基于用户行为模型的计算机辅助翻译方法
2011-06-14张桂平韩亚冬蔡东风
叶 娜,张桂平,韩亚冬,蔡东风
(沈阳航空航天大学 知识工程研究中心, 辽宁 沈阳 110136)
1 引言
机器翻译是自然语言处理领域的重要研究课题。数十年来,从传统的基于规则[1]和基于实例的机器翻译方法[2]发展到今天以统计机器翻译[3-4]为主流的翻译方法,机器翻译技术在消歧问题、代词指代以及更多的惯用法生成等方面都由于语料库技术的应用而有了解决的希望。然而,尽管机器翻译的译文质量比20世纪70年代有了长足的进步,却仍然没有达到实用水平。
在急速增加的翻译需求的驱动下,机器翻译思想发生了改变,即从全自动翻译技术向辅助翻译技术的转变。计算机辅助翻译系统(computer assisted translation, CAT)就是这种思想转变的体现。辅助翻译系统为用户提供作为辅助译文的自动翻译译文和用来对译文进行修改的界面。辅助翻译在质量和速度上都优于人工翻译。
在全自动机器翻译系统中,系统只能单方面提供自动生成的翻译结果,而无法得到反馈,系统所使用的知识也是静态的。相比之下,在辅助翻译系统中,用户(即翻译人员)可以对机器翻译自动生成的辅助译文进行筛选和整理,直至最终生成可用的译文。这个后编辑过程实际上是对系统的一种反馈。然而,目前辅助翻译系统[5-8]的机器翻译引擎和用户之间相互隔离,是简单的分工关系,系统对用户反馈的利用程度十分有限。因此,如何从用户后编辑行为中自动学习出隐性的翻译知识,并加以有效的利用,使得系统的翻译能力随着用户使用时间的增长而同步增长,实时动态提高辅助译文质量,是辅助翻译技术中亟待解决的问题之一。
本文提出一种基于用户行为模型的辅助翻译方法,其中通过实时记录和分析用户对辅助译文的后编辑过程,自动学习用户的翻译知识,构建用户行为模型,为机器翻译引擎提供指导,动态提高辅助译文的质量。实验结果表明,在同一篇测试语料的前30%文本的后编辑过程中建立的用户行为模型,使余下70%文本的辅助译文的BLEU值提高了 4.9%,用户模型中翻译知识的准确率达到94.1%。
2 相关工作
一些研究人员在翻译模型中考虑了用户行为因素。Kay[9]最早研究了交互式翻译(Interactive Machine Translation, IMT)技术,其中用户的工作被限制为消除原语句子中的句法歧义,规则系统负责对经过消歧处理的原文进行翻译,用户不必对目标语进行处理,甚至不需要具有任何关于目标语的语言知识。这种方法在某些特定应用中具有一定优势,但同时也存在着严重的不足,特别是用户不能直接控制最终译文的质量,以及对于熟练的翻译人员来说消除歧义是否真的比直接翻译更容易也存在疑问。为此,Foster等人提出使用文本预测(text prediction)技术[10-13]来实现交互式翻译。虽然基于统计方法的文本预测技术具有很高的准确率,但这并不意味着用户的翻译效率会有同样的提升。Langlais[11]通过实验证明,虽然TransType系统[10]能够准确预测超过70%的字符,但在一项实际的翻译测试中,翻译效率反而下降了17%。Foster[12]认为主要有两个原因: 首先,用户阅读提示(proposals)需要时间,所以当提示的内容过短或有错误时,实际的翻译速度会有所降低;其次,用户对待提示并不总是“理性的”,用户偶尔也会选择错误的提示。这表示TransType系统为了学习翻译知识,对用户的翻译过程产生了很大的干扰和影响,限制了辅助翻译技术优势的发挥。实际上,上述方法都要求用户对机器翻译系统提供某种特殊指导,并非从真实的辅助翻译后编辑过程中直接获取翻译知识。相比之下,本文记录了用户对辅助译文的真实后编辑过程,并从中自动分析出用户的翻译决策,作为翻译知识的来源。整个学习过程对用户的翻译过程影响很小。
