一种用于军事情报分析系统的数据分类算法
2011-07-16王卓君
王卓君
(解放军国际关系学院,江苏 南京 210039)
自动化情报分析系统就是在情报分析的若干环节应用计算机软件,帮助情报分析人员做出情报研判的自动化系统。其中,分类分析法是计算机辅助情报分析的方法之一。常用的分类分析算法有决策树算法、最近邻算法、Bayes算法和神经网络算法等。决策树算法[1]是一种从训练样本集中推理出判定树表示形式的分类规则的方法。其优点在于直观性和易理解性。该算法不仅能做出分类和预测,而且它的生成过程、分类、预测以及从中所提取的分类规则都具有很强的可理解性。但决策树算法同时也存在着不足。在计算树节点熵属性时,计算量大、复杂度高、训练集过大,从而可能造成计算机内存无法运行。神经网络算法可用于数据挖掘的分类、聚类、特征挖掘、预测和模式识别等方面。其优点包括对噪音数据的高承受能力,以及它对未训练数据的分类能力。神经网络最大的不足是需要较长的训练时间并且可解释性较差。最近邻算法也称KNN(K Nearest Neighbors)算法[2]。该算法的不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。Bayes算法是一类利用概率统计知识进行分类的算法,如NB (Naive Bayes)算法[3]。朴素贝叶斯分类算法是基于一个简单的假定:在给定分类特征条件下,属性值之间是相互条件独立的[4]。其薄弱环节在于实际情况下,类别总体的概率分布和各类样本的概率分布函数常常是未知的。为了获得它们,就要求样本足够大。
其中,决策树算法和神经网络算法以其直观性、易理解性、对噪音数据的高承受能力和对未训练数据的分类能力显著优势被广为应用。本文尝试应用决策树算法中ID3算法[5]和神经网络算法中的Boltzmann机[6]对军事情报系统进行组合建模,并针对Boltzmann机和ID3算法存在的不足,分别对Boltzmann机的Sigmoid函数和ID3算法中的信息熵进行改进,从而改善Boltzmann机在训练过程中易出现网络麻痹与温度训练过拟合等问题,同时降低ID3的计算复杂度,加快了建模的速度。
1 军事情报分析系统的组成和业务处理流程
1.1 系统的组成
