AVS逆扫描 反量化和反变换模块的硬件设计
2011-07-02王祖强
秦 盼,王祖强,宋 健
(山东大学 信息科学与工程学院,山东 济南250100)
AVS标准是我国第一个拥有自主知识产权的数字音视频编解码标准,其编码效率比国际标准MPEG-2高2~3倍,与MPEG-4/H.264相当,但算法复杂度及存储要求比H.264明显低,更便于硬件的实现。
逆扫描、反量化与反变换模块在AVS视频解码过程中占有很重要的位置,其算法与架构实现优劣对AVS解码器的性能有很大的影响,国内外学者对这3个模块进行了研究。本文为了提高AVS解码器的处理速度,综合了国内外学者的设计思想提出了一种逆扫描、反量化与反变换模块结构,在消耗逻辑资源允许的情况下提高了处理速度,做到速度和面积的平衡。
本文将逆扫描、反量化和反变换模块结合在一起进行设计,在实现了块内部优化的同时采用了乒乓缓存寄存器组来实现块之间流水线,提高了速度;采用寄存器组复用技术实现逆块扫描中寄存器组与反变换中的转置寄存器组的复用,节省了寄存器资源。
1 硬件结构
根据AVS解码标准,本文提出了一种高效简洁的逆扫描、反量化与反变换系统结构,该结构主要由四部分组成。反量化模块完成量化系数向变换系数的转变;逆扫描与寄存器组选择模块根据逆扫描表完成变换系数的存储;寄存器组用来存储变换系数及反变换中的转置数据;反变换模块将变换系数转换成残差样值,为后续的重构做好准备。硬件结构及数据流程如图1所示。
其中输入为VLD模块解析出的(run,level)对、块结束标志及一些模式判别的信息。反量化模块对Level数据进行反量化,逆扫描与寄存器组选择模块采用依据轮流使用的规则产生寄存器组选择信号,同时对Run进行累加,并根据累加结果查表得到需要存储的寄存器,等所有量化后的Level值存储完毕后,由It_start信号连续读取8次寄存器进入反变换模块,反变换模块采用内部流水线结构经过22个时钟周期处理完一个块。反变换模块中的转置寄存器复用了前端的寄存器组。

图1 硬件结构
本设计通过乒乓结构实现了块与块之间的流水。图2是本设计的总体时序安排,图中考虑到变换编码后一个块内的有效系数一般小于25。其中以一个块数据输入反量化模块作为起始时刻,当反变化模块读取一个寄存器组并将其作为转置寄存器使用时,另一个寄存器组用于存储下一个块的反量化结果。如图2,寄存器组1用来存储当前块反量化后的变换系数值,而寄存器2被用于上一个块的反变换中。另外,读取转置后的数据时,通过对移位最初的寄存器赋零对寄存器2清零,从而用于下一个块的变换系数的存储。

图2 设计时序安排
1.1 逆扫描与寄存器组选择模块
该模块先对Run值进行累加,并根据扫描方式查表,得到当前Level值所对应的寄存器号,控制将反量化后的变换系数存入相应寄存器中,重复以上工作直到读到块结束标志。当前块不为零的所有变换系数均根据逆扫描表存储在相应的位置,因为每次从寄存器中读取转置数据时都会对寄存器清零,为下次使用做好准备,所以对于变换系数为零的情况就不用单独存储,从而提高了设计的处理速度。
1.2 反变换模块
反变换模块是将当前块的变换系数矩阵转换为残差样值矩阵的一个过程,为了节约硬件成本,此设计采用一维变换和转置矩阵实现二维变换,参考文献[2]中提出了一种快速有效的方法,本文对其方法进行了优化,节约了不必要的硬件资源和时钟。
下面主要介绍一维变换过程。
设AVS的一维反变换的输入输出变量分别为:
X=[X0,X1,X2,X3,X4,X5,X6,X7]T
Y=[Y0,Y1,Y2,Y3,Y4,Y5,Y6,Y7]T
根据Y=T8×X,把 8个输出元素展开成以下组合,其中 T8为 8×8的反变换矩阵。
M0=8X0+8X4;M1=8X0-8X4
M2=4X1+4X5;M3=9X1-10X5
M4=6X1+2X5;M5=2X1+9X5
M6=10X2+4X6;M7=4X2-10X6
M8=9X3+2X7;M9=2X3+6X7
M10=10X3-9X7;M11=4X3+4X7
其中所有的乘法均可化为移位操作,再定义8个中间变量 N0~N7:
N0=M0+M6;N1=M2+M8+M4
N2=M1+M7;N3=M3-M9
N4=M1-M7;N5=M4-M10
N6=M0-M6;N7=M5-M11-M9
重新整理后得到的输出:
Y0=N0+N1;Y1=N2+N3;Y2=N4+N5;Y3=N6+N7
Y4=N6-N7;Y5=N4-N5;Y6=N2-N3;Y7=N0-N1
由以上算法可以看出,一维反变换模块只需要移位和加法操作,既方便硬件实现还节省了硬件资源。经计算此一维反变化模块共需要40个加法器。
反变换模块的时序见图2,第1时钟周期进行并行读取数据,2个时钟周期进行一维反变换,第4个时钟周期开始向转置矩阵中存入一维反变换后的数据,第12周期开始读取转置矩阵中的数据,第15个时钟周期开始输出数据,第22个时钟周期结果输出完毕。
1.3 寄存器组复用
在逆块扫描顺序中,一些后续的系数可能需要在一开始时就准备好,而一些在前面次序的系数则可能在后续的时间使用,所以只有一个块的所有数据都存储完成后,才能进行后续的反变换,故至少要对一个块的变换系数进行存储。为了提高处理速度,后续的反变换模块中将采用并行流水线输入,因此存储模块此时不能采用有时序限制的RAM,本文采用了寄存器组实现。同时为了消除块数据的准备延时,还采用了乒乓结构,即在设计中用了两个寄存器组,这样就可在处理当前一个块系数的同时,用另一个寄存器组来存储下一个块反量化后的数据。
在反变换中也需要用到转置存储。为了节省资源,本设计采用了寄存器复用技术,即反变换中用到的转置矩阵与逆扫描后用于存储变换系数的矩阵复用,具体复用方法如图3所示。
以上为一个寄存器组,包含64个13 bit的寄存器。最后一列为反变换模块输入,即当一个块变换系数根据逆扫描顺序存储完后,连续8个时钟周期读取寄存器组最后一列,在每个时钟周期向反变换模块并行输入8个13 bit的数据。第一列为转置数据输入端。考虑到反变换流水线及复用的问题,在连续2个时钟周期读取寄存器组最后一列输入到反变换模块后,转置数据开始从第一列输入,这样可以满足反变换内部的流水线问题,也可以达到寄存器复用的目的。第一行为转置数据的输出,最后一行在转置数据输出时赋值为零,这样可以使转置输出和寄存器赋零同时进行,从而可以减少不必要的时钟周期和资源。
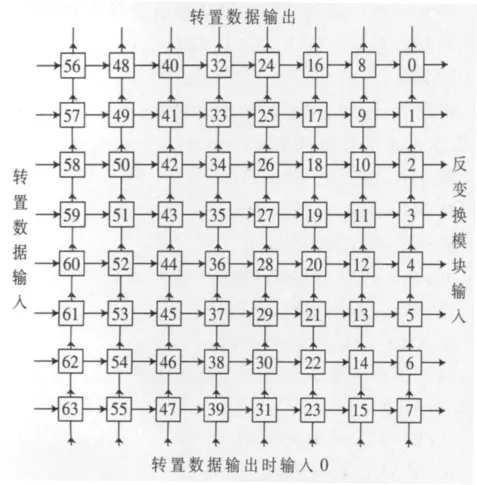
图3 寄存器组复用图
2 仿真结果及分析
根据上述思想,采用Verilog HDL语言对算法进行了RTL级电路描述,并采用Altera公司的软件Quartus II 8.0对此算法进行了实现和仿真验证,并将仿真结果与rm52j软件的输出结果进行了比较。Quartus II仿真结果如图4所示,波形图给出了一个块的反量化和反变换输出结果。rm52j的输出结果如图5所示,比较可见输出结果相同。

