最大熵模型的语义句法分析在陪护机器人中的应用
2011-06-11黄明王慧梁旭
黄明,王慧,梁旭
(大连交通大学 软件学院,辽宁 大连 116028)
0 引言
对中文信息进行处理,要理解中文信息所要表达什么意思是最关键的,语义句法分析是解决这个问题的一个好的方法,语义句法分析是信息处理的前提,必要条件,同时也是最重要的环节,对汉语的理解很到位,以后利用理解的关键字来处理相似度的查询,这样利用已分析好的关键字来查找也是准确的,若是对汉语的理解不充分的话,之后得到的关键字都是不充分的,就算以后采用更精准的形似度算法也是不完善的.所以理解汉语的语义是做一切后续工作的前提.由于汉语自然语言的特殊性,中文内容的字与词的区分不明显,由于分词的位置不同,容易造成歧义的产出,中文正因为有这样的问题,所以对中文准确的分析是有难度的,要更好更准确的理解中文语句,对整句话进行理解,语义句法分词是中文自然语言处理的关键阶段.
在理解自然语言方面,问句给出一句话,对整个语义的把握很重要,比如说中文的表达方式很多,句子意思是相同的两句话,在用了不同的表达方式后,经过分词方法的处理,得到了不同的关键字,使得不能充分的理解,在理解语义的同时,为了更好的把握整个问句的结构,需要掌握中文问句的组织结构,基于此,对于中文语言进行了总结,看看问句都采用了什么结构,也就是句法分析,只有在问句的语义加上问句的句法综合处理上,才能够更准确的理解汉语问句.本文基于汉语语言问句的语义的分析加上句子语法的融合,通过用最大熵算法的学习,使对汉语的理解达到最优,应用在陪护机器人中,对于老人的健康提问,机器人需要接受其问句,理解问句的语义,对问句进行处理,找出老人提问的核心词,通过查找理解老人问句语义和搜索问句句法相结合的方法,更充分的理解老人的提问,准确的搜索答案反馈给老人,此方法在实验验证中提高了回答问题的准确率.
熵值是表示一种混乱程度的状态,最大熵也是在一种极混乱的状态下,这样使概率达到均衡,寻求最大值,最大熵模型方法在确定句法结构以及词性标识方面已有了一定的研究[3-6].最大熵是一种基于概率统计的学习方法,是运用在随即概率事件中,首先需要对待学习数据进行训练学习,形成一种规则模式,再用学习之后形成的模式来分析现实生活中自然语言,来分析句子的成分,描述该句子成分的复杂程度.本文针对日常生活的对话内容用最大熵模型进行学习,找出其中的规律,之后对问句采用基于语义理解向量弧和句法分析语法树相结合的分析方法,抽取问题的特征类型及关键字,最后用最大熵模型的方法进行优化,解决了面向实际问题的语义分析[7].
1 基于语义依存的句法分析方法
举个例子说明理解中文需要从理解文字语义开始,如“我爱吃土豆”和“我喜欢吃马铃薯”,其实这两句话都表达了喜欢吃马铃薯的这个事实,就是表达的方式不同罢了,从表面上看两句话的确不一样,经过分词处理后得到的词也是不同的,但是从整体理解句子意思的角度来分析,这两个句子所表达的意思是相同的,因为“土豆”和“马铃薯”在实体上是一个东西,只是说法不同,像这样句子中有同义词的问句,在实际分析中没有考虑到语义分析,不能从深层理解上挖掘句子的意思.另外,由于汉语的广博,句子的结构成分也是多样化的,要透彻理解一个句子所要表达的内容,不仅要注重理解句子的语义,还要结合问句语法结构,只有将两者完美的结合,才能更好更快更精准的理解一个问句.本文采用了汉语问句语义依存向量弧和依存句法结构语法树相结合的方法,更加全面准确的理解问句语义.