军事情报分析系统以情报数据分类算法(IDC Information Data Classifying Agorithm)为核心,主要包括情报数据预处理模块、IDC数据分类模块、规则库模块。其中,IDC情报数据分类模块是其核心模块。
1.2 系统的业务处理流程
军事情报分析系统采用双层分类算法对情报数据进行分析处理。系统的业务处理流程简述如下。流程图如图1所示。
2 算法原理与改进
2.1 Boltzmann机算法原理与改进
作为第一层数据快速计算层中的核心算法,依据情报数据自身的特点,这里选择Boltzmann机是较为合适的,Boltzmann行动选择策略适于求解非精确状态信息下的顺序决策过程问题的行动选择策略。具体算法原理如图2所示:
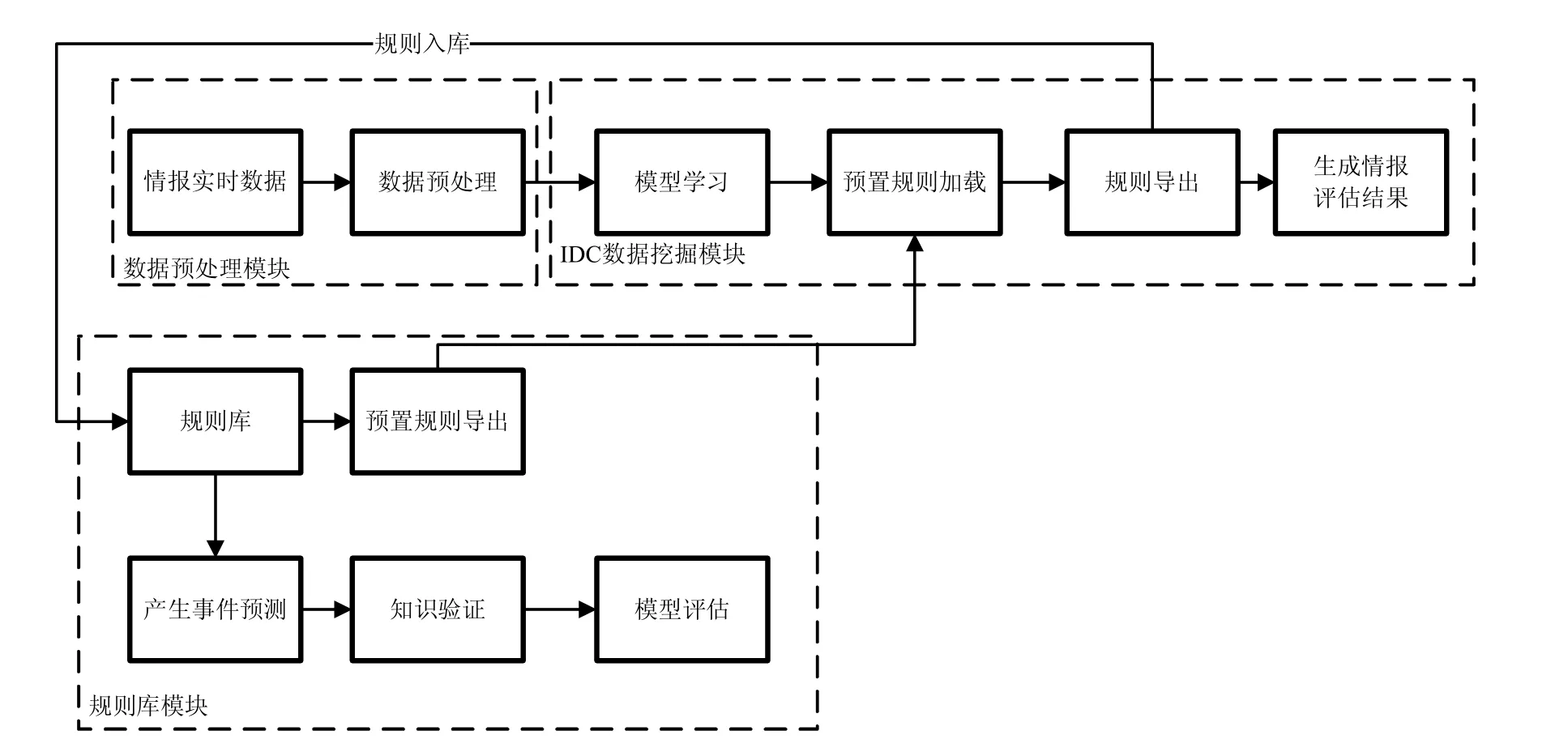
图1 情报处理系统基本业务流程图
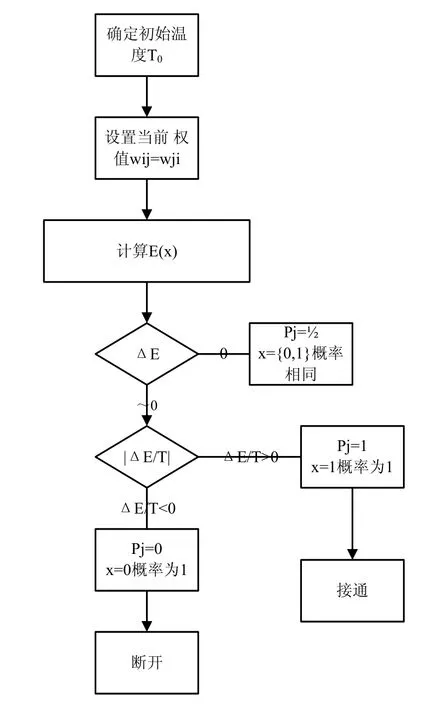
图2 Boltzmann机算法原理图
虽然 Boltzmann机能够用来求解组合优化等问题,但仍存在训练时间长和对统计错误敏感的问题。在实际应用中,收敛速度和推广能力会受到影响。对网络模型改进的主要目标有两个:一是防止网络训练过程中麻痹现象的出现,提高网络的训练速度;二是提高网络的泛化能力,避免过拟合现象。
由于 Boltzmann机是基于梯度下降法进行训练的,所以网络的激活函数要求连续可微。参数导数的存在性对学习至关重要,因此Boltzmann机网络一般不采用阈值函数和符号函数作为 sigmoid激活函数。Boltzmann机的激活函数一般要求非线性,否则多层网络将不提供高于两层网络之上的任何计算能力。有界性也是激活函数的一个条件,这可以限定权值和单元输出的上下边界,使训练次数也有限。如果输出是代表一个概率时,有界性尤其重要。单调性也是激活函数的一个期望的性质,因为如果激活函数在定义域中不是单调的,存在一个或多个极值,则会延长训练时间并对错误敏感。
当 sigmoid函数的输出接近饱和值时,其梯度很小,相应的权值调节量也很小,学习速度很慢,这就是麻痹现象产生的原因。一旦产生网络麻痹,则会不断地对采集过程中产生的演习过程数据中的某些属性值进行退火降温,从而拉长数据学习时间,降低整个数据分类效率。为了防止产生这种现象,本文提出了对 sigmoid函数的输出进行限制的方法,限制其最大输出值小于饱和值,改进sigmoid函数为