近年来出现了一些从后编辑结果中自动学习翻译知识的方法。2006年,Elming[14]提出,使用基于转换的学习(transformation-based learning),从词对齐后的机器译文和正确译文中自动获取翻译错误的修改规则。2007年,Simard[15]将机器译文作为源语言,将正确译文作为目标语言,训练出一个统计机器翻译系统,对机器译文进行自动后编辑。2009年,Groves[16]通过分析微软Treelet机器翻译系统的机器翻译结果和人工后编辑结果,识别出一系列后编辑模板。但是这些方法忽略了用户进行后编辑的中间过程,仅考察原始机器译文和最终正确译文,为了识别相互对应的修改单元,就需要对两个译文进行单元(词或短语)对齐,而原始译文和最终译文之间往往差别很大,很难达到较好的对齐效果。事实上,为了得到译文修改单元之间的对应关系,必须记录和分析用户对译文的整个编辑过程。本文通过将用户的复杂编辑过程分解为单步操作序列,并对比中间译文结果,自动得到对应的修改单元,从中学习翻译知识。
3 基于用户行为模型的辅助翻译方法
3.1 总体流程
在本文的辅助翻译系统中,通过建立用户行为模型,从用户的显性后编辑操作中挖掘出隐含于用户头脑之中的隐性翻译知识,实现辅助翻译系统中语言知识层面的人机交互和人机知识的同步增长,从而改善辅助译文的质量,提高翻译系统中的人机协同工作的效率。图1描述了基于用户行为模型的辅助翻译过程。
图1中,用户借助辅助翻译平台对系统提供的辅助译文进行后编辑操作, 辅助翻译平台自动记录整个编辑过程,通过自动学习系统,将用户行为转换为翻译知识,处理知识中的冲突,逐步建立用户行为模型,进而优化机器翻译引擎输出的自动译文,提高用户的翻译效率。
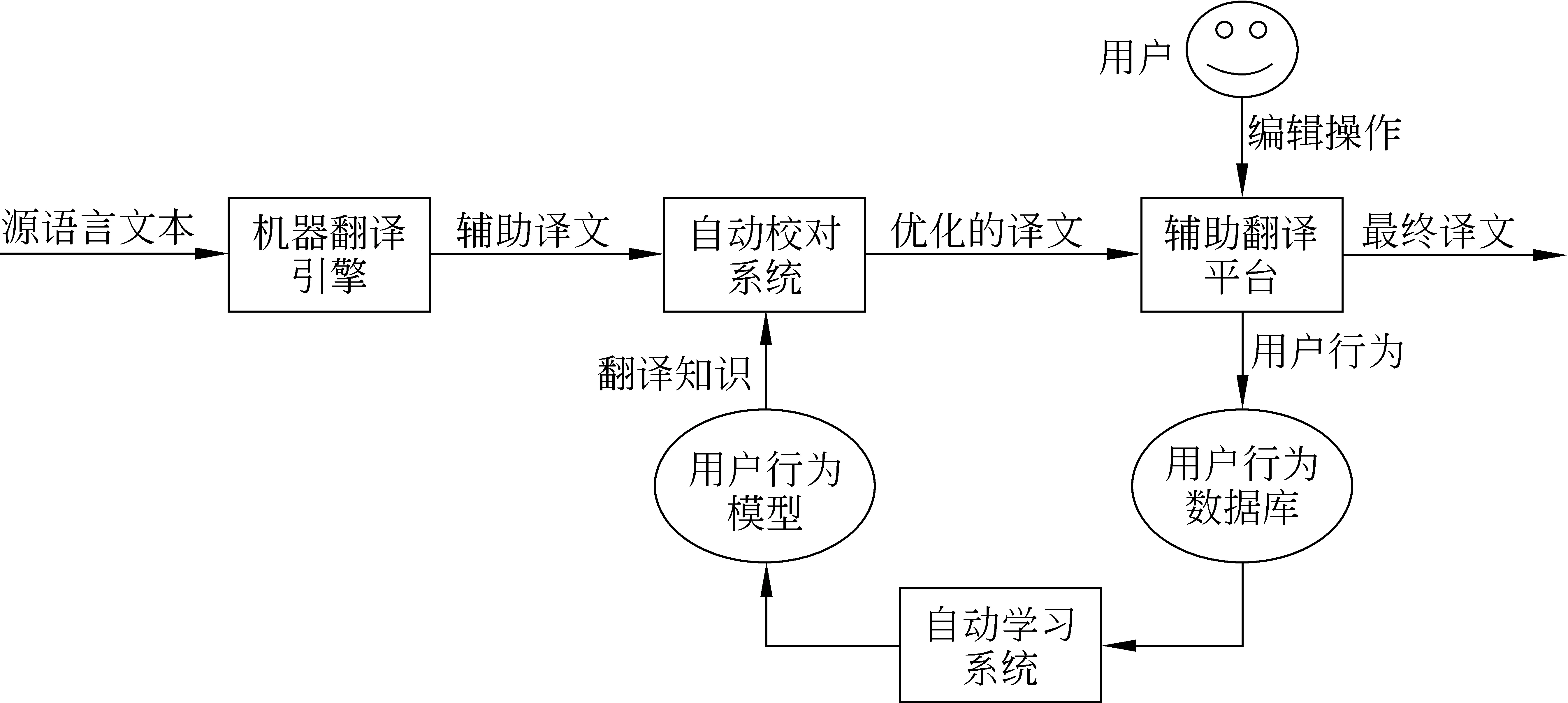
图1 基于用户行为模型的辅助翻译系统
3.2 用户行为采集
用户行为数据采集和分析系统可以看作是记录用户后编辑全过程的工具。该工具集成在辅助翻译平台中,由两个部分组成: 1)“后编辑”模块,2)数据采集模块。如图2所示。

图2 用户行为数据采集系统
“后编辑”模块提供了用户(即翻译人员)对机器翻译译文编辑的环境,并由数据采集模块进行记录。该模块记录了用户的后编辑全过程,用于实时动态挖掘翻译知识。
为了降低翻译知识学习的难度,本文的数据采集模块要求用户在每次完成一个相对完整的修改操作(操作包括“插入”、“删除”、“替换”3种)后点击提交,系统进行记录,自动识别和去掉没有意义的“中间无效修改”(本文规定5个词以上的修改为无效修改)后,保存到数据库。用户行为数据库中包含的信息是如下的二元组:
<原始译文TO,修改译文TM>
通过这种方式,在辅助译文上进行的复杂后编辑过程被分解为一系列翻译决策,其中每个操作代表用户所做的一个决策。整个后编辑过程表示为一个翻译决策序列:

决策分解策略的好处在于可以直接对齐用户每次修改的译文片段,降低翻译知识获取的难度,同时避免生成过于细化的规则,有助于提高规则的覆盖率,且不会对用户的翻译过程带来过多干扰。
3.3 用户行为模型建立
从用户行为采集系统记录的后编辑过程中,自动学习用户的翻译知识,形成翻译规则库,作为用户行为模型,来自动修改机器翻译模型生成的辅助译文中的翻译错误,优化辅助译文。
系统所采集的用户行为数据由一系列中间翻译决策组成。每个翻译决策Di仅包含对中间译文Ti-1的一次编辑操作,得到新的中间译文Ti。例如:
Dm->Tm-1:... in the fixed lock body ...
Tm:... in the immovable cylinder body ...
Dn->Tn-1:... perform the bamboo pole dance ...
Tn:... perform the bamboo dance ...
通过比较中间译文Ti和Ti-1,提取被修改过的译文片段,可以从中自动归纳出用于修正翻译错误的翻译规则。规则以三元组形式表示如下:
其中CONTEXT代表存在错误的译文片段S的上下文,是一个以S为中心的窗口;T代表用于对S进行修改时的目标片段。规则的含义是,当片段S的上下文为CONTEXT时,将S修改为T。上下文窗口的大小对翻译规则的性能有直接影响。窗口越大,所生成的规则越严格,准确性更高,但匹配上的概率越低,反之亦然。本文规定,当修改操作的类别为“替换”时,可忽略上下文;当修改操作的类别为“插入”或“删除”时,选取上下文窗口为当前片段S的前一个词Wpre和后一个词Wnext。
另外,本文还对规则进行了以下限制:
1) 在CONTEXT中,若Wpre或Wnext为禁用词,则去除该词,若两者均为禁用词,则滤掉这条规则;
2) 片段S或CONTEXT中至少应含有一个名词,否则过滤掉这条规则。
根据以上原则,上例中的翻译决策Dm可生成规则如下:
< fixed lock, -, immovable cylinder >
翻译决策Dn可生成规则如下:
3.4 辅助译文优化
辅助翻译系统在用户行为模型的指导下,利用学习出的翻译规则,对机器翻译引擎输出的辅助译文进行后处理,修正其中的翻译错误。译文优化的具体过程如下:
假设有源语言文本Ts
STEP 1: 机器翻译引擎将Ts翻译成辅助译文TR;
STEP 2: 对TR进行规则匹配,失败则转到STEP 4;
STEP 3: 按匹配规则修改TR,转到STEP 2;
STEP 4: 输出最终译文TR。
在该过程中,对自动生成的辅助译文进行规则循环匹配,直至没有能够匹配上的规则为止。用户模型中记录每条规则出现的位置,在发生规则冲突时,选择与片段S距离最近的规则进行匹配。
4 实验
4.1 实验设置
为了评测基于用户行为模型的辅助翻译方法的有效性,本文从互联网上下载了50篇中文文章(体裁包括新闻报道、科技说明文、评论性文章、小说、专利摘要等),组成评测语料。语料的具体情况如表1所示。
实验选取Google机器翻译系统作为辅助翻译系统中的机器翻译引擎,进行汉到英的自动翻译,以生成辅助译文。实验采用BLEU值作为辅助译文质量的评价指标,并用NIST(National Institute of Standards and Technology)官方网站发布的mteval-v11.pl来进行计算。

