基于中心语匹配的共指消解
2011-06-14张牧宇黎耀炳
张牧宇,黎耀炳,秦 兵,刘 挺
(哈尔滨工业大学 计算机学院信息检索研究中心,黑龙江 哈尔滨 150001)
1 引言
现实世界中同一个事物经常会有不同的名称以及描述,我们称这些名称以及描述称为“表述”(Mention),称这些表述所对应的事物为“实体”(Entity)。所谓的共指消解(Co-reference Resolution),就是根据一篇文档中各个表述的内容以及上下文信息将这些表述对应到具体实体的过程[1-2]。实质上,共指消解是一个对所有表述进行等价类划分的过程,它可以使隐藏在陈述中的等价关系变得清晰,这对于信息抽取、信息检索、机器翻译等上层应用的进一步发展是非常有帮助的。
近20年来,共指消解研究受到了特别关注,大多数计算模型和实现技术都是这一时期出现的。随着MUC、ACE、ARE等共指消解相关国际评测相继开展,共指消解得到快速的发展。
对共指消解的研究,无论是早期基于语言学规则的方法,还是近些年来基于统计机器学习的研究体系[3-4],都离不开对高质量特征信息的依赖。但当前NLP底层预处理效果不尽如人意,随着添加特征的增多,因前期预处理错误而产生的特征抽取错误也会增多。一些研究者通过特征筛选解决此问题,但这仅限于去除一些准确率较低的特征,仍不能去除那些预处理阶段已经产生的错误对训练数据的污染。
针对这些问题,本文提出基于中心语匹配的共指消解新方法,用于在消解过程中消除预处理过程中产生的部分错误,并捕获一些语义互斥的搭配信息,在使用相同信息的情况下,得到优于传统机器学习方法的共指消解效果。本文的第2节介绍共指消解的相关研究工作,第3节具体介绍一种简单、有效的基于平面特征的实例匹配算法用于共指消解,第4节提出一种“竞争模式”将中心语特征融入到实例匹配算法当中,第5节介绍实验设置以及实验结果与分析,第6节给出结论。
2 相关研究工作概述
共指消解的早期阶段,以基于语言学方法的研究思路为主,代表方法是Hobbs算法[8]以及中心理论[9]。他们大多使用了大量的语言学规则,而规则的有效性决定于规则的表达能力和可满足性。具体地说,规则前提的可满足性与NLP预处理效果密切相关。但即使是目前的研究水平,NLP底层预处理仍有诸多不如人意的地方。这迫使上世纪末,研究者开始转向各种鲁棒性更强的基于向量相似度计算的聚类方法以及基于二元对的机器学习分类方法。
基于二元对的机器学习分类方法,将共指消解这样一个等价类划分问题转化为任意两个表述是否存在共指关系的问题。在这种典型的二元分类框架[2]下,存在共指关系的两个表述中,靠前的都称之为“先行语”,靠后的都称之为“照应语”。
本世纪初以Soon等人为代表[3-4],在这种二元分类框架下,采用基于统计的机器学习方法研究共指消解问题。这些方法采用一系列和共指现象相关的信息作为机器学习算法的特征信息,经典的有如Soon等人于2001年总结提出的12个语义、词汇特征[3]。随后Ng等人[4]于2002年对Soon使用的12个特征进行了扩展,共使用了53个特征,涵盖了语义词汇等各个方面,取得了很好的共指消解效果。这一类特征均取离散值或者连续数值,常称之为“平面特征”。
近几年基于机器学习的研究方法开始进一步挖掘利用字符串匹配信息[5],将更多的结构化特征[6]融合进机器学习过程,甚至使用更多的背景语义知识作为特征信息[7]。有的研究者则尝试使用分类器组合策略[10]增强现有特征下的分类器消解效果。
这些根据训练数据特征信息拟合分类模型的机器学习方法,并没有进一步考虑预处理错误对训练数据造成的污染。对这种级联错误的解决办法,NLP领域目前较流行的解决办法是使用统一的语言模型,但这需要对NLP各部分预处理都要较深入的了解,在共指消解这个子任务上尚未有成熟的解决方案。
