基于依存树库的文本聚类研究
2011-06-14冯志伟
高 松,冯志伟
(1. 黑龙江大学 文学院,黑龙江, 哈尔滨 150080; 2. 中国传媒大学 应用语言学研究所,北京 100024;3. 教育部语言文字应用研究所, 北京 100010)
1 引言
随着互联网的迅猛发展,网络上的信息量呈指数级增长,这给信息检索带来了严峻的考验。文本分类和文本聚类技术是信息检索研究的重要方面,其目标是帮助人们自动检索文本,判别文本属性类别,在文本中快速、准确地寻找有用信息[1-2]。特征选择是文本分类的前提。一个合理、有效的特征选择方法可以在数据预处理阶段去掉数据中的冗余,降低特征空间的维数,提高分类的效率。特征选择方法主要有文档频率、互信息、信息增益、卡方统计、信息熵等。这些方法的计算量较大,为了提高聚类的效率,算法被不断地改进[3-6]。
为了避免使用计算过程复杂的算法,并能整合利用语言学特征[7],从语言学的角度对特征选择和文本分类结果进行分析和解释,已有研究者提出了基于语料库和统计学的方法来获取语体的计量特征,并将这些特征用于文本聚类[8]。已有的计量描写仅涉及到了字、词、句层面,其他层面的描写较少涉及。本文将在句法关系层面,从依存树库中统计出现代汉语口语体和书面语体中具有显著差异的词类依存关系,作为文本的聚类特征来对陌生文本进行聚类分析。
本文结构的安排如下: 第2节介绍本文研究使用的资源和研究方法;第3节从依存树库中提取文本聚类特征;第4节给出实验结果及分析;第5节是对本文的总结。
2 资源与方法
2.1 依存树库
树库是指在词性标注的基础上,对每个句子加注句法关系的语料库。近年来,树库作为获得句法结构的知识源和评价句法分析结果的工具,越来越受到研究者们的重视[9]。树库是进行计算语言学研究的重要资源[10]。树库中含有的大量句法分布信息可为句法研究提供坚实的基础[11]。依存树库是一种依存语法标注的语料库,通过建立词语之间的联系来描述句法的结构,它以依存关系为基础。图1 为汉语句子“他是一名学生。”的依存句法结构图。