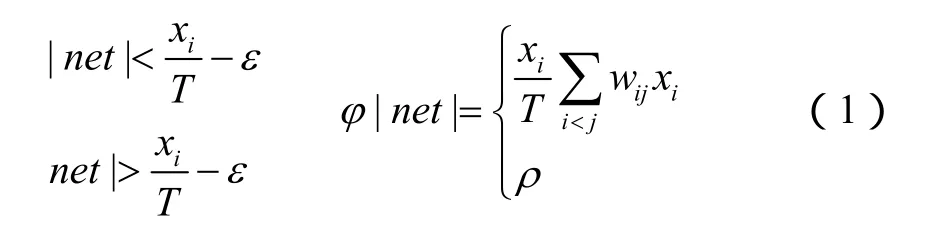
2.2 ID3算法原理与改进
ID3基本原理是基于二叉分类问题,但很容易将其扩展到多叉分类上。假设训练集中有m个样本,样本分别属于c个不同的类,每个类的预设训练实例集为X,学习的目的是将训练实例分为n类,记为C={X1,X2…Xn}。设第i类的训练实例个数是|Xi|=Ci,X中总的训练实例个数为|X|,记一个实例属于第i类的概率为P(Xi),则有

此时决策树对划分C的不确定程度为I(X,C),简记为I(X):
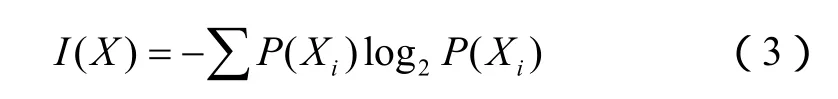
对熵压缩的度量过程就是缩小对数据划分不确定程度的过程。若选择属性A进行测试,设属性A具有性质a1,a2,a3,…at,在A=aj的情况下属于第i类的实例个数为,即为测试属性。A的取值为aj时,它属于第i类的概率。记为A= aj时的实例集。此时决策树对分类的不确定程度就是训练实例集对属性A的条件熵:
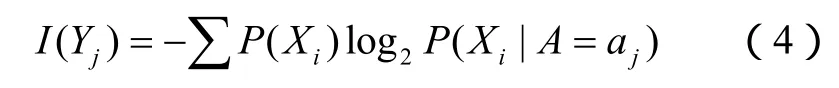
叶结点Xj对于分类信息的信息熵为
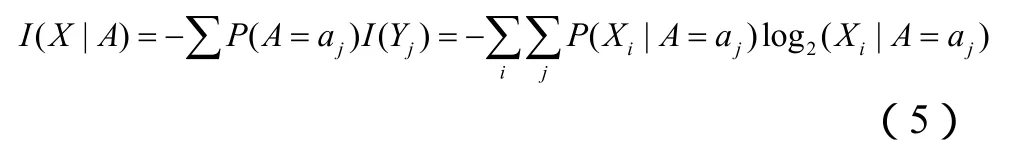
即属性A的熵压缩为

其中,I( X|A)越小, G ain( A)的值越大。说明选择测试属性A对于分类提供的信息越大,选择A之后对分类的不确定程度越小。该算法是把信息熵作为选择测试属性的标准,即树结点的选择策略。但在计算基于属性的信息熵时,公式比较复杂,计算量较大,相应的复杂度也高,当数据量很大时很耗费硬件资源,计算花费的时间也长。
改进后的ID3算法结合洛伦茨曲线思想,设属性划分绝对平等曲线和实际属性划分曲线之间的面积为A,实际属性划分曲线右下方的面积为B,并以A除以A+B的商表示不平等程度。如果A为零,系数为零,表示属性划分完全平等;如果B为零,则系数为1,属性划分绝对不平等。曲线的弧度越大,那么系数也越大。具体曲线关系如图3所示。
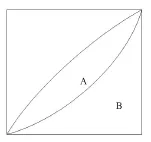
图3 绝对平等曲线与实际属性划分曲线图
此算法区别于传统决策树计算期望信息的方法,以往在计算不同类的信息概率后,首先将计算后的所有值进行相减,得出分类期望信息随后,再分别计算对类中不同的属性的熵,对这些熵进行相加,得出子集的熵最后,在将期望信息与子集的熵相减得出这个分支上的编码信息:
