提高个性化推荐精度的定制Web日志方法
2011-05-31苏玉召中科院国家科学图书馆北京100190
苏玉召 (中科院国家科学图书馆 北京 100190)
牛晓太 赵 妍 (郑州航空工业管理学院 河南郑州 450015)
随着网络信息技术和智能软件技术的发展,数字图书馆服务质量也得到了大幅度提高。一些数字图书馆网站不但能够利用网络信息技术提供图书馆员和读者在线互动,而且实现了个性化推荐服务。这样的服务不但提高了图书馆服务效率,而且方便了读者获取相关文献和定期更新的内容。这是一种智能服务系统,由系统自动将用户感兴趣的图书、文献和服务信息推送给用户,并以用户电子邮箱、注册账户页面和手机屏幕等方式呈现。同时,这种服务可以采用商业化模式运行,实现读者付费方式购买和网络下载。记录了用户访问网站过程的查询、下载和交易等操作信息的Web日志数据就是一种这样的数据。[1]通过对这些数据的处理和分析,能为企业发展做出正确的决策和预测提供事实依据。同时,个性化推荐系统实现了吸引用户、增加人气和增值服务的目标。
通常,个性化推荐系统分为基于规则过滤、基于内容过滤、基于协作过滤的方法以及这三种方法混合的具有智能性的推荐方法。[2]普通的Web日志格式采集到的数据无法满足用户分析、预测和推荐精度的需要,大部分定制专门的Web日志格式暂时能够满足目前业务需要。同时,各个企业定制的Web日志都是根据自己的需要,没有统一的规范和标准化可以遵循,不利于将来数据中心进行数据集成和业务扩展。
本文通过对个性化推荐和数据建模研究,指出普通Web日志格式存在的不足,提出定制Web日志数据建模的过程及方法,建立了基于NSTL嵌入式系统的定制Web日志模型原型。通过定制Web日志的方式采集数据,实现发现关联规则、内容分类和用户聚类分析,从而提高个性化推荐的精度。
1 定制Web日志
1.1 问题描述
NSTL定制Web日志数据建模的目的,主要是通过捕获用户访问活动操作浏览、查询、下载、收藏、兴趣定制和购买等信息,借助数据挖掘技术发现用户访问偏好,进行个性化推送服务,实现NSTL更好的数字图书馆服务功能。通过记录Web日志的方式,在线收集读者文献查询、下载和购买等信息的数据。系统对读者访问的这些日志数据进行分析、挖掘和预测,为其提供相关文献推荐和定期更新内容推送服务。