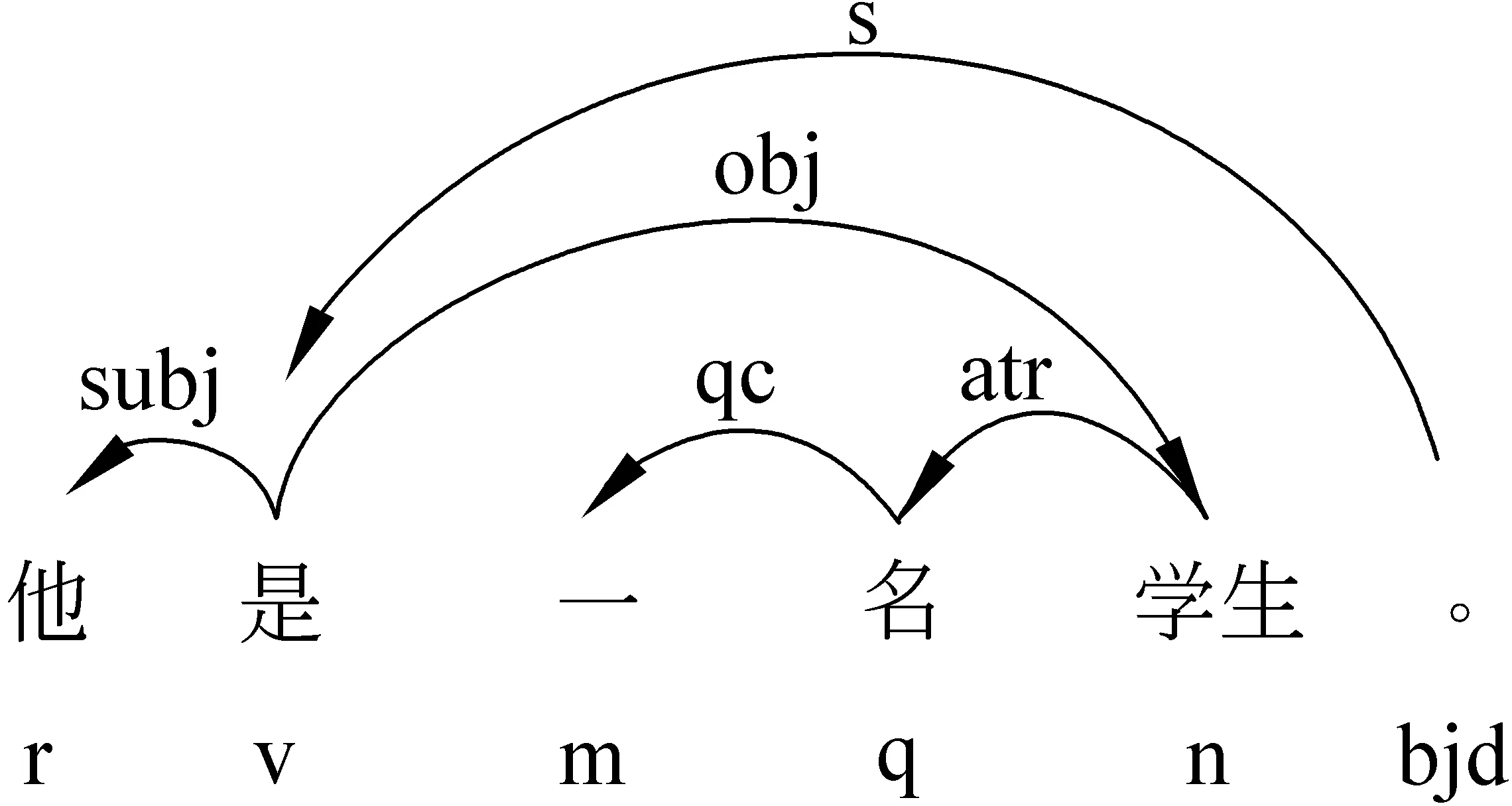
图1 “他是一名学生。”的依存句法结构图
由图1可见,依存关系是两个词之间一种有向的、非对称的关系。它具有三个组成部分: 支配词、从属词、依存关系标记。句子中的每个词都有自己的支配词,即它是受哪个词支配的,它依存于哪个词。把这种依存关系用符号标记出来,这些符号就是依存关系标记。图中带箭头的弧的起点为支配词,箭头指向的是从属词,弧上标记为依存关系标记。有关依存语法理论,可参见文献[11-13]。
本文使用的树库是中国传媒大学应用语言学研究所汉语依存树库(IAL-CUC CDT),它是面向有声媒体语言的依存树库。树库包含的语料为2007年电视台和广播电台31档节目的转写文本。电视节目如“新闻联播”、“实话实说”、“鲁豫有约”、“百家讲坛”等;广播节目如“新闻和报纸摘要”、“今日论坛”、“海峡时评”、“中国之窗”等。语料既包含新闻播报类又包含访谈会话类,涉及的范围和内容比较广泛。语体上,既有书面语体又有口语体。语料中共有3 600个句子,98 236个词次。文本进行了自动分词和词性标注,并采用依存语法对其进行了句法标注。为确保标注的一致性,对汉语的某些特殊结构,我们给出了统一的标注方法[14]。所有的标注结果都经过了人工和工具的核对校正。所用的汉语依存关系句法标注体系见文献[15]。我们从树库中选取10档节目的文本作为训练文本,10档节目的文本作为测试文本。以此来进行文本聚类分析实验。
2.2 方法