表1 评测语料
本文将用户后编辑产生的最终正确译文作为参考译文,用于BLEU值的计算。在实验中,每个测试句子只有一个参考译文。
4.2 实验结果及分析
本系统中,对于每篇测试文档,随着用户对辅助译文后编辑比例的增加,用户行为模型中的翻译知识逐渐累积,对于该文档余下句子的自动翻译效果不断提高。本文针对每篇测试文档,对用户模型的效果进行了封闭测试。测试方法是,让用户分别对每篇文档从头至尾进行后编辑,并在不同后编辑比例下,利用所生成的用户模型对整篇文档的辅助译文进行修正,并评测辅助译文的质量。实验结果如图3所示。
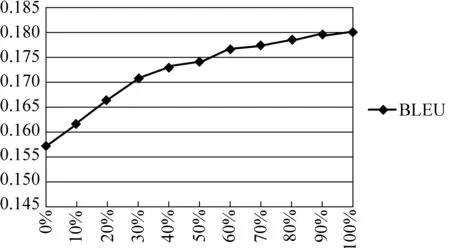
图3 不同后编辑比例下辅助译文质量评价结果
图3为全部语料上的总体测试结果。机器翻译引擎的初始辅助译文BLEU评价值为0.157 2,当用户完成对每篇文档的后编辑时(比例为100%),利用此过程中建立的用户行为模型,自动修改同一篇文档的初始译文,使得辅助译文的BLEU值提高了14.7%,达到0.180 3。其中本文对用户行为进行
有选择的学习,主要针对名词短语的选词错误,未覆盖全部翻译知识,因此处理后的辅助译文并非完全正确的。
从图3可以看出,辅助译文质量的提高呈非线性趋势。当用户完成对每篇文档前30%文本的后编辑后,辅助译文的BLEU值提高了8.7%,达到0.170 9,而余下70%文本的后编辑带来的提高仅有6.0%。这是由于文档的开头一般会说明全文的主要内容,提出所涉及的重要实体或概念,因此从该部分的后编辑中学习到的翻译知识对于同一篇文档余下部分的翻译具有很强的指导意义。而文档中间部分往往是对于文章主旨的深入和展开论述,即便出现新的实体或概念,也较少在后文中反复提及,因此其翻译知识的指导意义不如文档开头部分大。
由此可见,从文档前30%文本的后编辑过程中建立起来的用户模型中含有重要的翻译知识。为了验证这些翻译知识对于提高文档中其余文本翻译质量的作用,本文进行了开放测试,即利用每篇文档的前30%文本中建立的用户模型,来修改同一篇文档余下70%文本的辅助译文,并对译文质量进行评测。实验结果如表2所示(其中原始辅助译文由Google翻译引擎生成)。

表2 机器翻译系统对比实验结果
对比实验结果表明,使用了用户模型后,辅助译文的BLEU评价值提高了4.9%,说明用户模型中的翻译知识能够有效提高辅助译文质量。系统在用户翻译过程中自动获取用户的翻译知识,弥补了自身知识的不足。
例如,通过3.3小节中的翻译决策Dm所生成的规则,系统从用户行为中学习到,“固定锁头”的原始译文“fixed lock”是错误的,正确译法应是“immovable cylinder”。那么,如果后文中再次出现“固定锁头”,系统就会将错误的辅助译文自动修改为正确译文。同理,从翻译决策Dn所生成的规则中,系统学习到“竹竿舞”的正确译法。
本文的用户模型中翻译知识主要以规则形式表示,表3列出了上文开放测试中建立的用户模型的基本情况。

表3 用户模型
如表3所示,在303个中文句子的后编辑过程中共记录了2 069个中间译文(平均每个句子产生6.8个中间译文),从中生成了178条规则(平均每11.6个中间译文生成1条规则)。规则生成的比例较低,这是由于本文对生成规则的控制较为严格。同时本系统对规则的上下文有一定限制,因此匹配的正确率较高,为94.1%。
