一种改进的协作过滤算法
2011-06-26刘浩杰金鑫
刘浩杰 金鑫
(武汉理工大学 信息工程学院,湖北 武汉 430072)
0 引言
随着计算机和网络技术的发展,呈现在计算机用户面前的信息变得越来越庞大,但不同的用户对于信息的需求是不同的,因此如何快捷地为用户找到所需的信息成为一个难题,而协作过滤方法则是目前解决这一问题的主要手段。该方法是指信息使用者(即用户)根据自身的需求,通过和其他用户进行合作,形成一定的协作规则,或利用多个信息使用者的倾向性来预测单个用户的兴趣,然后根据具有相同兴趣喜好的用户对信息进行评价,从而得到推荐结果。与已有的大多数其他信息推荐方法相比,基于协作过滤对用户进行信息推荐的优势是巨大的,它是目前个性化推荐系统中最具有优势的技术之一,也是目前众多研究者的研究热点之一。与此同时,协作过滤技术的运用范围也正在不断扩大,在诸如信息查询、评价预测、产品推荐和电子商务等领域都有着较好的研究前景,本文也将针对协作过滤技术进行研究。
1 相关工作
目前,对于协作过滤技术的研究[1]有很多,在基于协作过滤技术开发的系统中,有些已经达到了使用水平,例如,基于资源的协作过滤推荐算法[2]、基于项目的协作过滤推荐算法[3]、基于用户的协作过滤推荐算法[4]等等。尽管这些技术已经取得了较大的成功,但还有很多地方存在缺陷,需要做进一步的研究,总结起来主要有以下几点:(1)如何更为有效地对用户的行为和兴趣进行形式化描述;(2)现有的多用户之间相似性计算方法存在语义不一致性,如何解决该问题还没有一种较好的方案;(3)由于目前的信息量越来越庞大,现有的方法不能很好地应对由于信息量增加造成的数据高维稀疏性和扩展性差的问题,还有待研究出更加有效的方法来进一步提高个性化服务的质量;(4)目前大多数方法对于某个资源的评分值都不是一个整数,很多方法对于得到的评价值采用"四舍五入"的原则来进行取舍,然而这种方式已经被证明无法得到准确的结果,与用户的真正需求相差甚远。鉴于以上几点不足,本文针对现有的协作过滤方法面临不足,提出了一种改进的协作过滤推荐算法,并进行了实验验证。实验结果表明,本文提出的协作过滤算法在推荐效果方面更优,能够更快更好地为用户推荐所需的信息。
2 协作过滤的基本思想
协作过滤算法的主要思想是依据不同信息使用者对资源的喜好来为对方相互推荐资源,这样可以免去对资源内容进行分析的复杂过程,然后,依据信息使用者对资源的评价来计算用户之间的相似性,并根据计算得到的相似性来预测当前用户对资源的需求强弱。下面先给出传统的协作过滤算法描述,如下所示。
算法1 传统的协作过滤算法
输入:测试数据集
输出:对目标用户的推荐结果
Step1.使用皮尔逊(Pearson)相关系数进行加权处理来计算用户之间的相似性;
Step2.从Step1中选择相似度大于某一规定阈值的k个用户,即为和当前用户最相似的用户;
Step3.利用相似邻居的加权和来预测当前用户ua对资源 t的打分:

其中,Sua表示用户 ua的邻居集,Pua,t表示用户ua对资源t的预测值,sim'(u0,ui)表示用户之间的相似度。
上述算法产生的预测值Pua,t通常情况下不是一个整数,但是在实际应用中,信息使用者对资源评价值需要整数,例如,在电影推荐系统中,用户的评分级别一般为2、4、6、8、9和10分。所以,对于Pua,t,我们还需要将它进一步修正为一个整数。如果预测值为2、4、6、8、9 和 10 分,可以直接判定,但是如果预测值为 5.2分,现有处理办法都是按照"四舍五入"的原则判定为5分,如果预测值为4.8分则判定为5分,显然,这种处理是不够合理的,它没有考虑到用户对资源使用存在的潜在需求。另外,当数据量很大时,传统的协作过滤算法计算就会很复杂,需要耗费大量的计算资源,另外还无法避免或减少数据稀疏性所带来的计算不准确问题,从而导致了推荐质量的低下。
针对以上的问题,本文提出了一种改进的协作过滤算法,算法通过对预测值进行修正、过滤数据预处理、聚类等一系列操作来保证最终推荐结果的准确性。