首先,我们对训练文本的语料进行语体分类。根据语体学理论[16],人工将训练文本的10档节目文本分成新闻类书面语体和谈话类口语体。接下来,在分属不同语体的依存树库中,提取汉语主要词类名词、动词、形容词、代词、副词、介词的依存关系。统计在不同语体中,各个词类做支配词和做从属词时所形成的依存关系,这些依存关系出现的频次和百分比。然后提取文本聚类特征。比较各词类依存关系在不同语体文本中的分布,提取具有显著差异的词类依存关系,也就是在训练文本中找到聚类特征候选集。并以独立样本T检验方法来检验这些差异在统计学意义上的显著性。最后,从聚类特征候选集中选择最终的聚类特征,对测试文本进行层次聚类分析实验。
3 提取聚类特征
我们在训练文本中,统计出名词、动词、形容词、代词、副词、介词做支配词和做从属词时所有的依存关系,并对各种依存关系按照语体的不同进行分类,找出了具有显著差异的10种依存关系,将这10种依存关系作为聚类特征的候选集。聚类特征候选集的分布数据见表1。
表1列出了训练文本的新闻类、谈话类语料中具有显著差异的10种依存关系、其均值(Mean)和标准差(standard deviation)。表中“<-”和“->”是依存关系符号,“<-”表示从属关系,“->”表示支配关系。名词n、动词v、代词r、形容词a、副词d是词类标记,定语atr、宾语obj、复数plc、主语subj、状语adva、标点符号punct是依存关系标记。这10种依存关系分别为: 名词为从属词做定语、名词为从属词做宾语、动词为支配词支配宾语、代词为支配词支配名词复数、代词为从属词做主语、代词为从属词做定语、形容词为从属词做定语、形容词为从属词做状语、副词为支配词支配标点符号、副词为支配词支配状语。这10种依存关系与语料所属语体的点二列相关(point-biserial correlation)系数均大于0,其中5种依存关系与语料所属语体的点二列相关系数大于0.6。它们是: 名词为从属词做定语、代词为从属词做主语、代词为从属词做定语、形容词为从属词做定语、副词为支配词支配标点符号。
