唐代以来汉语文学作品中的字频演变
2011-06-14刘宇凡郭金忠陈清华
刘宇凡,郭金忠,陈清华
(1. 石家庄经济学院 人文社科学院,河北 石家庄 050031;2. 北京师范大学 管理学院,北京 100875)
1 引言
人们很早就发现,文学作品或者文集中的基本组成单元或元素并不是等概率出现的,少数的字和词使用非常频繁,而只出现一次的字和词非常多。这种特定的统计分布形式具有非常强的普适性,存在于不同地区不同时期多种语言之中。这种统计研究除了在理论上讨论语言的共性外,其结果也具有实际应用价值,例如它可以应用于语言信息的计算机化处理,包括文本的压缩、输入法的编码等,以及目前比较流行的文本自动分析和处理,还可以用于语言学习材料的组织和其他方面,如小学课本中常用字词的选取等。
语言的统计研究可以追溯到很久以前,古印度语法学家在研究《吠陀》时,就进行过单词和音节数目的统计。1898年德国学者Kaeding编制了世界上第一部频率词典《德语频率词典》。1935年和1949年哈佛大学语言学家Zipf先后出版了两本著作[1-2],提出了著名的Zipf规律(或齐夫定律)。他在总结前人统计发现的基础上,指出在文集中词的出现不是等概率的,它们满足这样的形式:p(r)=Cr-β,其中P(r)为排序在第r位置的词出现的频率,β为Zipf指数,C为常数。后续一些研究发现西班牙语、法语、爱尔兰语[3]、希腊语[4]、印度语[5]、土耳其语[6]均满足这种分布特征,甚至现在已经灭绝的语言也是如此[7]。随着计算机技术的发展,对语料库的统计工作变得非常简单,这方面的研究工作变得更容易进行。
但对于汉语来说,这种基本元素的统计非常特殊。汉语具有两个基本单元,一个是字(character或ideogram),另一个词(word)。这两方面的统计研究工作历史上都有过一些,例如,1975—1976年,北京新华印刷厂等19个单位发动了1 500名中学生对出版物中的2 162万字的材料进行统计,编成《汉字频率表》;中国“七四八”工程查频组首次利用计算机对汉字的频度进行统计,得出《现代汉字综合使用频度表》;1990年,Zhao对统计结果尝试进行了曲线拟合,发现字频分布具有半指数半幂律特征[8];1999年,关毅等人以当时Internet网上的中文字频统计共享资源为对象进行统计,发现在现代汉语的字、词、二元对等层次结构上,同样存在Zipf形式的频度——频级关系[9]。2003年,Ha等人讨论了单个汉字和汉字多元对的分布,发现单个汉字不服从Zipf分布,而多元对的分布近似服从Zipf规律,这与英文多元对的分析情况是一致的[10]。
这些工作都是针对同一个时期的文字材料,缺乏对于字词使用的动态分析。2005年,Wang Dahui等人首次发现字频随着历史发展存在变化,他们对中国不同时代的文献著作分别进行了分析[11],统计了甲骨文、青铜器上的铭刻、《诗经》、《尔雅》、《毛泽东选集》、《亮剑》等文学作品中的汉字使用分布,发现汉字的使用分布在不同时代具有显著差异,早期的中国文献的字的频数和排序关系是满足Zipf分布的,而晚期(秦朝以后)的文献并不满足这个分布,而更多地表现出指数的特征。Da Jun的统计也发现现代汉语和古代汉语在字频使用上存在差异[12]。那么,历史上字频是一次性突变还是经历了一个变化过程?这是一个有趣的问题。讨论历史上各个时期文字材料(本文选取自唐以来的各个历史时期汉语文学作品)中字频分布的精确性质及其演变,可以为我们更加深入研究汉语言的演变提供重要依据。
2 语料库
中国历史上的很多时期有其代表性的文学样式,其发展顺序大致为: 诗经→楚辞→先秦散文→汉赋乐府→魏晋骈文→唐诗→宋词→元曲→明清小说。其中,唐诗、宋词、元曲和明清小说是其中的杰出代表,留存也较为齐全。我们从互联网(如天涯在线书库http://www.tianyabook.com/等)上获得了如下材料建立语料库,如表1所示。