通过分析错误实例,本文发现,匹配错误主要是由于“替换”操作所生成的规则未充分考虑上下文造成的,且错误集中于单个名词的修改中。
例如,“恒温混水阀”的原始辅助译文为“temperature mixing valve”,正确译文是“thermostatic mixing valve”。本文的学习算法生成规则
本文还对测试语料中不同体裁的文章分别进行了开放测试,即用户对每篇文章的前30%进行后编辑,利用该过程中建立的用户模型对同一篇文章余下的70%文本的辅助译文进行修改,并评价译文质量。实验结果如图4所示。
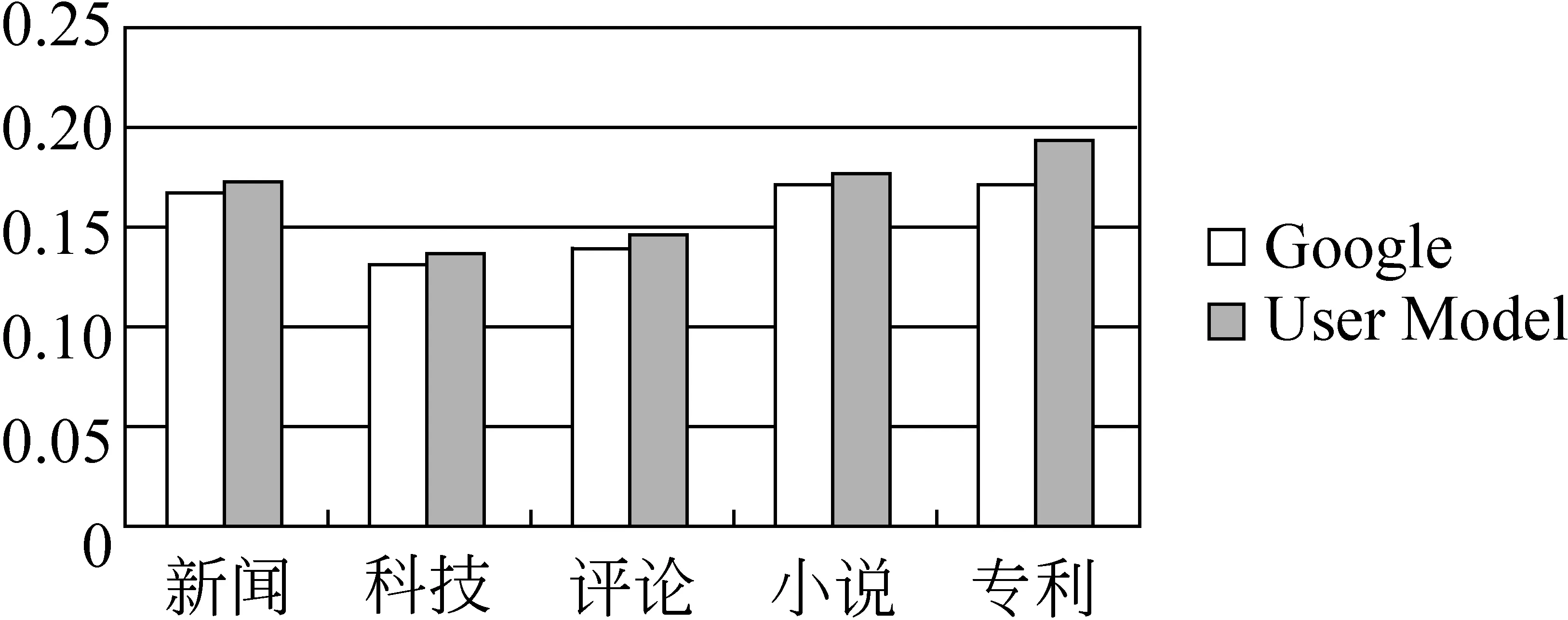
图4 不同体裁语料的对比实验结果
实验结果表明,对于新闻、科技、评论、小说和专利语料,用户模型的建立使得辅助译文的BLEU值分别提高了4.0%、4.0%、5.4%、3.0%和12.6%。其中专利语料的提高幅度最大。本文认为其原因是专利中含有较多的专业名词,且这些名词在全文中重复出现的概率较高,这使得系统从用户的翻译过程中学到的翻译知识能够更充分地发挥作用。小说语料的提高幅度相对较小,原因是小说中的实体和概念通常较为常见,机器翻译引擎翻译效果较好,系统学习到的翻译知识较少,使得用户模型的作用不如在其他体裁的语料上明显。
5 结论
本文从用户翻译行为角度出发研究辅助翻译过程,通过实时记录用户对辅助译文的后编辑过程,将整个过程分解为翻译决策序列,据此学习出用户的翻译知识,建立用户行为模型,实现辅助翻译系统中翻译知识的同步增长,进而动态优化辅助译文,提高辅助翻译系统中人机交互的效率。实验结果表明,该方法是有效的,通过对同一篇文档的前30%文本进行辅助翻译,在后编辑过程中建立的用户行为模型可以使余下70%文本的辅助译文BLEU值提高4.9%。
本文建立的用户行为模型中,主要是选词方面的翻译知识,在下一步的工作中,我们将研究如何更深入地挖掘翻译决策数据,从中学习调序及其他更高层次的翻译知识。另外,在记录翻译过程时,本文的方法对于用户的翻译行为有一些限制和要求,未来的工作中,我们将研究如何在完全不干扰用户翻译过程的情况下,采集用户的行为。
[1] Nirenburg S. Machine Translation[M]. Cambridge University Press: 1987.
[2] Nagao M. A framework of a mechanical translation between Japanese and English by analogy principle[J]. Artificial and Human Intelligence, 1984: 173-180.
[3] Brown PF, Pietra SD. The mathematics of machine translation: Parameter estimation[J]. Computational Linguistics, 1993: 263-311.
[4] Koehn P, Och FJ, Marcu D. Statistical phrase-based translation[C]//Proceedings of the NAACL 2003. 2003: 48-54.
