(b,J)和#(b,T)也表示相应的次数.利用式(1) ~ (5)[4-7]估计出概率P(w|I)后,就可以直接利用这个概率对图像进行标注.本文中将αJ和βJ这2个参数经评估后分别取为αJ=0.1,βJ=0.9.
1.2 CMRM的图像标注算法
利用联合媒体相关模型对图像进行标注的主要步骤总结如下:
1)从数据集的文件中统计出的基本信息.
#(w,J):每个关键字出现在每幅图像的标注中的次数,一般为0或1.
#(w,T):关键字出现在数据集中的总次数.
#(b,J):视觉词元b出现在每幅图像中的次数.
#(b,T):视觉词元b出现在全部训练图像中的次数.
2)利用统计信息计算关键字和视觉词元的条件概率P(w|J)和P(b|J).
3)利用条件概率对关键字和视觉词元的联合概率进行估计.
4)利用p(w,b1,b2,…,bm)来近似p(w|b1,b2,…,bm).
2 基于词间相关性的CMRM图像标注
CMRM算法是根据图像的底层特征等对图像进行标注的,由于“语义鸿沟”的存在,使得该算法的标注性能受到影响.在利用CMRM对图像进行初始的标注之后,利用图学习方法,将从训练集中得到的词间相关关系矩阵作用到初始标注矩阵上,使得关键字之间的相关性在图的各个顶点之间进行传播,从而实现了对标注结果的改善.
2.1 词间相关性描述
词间相关性是指2个关键字同时标注一幅图像的特性.相关程度用词间相关性矩阵表示.为了获得关键字之间的相关性矩阵,可以对训练集中关键字出现的次数进行统计,文中将2个关键字作为同一幅图像的标注出现的次数称为它们的共生次数.


要准确地获取关键字之间的词间相关性矩阵,需要对训练集数据进行统计和整理,并进行相应的计算.下面将详细说明计算该矩阵的算法.算法的主要步骤如下:
1)读入训练图像集中的标注信息,即训练图像本身自带的标注关键字;
2)从训练集的标注信息中,统计出任意2个关键字的共生次数,即K(w1,w2);
3)统计每个关键字在训练图像集中作为标注出现的次数n1;
4)按照式(6)计算出词间相关性矩阵;
5)对矩阵进行归一化处理.
2.2 相关关系传播算法
本文利用图学习算法来实现词间相关性在各个关键字之间的传播.文献[8]将图学习算法应用于图像标注中,所提出的基于图学习的标注框架首先进行初始标注,即以图像为节点,以图间相似性为边建立图,通过图学习算法将标注信息从已标注图像传递到未标注图像,然后对标注结果进行改善.这时,利用词间相关性建立以词为节点的图,以初始标注结果设置初始状态向量,通过学习算法得到图像的最终标注结果.本文方法借鉴了这一框架.
设G=(V,E)表示图,其中V={x1,x2,…,xn}是图的顶点,对应标注的关键字;E代表图的边,边上的权值对应它所连接的2个关键字之间的相关强度.同时,设CMRM标注结果用矩阵Y表示,它的元素yij表示第i幅图像被标注为第j个关键字的概率.结果矩阵R的元素表示每幅图像被标注为每个关键字的最终概率结果,由下面的迭代过程产生[8]:

式中:t表示迭代次数,其初值为0,R(0)=Yβ是传播系数,它决定了相关矩阵对标注结果的影响程度,本文中t的终值取500,β取0.25.
从上面的描述可以看出,迭代过程中有2个最重要的矩阵,相似矩阵S和初始标注矩阵Y,前者对应着上一节中得到的共生矩阵,而后者由CMRM算法对测试图像进行标注而得到.
2.3 基于词间相关性标注算法
下面给出算法的具体步骤如下.
1)从数据集的文件中读入训练数据信息,进而完成对基本信息#(w,J)、#(w,T)、#(b,J)、#(b,T)的统计,并转2).
2)估计关键字w和视觉词元b的条件概率,并计算关键字与视觉词元之间的联合概率.
3)提取词间相关性矩阵S.
4)将2)中得到标注矩阵与式(7)中的初始状态矩阵Y对应,进行迭代计算,直到收敛,得到的新矩阵就是最终标注结果.
5)对矩阵每行的元素按概率值排序,取概率最大的N个作为最终的标注关键字,在本文方法中N=5.
3 实验结果与分析
3.1 实验数据
本文采用带有标注字的 Corel5k图像集[9]实验.整个图像集中共包含50个文件夹,每个文件夹100张图像,共5 000张图像.从每个文件夹中选取80张图像作为训练图像,再先取10张作为评估图像集,用于对参数进行评估,其余10张图像作为测试图像[4].
对所有图像均先利用NCut算法进行图像分割,取前10个面积较大的区域作为有效区域,进行特征提取.区域的视觉特征为36维特征向量,包括18种颜色特征、12种纹理特征和6种形状特征.对训练图像,利用K-均值聚类算法(K=500)对所有有效区域进行聚类,由聚类结果得到500个视觉词元.
3.2 实验结果
对500幅测试图像进行了自动的标注,计算了每个关键字(标注字)的平均查全率和平均查准率.查全率(recall)度量出对单个词查询的完整性,查准率(precision)反映出查询的精度.对于给定的标注字w,若在测试图像集的手工标注结果中包含w的图像个数为Nm,使用自动标注模型的标注结果中包含该词的图像个数为Na,其中参照手工标注结果有Nr个是正确的,则单个标注字的查全率和查准率为

采用标注字的平均查准率和平均查全率来考察本文方法的标注性能.与CMRM算法相比,部分关键字的查全率与查准率有明显的提高,如图1及图2所示.

图1 本文方法与CMRM模型的部分关键字的查全率对比Fig.1 Recall contrast results of partial words with CMRM model
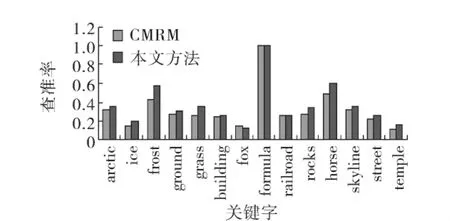
图2 本文方法与CMRM模型的部分关键字的查准率对比Fig.2 Precision contrast results of partial words with CMRM model
对测试图像集中500幅图像的标注结果进行统计,对标注性能最好的前49个标注字的平均查全率为0.375,平均查准率为0.38.本文方法与CMRM模型的标注性能进行了对比,见表1.
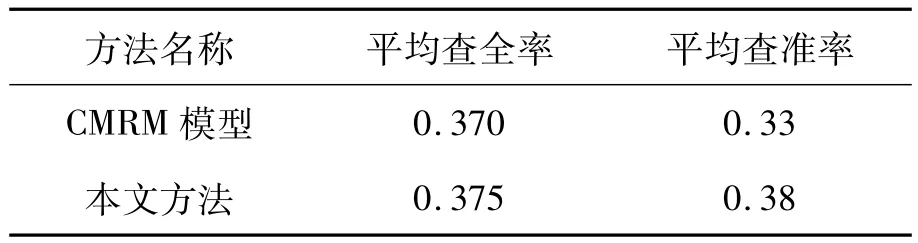
表1 与CMRM模型的性能对比Table 1 Efficiency contrast results with CMRM model
本文方法充分考虑了标注关键字之间的相关性,这种相关性反映了各个关键字之间的语义联系,通过相关性将2个紧密联系的关键字的标注概率进行调整,并对CMRM的标注结果进行调整,使得标注结果在查准率和查全率上较CMRM有所提高.表2给出了部分图像的标注结果.
本方法无论在查全率还是查准率方面,都较CMRM模型有所提高.但是由于图像的视觉词元对最终标注结果的影响是非常大的,不可避免地出现了一些标注效果不理想的情况.标注性能受以下几方面因素影响:1)颜色、形状特征在全部特征中所占的比重,各种特征直接影响聚类的效果;2)对于词间关系的提取不够全面;3)所有图像的标注长度相同,影响了最终的查全率与查准率.