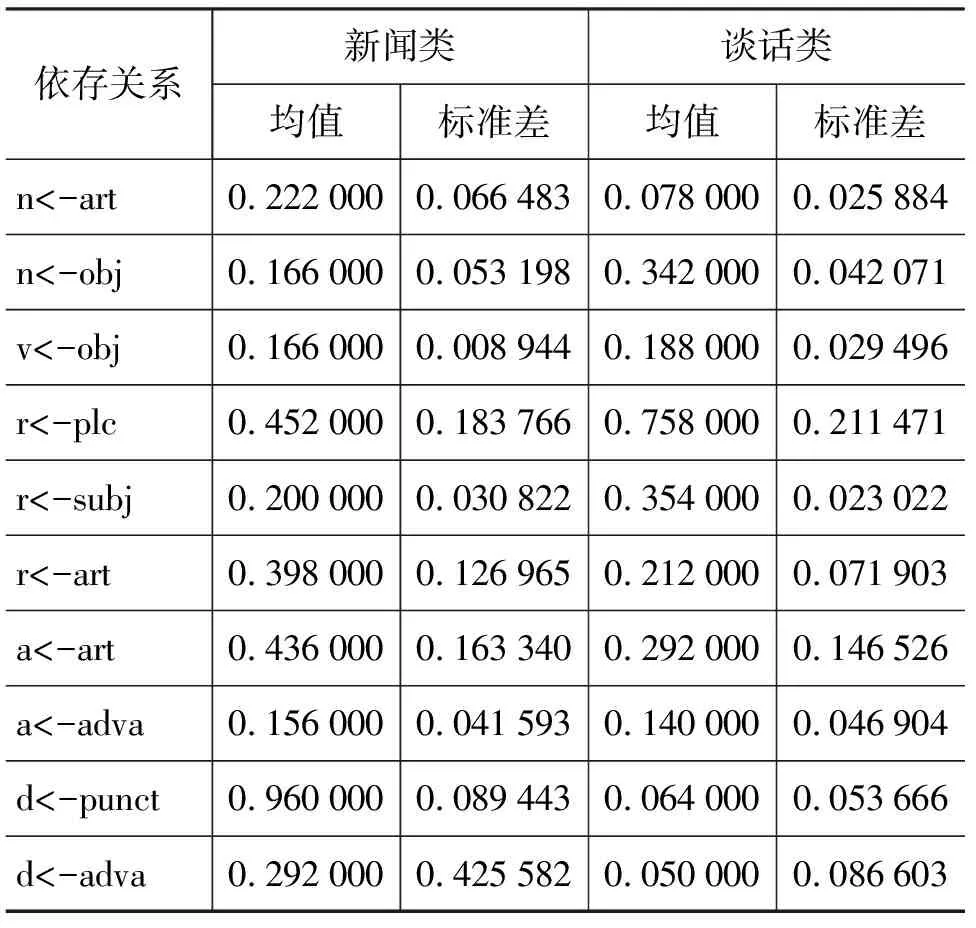
表1 训练文本中聚类特征候选集的分布数据
这5种依存关系在不同语体中具有显著差异,在语言学中我们尝试可以对其进行解释。
名词做定语在新闻类的语料中比例高于谈话类,原因是新闻播报中的多重定语多于谈话类,并且多重定语中名词作定语的情况很多。新闻播报属于书面语体,口语中的词较少使用,更多地使用书面语色彩浓重的词,如名词中最具书面语色彩的专有名词大量使用。像新闻语料中“农村党风廉政建设信息平台”这个名词短语,就是由多个专有名词做定语构成。
新闻播报中代词的使用有语体的限制,较少使用第一人称和第二人称代词,句首主语较多地使用专有名词,代词“各”作名词定语情况很多,如各地、各国、各人、各类等。谈话中人称代词的使用没有语体的限制,三种人称代词都使用,句首主语大多是人称代词,代词“各”做名词定语的情况不多。因此,谈话语料中代词做主语的比例比新闻语料高,代词做定语的比例比新闻语料低。
形容词做定语在新闻语料中的比例高于谈话类,其原因在语言学上较难解释,有待于从词性标注和依存关系分析的角度深入研究。
新闻类语料中,副词在句首做状语后面常常停顿,用标点符号逗号“,”表示停顿。如: “届时,”、“近来,”、“为此,”、“实际上,”等。我们对句子进行依存句法标注时,为了避免句子依存关系图中有交叉弧,也为了不影响对句子意思的理解,对句中标点符号的处理是: 让标点符号通过依存关系punct从属于它前面的成分。新闻类语料中,副词后带标点符号的例子比谈话类语料多,副词作为支配词支配标点符号的比例比谈话类语料高。
4 文本聚类实验及其结果分析