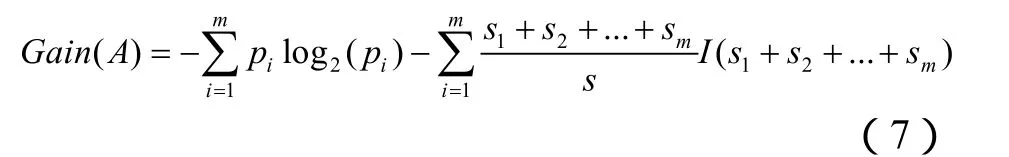
这样的计算步骤繁杂,在计算机语言中难以表达,因此,本文提出了一种反向熵压缩度量法。该算法对的定义进行了改进,缩小了分析的粒度,立足点设立在每个集合中的属性分布情况,从而降低了测试复杂度,减少了计算时间。下面对反向熵度量做出介绍。
在反向熵度量法中,I ( s1+ s2+ . ..+ sm)是一个计算根节点分裂的关键要素,是类中每个属性的信息值。当对根节点进行分裂时,直接计算数据集合中每个类中不同属性的熵值,根据每个类中属性值总和的大小对整个数据集进行分裂。熵值越小,子集划分纯度越高。

其中,Pi是属性i在属性集中出现的相对频率。
如果类I按照某个划分点分成I1和I2,则划分后的属性信息和为
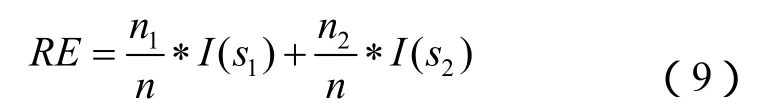
2.3 情报数据分类算法
情报数据分类算法(IDC Information Data Classifying Agorithm)由两层组合而成:第一层是基于改进后的Boltzmann机的快速计算层;第二层是基于改进后的ID3算法的精确分析层。当经过预处理的情报数据进入IDC计算第一层后,对实战过程情报数据、参战单位编成情报数据、装备相关情报数据、地理位置情报数据进行加权计算,权值是由输入和输出的相关性决定。相关性越大,则它们的相关权越大。然后采用Boltzmann机算法进行粗粒度地快速分类处理,得出分类结果。当数据粗分类结果进入第二层时,数据开始重新根据属性集中各个属性出现的相对频率进行决策树节点分裂计算,选择属性出现频率最大的作为决策树节点分裂值。对进入第二层的情报数据属性集进行反复计算,形成决策树,得出当前作战的决策和规则。IDC算法流程如图4所示。

图4 IDC算法原理示意图
3 实例分析与验证
3.1 系统实例分析
3.1.1数据预处理
在数据挖掘的前期数据准备阶段,需要对等待挖掘的原始数据进行数据清洗、数据变换、数据维归约等操作,将之转化为高质量的训练样本数据。以作战过程中的陆战编成数据中的部分属性为例:
采集数据以数组的形式接收进来,其中D1为编成序号,D2为单位序号,D3为X轴坐标值上的参战部队坐标值,D4为Y轴上的参战部队坐标值。
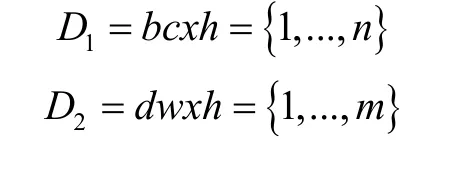