4结论
本文在CMRM模型基础上,利用标注字之间的词间相关性对CMRM标注方法进行了改进,取得了更好的标注效果.下一步的研究工作可以从以下几个方面进行.
1)优化图像的特征提取方法,在不影响算法性能的前提下,尽量全面地采用各种特征,以消除某些特征对聚类的影响.
2)对于共生关系矩阵的提取,可以借助一些结构化的词典来进行,普林斯顿大学开发的WorldNet就是一个不错的选择,该词典收录了大量的单词,且按语义对单词进行组织,能够更加全面地衡量关键字之间的相关性.
3)可以对图像进行长度不固定的标注,例如对图像中每个区域进行单独的标注,然后对于标注相同的区域进行融合,这样可以更好地消除噪声关键字对查全率和查准率的影响.
[1]陈世亮,李战怀,袁柳.一种基于区域特征关联的图像语义标注方法[J].计算机工程与应用,2007,43(2):53-57.
CHEN Shiliang,LI Zhanhuai,YUAN Liu.Image semantic annotating method based on region features relevancy[J].Computer Engineering and Applciations,2007,43(2):53-57.
[2]YU Feiyang,HORACE H S.Semantic content analysis and annotation of histological images[J].Computers in Biology and Medicine,2008,38:635-649.
[3]LAVRENKO V,CROFT W.Relevance-based language models[C]//Proceedings of the 24th Annual International ACM SIGIR Conference.New Orleans,USA,2001:120-127.
[4]LAVRENKO V,CHOQUETTE M,CROFT W.Cross-lingual relevance models[C]//Proceedings of the 25th Annual International ACM SIGIR Conference.Tampere,Finland,2002:175-182.
[5]王斌.图像检索中自动标注与快速相似搜索技术研究[D].长沙:中国科学技术大学,2007:5-45.
WANG Bin.Researches on automatic image annotation and fast similarity searching technology in CBIR[D].Changsha:University of Science and Technology of China,2007:5-45.
[6]袁曾任.人工神经元网络及其应用[M].北京:清华大学出版社,1999:40-50.
[7]JEON J,LAVRENKO V,MANMATHA R.Automatic image annotation and retrieval using cross-media relevance models[C]//Proceedings of the 26th International ACM SIGIR Conference.Toronto,Canada,2003:119-126.
[8]卢汉清,刘静.基于图学习的自动图像标注[J].计算机学报,2008,31(9):1629-1639.
LU Hanqing,LIU Jing.Image annotation based on graph learning[J].Chinese Journal of Computers,2008,31(9):1629-1639.
[9]http://www.cs.arizona.edu/people/kobus/research/data/eccv_2002
[10]纪颖.一种基于实例的图像自动语义标注方法[J].哈尔滨理工大学学报,2009,14(1):38-42.
JI Ying.An instance-based method for automatic image semantics annotation[J].Journal of Harbin University of Science and Technology,2009,14(1):38-42.

刘咏梅,女,1973年生,副教授,硕士生导师,博士.主要研究方向为模式识别、图像理解和生物信息学.

代丽洁,女,1983年生,硕士,主要研究方向为图像处理与模式识别、图像标注.
A method of CMRM image annotation based on inter-word correlation
LIU Yongmei,DAI Lijie
(School of Computer Science and Technology,Harbin Engineering University,Harbin 150001,China)
Automatic image annotation is significant for image understanding and retrieval of web images.As a result,it has become a hot research topic in recent years.On the basis of a CMRM image annotation model,an efficient image annotation method was proposed based on inter-word correlations.The correlations between the annotated words were picked up,and the inter-word correlation matrix was added to the initial labeling matrix by a graph learning algorithm.The proposed annotation approach was tested by a Corel5k database with natural scene images.The experimental result shows that the method can automatically label the images in the test set very well.The recall and precision are increased compared to CMRM.
image annotation;CMRM;correlation;word-correlation matrix
TP391
A
1673-4785(2011)04-0350-05
10.3969/j.issn.1673-4785.2011.04.012
2010-03-15.
中央高校基本科研业务费专项资金资助项目(HEUCF100604).
刘咏梅.E-mail:liuyongmei@hrbeu.edu.cn.