1.2 日志建模
Web日志数据是一种特殊的数据类型,因此,数据建模理论适用于进行 Web 日志数据建模的应用研究。[3][4][5]个性化推荐内容的准确性,依赖于挖掘后获取的用户访问内容的具体分类。Web日志中记录的操作对象属性完整性、准确性和唯一性,能够提高定制Web日志的数据质量。
Web日志数据的特殊性在于:采集的数据都是基于用户在Web页面上的访问行为,包括用户在前台的操作活动和应用程序在后台记录访问的信息。因此,Web日志数据记录的是用户和网站的交换行为。进行Web日志数据建模应明确以下几方面:
(1)建模采用的模型类型,在不同的建模阶段,分别采用概念建模、逻辑建模和物理建模。
(2)建模方法,步骤:①弄清要做的事情包括哪些;②弄清捕获的数据固有的质量水平;③重点弄清需要捕获用户访问需要记录的Web日志数据的定义;④重视数据质量;⑤弄清不同用户对不同层次建模的不同需求。
(3)建模项目类型,主要有三类:①企业项目模型,需要捕获全部动态数据;②交易项目模型捕获一次一个用户活动的具体信息;③数据仓库/企业报表项目空间模型收集一次一个用户活动的具体信息,并选择和集成为简化准确的报表。
(4)项目使用目标,是通过定制的Web日志数据,在数据质量方面实现提高个性化推荐的精度。
(5)业务类型,捕获的数据对象和用户与网站的交互活动有关。在Web日志数据建模方案中,与用户活动相关的操作包括:浏览、查询、下载、个人收藏、兴趣和偏好定制和商品购买等,应用程序的业务根据这些用户活动捕获日志数据对象。
(6)业务对象,捕获的Web日志数据对象,就是建模过程中需要处理的业务对象。在不同的业务平台,用户活动操作的对象也各不相同。在数字图书馆领域,业务对象主要是文献,这些文献可能是期刊、会议、书籍、专利或者报告等。
(7)对象属性,不同的业务平台,捕获的Web日志数据对象属性也各不相同。数字图书馆文献的属性主要包括题名、作者、关键词、出版社、文献类型、所属领域和出版日期等。
(8)属性命名规则,由于Web页面存在结构化、半结构化和非结构化的数据对象,因此,需要将捕获的日志进行结构化处理,记录的日志数据严格按照设计的命名规则处理。
(9)用户信息,主要记录用户注册信息、兴趣和偏好定制、个人收藏等。