本文针对以上问题,提出基于中心语匹配的共指消解办法,希望在共指消解的过程中消除预处理过程产生的部分错误,并捕获一些语义互斥的搭配信息,在实验验证中取得了较好的结果。
3 基于平面特征的实例匹配算法
为了保证基于中心语匹配的共指消解效果,并且由于本文的研究重点不在于平面特征的丰富性,故本文采用了Soon等人总结提出的12个平面特征作为基础特征集。
基于平面特征的实例匹配算法,其核心思想是从训练实例中寻找那些与测试实例最相似的实例,并根据相似实例的类别分布给出测试实例属于某个类别的置信度。
本文将实例间的相似度定义为两实例拥有相同特征取值的个数。在寻找那些与测试实例最相似的实例过程,我们希望有不少训练实例的特征取值与测试实例的特征取值完全一致,并且这些实例全为正例(或反例),此时便能以置信度1 将测试实例判定为正例(或反例)。但实际情况中常常出现两类偏差:
(1) 不存在特征取值与测试实例完全一致的训练实例。
对于这类偏差,可称之为匹配失效,产生的原因有二: 其一,测试实例某个特征取值未曾在训练实例中出现过;其二,测试实例的特征取值在不同的训练实例上出现过,但没有任何一个训练实例的特征取值与测试实例完全一致。总的说来,这是由于数据稀疏造成的。
(2) 特征取值与测试实例完全一致的训练实例的类别分布过于均匀。
对于这类偏差,一方面,在于现有特征的表现力不足,不足以有效区分两种类别;另一方面,在于训练数据受到污染,特征抽取不准确。
由于以上两类偏差的存在,使用全部特征取值挑选与测试实例最相似的训练实例是不明智的,需要对完全匹配的要求进行修改以适应实际应用。本文设计的基于平面特征的实例匹配算法,利用决策树算法[11]中使用的“信息熵”(Information Entropy)作为选择函数,通过贪婪思想挑选与测试实例最相似的训练实例。
“信息熵”描述了一个带类别标签的样本集中类别分布的均匀程度,“信息熵”越大表明各类别样本的数量差别越小,从中随机抽取一个样本并成功将其判定为某一类的概率越低。在样本集S中只有两类情况下,若样本集中类别为“P”(Positive)和“N”(Negative),相应的样本数量分别为p与n,则“信息熵”具体表示如下:
(1)
可以证明,当p=n时,信息熵为1;而p=0或n=0时,信息熵为0。
以下具体描述基于平面特征的实例匹配算法:
算法1基于平面特征的实例匹配算法
输入: 抽取了平面特征的训练实例库、待测试实例
输出: 待测试实例的正例置信度
(1) 定义“特征取值对”为“<特征名,取值>”,测试实例i的所有“特征取值对”构成未使用的特征取值列表L,所有训练实例构成候选实例集D;
(2) 从L中选择一个“特征取值对”e,使得实例集D中满足该e要求的子集D′的信息熵I(D′)最小,并令D=D′,从L中删除e;
(3) 若I(D)=0或L为空,返回训练实例子集D,及其中正例所占比例p/(p+n)作为测试实例i的正例置信度;否则返回步骤(2)。
可以看到以上基于平面特征的实例匹配算法将寻找匹配实例的过程,转化为通过贪婪方式选取“特征取值对”并筛选训练实例的过程,最终算法返回了局部优化的匹配结果,并通过训练实例的类别分布给出正例置信度。
该实例匹配算法设计思路简单,但如表2和表3 所示的实验结果所示,在简单平面特征集上取得了与传统机器学习方法Maxent(最大熵)、J48(决策树)和SVM(支撑向量机)相当的共指消解效果。
对实验结果进行详细分析后发现,上述算法1产生的错误中,存在命名实体识别错误和先行语与照应语语义互斥两类现象:
(1) 命名实体识别错误
对于同一领域的语料或者文本,常使用同一命名实体识别(NER)工具及名词短语抽取工具从文本中抽取待消解的候选表述。但由于这些工具往往出现不同程度的识别错误,而相同的识别错误会反复发生在训练和测试阶段。如我们在实验时曾发现,现使用的NER工具及名词短语抽取工具常将ACE2005英文语料上的“news”识别为候选先行语或照应语,但“news”单词不在ACE语料考察的实体类型范围之内。类似的错误还包括曾反复将“the game”、“tuesday night”等作为照应语。
(2) 语义互斥的搭配
在ACE新闻语料中,“We”与“them”分别是第一和第三人称代词,而前者常指新闻报道员或评论员,绝大多数情况下两个表述不应该存在共指关系。当这两个表述在同一句子出现,且明显满足单复数一致性,这导致在缺少更多背景知识的情况下,无法正确将其判定为反例,进而做出错误的决定。
事实上,这两类错误信息可以通过后续融合中心语特征的实例匹配算法加以捕获利用。
4 融合中心语特征的实例匹配算法
如上节所述,基于平面特征的实例匹配算法无法有效识别“命名实体训练错误”和“语义互斥的搭配”两类错误。通过增强命名实体与名词短语抽取模块可以减少第一类错误,但短期内这类错误很难得到彻底解决;对于第二类错误,容易想到的解决办法是从训练数据中挖掘这些语义互斥的搭配模板,但模板挖掘依赖于频率计算,一些出现次数较少但语义上同样明显不相容的名词短语对很难被充分挖掘。
实际上,通过实例匹配算法直接查找那些与测试实例拥有相同中心语的训练实例,则能根据这些训练实例的类别分布做出正确的判断,从而有效地解决这两类问题。下面进一步通过强制约束与协商约束两种方式,将中心语约束信息融合进实例匹配算法。
4.1 基于中心语的强制约束
如上所述,通过中心语字符串的表面约束能正确识别出部分反例,而实际上融合中心语特征与平面特征还能增加一些隐含的匹配约束信息,这是实例匹配过程所需要的。有鉴于此,我们在此增加两个中心语字符串特征,具体分别为“AntHead”(先行语的中心语字符串)和“AnaHead”(照应语的中心语字符串) ,其直接以字符串的形式作为一个特征取值,具体内容和长度视情况而定,对长度没有限制。如上面的实例“
基于中心语强制约束的实例匹配算法如下:
算法2基于中心语强制约束的实例匹配算法
输入: 抽取了平面特征和中心语特征的训练实例库、待测试实例
输出: 待测试实例的正例置信度
(1) 定义“特征取值对”为“<特征名,取值>”,测试实例i的所有“特征取值对”(不包括中心语特征)构成未使用的特征取值列表L,所有训练实例构成候选实例集D;
(2) 从D中选择与测试实例在“AntHead”特征上取相同值的所有实例子集D′,如果D′为空集,直接跳到(4);否则,令D=D′;
(3) 从D中选择与测试实例在“AnaHead”特征上取相同值的所有实例子集D′,如果D′为空集,直接跳到(4);否则,令D=D′;
(4) 从L中选择一个“特征取值对”e,使得实例集D中满足e要求的子集D′的信息熵I(D′)最小,并令D=D′,从L中删除e;
(5) 若I(D)=0或L为空,返回训练实例子集D,及其中正例所占比例p/(p+n)作为测试实例i的正例置信度;否则返回步骤(4)。
与算法1相比区别在于,算法2首先利用“AntHead”和“AnaHead”对训练实例集进行筛选,随后再使用平面特征进一步挑选实例。为了验证算法2的效果,我们在小数据集(ACE2005英文BNews语料,16篇训练语料,10篇测试语料)上测试了的共指消解效果,具体结果见表1。
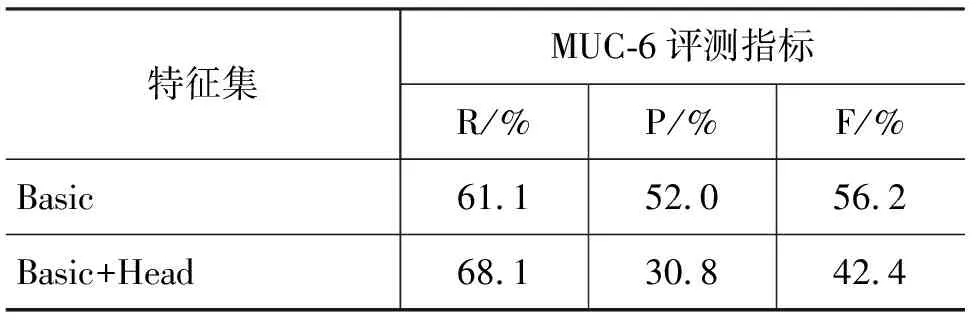
