一种基于模板匹配的语音识别算法
2011-06-05聂晓飞詹庆才
聂晓飞,赵 禹,詹庆才
(1.北京交通大学 电子信息工程学院,北京 100044;2.北京电力公司密云供电公司 北京 101500;3.北京四方继保自动化股份有限公司 北京 100085)
语音识别的研究方向有3个:基于声道模型和语音知识的方法、利用人工神经网络的方法以及模版匹配的方法。第1种方法需要系统能听懂人类语言,并理解他的意思,对人工智能的依赖很大。第2个方法是完全模拟人类的大脑活动,就像一个婴儿一样从头学习某一种语言,因此需要极其庞大的数据库来存储数据。目前,这两个方法基本还处于研究阶段。
第3种模版匹配方法是目前应用最广的方法,它广泛应用于各种需要控制和身份识别的场合。这种方法第一步是进行模板训练,通过训练得到模板库。以后的工作就是将得到的信号按同样的规则处理后所得数据与模板库中的数据进行匹配。算法的关键在于如何将语音信号处理成尽可能简单,但又不会失去特征的一组数据,以及判定这些数据是否符合匹配的标准。最后将与语音信号最相似的模板作为判定结果。如果相似度过小,则要求重新输入语音信号。
1 系统框图
可以看出整个系统实际上工作于两种模式[1-3],即训练模式和工作模式。训练模式中,不输出结果,只需要将语音处理后得到的数据加入模板库中。工作模式中,需要进行截取语音信号,生成特征参量,模板匹配判断,输出判定结果4步操作[4]。具体的实现框图如图1所示。
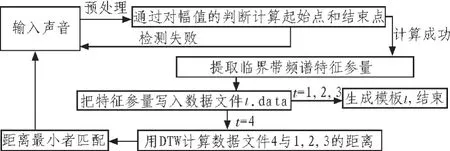
图1 系统流程Fig.1 System flow
在如上框图中,t这个变量决定系统工作于哪一个模式,是很关键的一个变量。同时,它还作为数据文件的文件名。
2 语音识别流程
2.1 预处理
首先是对声音信号的预处理。预处理第1步是采样,按照8 kHz的采样频率进行直接采集。根据奈奎斯特定理,这个采样频率可以保证声音信号的无失真复原。第2步是对声音信号幅值的一个削弱,因为声音信号由麦克输入,声音幅值会很大,造成不必要的干扰。第3步是加窗,加汉明窗,滤掉高频成分,可以有效防止频谱的混叠。由于用麦克输入的声音信号的信噪比都比较高,所以就不用考虑滤波这个环节了。预处理这个环节就是为了给后面的各个模块提供品质较好的语音信号数据。
2.2 声音截取和分帧
接下来就是端点的检测。语音信号经过预处理后,要提取出字词,就必须通过进行端点检测来去除前后两端无声区的影响,使得声音信号尽可能不受人为输入反应时间的干扰。第一步是计算所有声音信号幅值的平均值a,当声音的幅值达到平均值的(1/2)a,我们就认为这个字开始了,当声音信号再次下降到平均值的(1/3)a,我们就认为这个字结束了。在这里,幅值代替了功率的作用,(1/2)a 和(1/3)a 作为判断的两个阈值。因为说话的声音的幅值肯定大于背景噪声,所以这个方法在安静环境下或者采用麦克风输入时效果还可以接受。如果环境质量不高,还可以结合过零率[5]等参数来进行端点检测。伪代码:

如果端点检测成功,就说明有声音输入了,接下来需要做的就是特征参量的提取了。按照常识,一个字一般持续时间为0.25 s,以8 kHz的采样率,可得到2 000个点,按2 048算。每帧有128个点,共分16帧。为了提高精度,将每帧和它的下一帧合起来作为一个256点的语音信号帧,每帧之间有互相的包含。这样对整个信号的处理就变成对每帧信号的处理。
2.3 帧处理得到数据文件
帧处理的过程如下:
第1步,对语音信号每一帧的加窗语音Xn(m)做256点的DFT变换,得到频域上的表达式,即功率谱。
第 2步,划分临界带。在 0~fs/2(fs为采样频率)中确定 f1,f2,f3…作为临界带频率的13个分割点。确定的方法是将i=1,2,3…代入(1)-0.53 中。由此可以求出 f1,f2,f3…并且,由f1与f2构成第一临界带,f2与f3构成第二临界带,以此类推。因此在0.1~4 kHz范围内需要安排12个临界带。
第3步,求临界带特征矢量。将每一个临界带中的功率谱累加,即可得到相应的临界带特征矢量。从而,每帧都可以得到一个12维的临界带特征矢量。
也就是说,每一个语音信号都产生了16×12个特征参量。我就就是要通过比较这些特征参量来进行语音的识别。至此,一帧语音信号的的特征矢量提取完毕。当录入一次语音信号后,首先将其分帧,每一帧语音信号进行如上特征矢量提取,最终一段语音信号所有帧的特征矢量提取完毕之后共同组成这一段语音信号的特征矢量。
在实验中我们得到[0,177,5 303,296,918,298,186,56,82,259,42,9]是“4”这个音的第一帧的临界带特征矢量。伪代码为:

2.4 模板的匹配判断
比较语音参量我们用的是动态时间规整 (Dynamic Time Warping,DTW)算法,DTW算法[6]能够较好地解决用于孤立词识别时说话速度不均匀的难题。测试的语音参数共有N帧矢量,而参考模板有M帧矢量,且M不等于N,则DTW就是寻找一个时间归整函数,它将测试矢量的时间轴n非线性地映射到模板的时间轴m上,并使该函数满足第n帧测试矢量和第m帧模板矢量之间的距离测度最小。
这个匹配过程实际上在寻找一条从点 (1,1)到点(16,16)最短的路程,路径程度就是每帧特征参量间的差值。伪代码为:

DTW算法之所以有这种特性是因为动态规划算法的基本特性:每个点的最优解累积起来就是最优解,不用再向前再考虑。由于声音只可能是由于说话速度不均匀造成两个模板相同帧之间标号的不一样,但二者肯定都是按顺序来的。举例来说,如果信号的第3帧与模板的第2帧匹配,那么与模板第3帧匹配的帧必然是信号的第4帧乃至第4帧以后的帧,不用再向前考虑。这和动态规划的精神是契合的。所以我们选择DTW算法来进行最后的模板匹配判断。
3 实验结果
记录了 30 次的测试结果如下表,3 个音 (“4”,“5”,“8”)各 10 次,模板 1,2,3 对应声音“4”,“5”,“8”。
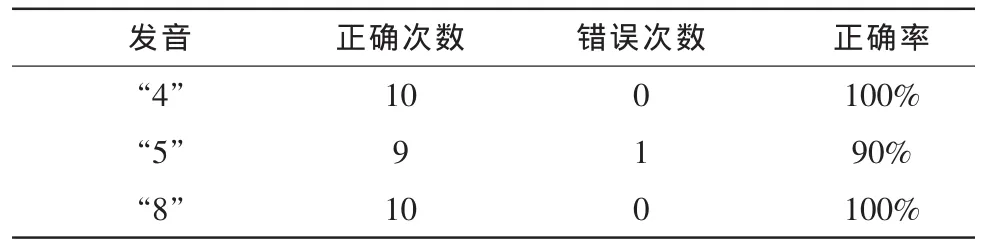
表1 测试结果Tab.1 Test results
可以看出正确率还是很高的。除了一次5被认成8以外都是正确的。当然,这与声音的选取也是有很大关系的。如果选取1,4,7这3个发音比较相近的音,正确率就不会有这么高。
4 结束语
总的来说,这种语音识别算法虽然是一种比较简单的方法,但也包括3一个完整的语音识别过程,可以通过改进每一个流程采取的算法来提高整个系统的性能。笔者希望这篇文章能对语音识别的嵌入式系统开发的初学者提供一些借鉴。
[1]肖永江,张兴娇,文如泉.一种雷达目标模拟器的DSP软件设计[J].舰船电子工程,2011,31(4):117-121.XIAO Yong-jiang, ZHANG Xing-jiao, WEN Ru-quan.DSP software design of a radar echo signal simulator[J].Ship Elctronic Engineering,2011,31(4):117-121.
[2]何翔,刘大健.孤立词语音识别系统的DSP实现[J].现代电子技术,2009,32(17):118-123.HE Xiang,LIU Da-jian.Realization of isolated speech recognition based on DSP[J].Modern Electronic Technique,2009,32(17):118-123.
[3]苏明武.基于DSP的语音识别技术研究与实现[D].哈尔滨:哈尔滨工程大学,2005.
[4]梁俊,杨燕翔,王娟,等.基于DSP的语音识别计算器设计[J].电子设计工程,2010,18(5):135-138.LIANG Jun, YANG Yan-xiang, WANG Juan, et al.Design of speech recognition calculators based on DSP[J].Electronic Design Engineering,2010,18(5):135-138.
[5]胡钢.一种语音端点检测算法在DSP上的实现[J].鞍山师范学院学报,2009,11(6):44-47.HU Gang.DSP implementation of speech recognition based on endpoint detection of speech[J].Journal of Anshan Normal University,2009,11(6):44-47.
[6]吕涛,刘白芬,燕贤青.一种基于定点DSP的语音识别算法实现[J].华东交通大学学报,2008,25(6):68-72.LV Tao,LIU Bai-fen,YAN Xian-qing.The realization of a fixed-point speech recognition algorithm based on DSP[J].Journal of East China Jiaotong University,2008,25 (6):68-72.