1.1 汉语问句语义依存向量弧[8]
依存文法描述句子里有两种成分中心词和依存词,他们之间构成一种依存关系,依存词依赖着中心词,中心词与依存词之间用一个弧相连,弧头指向的是中心词,弧尾那端是依存词[9].图1为“糖尿病的严重症状是什么”依存关系分析结果.图中有弧相连就说明两个词有依存关系.弧上的字母注释代表着依存关系的结构类型,分别是:de代表弧中有“的”字的结构,att代表定语的修饰结构,sub抓取的是句子的主语成分,cet是句子的谓语,是句子的中心支撑,obj代表句子的宾语成分,特定字符〈E〉与句子的中心成分相关联,通过这样的表示,直接通过sbj、cet、obj可以找到句子的主要成分.“糖尿病”和“的”相连,“糖尿病”依存于“的”,“的”和“症状”相连,“的”依存于“症状”.在问句的分析过程中[10-12],确定问句的特征类型是极其重要的,根据问句的语义,提取关键字,对关键字进行分析,找出决定关键语义的词语,确定问句的问句类型,这样分析问句在搜索答案时,能够直接搜索类型相关的答案,缩短了搜索时间,增加了准确率.本文利用依存结构来提取问题分类的特征,首先分析问句中每个词之间的依存关系,去掉无作用词语,选择问句中关键语义的词作为特征词.问句“糖尿病的严重症状是什么”,其中“糖尿病”、“的”、“严重”都是“症状”的修饰成分,通过本文的方法降噪后获得语义特征为“症状是什么”,该查找范围是医疗方面的知识,提高了回答问题的准确率及查找答案的速率.
提取语义分类特征有如下步骤:
(1)找疑问词
生活中有很多疑问词,经过总结把这些疑问词做成表,以便确定句中的疑问词是否在表中.“糖尿病的严重症状是什么”,经过分词得到“糖尿病”、“的”、“严重”、“症状”、“是”、“什么”,之后通过查找疑问词表,查找到“什么”是疑问词.
(2)对问句进行句法分析
分词后要研究各个词之间的依存关系,以及标注好它们之间的关系类型.“糖尿病的严重症状是什么”,句法分析结果如图1.
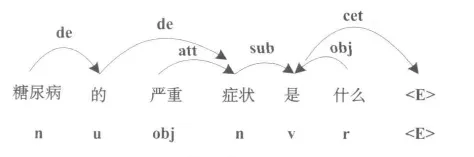
图1 问句的依存关系分析结果
(3)确定问题分类及特征
根据第二步,已经很清晰的看出句子的依存关系,根据依存关系,能够找到句子的主干,加上依存疑问词的成分就能够确定句子的问题类型,这样做能够去掉很多冗余.算法的思想是通过依存向量弧的分析,能够找出句子的主(S)谓(CE)宾(O)结构,设问句里存在疑问词C,通过查找,就可以查找到与C有依存关系的词D,则S、CE、O、C、D的组合就是这个问句的问题分类特征,特殊情况下,若C和查找到的D已经是句子主干的子集,则只需取其中的一个(如D)作为分类的特征,则提取的特征为S、CE、O、D.对于“糖尿病的严重症状是什么”,“是”为谓语中心词(CE),“症状”依存于“是”,是主语,“什么”也同样依存于“是”,是宾语(O),所以句子主干为:“症状是什么”,由于疑问词“什么”既是句子的宾语,同时也是依附成分,所以取其中一个即可,最终提取问题分类特征为“症状是什么”.
通过以上三个步骤,能够简洁的提取问句的分类特征,减少影响问题分类噪音冗余,能够准确的在问题分类的相关领域内进行问句答案的搜索.该方法提高问题分类的准确度.
1.2 面向自然语言的语法树结构
通过面向自然语言的语法树结构[13]方法,能够更加透彻的了解一个问句的句法结构.下面就来研究一下句子的结构,一个句子一定是由名词短语(NP)和动词短语(VP)构成,一个问句一定是有主语的,不管主语是名词(n)、代词(r)还是数词(m)、量词(q),都要描述主语做了什么,而做了什么即是动词短语部分,强调进行了什么动作,或者进行一段描述,将这样的文法需要描述成一组符号,让计算机能够识别,这就是上下文无关文法.下面我们就用这个规则来分析“医生解除老人一身病痛”这个问句的语法树结构,用一棵“树”型结构来体现问句的结构 (图2),其中多孩子箭头代表着一种组合关系,单箭头代表着对应关系,其中MP是数词短语,由数词和量词组成,另外,VP=v+NP+NP这里面v后面还有两个NP,就说明了动词后面有两个名词短语,这时动词后面的两个词称为“双宾语动词”,用(双宾=“双”)表示,也可以一个,看具体的问句分解为语法树后的情况而定,双宾语只是语法结构的一种形态.语法树的结构清晰,为理解问句语法结构起到了一定的作用.所以理解自然语言的语义,需要将语义分析与句法分析相结合,本文就是将基于语义依存向量弧与面向自然语言的语法树相结合,更能够准确的理解问句的语义.