表1 小数据集上的实验结果
如表1所示,“Basic”表示Soon等人提出的12个平面特征,“Basic+Head”表示12个特征再加上前面定义的“AntHead”、“AnaHead”两个中心语特征。可见,虽然增加了中心语特征,算法2在 MUC-6 评测标准的F值上比算法1低很多。显然,这种组合使用平面特征与中心语特征的方式过于粗糙,下面我们将针对出现的一些问题对其进一步改进。
4.2 基于中心语的竞争模式
4.2.1 强制约束的错误分析
对算法2与算法1的结果进行详细对比后发现: 虽然算法2能够有效解决以上所述两类错误,但由于算法2中步骤(2)、(3)硬性引入中心语过滤操作,反而使噪声信息被放大。具体地说,算法2引入中心语过滤操作后,产生两类差异:
(1) 坏的差异: 原被算法1正确分类的实例,现被算法2错误分类。
这主要是由于中心语约束过于严格,经过中心语过滤后剩余的训练实例偏少,呈现严重的数据稀疏性。后续以信息熵为选择函数通过贪婪方式选取“特征取值对”,会使过滤后剩余的实例变得更加少,并且此时类别分布极不均匀。这相当于只使用很少的平面特征便给出类别判定,一旦这几个实例的特征取值出现噪声,便造成类别判定出现截然相反的结果。
(2) 好的差异: 原被算法1错误分类的实例,现被算法2正确分类。
这主要是由于算法2专注于解决上述两类错误,并希望引入更多隐含的深层匹配约束信息所得到的收益,是我们所希望看到的。
4.2.2 竞争模式
我们希望去除大部分“坏的差异”,保留“好的差异”。在一定的条件下我们使用算法2的结果,而在另外的情况下我们使用算法1的结果,以这种思想为基础,我们引入“竞争模式”这种相对柔和的协商约束方式。
算法3竞争模式
(1) 在Basic+Head特征集上利用算法2获取与测试实例最匹配的训练实例子集D2;
(2) 在Basic特征集上利用算法1获取与测试实例最匹配的训练实例子集D1;
(3) 计算训练实例子集D1与D2的“重要度”,ScoreIMP(D1)和ScoreIMP(D2);
(4) 如果ScoreIMP(D1) >ScoreIMP(D2),返回D1中正例所占比例作为测试实例的置信度;否则,返回D2中正例所占比例作为测试实例的置信度。
重要度计算公式:
(2)
其中: (1)nD为训练实例子集D中全部实例的数量;
(2)rD为训练实例子集D中正例所占比例。
注意到公式(2)中α为大于0的待定参数,其值取决于训练数据的具体分布,在实验中采用交叉验证获得其最优值。从公式(2)可见,当D中实例数量越多,且正例所占比例越接近0或1时(此时类别分布非常不均匀),评分越高。它是综合考虑“信息量”(支撑结论的证据数)和“类别分布均匀度”的结果。
上述竞争模式就是我们将中心语特征融合进实例匹配算法的方式。实验表明,竞争模式算法作用在“Basic+Head”特征集上,能有效去除绝大部分“坏的差异”,保留为数不少的“好的差异”,从而增强共指消解的效果。
5 实验结果以及分析
我们通过实验验证了前述“基于平面特征的实例匹配算法”与“融合中心语特征的实例匹配算法”的效果,下面介绍实验设置与具体的实验结果。
5.1 实验设置
本文在BART共指消解平台上完成实验[12],该平台首先对语料进行预处理,包括Tokeniztation、NER、POS、Parsing等。
我们使用ACE2005英文BN和NW语料作为实验数据,其分别包含226、106篇语料。使用的特征包括Basic特征集与Head特征集,具体见4.1节中的描述。
训练实例的构造方式与测试过程中使用的消解策略均采用Soon等人[3]提出的方法,并采用MUC-6评价方法中R、P、F三个指标表征消解效果。由于公式(2)中存在待定参数,故采用5-fold交叉验证方式验证不同参数下的共指消解效果。
