面向目标的计划合并技术
2011-06-01刘宏义
刘宏义
(西安陆军学院信息化研究试验室,陕西西安 710108)
使用面向目标的行为计划系统创建和管理自动化代理的行为是一种强大的技术,并且迅速地在游戏开发者中得到认同。在游戏开发中,计划系统相对来说是新技术,但是学术界使用计划来解决问题己经有多年。所以,找到一个可供游戏开发者用于改进计划系统的研究基础并不困难。计划者可以使用计划合并技术改进当前的计划系统,使自动化代理的行为范围变得更宽,甚至让它们同时尝试追求多个目标。这种技术使用方式有多种,但尚未应用到游戏中。本文描述了在实时游戏的背景下,实现计划合并系统的方法以及使用这个系统的含义。
1 面向目标的计划系统
面向目标的行为计划系统是一种决策算法,它能让程序员摆脱对特定代理行为的选择,将这些选择置入代理自身的感觉-思考-行为的循坏中。使用这个系统的最大好处是减少设计人工代理个人行为的复杂度,同时在代理的总行为中保持很高水准的真实感[1]。
面向目标计划让特定的代理通过追求特定的目标来决定自身的行为。一个代理的目标可能包括破坏一个目标或获得一个物品。在使用代理来记录世界状态的系统中,目标被表现为期望的世界状态。在传统的计划系统中,代理被限制,只能在给定的地点及时机挑选一个最重要的目标。一旦这个目标被选中,一个代理可以将原子行为串联成一个序列来创建一个计划,有时也被叫做运算符。
使用效果和前提作为指导,任何启发式的搜索都可以通过列出一个代理可用来达到期望目标的行为序列来创造计划。文献[2~3]中描述了如何为计划目的而使用A*算法。完成后的计划就是代理用来实现目标的一系列行为。
图1展示了制作三明治的部分有序计划和完全有序计划的例子。在部分有序计划的版本中,注意独立的行为相互之间没有顺序关系。但是行为可以有相对的顺序:所有的组成部分必须在制作三明治前获得。通常来说,给予行为的惟一顺序是行为的前提条件所要求的。另外,完全有序计划加强了所有行为的特定顺序,而不管单独的行为是否满足其他行为的前提条件。虽然可以为三明治以任何顺序获得肉、奶酪和面包,但是一个完全有序计划指定了执行这些行为的顺序。显而易见,任何部分有序计划都可以被表现为一个完全有序计划[4]。
虽然绝大多数基于学术的计划算法产生部分有序计划,但是这种类型的计划者还没有在游戏中找到广泛应用。有一些原因解释了为什么完全有序计划能更直接地应用到 NPC 上[5-6]。
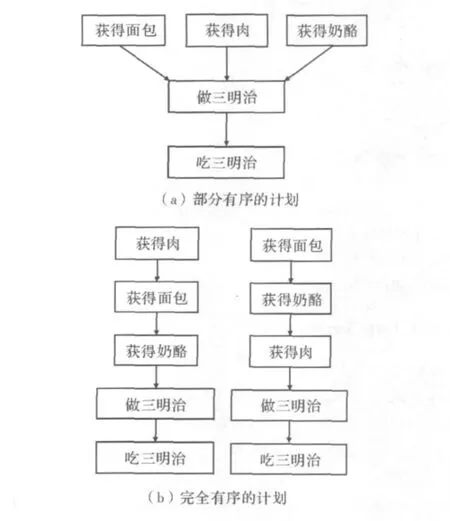
图1 部分和完全有序计划
首先,给予一个部分有序的计划,为了执行计划的行为,一个代理在某时不得不明确地或含糊地定义一个完全有序计划。也就是说,代理仍然需要在任何数量的未排序的行为中选择一个行为来第一个执行。在这个基础上,有些原因解释了为什么在其他行为前执行一个行为可能是有利的,但是代理选择第一个行为的原因可以很容易地被抽象到计划者自身。
游戏传统地处理完全有序计划的第二个主要原因是用A*来创造计划的方便性。因为A*是一个众所周知并且多用途的算法,对于面向目标的计划系统是一个好的选择,而且A*本质上产生完全有序计划。文献[2~4]覆盖了许多用于游戏中实现A*计划系统的实践细节。
2 用于面向目标计划的计划合并
计划合并适用于采取一些独立生成的计划并从中生成一个单独计划的过程,通常伴随着减少计划的总体开销的目的。减少了开销的计划往往也有着产生更合理行为的益处。