3 改进的协作过滤算法
3.1 对协作过滤算法中预测值的修正
为了方便论文的后续描述,先给出以下几个相关的定义。定义1趋势度(Trend Degree):指用户根据自身的需求,将某一信息评为某一级别的概率。设某个评分级别k趋势度标记为Tre(k),则有:
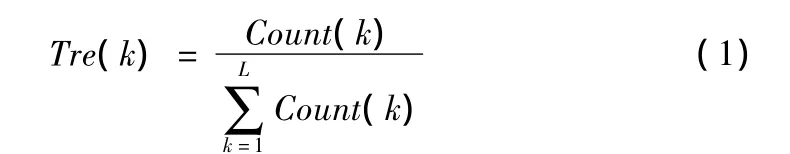
L表示评分级别(Level)的个数,Count(k)表示用户评分中被评为级别k的个数。
定义2差异度(Difference Degree):按照用户根据自身的需求,指通过算法对某一信息进行评价的值偏离某个评分级别的程度大小。设预测值p相对于级别k的差异度标记为Dif(p,k),计算公式为:
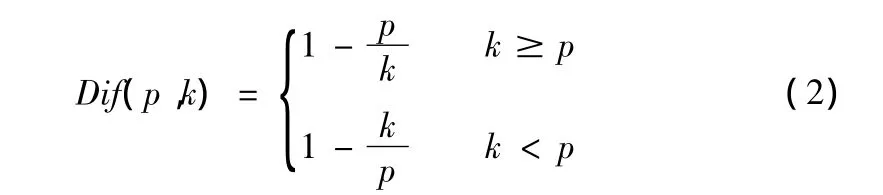
定义3 可信度(Credible Degree):指通过某个算法预测用户对一个资源评分的预测值应该被判定为某个评分级别的可能性程度。设预测值p相对于级别k的可信度标记为Cre(p,k),计算公式为:

其中α为可调节因子,在实验中来设定。
结合上述三个定义,预测值的修正算法如下所示。
算法2 预测值的修正算法
输入:通过某算法计算用户对一个资源的预测值P,该用户的评分集合 R={r1,r2,r3,…,rn},评分级别 L={l1,l2,l3,…ln}
输出:预测值P的修正值;
Step 1.根据公式(1)计算每个评分级别li的趋势度T(li);
Step 2.根据公式(2)计算预测P与最接近的两个评分级别的差异度 Dif(p,lia)和 Dif(p,lib);
Step 3.根据公式(3)计算与预测值P最接近的两个评分级别的可信度Cre(p,lia)和Cre(p,lib),选择较大的作为最后的修正值。
3.2 改进后的协作过滤算法
目前的信息资源数量越来越庞大,但是我们可以根据资源的种类、属性和领域等对其进行分类,划分为不同的类别,这样就可以大大降低数据的维度和稀疏程度。那么,如果先对多个用户进行聚类,然后在簇内部计算目标用户和其他用户的相似性,并选取相似度值大于某个阈值的K个用户作为其最近邻居。这样,不仅可以缩小目标用户查找最近邻的搜索范围,而且由于簇内部的用户的兴趣也较为相似,因此,他们共同进行评分的参考数据往往也较多,这样可以增加选择相似邻居的准确性,从而能够提高为用户进行资源推荐的质量。
基于以上的考虑,得出本文改进的协作过滤算法的主要思想是:首先对资源进行分类,然后通过加权过滤数据预处理,再利用K-平均聚类算法对用户进行聚类,最后,通过计算用户间的相似性,产生最近邻居集,并对预测值进行修正,从而得到用户的推荐集。算法描述如下所示。
算法3 改进的协作过滤推荐算法
输入:测试数据集
输出:对目标用户的推荐集
Step1.对资源项目依内容进行分类;
Step2.将用户-项目矩阵R(M×N)转化为用户-资源项目类别矩阵C(M×X);
Step3.对矩阵C(M×X)进行加权过滤数据预处理,得到CW(M×X);
Step4.运用K-平均聚类算法对用户进行聚类;
Step5.在各簇中,计算目标用户与其他用户的相似性;
Step6.选取目标用户的若干最相似用户,建立最近邻居集。
算法各个步骤的具体说明如下:
Step1,在对资源进行分类时,主要基于启发式规则和基于贝叶斯分类的方法进行资源分类,以确保分类的正确性;
Step2,将Step1中的分类结果进行转换,得到用户-资源项目类别矩阵C(M×X),矩阵的值Cm,x表示用户M对某一资源类别X的评分。由于资源可以依据其内容或者属性划分为多个不同的类别,用户对资源的最终评分通常取其不同类别评分和的平均值;
Step3,一般情况下,不同的用户进行评分的数据是不同的,因此得出的评分结果也存在很大的差异,为了归一化评分结果,本文采用文献[5]中提出的一种加权过滤的方法,对用户-资源项目类别矩阵C(M×X)进行数据预处理,从而得到标准化的资源;
