基于DSP的相关干涉仪测向快速实现方法
2011-06-13钱志柏
钱志柏,陈 娜
(1.中国电子科技集团公司第五十四研究所,河北石家庄050081;2.石家庄铁道大学,河北石家庄050043)
0 引言
相关干涉仪是一种优秀的测向技术,具有高灵敏度和高抗扰度等特点,已经被国际电联列为高精度测向体制。相关干涉仪测向首先要得到天线阵元的入射波相位分布,然后将其与事先已存的各方位、各频率来波相位分布相比较,由其相似性确定来波方向。相对于传统干涉仪,相关干涉仪技术通过遍历各个方向上的相关度,达到弱化波阵面畸变对测向精度影响的效果。但是,这种“弱化”的代价就是“遍历”产生的大运算量,由此引起的处理速度问题在一定程度上限制了这种测向技术的应用范围。
DSP芯片一直在测向接收机中扮演着非常重要的核心作用,在价格、功耗和研发实用性上有着相比于其他嵌入式处理器无法比拟的优势。基于TMS320C6713芯片实现了相关干涉仪测向算法,使用了先进的并行流水编程技术以及同步接口的DMA技术,极大地提高了测向处理速度。
1 关键技术
充分发挥DSP优势的关键是高效的程序和快速的接口,以及两者的并行工作。基于汇编语言的并行流水编程方法是当今主流DSP最重要的核心应用技术之一,首次将之用于实现相关干涉仪测向算法。运算能力提高后,DSP与外部大容量存储器的接口速度成为制约整个系统效率的瓶颈。因此,应用了传输效率最高的同步接口DMA方式,并进行了分析,首次给出了手册上没有发布的接口时序图。
1.1 基于汇编语言的并行流水编程技术
并行计算是目前计算机软件设计中的研究热点之一。它指多个逻辑处理单元的分工合作,共同完成一个整体任务同步和异步执行。具体针对嵌入式处理器开发而言,并行处理是指多条指令的同时执行。TMS320C6000系列DSP具有先进的超长指令字结构(VLIW),在一个机器周期内可以并行存取和执行8条32 bit的指令。流水线是对中央处理单元(CPU)内部指令操作的形象描述,它指一种能够使多条指令重叠操作的处理机实现机制。在DSP中,为提高硬件的使用率和指令的吞吐量而采用多重硬件流水线。即在一个指令周期内,CPU同时执行取指令(F)、指令解码(D)、指令执行(X)、写回(W)等的循环操作,形成硬件流水线,如表1所示。软件流水线的实现要求数据相关性的去除,通常的办法是寄存器重命名和动态指令调度。对于TMS320C6713而言,有相当一部分指令(存储器操作指令和乘法指令)不能在单机器周期内执行完毕,而流水线技术可以大大提高程序的吞吐率和硬件资源的利用率,相当于循环体内的所有指令都能在单周期内执行完毕。
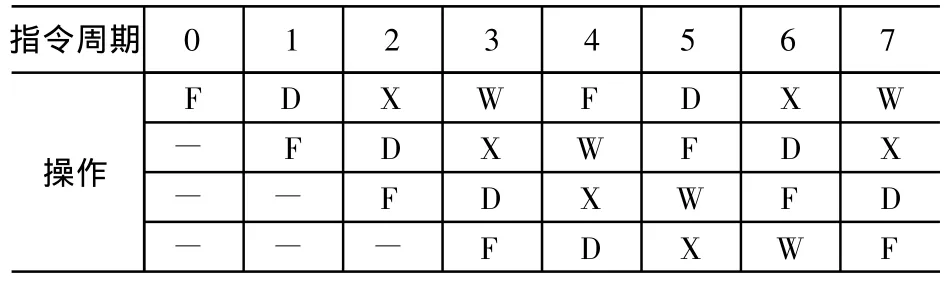
表1 CPU执行流水线处理过程