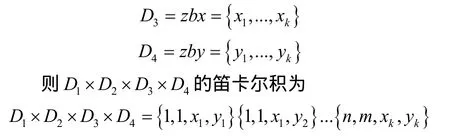
为了使网络达到较好的训练效果,需要对数据进行规范化处理,将属性数据按比例缩放,使之落入一个小的特定区间,如[0,1]或[-1,1]之间。
本文采用最小-最大规范化对原始数据进行线性转换。假定minA和maxA分别为属性A的最小和最大值。最小-最大规范化通过计算:
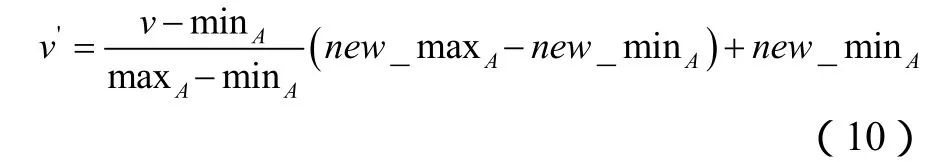
将A的值v映射到区间[n ew _ minA,n ew _ maxA]中的 v'。例如属性编制人数的最小与最大值分别是0和8006,如果想映射编制人数到区间[0, 1],根据最小-最大规范化,编制人数1280将转变为
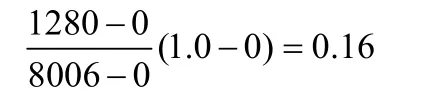
当数据预处理结束后,将所有规格化数据根据不同的属性划入不同的计算节点。节点划分策略是根据数据属性来确定节点的数量,数据属性,节点= { n1, n2,...,nn}。随后采用情报数据分类算法进行下一步的分类工作。
3.1.2数据快速分类层
当情报数据进入数据快速计算层时,采用抽取主表进行分析的策略。这里选择陆战编成情报数据和陆战当前状态情报数据这两类情报数据作为数据快速计算层分析的主要内容,对其进行布尔量化,量化结果如表1所示。
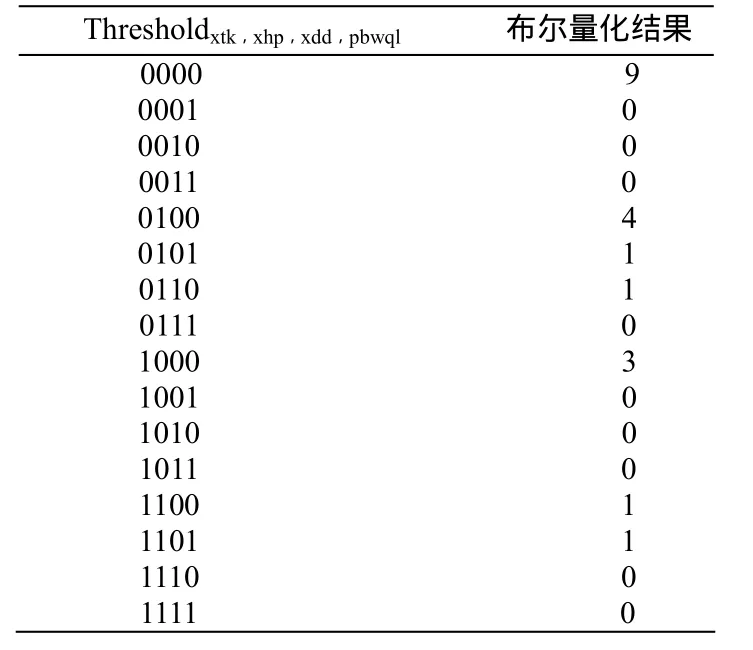
表1 布尔量化结果表
首先设定网络权值、初始温度。预置权值不能为0,否则学习过程将不可能开始,一般权值选定在[0,-1]或[-1,1]之间。任取初始权值w1= 0 .5,w2=0.4,w3=0.2,w4=0.3。训练集由状态{0000,0100,0101,0110,1000,1100,1101} 组成,它们的阈值分别为-0.9,-0.2,-0.3,0.7,初始温度为0.25,0.5,1。
随后根据各个节点单元激活函数值计算出各个状态的转移概率。当属性状态从0转移至1时,
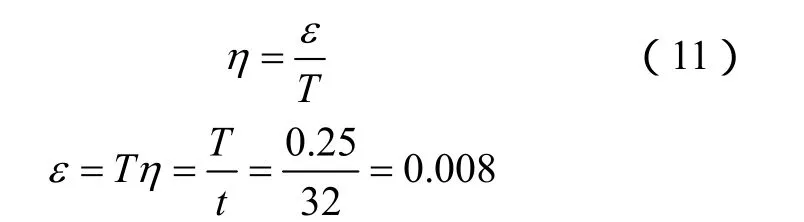
在初始设定温度为 0.25时,当 φ ( s )< 3 .992,取;当 φ ( s )> 3 .992,取ρ值。ρ取{0,3.992}之间的一个值,这里定为3.9;当初始设定温度为0.5时,ρ取{0,3.994}之间的一个值,这里也定为3.9;当在初始设定温度为1时,则ρ取{0,3.968}之间的一个值,这里同样定为3.9。