(10)访问时间,用户的浏览、查询、下载、个人收藏、兴趣和偏好定制和商品购买等活动的时间变化,能够体现其对该网站访问的习惯、忠诚度和偏好的变化。
(11)使用数据的用户,捕获的Web日志数据要满足不同用户的需求。在建模阶段,考虑使用模型的用户,不但包括建模技术人员,而且将来的用户还会包括数据分析师、决策者和进行业务扩展的应用程序开发技术员。
1.3 日志原型
NSTL日志模型属于交易项目,捕获一次一个用户活动的操作信息,采集的日志数据主要用于统计分析、个性化推荐。
在原型系统中,采集的Web日志信息主要包括4个部分:用户信息、用户操作信息、购物篮信息、订购信息。①用户信息主要记录用户注册的的个人信息,主要包括个人联系方式、访问Web页面的操作统计信息等,包括:用户标识号、登录名、真实姓名、电话号码、地址、注册日期、最后一次访问时间、登录次数、电子邮件、简单搜索次数、高级搜索次数、订购次数和订购总金额;②用户操作信息主要记录用户访问Web的方式、操作类型和操作对象,包括:用户标识号、访问时间、返回代码、客户IP地址、操作类型和操作对象;③购物篮信息主要记录用户已经放入购物篮,但还没有提交订购的信息。主要包括订购文献的名称、价格列表,金额和订单状态信息,包括:用户标识号、文献列表、文献数量、价格列表、购物篮金额、订单号和是否发送邮件确认;④订购信息主要记录用户订单号、日期和订单处理状态,包括:用户标识号、订单号、订单日期和订单状态。
1.4 日志数据预处理
本文实验所用数据来自NSTL嵌入式资源服务系统2周内采集到的用户访问日志数据。按照日志数据清洗、转换、加载的流程对日志数据进行了预处理(见图1)。
数据清洗主要分为两个步骤:去除冗余和无效记录、分割关键字段。去除冗余是为了减少重复出现的字段,降低在数据挖掘阶段权重重复的可能。去除无效记录是为了减少一些错误的记录数据、删除没有登录的用户访问记录,目的是有针对性地为注册用户提供个性化推荐服务。将用户访问时输入的关键词、操作类型和操作对象分割开来,增加数据挖掘是用户兴趣和偏好的比重,便于更好的提供个性化推荐服务。
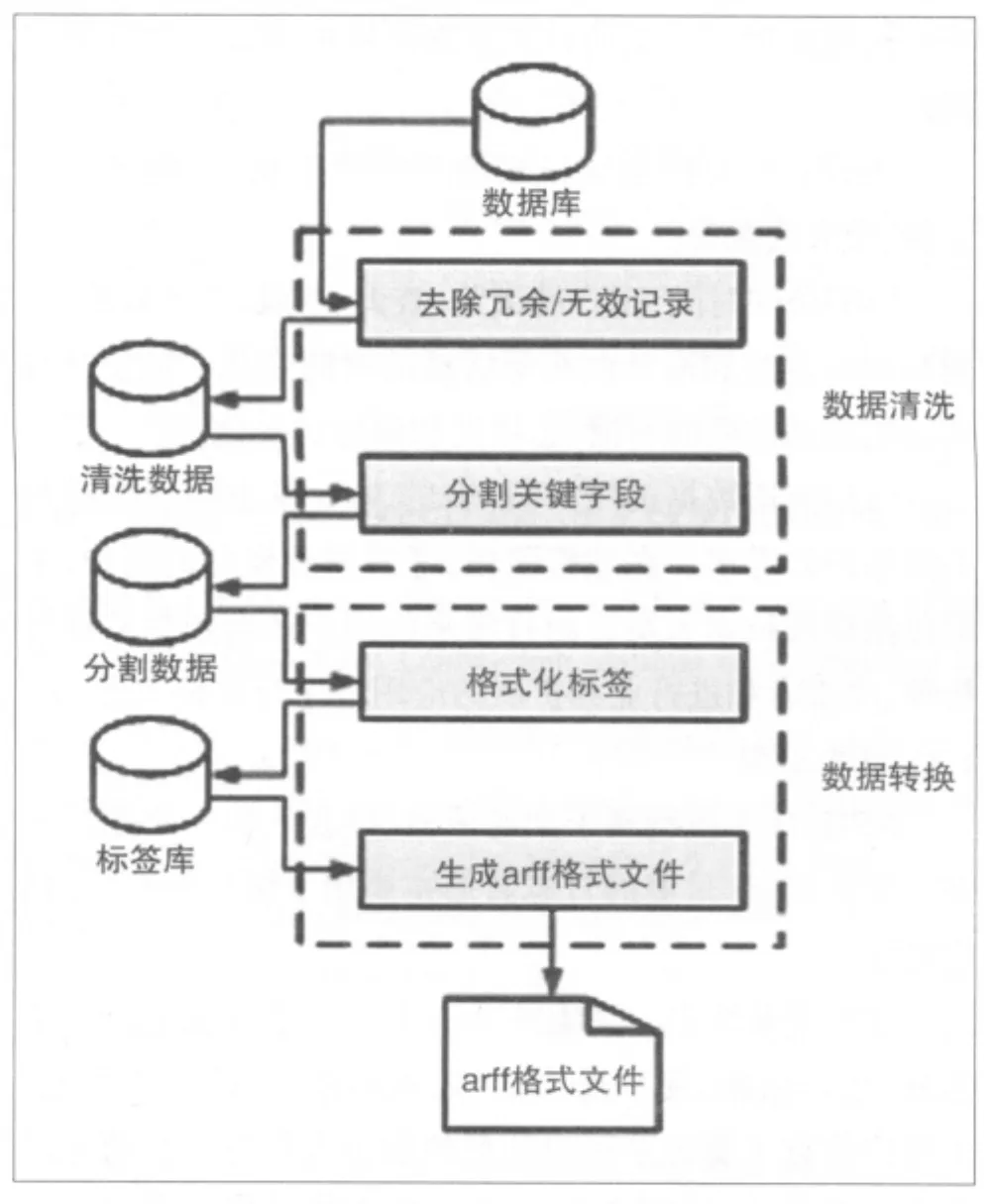
图1 NSTL日志数据预处理