但是,并不是任意两条指令都能够同时执行。也就是说,并行性仅存在具体的指令搭配之中。而且欲构成软件流水线的指令内部不能有条件跳转指令,同时流水线内部数据不能相关。由于这些原因,C语言实现的程序,很难被开发环境配套的编译器编译成高效的DSP代码,从而发挥全部DSP的潜力。因此,该设计使用汇编语言实现。一般意义上讲,汇编语言实现比高级语言实现的程序效率高。主要的原因是高级语言对CPU寄存器的管理能力有限。高级语言定义的变量多存在于存储器而不是寄存器中,而所有的运算最终都发生在寄存器中。这对矛盾会产生两个后果:一是对存储器的多余访问,二是存储器操作与寄存器运算的高度相关。这两个后果直接导致了程序效率的降低。然而实际应用中,对存储器的大量访问不可避免。这种情况下,如果仅仅依靠汇编语言实现对程序效率的提高,优化的空间就很有限。此时,必须使用并行指令以保证硬件资源利用最大化,而流水编程技术则避免了数据相关引起的程序效率问题。
1.2 同步接口DMA技术
DMA技术是指内核需要进行大量数据传输时,不需要内部CPU的介入,使I/O设备与存储器或者存储器之间直接交换信息。内部存储器是嵌入式处理器中最稀缺的硬件资源,通常情况下,待处理的数据量往往大于片内存储器容量,所以必须借助DMA在片内高速缓存与片外低速存储器之间进行数据交换,以提高系统整体性能。而且多数情况下,数据传输花费的时间往往超过数据处理的时间。
对于TMS320C6713的外部存储器接口来讲,尤其是同步存储器接口,DMA方式和随机访问(RA)方式有着惊人的速度差别。德州仪器公司(TI)提供的数据手册对同步动态随机存储器(SDRAM)接口的突发方式的时序说明很不详细,通过chipscope软件对SDRAM接口时序进行了抓取,其结果如图1所示。从接口时序图可以看出,TMS320C6713的SDRAM接口可以工作在4字突发模式下,虽然4字的突发传输(BURST)需要每次启动,即列地址所存(CAS)有效,但各次启动之间并没有间隙(latency)。也就是说,以DMA方式工作的SDRAM接口可以在外部时钟的速率上进行数据传输。
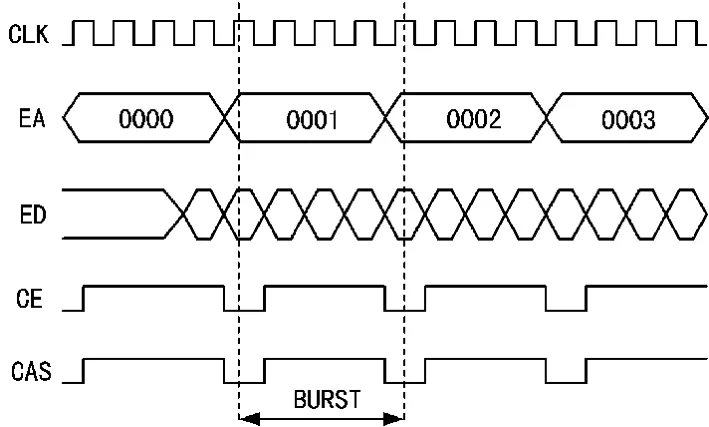
图1 SDRAM接口DMA读时序
2 相关干涉仪测向的快速实现
对于5信道相关干涉仪测向系统,计算一个方向的相关度至少需要4次减法、4次加法、14次存储器读、5次存储器写、1次比较以及跳转等操作。而每个方向的相关度计算过程又是重复的。传统的基于PC机或者嵌入式处理器的实现方式只能将上述重复的操作顺序执行,处理效率低。通常,流水地而不是顺序地处理重复操作会提高效率。而现今业界主流的DSP芯片不仅支持流水线处理,而且支持并行操作,这就使得处理效率的提高成为可能。相关干涉仪测向算法运行过程中,样本相位差必须事先就绪。同步存储器接口的DMA传输方式不仅加快了DSP访问外部大容量存储器的速度,而且不需要CPU的干预,可以和数值计算并行工作。
2.1 硬件平台