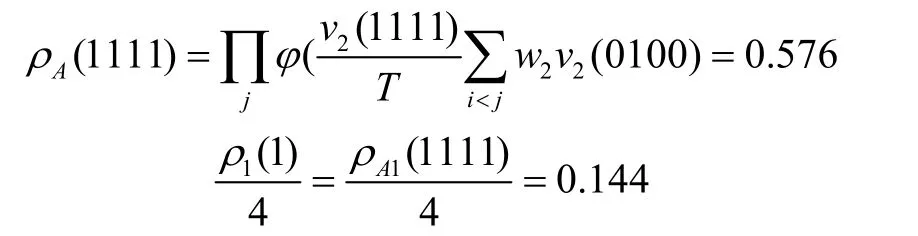
对陆战情报数据中的火力打击能力进行情报分析需要根据P(1)的综合指标指数来判定火力打击的水平 PSD。P(1)综合值越高,打击水平越强。根据 P(0)的综合指标指数初步判定危险级别DL。P(0)综合值越小,危险级别越高,结果见表3。
3.1.3数据精确分类层
当数据从上一层分析完毕后,进入精确分类层的数据已经形成初步的分类数据模型,随后展开进一步的精确数据分类处理。这里需要确定能够生成一棵简单决策树的分裂属性。
已分析过的数据中包含{zbx,zby,xtk,xhp,xdd,pbwql,bcxh,f}属性。其中,xtk表示坦克,xhp表示火炮,xdd表示地点,pbwql表示武器,bcxh表示消耗量,f表示类型。下面展开对这些属性反向熵值的计算。类标号 f有两个不同的值(即{1,2},1代表我军,2代表敌军),因此有两个不同类 C=2。设C1对应1,C2对应2。类1中有12个样本,类2中有8个样本,随后基于C中不同的类别开始计算属性的反向熵值。首先从陆战编成情报数据和陆战当前状态情报数据中的属性开始,如表4。
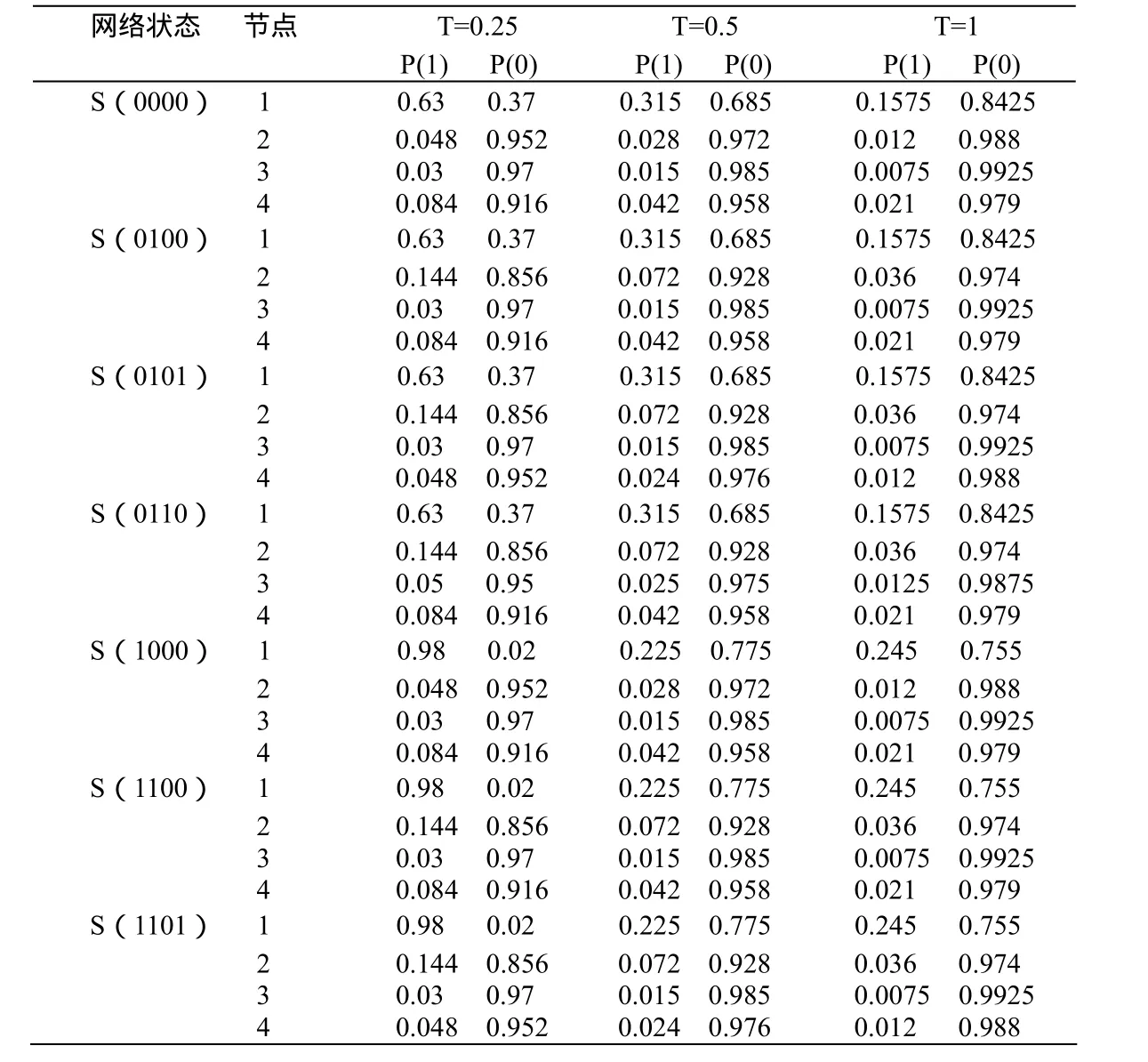
表2 第一层Boltzmann机网络训练结果表

表3 评估结果表
根据式(8)、式(9)对每一个属性的反向熵值进行计算:
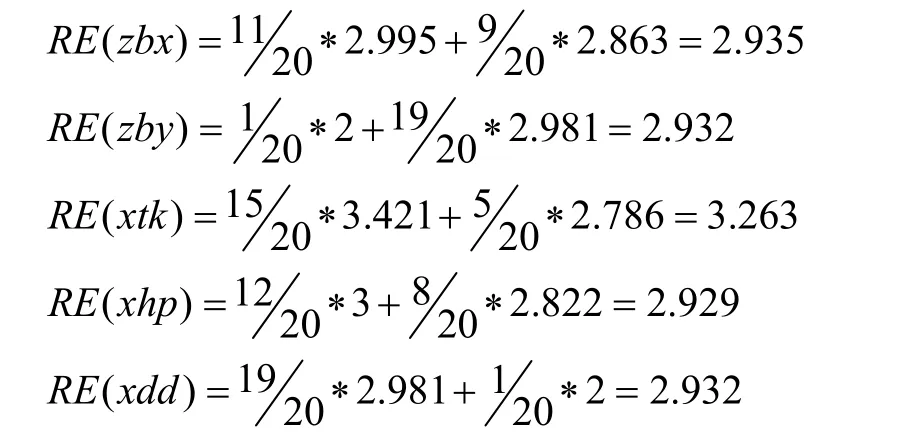
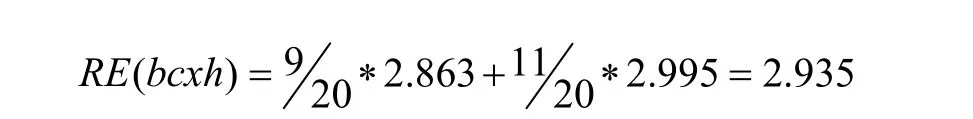
目前最小的反向熵值属性是 xhp,所以在决策树的根节点处选择xhp作为其分裂节点。随后对我军编成情报数据、敌军编成情报数据中的数据进行属性熵值分析。这时需要重新划分类C。我军编成情报数据、敌军编成情报数据中的类标号属性 bcxh有两类不同的值,分别是{001001001000001,…, 001001001001000}和{001001001001001,…, 001001001002000},这时也存在两个不同的类 C=2。设 C1对应{001001001000001,…, 001001001001000},C2 对应{001001001001001,…, 001001001002000}。计算我军编成情报数据中的属性熵值,如表5。