实验选用的语料是训练文本和测试文本中的20档节目文本。实验用的文本具体描述见表2。其中X1~X10为训练文本,C1~C10为测试文本。训练文本中X1~X5属于谈话类口语体,X6~X10属于新闻类书面语体。测试文本有的属于谈话类口语体,有的属于新闻类书面语体。训练文本和测试文本的长度大致相同。
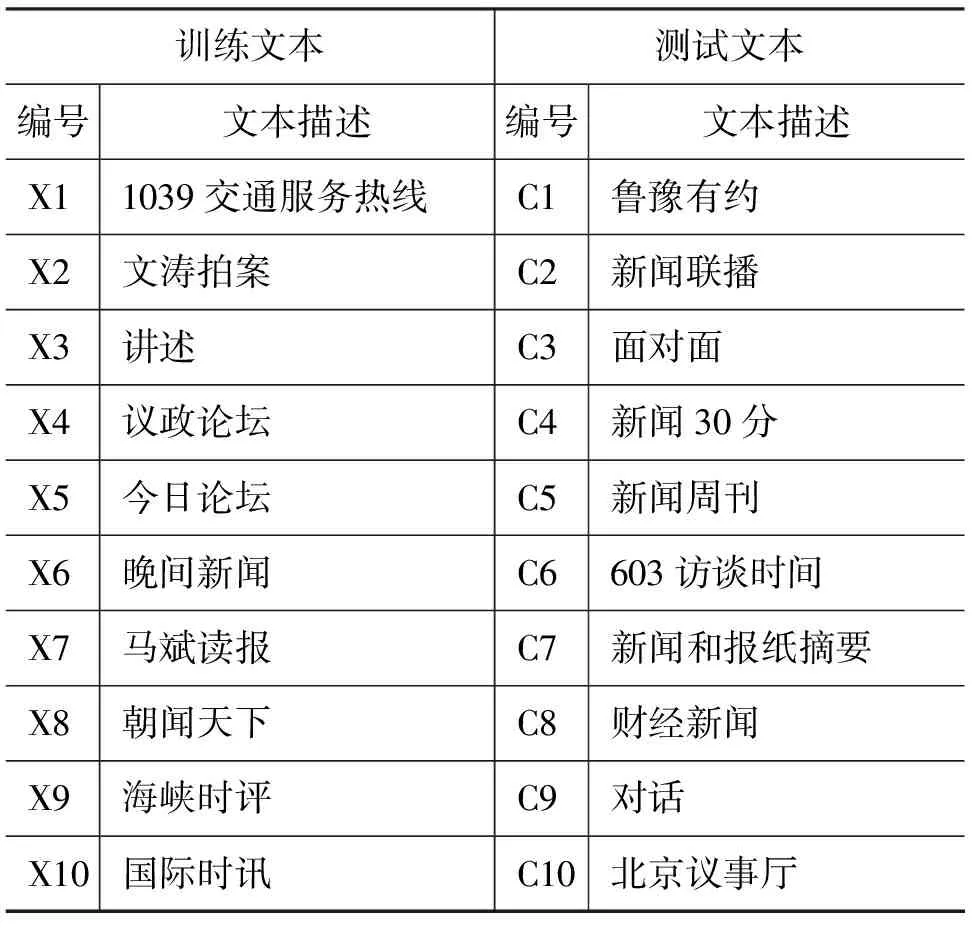
表2 训练文本和测试文本中20档节目文本描述
我们采用的统计分析工具是Minitab14 (similarity level=95%,single linkage method,Euclidean Distance Measure)。首先以10种依存关系作为聚类特征,对训练文本的10档节目文本进行文本聚类分析。图2为Minitab14环境下,对10种依存关系在训练文本中出现的概率进行统计的情况。其中C1-T是节目栏,X1~X10为训练文本的10档节目文本;C2~C11是10种依存关系在10档节目文本中出现的概率。如C2栏“n <- atr”表示支配词支配名词形成定语,这种依存关系10档节目中出现的概率。在X1节目中出现的概率是0.11,在X2节目中出现的概率是0.10,在X3节目中出现的概率是0.07,等等。
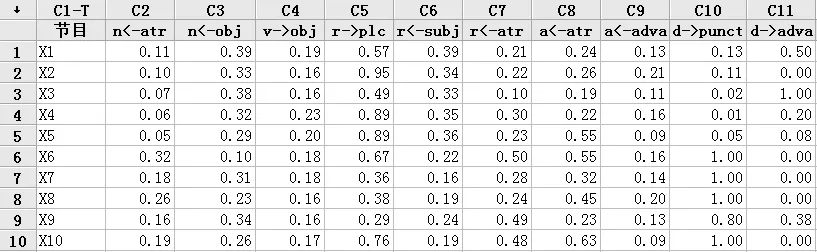
图2 10种依存关系在训练文本中出现的概率统计
根据统计出来的数据,可用Minitab14对文本进行聚类分析。以10种依存关系为聚类特征对训练文本进行聚类分析的树状图,见图3。又以5种与语料所属语体的相关系数大于0.6的依存关系作为聚类特征,对训练文本的10档节目文本进行聚类分析。实验方法同上,实验结果见图4。
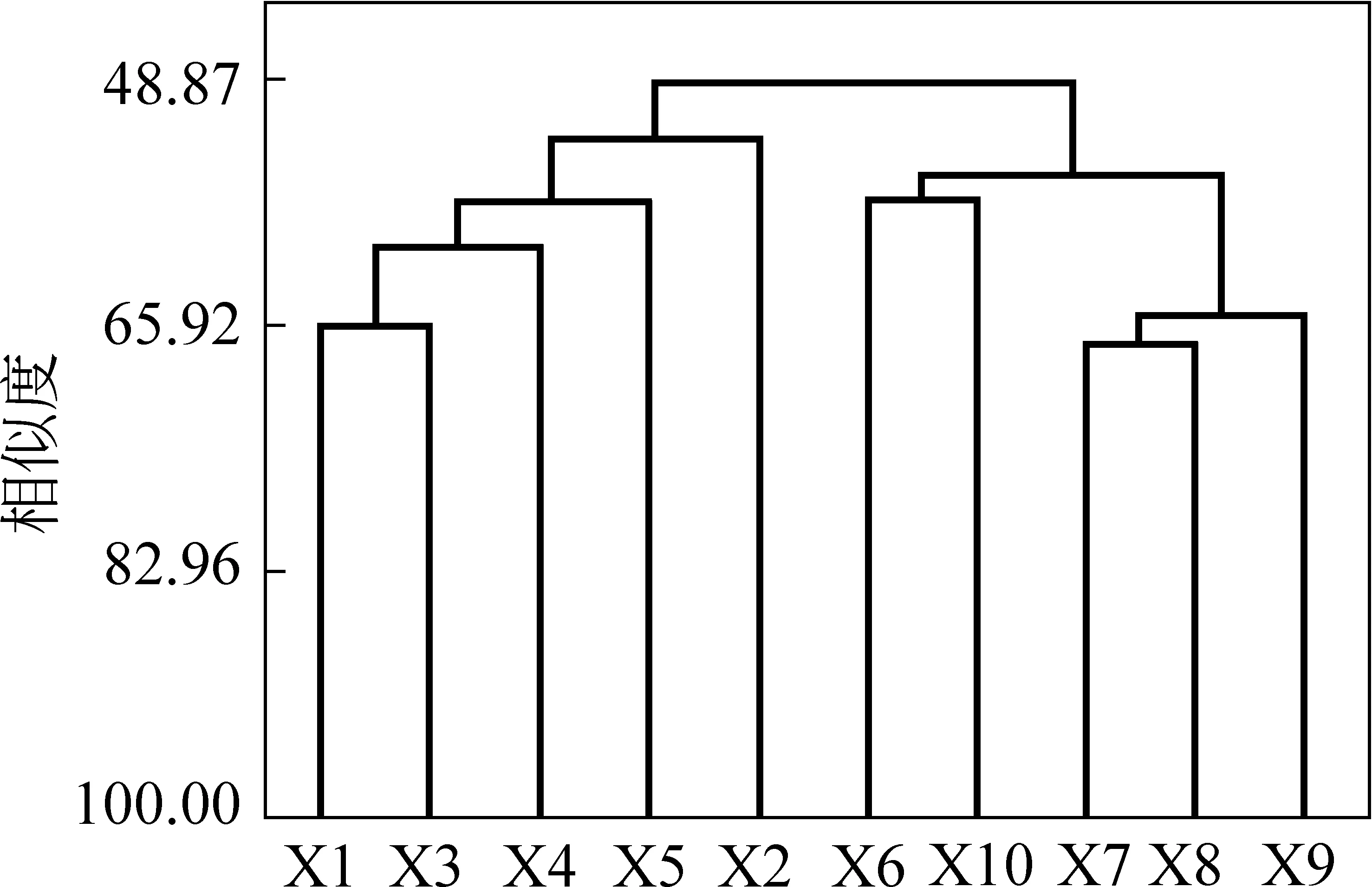
图3 10种依存关系为聚类特征对训练文本聚类分析的树状图
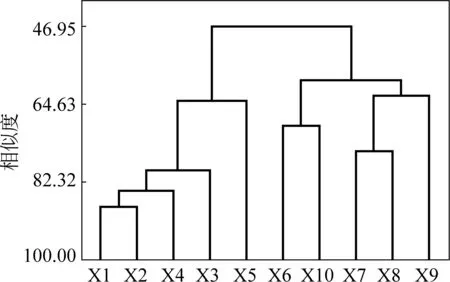