天线接收外界电波信号,经信道和中频采样后,由FPGA处理后得到5路信号的4组相位差,缓存后被DSP读取。DSP得到相位差后进行干涉仪相关运算,得到来波方位角后进行输出。其中TMS320C6713外挂的SDRAM负责存储不同频率和方向上的相位差样本。硬件平台如图2所示。
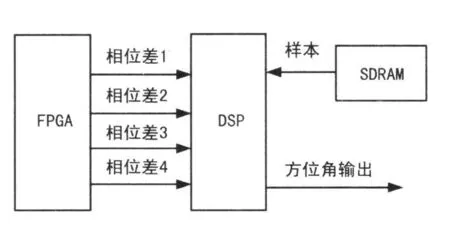
图2 硬件平台框图
2.2 相关度计算的并行流水实现
该设计软件的内核循环仅包含6个指令包(Instruction Packet,IP),执行了对一个方向相关度计算的所有27条指令。下面的代码列出了内核循环前两个指令包。可以看出,由于应用了并行处理技术,DSP在循环体的前两个时钟下的每个时钟内都同时执行了6条指令。其中,第一个时钟内启动两次条件跳转、读取4个样本相位差以及两次比较,第二个时钟内完成两次表地址获取、启动两次相位差读取以及两次余弦值相加。由于存储器操作需要延时,5个时钟结果才能出现,对余弦表的读取和对其结果的处理没有放在一次迭代中进行。而是使用流水处理技术,将之分解在两次迭代中重叠处理。跳转指令同样需要延时,6个时钟后程序指针才能到达指令指定的地址。因此,除第一个指令包外,内核循环的剩余5个指令包都是在程序跳转的过程中流水地执行的。综上所述,流水线技术保证了运算单元及寄存器在指令启动后到结果出现前没有空闲,最大限度地利用了硬件资源,使程序效率到达了最优化。
loop:
[!is_edge]b loop;条件判断是否继续循环
||[is_edge]b loop_end ;条件判断是否退出循环
||ldw*table_a ++[2],v_1_ 0_ a
||ldw*table_b ++[2],v_3_2_b ;并行读取4个样本相位差
||cmpeq cnst_359,cntr,is_edge ;迭代次数和总数比较
||cmpgt v_cos_sum,v_ cos_max ,is_large ;相关度比较
abs sum_1,index_1;得到第2个余弦表的地址
||abs sum_3,index_3;得到第4个余弦表的地址
||ldh*cos_a[index_0],v _ cos _0;启动读取第1个相位差的余弦值(下次迭代结果才到位)
||ldh*cos_b[index_ 2],v_cos_ 2;启动读取第3个相位差的余弦值(下次迭代结果才到位)
||add v_cos_0,v_cos_1,v_cos_1;前两个相位差的余弦值相加(上一个方向)
||add v_cos_2,v_cos_3,v_ cos_3;后两个相位差的余弦值相加(上一个方向)
2.3 DMA方式导入样本相位差
程序得以全速运行的前提是运算所需的样本相位差表一直存在于DSP的内存中,而TMS320C6713的内部存储器只有256 k字节,不足以容下整个频段的样本相位差。同时不希望样本相位差的导入会影响CPU的运算,因此使用乒乓缓存的方式实现SDRAM中样本相位差和相关度运算程序的接口。在DSP内部存储器中开两块缓存,每块缓存都可以存放1个频点的360个样本相位差。在开始处理其中一块缓存中数据前,以DMA方式启动对另一块缓存的数据导入,即导入样本相位差数据的同时也在进行采样相位差和样本相位差的相关度运算。图3表征了两个进程的并行处理以及同步情况。该设计中,数据传输时间大于数据处理时间。因此,以DMA传输的结束作为两个进程的同步标志。同步并行处理示意图如图3所示。