表4 陆战属性计算表

表5 我军编成属性计算表
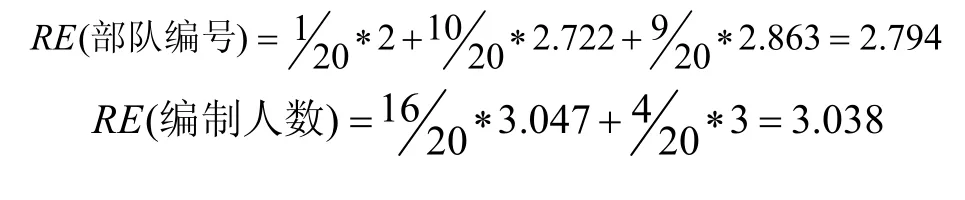
计算敌军编成情报数据中的属性熵值,如表6。

表6 敌军编成属性计算表
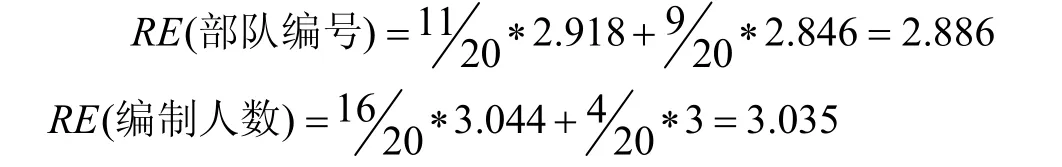
故此部队编号属性为决策树的子节点的属性。
随后计算我军部队编成准备情报数据、敌军部队编成准备情报数据的属性熵值,这时划分类C不用发生改变。下面计算我军部队编成准备情报数据中的属性熵值,如表7。
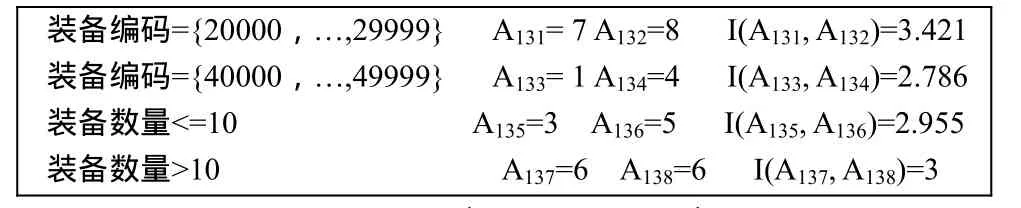
表7 我军部队编成准备属性计算表
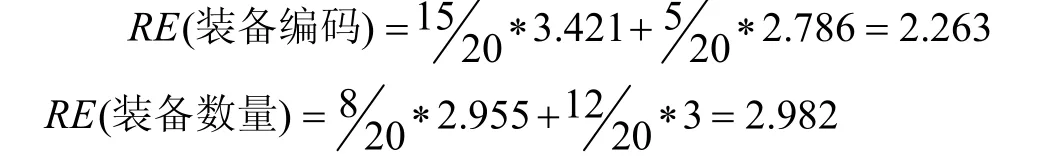
故此装备编码属性为决策树子节点的属性。所有采集的数据都依次推算,最终得到一颗完整的决策树。
3.1.4生成规则
部分得到的规则如表8所示,表中的DL分别取值“High”、“Normal”和“Low”,代表指定单位实时威胁评估的风险等级。

表8 第二层得到的规则表
3.2 系统验证
首先采用改进sigmoid函数的Boltzmann机对问题进行训练,sigmoid函数采用公式(1)中的函数,ρ取1.5。训练目标采用区间[-1.7,-1.0]或[1.0,1.7],训练方法采用随机训练法。随后采用改进熵函数的ID3算法对经过改进后的Boltzmann机训练后的问题进行分类。同时,也采用没有改进的Boltzmann机和ID3算法对问题进行训练和分类。为了直观的比较两种情况的效果,我们分别做出了它们的训练曲线,实验结果如下。
实验分别采用了83-53-13结构的Boltzmann机网络进行训练,然后利用ID3算法对训练结果进行分类,例如图 5是利用改进后的 Boltzmann机与未改进Boltzmann机进行问题训练曲线图。
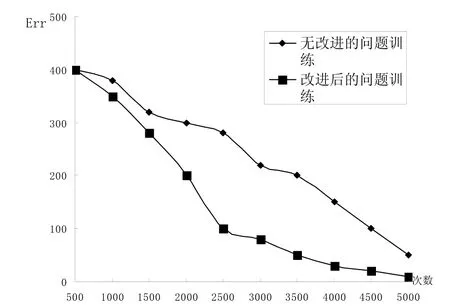
图5 改进后的Boltzmann机与未改进Boltzmann机问题训练曲线图
图6是利用改进后的ID3算法和未改进的ID3算法进行问题分类的曲线图。