表1 统计材料说明
其中全唐诗共 900卷,收录唐代和五代诗篇 48 900余首,作者2 200多人。全宋词收集词人1 300多人,词作19 900余篇。明清小说文集我们选择四大名著(即《三国演义》、《水浒》、《西游记》和《红楼梦》)。网络小说来源于互联网写手所创作的最新小说,我们从Google网络小说排行榜(http://www.google.cn/rebang/)上随机选取了2009年4月20日上榜的50篇中的10篇文章,如《长生界》、《坏蛋是怎样炼成的》、《鬼吹灯》,其中一些小说还在连载中而没有终稿。我们在统计字频之前去除了文集中的所有标点符号、阿拉伯数字和英文字母,只保留了汉字字符。
3 字频的简单统计
经过简单统计发现,不同的字在同一个文集中出现的次数有很大差异,如全唐诗中 “花” 出现 11 356 次, “明” 出现6 818次,“话”出现518次,而“神”只出现了1次。此外,不同语料库中同样的字出现的绝对次数不一样,如全唐诗中“不”字出现 26 502 次,而全宋词中出现10 177次,在四大名著小说中共出现38 983次,它们的相对频率也不同,如表2所示。
表2列出了我们所讨论的5个文集中出现最多的20个字及其频率,其频率的值越大说明在文集中出现的次数越多。全唐诗中“日”的频率为 0.005 75,意味着在唐诗文集中平均每174个字中会有一个“日”字。我们可以看出不同文集中出现最多的20个字不完全相同,但文集的对应时期越近,列表中相同的字数越多,且顺序更一致。对所有5个文集来讲,有5个字都在出现频率最高的前20名内,它们是“不”、“一”、“来”、“人”和“有”。为定量衡量这个差异,我们使用Shlomo Havlin在1995年提出的计算两个概率序列距离的公式。

表2 字频统计
其中λ表示两个序列i,j中都有的字,ri(λ)表示在序列i中的位置,N为λ的个数,即两个序列中包含的相同的字的个数。结果如表3所示,说明较近时期的文学作品对汉字的使用具有更大的相似性。元曲和明清小说的差别最小,而唐诗和现代网络小说在汉字的使用习惯上差别最大。

表3 不同文集字频序列的距离
4 字频分布的性质及拟合
在语言方面的研究工作中,常常将字频或者词频按大小顺序从左到右排列起来,横轴为所在的位置序号,纵轴为这个字/词出现的频率。如图1所示,图中的曲线自上而下分别为全唐诗、全宋词、全元曲、明清小说和网络小说。采用的坐标为纵轴为对数坐标,图形右端类似直线,表现出很强的指数特征,即字频的下降速度很快。图形右上角的子图为Zipf图,即为双对数坐标。左端具有一定的线性规律,表示字频具有一定的幂律特性。唐诗和宋词幂律部分较为接近,宋词和元曲在指数部分比较接近,即唐诗和宋词在高频词的使用频率上比较接近,而宋词和元曲在低频词的使用频率上更为相似,网络小说的词频则呈现出两个极端。
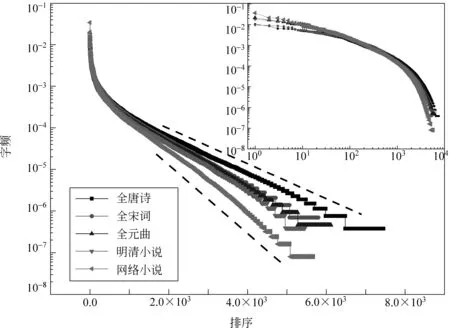
图1 汉字字频的Zipf图形