图4 5种依存关系为聚类特征对训练文本聚类分析的树状图
图3中,以10种依存关系作为聚类特征,5个新闻类书面语体文本的相似度是55.24%,5个谈话类口语体文本的相似度是52.79%。以这10种依存关系为聚类特征,可将文本根据语体的不同聚集在一起。图4中,以5种依存关系作为聚类特征,5个新闻类书面语体文本的相似度是59.12%,5个谈话类口语体文本的相似度是63.97%。值得注意的是,以10种依存关系为聚类特征,“1039交通服务热线”和“讲述”节目的相似度是65.71%,在5档谈话类口语体节目中,相似度最高;以5种依存关系为聚类特征,“1039交通服务热线”和“文涛拍案”节目的相似度最高,88.12%。原因有待于从聚类特征候选集中的依存关系来进一步考察。
对比10种和5种依存关系对文本进行聚类的效果,以5种依存关系作为聚类特征对文本聚类,文本相似度高于10种依存关系。因此,从聚类特征候选集中选择最终的聚类特征为5种依存关系。用最终确定的聚类特征来对测试文本进行文本聚类实验。实验结果见图5。
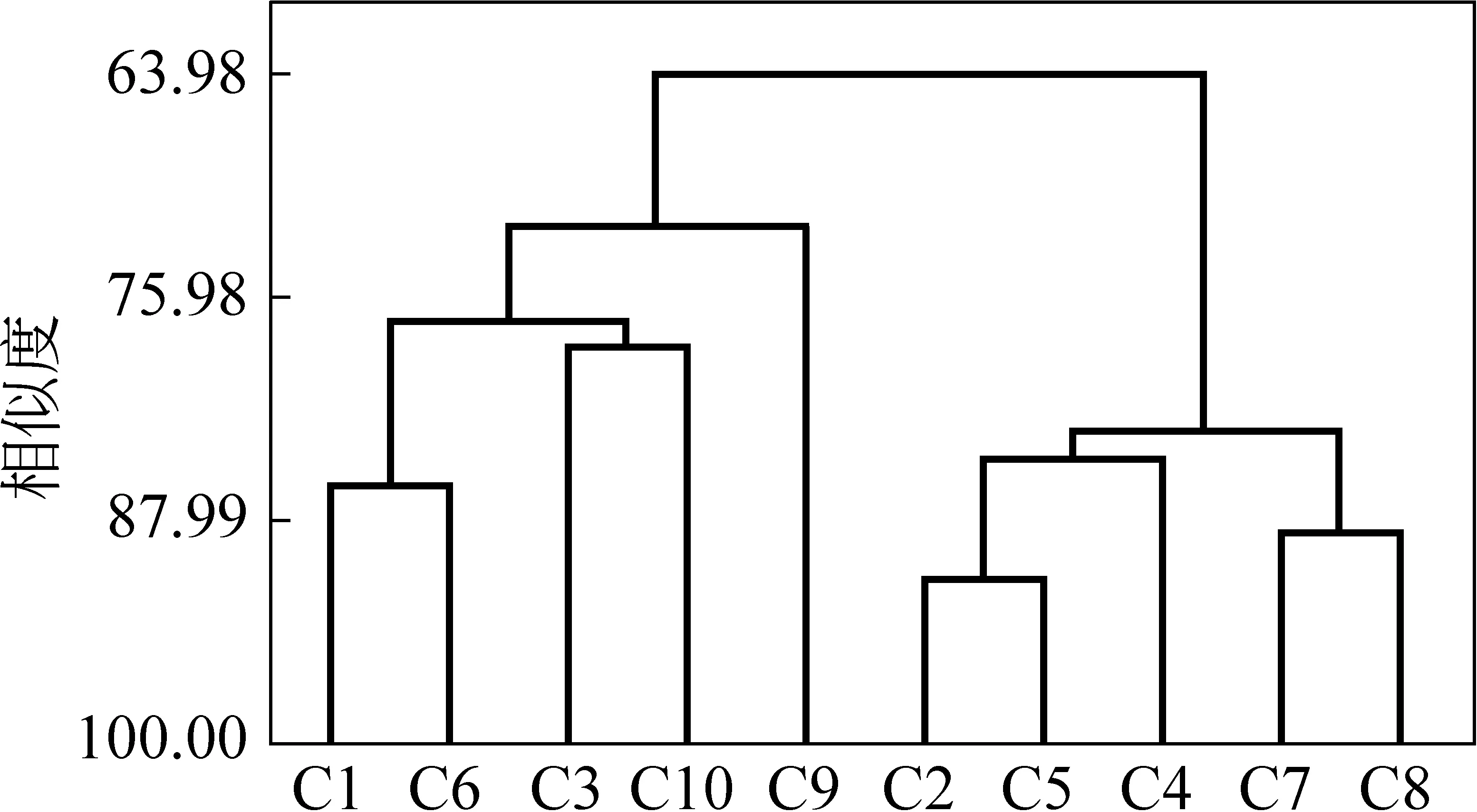
图5 5种依存关系为聚类特征对测试文本聚类分析的树状图
图5中可以看出: “鲁豫有约”、“603访谈时间”、“面对面”、“北京议事厅”和“对话”节目准确地聚集在一起,它们的相似度是71.98%。这5档节目都属于谈话类口语语体。“新闻联播”、“新闻周刊”、“新闻30分”、“新闻和报纸摘要”、“财经新闻”节目准确地聚集在一起,它们的相似度是83.13%。这5档节目属于新闻类书面语体。以5种依存关系为聚类特征,对实验文本聚类的效果比较好。
5 结论