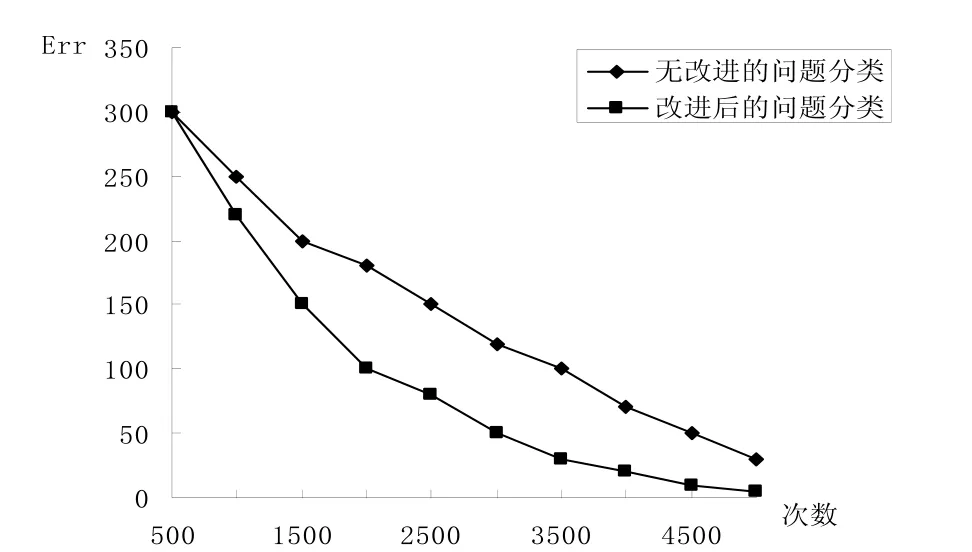
图6 改进后的ID3算法与未改进ID3算法问题分类曲线图
图7是采用改进后的 Boltzmann机和改进后的ID3算法-未做改进的Boltzmann机和ID3算法进行问题训练分类曲线图。如图所示,在三种情况下,用改进后的 Boltzmann机和 ID3算法明显比未做改进的Boltzmann机和ID3算法训练分类速度快。
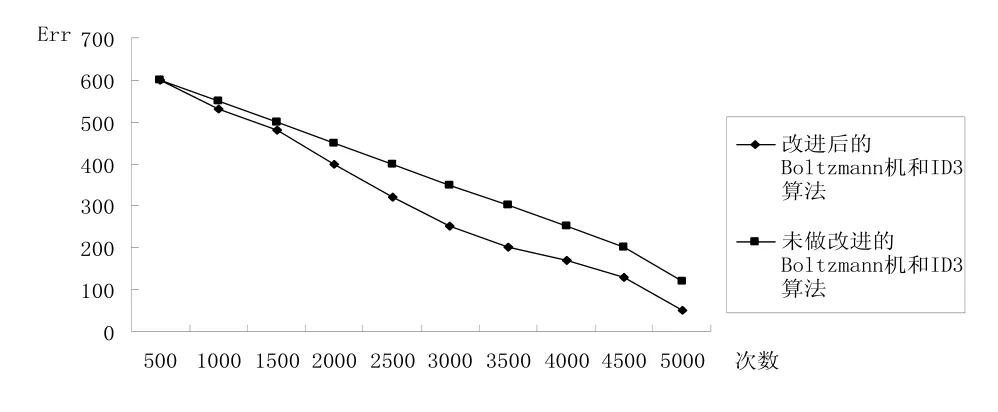
图7 改进后的Boltzmann机和ID3算法和未做改进的Boltzmann机和ID3算法问题训练分类曲线图
4 结束语
本文利用两种情报数据分类算法构建出一种新的情报数据分类算法用于军事情报分析系统的设计开发之中,针对原有算法的不足做出改进,并借助情报数据对整个系统进行了实例分析与验证。从分析结果中发现,新的情报数据分类算法在数据训练、分类的速度上要优于未做改进的算法。
[1]王旅,彭宏,胡勤松.基于判定树归纳分类的土质分类定名方法[J].计算机工程与设计,2006,27(11):1929-1931.
[2]王燕,李睿,李明.数据挖掘技术应用研究[J].甘肃科技,2001,17(1):49-50.
[3]Witten I H,Frank E.Data Mining:Practical Machine Learning Tools and Techniques with Java Implementations[M]. Seattle: Morgan Kaufmann Publishers,2000:265-314.
[4]张璠.多策略改进朴素贝叶斯分类器[J].微机发展,2004(4):35-36.
[5]贾世楼.信息理论基础[M].哈尔滨:哈尔滨工业大学出版社,1986.
[6]D.E.Culler, R.Karp, D.Patterson, A.Sahay, K.E.Schauser,E.Santos,R.Subramonian,T.Voneicken[A].LogP: Towards a Realistic Model of Parallel Computation. Proc.ACM Symp.on Principles and Practice of Parallel Programming,1993:1-12.