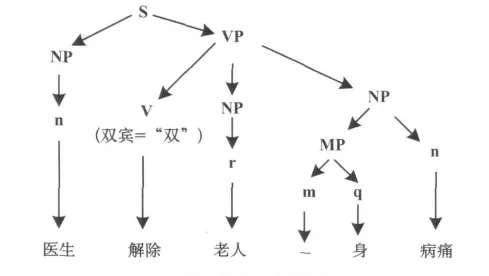
图2 问句的语法“树”表示
2 最大熵模型
最大熵模型[14]主要应用在预测随机概率事件的分布,是一种基于统计的学习模型方法,在全部概率条件已知的情况下,绝不带有任何主观假设的成分,对随机概率事件进行分析,随机概率事件分布均匀,更有利于预测,这时求得的熵值最大时的概率分布就可以作为正确的概率分布模型.所以最大熵模型是很客观的智能的概率分布模型,很适合解决问题分类这一方面的问题.最大熵模型以每次分词后形成的词作为一个独立的事件,选取数据进行单独训练.假设分词后存在m个分词f1,…,fm,每个分词分别对应m个约束条件,进行训练后,满足约束条件得到的模型为:
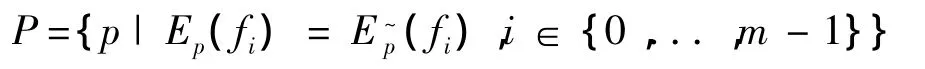
在上述集合中,选取熵值最大的模型即为所求的模型:
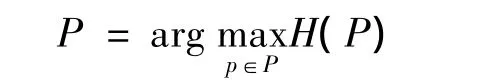
满足所求模型的解如下:

其中,Z(x)是因子系数;μ为权重参数.这样转化后,根据训练数据求解参数μ即为解决最大熵模型的建模问题.由问句语义分析和句型语法树的结合充分理解问句语义的前提下,得到的优的化分词方法,这时最大熵模型把分词结果作为其训练依据,在随机概率事件分布的情况下,求得最大概率的熵值,使得得到的结果更加准确.
3 实验结果及分析
为了验证结果,进行了大量的实验,实验采用了2 000个语句作为训练语句,实验在特定情况下进行的,其中随即抽取1 000个问句用来测试实验结果,问题领域涉及到多个方面,具体分类见表1,几乎每一类的问句数量分布均匀.首先对问句采用语义依存向量弧与语法分析树标注相结合的方法进行分词和词性标注[15],之后对问句提取语义特征进行问题类型,把问题各自划分在该领域中,这样便于搜索问题,最后用最大熵模型对这些标注好的分词进行训练、优化,形成最大熵模型.
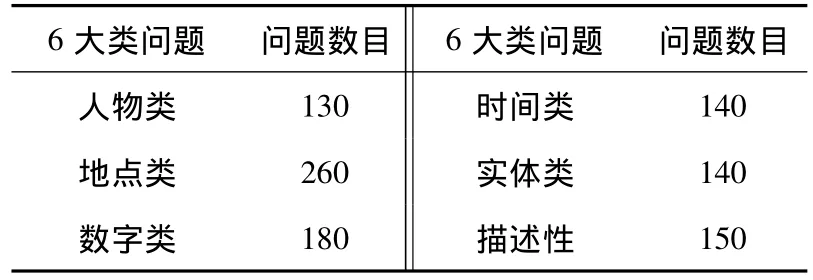
表1 测试问题分布情况
实验的评价标准是各个类型的问句原来问句理解的准确率与改进后问题理解的准确率相比较[16],比较结果表2,从中可以看出,大部分问题分类的准确率都有一定的提高,但仍有比如描述类问题改进方法的准确率52.8%比原来的能稍低一些,其原因是:①描述类的问题描述本身比较长,问题的理解程度还不够;②对参与训练的日常问句数量还太少,特征集合也不够大,随着以后加大训练,语句逐步会增多,准确率也会逐步提高.