利用一个计划系统,可以有很多方式完成这个行为。假设收集道具并返回家的目标叫做道具返回目标。可以写一个收集道具行为来完成这个目标。一个执行收集道具行为的代理会寻找最近的道具,尽可能多地收集,然后带着它们返回家。虽然这是一种解决方案,但很明显,收集道具行为会非常复杂。它需要包括寻路和在道具间移动,拾起道具,寻路回家,以及到达之后放下道具的代码。为了使在一个行为中增加的功能起作用,会挫败拥有一个灵活的计划系统的目的。
普遍会选取两个有重叠行为的计划,把它们合并为一个比单独执行每个原本计划开销要低的单一计划。在这个例子中,代理可以计划独自收集每个道具,产生两个不相关但十分相似的计划,如图2(a)所示。合并这样的两个计划的可能结果是尽可能合并更多的行为,产生单独的计划,如图2(b)所示。当代理执行这个计划时,它会在回家前收集两个道具。
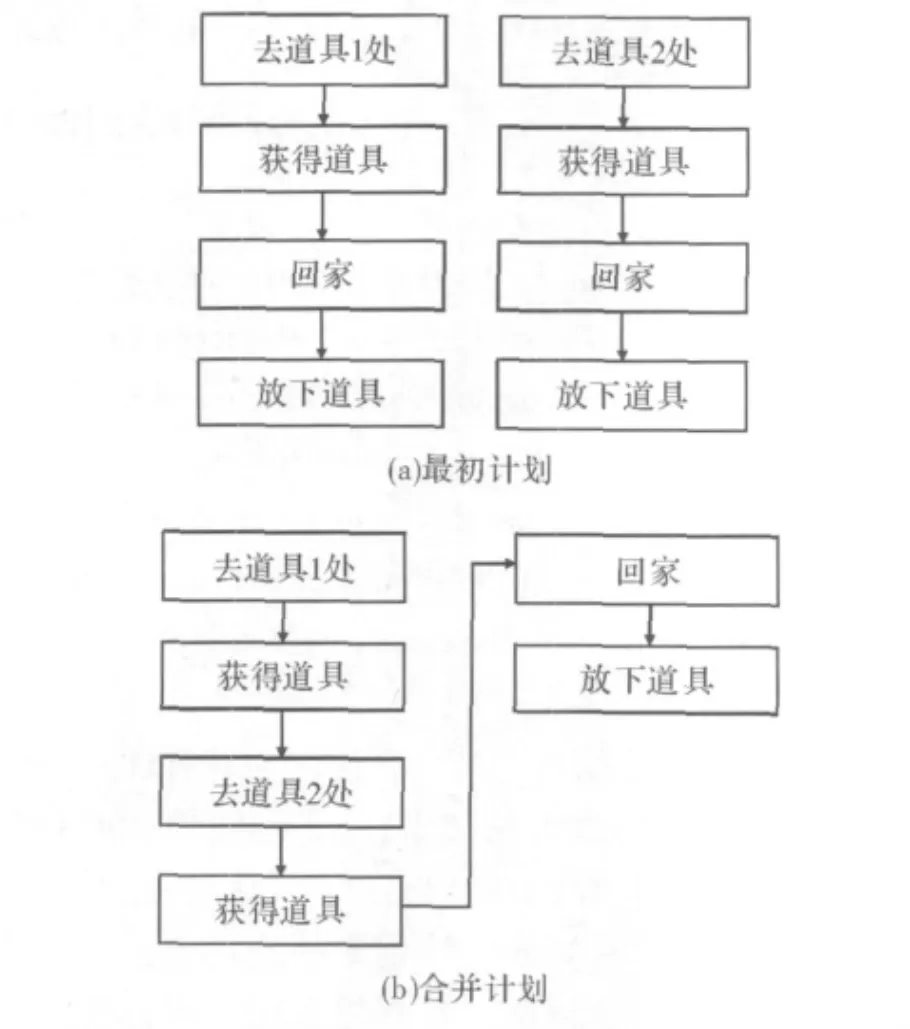
图2 两个完全有序计划和它们可能合并的结果
2.1 实现一个计划合并算法
计划合并的主要目的是优化计划。文献[1]指出了优化一个计划的两个主要组成部分,一是找到可以被合并的行为;二是如果存在多于一种合并操作的方法,则算出最优的方法来合并行为。分开处理这些问题会更容易,所以我们在本文中采用这种方法。
寻找可合并行为的第一个挑战在于准确地发现什么类型的行为可以被合并。但是简单来说,如果有另一个行为可以用下面的结果来代替被合并的行为,任何行为都可以被合并。
(1)如果行为有相同的有用的效果。
(2)如果用来代替的行为的开销小于被合并行为的开销总和。
如果效果直接为计划中的另一个行为建立了前提条件或者是目标本身的前提,那就是有用的。比如,假设一个代理计划用开火和上膛行为来摧毁目标。上膛行为有很多效果,首先,它使武器有子弹,其次,它减少了代理的弹药量。第一个效果是有用的,因为它完成了计划中另一个行为的前提条件。第二个效果没有用,因为它与计划的执行无关。
如果没有行为本身的信息,搜索可合并行为计划的开销会很大,所以最好寻找那些已知可以合并的行为。在一个已实现的系统中,这意味着要么寻找自己可合并的特定行为,要么寻找已知的可以合并的行为组合。在早些的资源收集例子中,知道代理会有多种计划,每一个都有Returnltems行为。这就是一个要寻找的完美的候选行为,因为知道可以合并两个Retumltems行为。在这个特定的例子中,甚至可以从计划的末尾开始寻找,因为很可能是每一个计划中的最后行为可以被合并。GoTo(Base)也可以与自身合并,因为它显然可以完成同样的效果。
最简单的是,接下来合并计划算法接受由通用A*计划系统生成的两个计划。比如,代理可以把它最重要的两个目标发给计划者,然后把那两个独立的计划发送给计划合并者。对于第一个计划的每一个行为,算法检查它是否可以被第二个计划的一个行为合并,如果可以执行合并,那两个行为被放到一个单独的计划中。从两个计划中放置合并行为前的行为要小心,对于在合并行为后的行为也是一样。如果需要对未合并行为的顺序进行更精确的控制,可以加入评价来决定最好的顺序,并且根据需要重新安排行为的顺序。对于更广范围的可能合并来说,一个完整的计划合并算法应该在每一个计划中检查每一个可能的行为组的综合效果,寻找一连串的行为可以被一个单独的、更廉价的行为所代替的情况。这样一个算法对可合并计划产生非常可观的改进,但是运行起来开销同样巨大。
2.2 超越单代理合并
虽然为一个单独的代理合并两个计划确实可以改进行为,但计划合并同样在分组行为区域中可以提供益处。比如,一个利用计划合并的代理可以合并一个单独的目标和分组目标。在这些情况下,利用计划合并可以允许一个代理在分组顺序下维持它自己的目标和个性,甚至允许代理同时完成很多目标的情况。
2.3 提高行为搜索的战略