[5] Trados. Trados Translators Workbench, product description[R]. 1997.
[6] Eurolang. Eurolang Optimizer, product description[R]. 1999.
[7] 张桂平, 蔡东风. 翻译工作室[C]//2002年全国机器翻译研讨会论文集. 2002: 334-341.
[8] 姜柄圭, 张秦龙, 谌贻荣, 常宝宝. 面向机器辅助翻译的汉语语块自动抽取研究[J]. 中文信息学报, 2007, 21(1): 9-16.
[9] Martin Kay. The MIND system[J]. Natural Language Processing, 1973: 55-188.
[10] Langlais P, Foster G, and Lapalme G. TransType: a computer-aided translation typing system[C]//Workshop on Embedded Machine Translation Systems. 2000: 46-51.
[11] Langlais P, Sauvé S, Foster G, et al. Evaluation of TransType, a Computer-aided Translation Typing System: A comparison of theoretical- and user-oriented evaluation procedures[C]//Proceedings of Second International Conference on Language Resources and Evaluation. 2002: 641-648.
[12] Foster G, Langlais P, and Lapalme G. User friendly text prediction for translators[C]//Proceedings of EMNLP 2004, 2004: 148-155.
[13] Barrachina S, Bender O, Casacuberta F. Statistical approaches to computer-assisted translation[J]. Computational Linguistics, 2009, 35(1): 3-28.
[14] Elming J. Transformation-based corrections of rule-based MT[C]//Proceedings of the EAMT 11thAnnual Conference. 2002.
[15] Simard M, Goutte C, Isabelle P. Statistical Phrase-Based Post-Editing[C]//Proceedings of HLT-NAACL 2007. 2007: 508-515.
[16] Groves D. Identification and Analysis of Post-Editing Patterns for MT[C]//MT Summit XII. 2009.