5.2 实验结果
在基本特征集(Basic)及扩展特征集(Basic+Head)下,表2 和表3分别给出了利用ACE2005英文BN与NW语料的实验结果,其中A1和A3分别表示算法1和算法3,而A3在表2和表3中的结果都在最优α值下取得的结果(α最优值分别为0.6和0.5)。
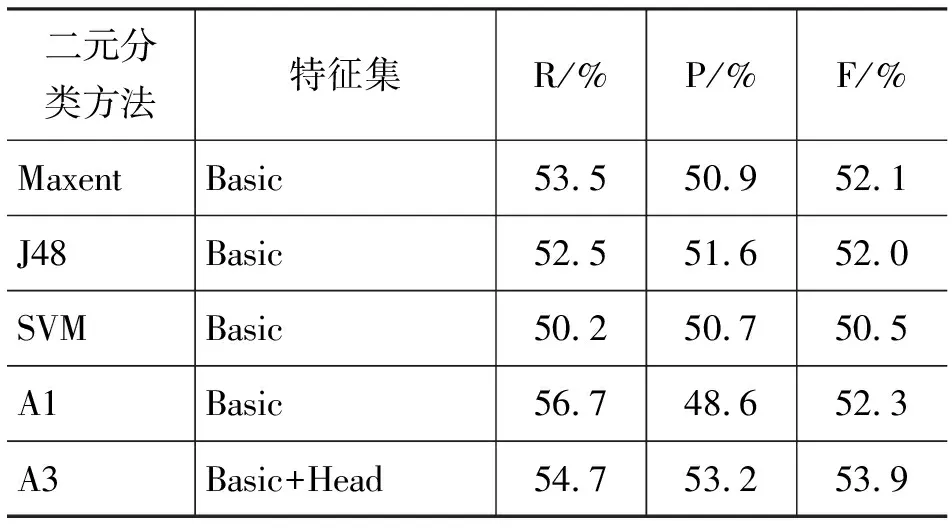
表2 ACE2005 BN语料上实验结果
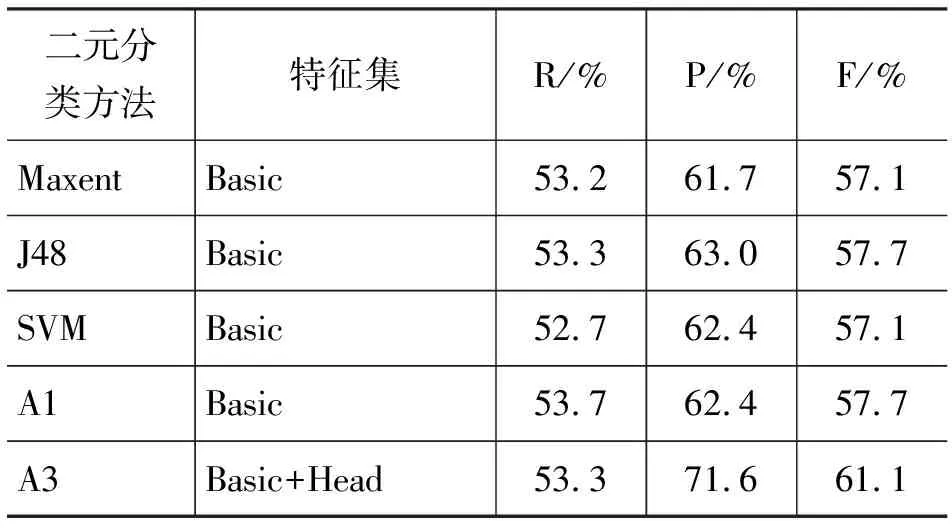
表3 ACE2005 NW语料上实验结果
结果表明,在基本特征集下,无论是使用BN语料还是NW语料,基于平面特征的实例匹配算法(A1)在F值上都达到了Maxent、J48和SVM三种传统机器学习算法的最好效果。这证实了A1算法虽然简单但有效,通过寻找与测试实例最相似的训练实例,能够使共指消解效果达到传统机器学习模型的最好水平。
进一步观察表2和表3,发现融合中心语特征的实例匹配算法(A3)与传统的Maxent、J48和SVM算法相比,均能明显提高F值。在BN语料上F值提高幅度达1.8%~3.4%,而在NW语料上F值提高幅度达3.4%~4.0%。并且可以观察到,A3在F值上的提高很大程度是由于P值得到的较大的提升,提升幅度分别为1.6%~2.5%、8.6%~9.9%。算法3提出的竞争模式的初衷是将中心语特征有效地融合进实例匹配算法,使其能有效捕获利用4.1节中提出的两类信息,进而减少P值的损失。实验结果可以证实,算法3达到了我们预期的效果,使P值得以提升,融合中心语特征的实例匹配算法通过使用中心语约束信息增强了共指消解效果。
6 结论
本文通过实验,证明了中心语匹配约束对共指消解的增强作用。结果同时也体现了基于简单平面特征的实例匹配算法简单而有效,能充分利用每一个训练实例的特征信息,其效果达到了传统机器学习方法的最优水平。进一步,实验结果证明,引入中心语字符串特征并使用竞争模式后,基于中心语匹配确实能有效去除预处理过程中产生的部分错误及捕获一些语义互斥的搭配,提高了共指消解的P值,从而改善的共指消解的总体效果。
本文的方法还有很多地方可以提高,比如算法1通过贪婪方式选择“特征取值对”过滤训练实例只能取得局部最优的选择序列,要获得更好的选择序列应该从全局信息出发修改算法。另外,考虑照应语和先行语的修改语作为字符串特征,增加约束信息会取得更好的效果。
[1] 王厚峰.指代消解的基本方法和实现技术[J]. 中文信息学报,2002, 16(6):9-17.
[2] J. Lang, B. Qin, T. Liu,et al. Intra-document Coreference Resolution: The state of the art[J]. Journal of Chinese Language and Computing,2007, 17(4):227-253.
[3] W. M. Soon, H. T. Ng, D. C. Y. Lim. A machine learning approach to coreference resolution of noun phrases[J]. Computational Linguistics, 2001, 27(4):521-544.