图4 硬件仿真结果
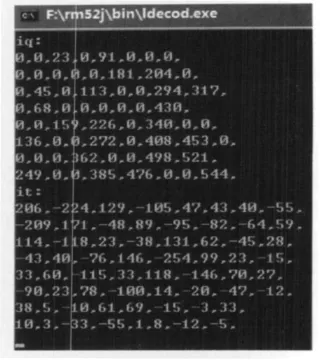
图5 软件仿真结果
本设计采用的是自顶向下和自下而上的混合设计方法,逆扫描、反量化和反变换过程是AVS系统中的一个模块,局部的测试很难判断出该模块是否可以应用到整个解码系统中去,所以此模块亦在自己搭建的基于SoPC的AVS验证平台上进行了验证。加入此模块前,软件处理一帧码流时间与用此硬件模块代替软件模块后的解码时间如图6所示,通过计算可知解码速度提高约15%。
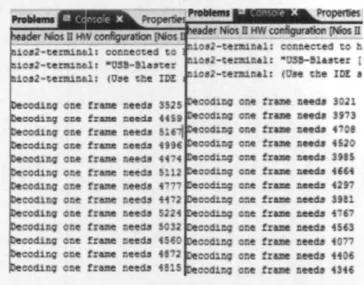
图6 纯软件解码与加入硬件模块后的解码
变换编码后一个块内的有效系数一般小于25,所以逆扫描、反量化的时钟一般小于25个时钟周期,而反变换的时钟周期为22个,所以处理一个块的时钟周期大约为25个,大大提高了速度。由于寄存器的复用及设计的优化,节省了硬件资源,本设计采用的FPGA为EP2C35F672C6,资源使用情况如图7所示,可见使用的总的LE为3 059个。

本文对AVS逆扫描、反量化和反变换算法进行了研究,并对目前其他学者在这方面取得的成果进行分析验证,实际考虑了AVS解码器整体设计的可行性,提出了一种速度更快、资源占用更少的方法。本设计为了解决RAM读写时序限制的影响,采用了两组寄存器阵列代替RAM实现乒乓操作,同时为了减少硬件资源,采用寄存器组复用技术,即反变换中的转置矩阵与逆扫描后存储寄存器组复用。最后给出了波形仿真结果,并与rm52j的输出结果比较,验证了结果的正确性。通过在基于Nios II的SoPC系统上进行测试,证明该设计能够正确快速实现逆扫描、反量化及反变换功能。
[1]GB/T 20090.2006.信息技术 先进音视频编码 2部分:视频[S].2006.
[2]张璐,刘佩林.基于FPGA的AVS反变换的设计与实现[J].电视技术,2006(7):20-23.
[3]毛讯.高速视频解码器设计研究[D].杭州:浙江大学,2001.
[4]赵策,刘佩.AVS游程解码、反扫描、反量化和反变换优化设计[J].信息技术,2007(2):54-57.
[5]黄友文,陈咏恩.AVS反扫描、反量化和反变换模块的一种优化设计[J].计算机工程与应用,2008,44(19):93.
[6]H.264及 AVS视频解码器中 IQ/IDCT的设计与实现[J].电子技术应用,2006,32(7):39-42.