搜索带有相似效果的两个或多个计划行为是昂贵的,特别是如果考虑用不同的综合效果代替行为组。如果游戏是快节奏的,代理的第一个和第二个目标会变换得更快,甚至可以为它的第二个目标设计计划。确实,如果不能快速执行合并,计划合并是没有用的。
一个可能的减少搜索行为时间的战略是只在计划存在特定行为时才搜索可合并的行为,这可以在计划决策过程中做出决定。对于非常长的计划来说,计划结构本身会带有直接与可能合并的行为的联系,不仅要指示算法立刻进入正确的位置,并且也会通知它是否值得搜索一个合并。在特定类型的代理中,在每一个计划中只寻找特定行为来合并也是值得的。
相似地,也许只在计划目标相容的情况下才尝试合并。相反地,如果两个计划之内的目标不相容,也就没有意义去费力地尝试合并。确实,如果目标不相容,即使为第二个目标做计划也一是浪费时间。这个决定可能最好由程序员做出。显然,攻击和撤退目标永远不会产生可合并的计划,但是算法会在报告没有可合并行为存在之前搜索每个计划的每一个行为。
3 结束语
计划合并提供方法来改进代理在单独或组行为时的可感知智能。虽然可能是一个开销十分昂贵的过程,但应仔细地考虑,可以通过花费一小部分额外的时间检查生成的计划来完成它。文献[5~6]介绍了不同的执行计划合并的系统和方法,也许更适合于比这里描述的代理行为更长的代理。比如,在[6]中描述的计划合并算法特别适合于策略游戏AI对手,可以用多种不同的方法来完成目标,并且可能延迟行为来利用明确的合并机会。
计划是一个多功能的AI系统,有很多的机会来进行扩展和改进。即使在给定情况下计划合并没有用,但其提出的想法可以应用到其他AI系统中,或者甚至是其他的像分级任务网络(HTNs)那样的计划系统中。这种技术提供的行为改进使得代理有更好的智能,同时使玩家有更好的游戏体验。
[1]FOUSLER D,LI Ming,YANG Qiang.Theory and algorithms for plan merging [J].Artificial Intelligence,1992,57(2 -3):143-181.
[2]ORKIN J.Applying goal- oriented action planning to games[M].Charles River Media:AI Game Programming Wisdom 2,2004.
[3]ORKIN J.Symbolic representation of game world state:toward real- time planning in games[R].USA:AAAI Challenges in Game AI Workshop Technical Report,2004.
[4]ORKIN J.Three states and a plan:the AI of FEAR[C].USA:Proceedings from Game Developers Conference,2006.
[5]THANGARAJAH J,WINIKOFF M,PADGHAM L,et al.A-voiding resource conflicts in intelligent agents[C].Syato:Proceedings of the 15th European Conference on Artificial Intelligence,2002.
[6]THANGARAJAH J,PADGHAM L,WINIKOFF M.Detecting&exploiting positive goal interaction in intelligent agents[C].Fukong:AAMAS'03,2003.