图2 唐诗和现代网络小说文集的字频拟合
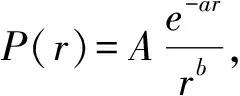
我们用这个函数对实证数据进行拟合。为了减少拟合过程中对高端数据偏差带来的惩罚效应,我们采用logP(r)=logA-ar-blogr使用Matlab中的nlinfit函数进行拟合,得到较好的拟合效果,如图2所示,是我们对全唐诗文集和现代网络小说文集中字频统计的拟合结果。除了在高频部分存在一定的偏差外,拟合曲线很好地符合了实证数据。
拟合过程得到的参数估计如表4所列。

表4 字频拟合的参数结果
以上参数中,a描述的是指数特性,而b描述的是幂律特性。整体看,随着历史的发展,汉语文学作品中字的使用频率的衰减指数特性增强,幂律特性减弱。唐诗、宋词、元曲具有更大的相似性。
5 结论
本文讨论了自唐代以来各个历史时期文学作品中汉字的使用情况。自秦始皇统一中国的文字以来,汉字的书写方式和种类相对固定。讨论汉字使用习惯的演变是一个很有意义的事情,可以帮助我们深入了解汉语言的变迁,并对将来汉字的发展情况做出预期。我们的讨论结果表明,汉字的使用在不同历史时期存在差异,相近的历史时期汉字的使用习惯更具有一致性,并且幂律特性逐步减弱而指数特性逐渐增强。这个原因可能是因为在历史早期,人们往往用一个汉字(即单音节词)来表达意思,而随着历史的发展,人们更多采用多音节词来表达意思。具体如何造成指数特性增强而幂律特性减弱还需要进一步讨论。
[1] Zipf G K. The Psycho-Biology of Language[M]. Boston:Houghton Mifflin, 1935.
[2] Zipf G K. Human Behavior and the Principal of Least Effort[M]. Cambridge :Addison-Wesley,MA,1949.
[3] Ha L Q, Stewart D, Hanna P. Zipf and Type-Token rules for the English, Spanish, Irish and Latin languages[J]. Web Journal of Formal Computational & Cognitive Linguistics, 2006, http://fccl.ksu.ru/issue8/ha_fccl_zipf.pdf.
[4] Hatzigeorgiu N, Mikros G, Carayannis G. Word length, word frequencies and Zipf’s law in the Greek language[J]. Journal of Quantitative Linguistics,2001,8(3):175-185.
[5] Jayaram B D, Vidya M N. Zipf’s law for Indian languages [J]. Journal of Quantitative Linguistics, 2008,15(4): 293-317.
[7] Smith R D. Investigation of the Zipf-plot of the extinct Meroitic language[J]. Glottometrics, 2007, 15:53-61 .
[8] Zhao Kaihua. Physics nomenclature in China[J]. American Journal of Physics 58(5) (May 1990) 449-452.
[9] 关毅,王晓龙,张凯.现代汉语计算语言模型中语言单位的频度一频级关系[J].中文信息学报,1999,13(2):8-15.
[10] Ha L Q, Sicilia-Garcia E I, Ji Ming. Extension of Zipf’s law to words and character N-gram for English and Chinese[J]. Computational Linguistics and Chinese Language Processing, 2003,8(1):77-101.
[11] Wang Dahui, Li Menghui, Di Zengru. True reason for Zipf’s law in language[J]. Physica A, 2005, 358(2-4):545-550.
[12] Da Jun. A corpus-based study of character and bigram frequencies in Chinese e-texts and its implications for Chinese language instruction. In Zhang, Pu, Tianwei Xie and Juan Xu. (eds.). The studies on the theory and methodology of the digitalized Chinese teaching to foreigners[C]//Proceedings of the Fourth International Conference on New Technologies in Teaching and Learning Chinese: 501-511. Beijing: Tsinghua University Press.