[4] V. Ng, C. Cardie. Improving Machine Learning Approaches to Coreference Resolution[C]//Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, Pennsylvania, 2002. Association for Computational Linguistics, 2002:104-111.
[5] X. Yang, G. Zhou, J. Su,et al. Improving Noun Phrase Coreference Resolution by Matching Strings[C]//Proceedings of the 1st International Joint Conference on Natural Language Processing (IJCNLP2004), Hainan Island, China, 2004. 2004:22-31.
[6] X. Yang, J. Su, C. L. Tan. Kernel-based pronoun resolution with structured syntactic knowledge[C]//Proceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics, Sydney, Australia, 2006. Association for Computational Linguistics, 2006:41-48.
[7] 郎君, 忻舟, 秦兵,等. 集成多种背景语义知识的共指消解[J]. 中文信息学报, 2009, 23(3):3-10.
[8] J. R. Hobbs. Resolving Pronoun References[J]. Lingua, 1978, 44:311-338.
[9] B. J. Grosz, S. Weinstein, A. K. Joshi. Centering: A framework for modeling the local coherence of discourse[J]. Computational Linguistics, 1995, 21(2):203-225.
[10] S. Vemulapalli, X. Luo, J. F. Pitrelli,et al. Classifier Combination Techniques Applied to Coreference Resolution[C]//Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Companion Volume: Student Research Workshop and Doctoral Consortium, Boulder, Colorado, 2009. Association for Computational Linguistics, 2009:1-6.
[11] J. Quinlan. Induction of decision trees[J]. Machine learning, 1986, 1(1):81-106.
[12] Y. Versley, S. P. Ponzetto, M. Poesio,et al. Bart: A modular toolkit for coreference resolution[C]//Proceedings of the ACL-08: HLT Demo Session, Columbus, Ohio, 2008. Association for Computational Linguistics, 2008:9-12.