本文针对在句法层面对文本按照语体进行聚类的问题,提出了基于依存树库来进行文本聚类的方法。在依存树库中,提取出现代汉语主要词类的依存关系,通过对比各依存关系在不同语体中的分布,得出10种具有显著差异的词类依存关系,将其作为聚类特征候选集,来进行文本聚类分析实验。实验结果证明: 利用依存树库中的句法信息对文本进行聚类这种方法的可行性和有效性。以名词作定语、代词作主语、代词作定语、形容词作定语、副词支配标点符号这5种依存关系作为聚类特征,文本聚类的效果比较好,测试文本中谈话类、新闻类文本的相似度分别是71.98%和83.13%。下一步我们将扩充聚类特征候选集,提取汉语中非主要词类的依存关系,得出在语体分布上具有显著差异的依存关系,更准确有效地进行文本聚类。
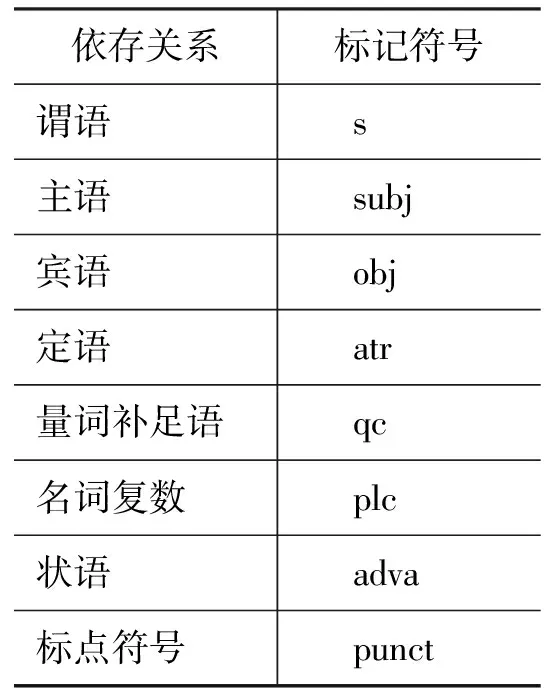
附录 依存关系及其标记符号
词性及其标记符号
[1] 刘挺,秦兵,张宇,车万翔. 信息检索系统导论[M].北京:机械工业出版社, 2008.
[2] 孙建军,成颖,等. 信息检索技术[M]. 北京:科学出版社, 2004.
[3] 曾依灵, 许洪波, 白硕. 改进的OPTICS算法及其在文本聚类中的应用[J].中文信息学报,2008,22(1): 51-60.
[4] 何婷婷, 戴文华, 焦翠珍. 基于混合并行遗传算法的文本聚类研究[J]. 中文信息学报,2007,21(4): 55-60.
[5] 谷波, 李济洪, 刘开瑛. 基于COSA算法的中文文本聚类[J]. 中文信息学报, 2007,21(6): 65-70.
[6] 肖婷,唐雁.改进的Х2统计文本特征选择方法[J].计算机工程与应用, 2009,45(14): 136-137.
[7] 赵世奇, 刘挺, 李生. 一种基于主题的文本聚类方法[J]. 中文信息学报, 2007,21(2): 58-62.
[8] 黄伟,刘海涛. 汉语语体的计量特征在文本聚类中的应用[J].计算机工程与应用,2009,45(29):25-33.
[9] Abeillé, A. Treebank: Building and using Parsed Corpora [M]. Dordrecht: Kluwer.2003.
[10] Nivre, J. Dependency Grammar and Dependency Parsing [R]. (MSI report) Växjö University: School of Mathematics and Systems Engineering, 2005.
[11] 刘海涛. 依存语法的理论与实践[M]. 北京:科学出版社, 2009.
[12] 冯志伟. 特思尼耶尔的从属关系语法 [J]. 国外语言学,1983, (1): 63-65.
[13] Hudson, R.A. Language networks: The New Word Grammar [M]. OXford: OXford University Press, 2007.
[14] 高松,赵怿怡,刘海涛. 汉语特殊结构的句法标注策略[C]//中国计算语言学研究前沿进展(2007-2009).北京:清华大学出版社, 2009:142-147.
[15] Liu H, Huang W.A Chinese Dependency Syntax for Treebanking[C]//Proceedings of The 20th Pacific Asia Conference on Language, Information and Computation. Beijing: Tsinghua University Press, 2006:126-133.
[16] 袁晖,李熙宗. 汉语语体概论[M]. 北京:商务印书馆, 2005.