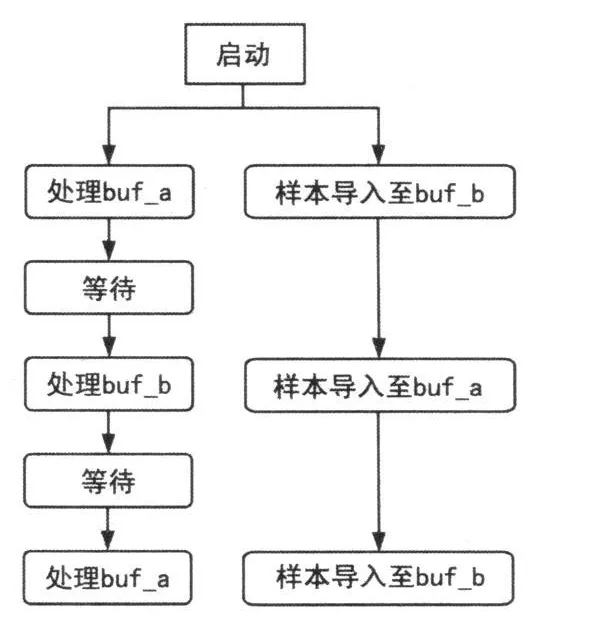
图3 同步并行处理示意图
3 处理速度分析
针对测向精度要求为1度的应用,得到一个频点的来波方向需要处理360次相关度计算,而完成一个方向的相关度计算需要27条指令,总计9 720条指令。从2.2可以得出,DSP仅花费6个时钟就可以完成一个方向的相关度计算。如果在360个方向进行遍历,再考虑程序进入循环前的准备,得到最终来波方向时间开销小于1200个时钟。TMS320C6713的核时钟工作在200 MHz,因此对一个频点相关度的遍历运算仅需要6 μ s。
该设计应用于频率跨度为175 MHz的宽带测向系统,而频率分辨率为12.5 kHz,则全频段频点个数为14 000。每个频点需要预存360个样本相位差,每个样本为4个16 bit,那么最终消耗的存储器为40 M字节。该设计采用的SDRAM,存储深度为64M字节,可以满足样本相位差存储的要求。SDRAM的工作时钟是90 MHz,总线宽度为32位,导入360个方向4个16 bit宽的样本相位差需要8 μ s。相关度计算所需时间小于对样本相位差导入的时间,而两者同时启动,同步运行,最终处理时间决定于较慢步骤。因此需要8 μ s完成一个频点的来波方向测定。
传统的基于PC机或者嵌入式处理器的实现方式大约需要1 ms才能完成一个频点的测向,该设计将处理时间缩减了两个数量级。用每秒10 000跳的跳频信号源对该设计进行验证,结果如表2所示。可以看出,对驻留期为100 μ s的信号进行了10次测向,说明一次测向时间花费小于10 μ s。

表2 测向速度验证结果
4 结束语
该设计应用了先进的同步存储器接口的DMA技术和并行流水编程技术,最大限度的发挥了DSP芯片在密集型数值计算方面的优势,大大提升了处理效率。其中涉及的关键技术具有相当的通用性,尤其适合应用在一些算法具有一定复杂度,对实时性要求较严格的系统中。
该设计已经在某宽带测向系统中成功应用,相比传统实现方案,大大提高了系统的测向反应时间。可以预计,对实时性要求较高的跳频测向系统,这种灵活而快速的实现方案也将有用武之地。
[1]张海燕.五通道相位干涉仪测向的研究和实现[D].成都:成都理工大学,2004.
[2]李 淳,廖桂生,李艳斌.改进的相关干涉仪测向处理方法[J].西安电子科技大学学报,2006,33(3):400-403.
[3]贾立哲,魏利辉.相关干涉仪测向算法的FPGA设计实现[J].无线电工程,2006,36(12):40-42.