Step4,在Step2和Step3的基础上,采用K-平均聚类算法对用户进行聚类;
Step5,在对用户聚类后的基础上,在簇内计算目标用户和其他用户的相似性,再选取相似度值大于某一规定阈值的用户作为其最近邻居。用户的相似性本文选取余弦相似性来评价。
Step6,根据最近邻居对项目i的评分来计算目标用户u对资源项目i的预测评分。再依据预测评分的高低,产生资源项目的推荐。目标用户预测评分的计算公式如下所示。
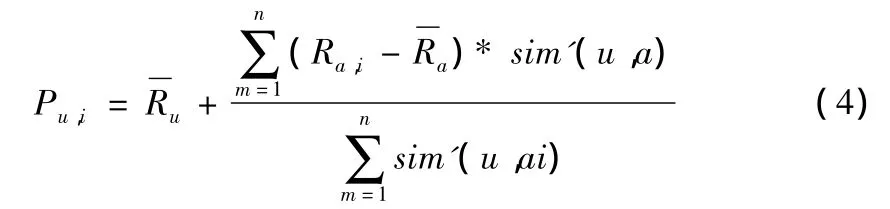
4 实验结果与分析
4.1 测试数据集
本文利用了较为典型的MovieLens数据集[6]来进行实验测试,它包含了900多个用户对1600多部电影的10万个评价值。从每个用户的打分项中,随机抽取30个作为测试项,其余的作为训练项,因此训练集的大小为90500,测试集的大小为9400,和目前大多数协作过滤方法的评价指标一样,本文也使用正确率(Correct)、平均绝对误差(MAE)、运行时间(Time)作为实验的评价标准。
4.2 对比实验及结果分析
在实验中,考虑了邻居数目从10到110的情况下,两种算法(算法1和算法3)的比较(权重因子取值为0.85)。其中,算法1是传统的协作过滤推荐算法,算法3是本文提出的改进的协作过滤推荐算法。正确率的比较如图1所示:
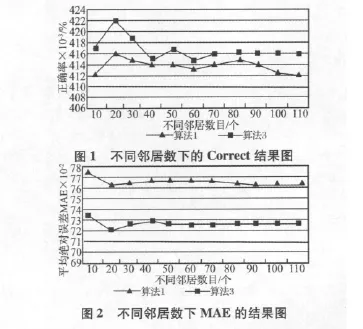
平均绝对误差的比较如图2所示:
运行时间的比较如图3所示:

图3 不同邻居数下的Time开销
比较改进算法和传统算法的推荐效果平均值如表1所示:

表1 推荐效果的平均值比较
由以上图和表可知,本文改进的算法的正确率有了比较明显的提高,其时间开销要略高于传统算法,但推荐结果的平均绝对误差却比传统方法降低了很多,这表明本文的方法是有效的。仔细分析其原因可知,这主要是因为改进后的算法首先通过对资源进行分类、加权过滤数据预处理以及K-平均聚类算法对用户进行聚类,然后利用余弦相似度计算用户间的相似性,产生最近邻居集,最后基于可信度对算法产生的预测值行了修正,因此得到了较为理想的推荐结果。
5 结束语
针对现有协作过滤算法没有对预测值进行修正、存在高维数据稀疏性以及可扩展性不强等问题,本文提出了一种改进的协作过滤方法,该方法基于可信度对预测值进行了修正,最后采用基于资源分类、聚类的思想得到目标用户的推荐集。经过实验分析,改进后的算法与传统的协作过滤算法相比,能得到更好的推荐质量。
未来的工作包括以下两个方面:第一,根据用户的背景知识,从多个角度进行相似度的计算,挖掘语义层次的最近邻居;第二方面,对算法的时间复杂度做进一步的优化,并考虑将改进后的算法应用到其它的领域。
[1]曾春,邢春晓,周立柱.个性化服务技术综述[J].软件学报,2002,13(10):1952-1961.
[2]纪良浩,王国胤.基于资源的协作过滤推荐算法研究[J].计算机工程,2008,44(8):33-36.
[3]李伟,王新房,刘妮,等.基于项目的非邻近序列模式推荐算法[J].计算机工程,2009,35(16):65-67.
[4]邓爱林,左子叶,朱扬勇,等.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):46-52.
[5]Tuguldur Sumiya,Jonghoon Chun,Sang-goo Lee,et al.A weighted siringmethod to improve the effectiveness of collaborative filtering[C]//2004 IEEE Region 10 Conference,2004:266-269.
[6]Movielens[EB/OL].[2006-10-05].http://movielens.umn.edu/login.