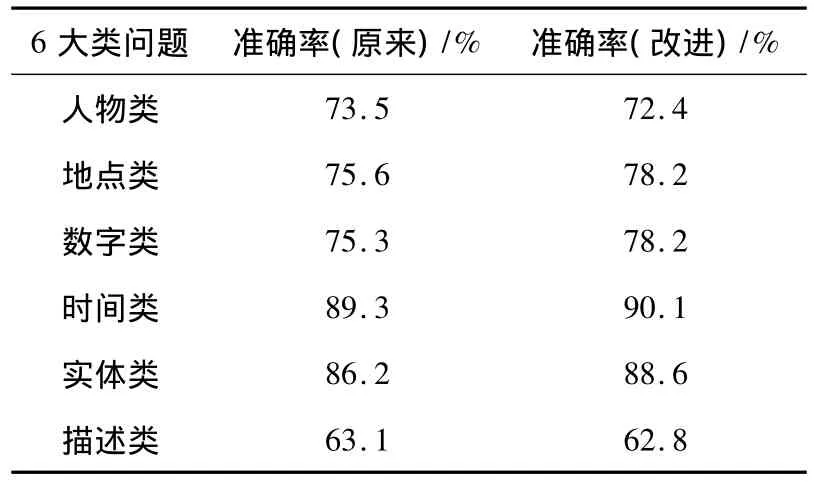
表2 最大熵模型学习之后的比较结果
4 结论
最大熵模型是分析随机事件概率分布的一种学习模型,在自然语言处理中应用广泛,基于语义依存的向量弧和语法分析树的结合,对问句进行深层语义理解之后进行分词、词性标注,提取问句语义特征进行问题分类,并通过最大熵模型对分词进行学习、训练,实现汉语从语义理解方面更好的理解问句,降低了中文理解的困难度,是一种非常有效的汉语问句语义分析的方法.为进一步完善问句理解的准确性,下一阶段计划将在特征选取算法等方面进行研究.
[1]李鑫,杜永萍.基于句法信息和语义信息的问题分类[C].第一届全国信息检索与内容安全学术会议,2004:243-251.
[2]张仰森,曹元大,俞士汶.最大熵方法中特征选择算法的改进与纠错排歧[J].北京理工大学学报,2006,26(1):36-40.
[3]李素建,刘群,杨志峰.基于最大熵模型的组块分析[J].计算机学报,2003,26(12):1722-1727.
[4]周雅倩,郭以昆,黄萱菁.基于最大熵方法的中英文基本名词短语识别[J].计算机研究与发展,2003,40(3):440-446.
[5]徐延勇,周献中,井祥鹤.基于最大熵模型的汉语句子分析[J].电子学报,2003,31(11):1608-1612.
[6]钱伟,郭以昆,周雅倩.基于最大熵模型的英文名词短语指代消解[J].计算机研究与发展,2003,40(9):1337-1343.
[7]石晶,李万龙.汉语语义分析方法研究[J].计算机应用研究,2010(2):529-531.
[8]高玲玲.基于依存语法的汉语句法分析研究[D].中国优秀硕士学位论文全文数据库,2009.
[9]文勖,张宇,刘挺,等.基于句法结构分析的中文问题分类[J].中文信息学报,2006,20(2):33-39.
[10]XIN LI,DAN ROTH.Learning Question Classifiers[C].The 19th Internati-onal Conference on Com-putational Linguistics,2002:556-562.
[11]XIN LI,DAN ROTH.The Role of Semantic Information in Learning Question Classifiers[C].First Inernational JointConference on Natural Language Processing,2004:451-458.
[12]张宇,刘挺,文勖.基于改进贝叶斯模型的问题分类[J].中文信息学报,2005,19(2):100-105.
[13]俞士汶,段慧明,朱学锋,等.综合型语言知识库的建立[J].中文信息学报,2004(5):1-10.
[14]谢法奎,张全.基于最大熵模型的语义块切分[J].计算机工程与应用,2009,45(26):118-120.
[15]孙铁利,李晓微,张妍.信息过滤中的中文自动分词技术研究[J].计算机工程与科学,2009(3):80-82.
[16]李宪东.基于最大熵原理的确定概率分布的方法研究[D].中国优秀硕士学位论文全文数据库,2009.