数据转换的目的是将清洗过的数据转换为挖掘工具易于识别的数据类型和格式,为的是得出理想的挖掘结果,从而便于发现用户兴趣和偏好。数据转换主要分为两个步骤:格式化标签与生成arff格式文件。统计分析日志数据中重复出现的数据对象、操作类型、关键词,用标签的方式进行唯一标示,这样做的好处是易于生成数据挖掘工具需要的数据格式,也节省了挖掘计算时间。生成的arff文件格式,可以方便地导入一些挖掘工具,例如Weka和RapidMiner等。
2 实验结果及分析
在个性化推荐应用领域,通过Web日志挖掘技术,发现用户兴趣、使用偏好,推荐用户可能感兴趣的内容,帮助用户快速找到需要的内容,吸引用户对本系统的忠诚度,提高个性化服务能力和水平,实现价值增值。定制Web日志数据的方式能够提高个性化推荐的精度,并且能够简化数据预处理工作、提高系统效率。用于Web日志挖掘的技术主要分为三类:关联规则分析、分类分析和聚类分析。
2.1 关联分析
在Web日志挖掘研究中,关联规则分析目的是找出用户访问的日志中,所执行的操作与操作、操作和访问对象、对象和对象之间的关系,进而预测用户行为、兴趣和偏好。
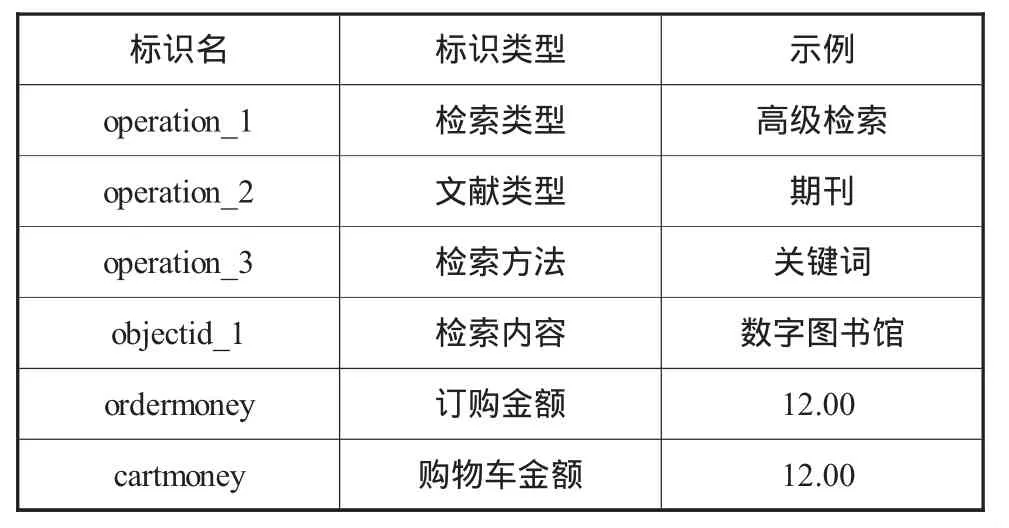
表1 关联项目标识定义
图2 FileteredAssociator发现的关联规则
在实验中,根据 Apriori算法[6][7],枚举出 10 个经过过滤的规则,在枚举过程中,不断减小最少支持度需找需要的并能满足最小置信度的规则(实验结果找到的前10条FilteredAssociator规则见图2,其关联项目标识定义见表1)。可以看出,具有很强的关联关系的属性是检索类型、检索方法、文献类型和检索内容,根据这些关联规则预测更喜欢的推荐方式,将会更加吸引注册用户的兴趣。同时发现,用户一旦将订购的文献放入购物车,其购买项目的可能性就很大。可以推断,此类用户有很强烈的需求,在个性化推荐的时候,要重视推荐给此类用户的质量,以维护其较高的客户忠诚度。
通过关联分析,能够发现隐藏在定制Web日志数据里的操作对象和内容之间的关系,找到用户的访问兴趣偏好、访问习惯,预测用户可能的需求。
2.2 分类
实验采用J48算法生成剪枝的C4.5决策树[8],以用户操作类型为分类的类标,主要针对用户操作进行分类(类标说明见表2,分类结果见图3)。
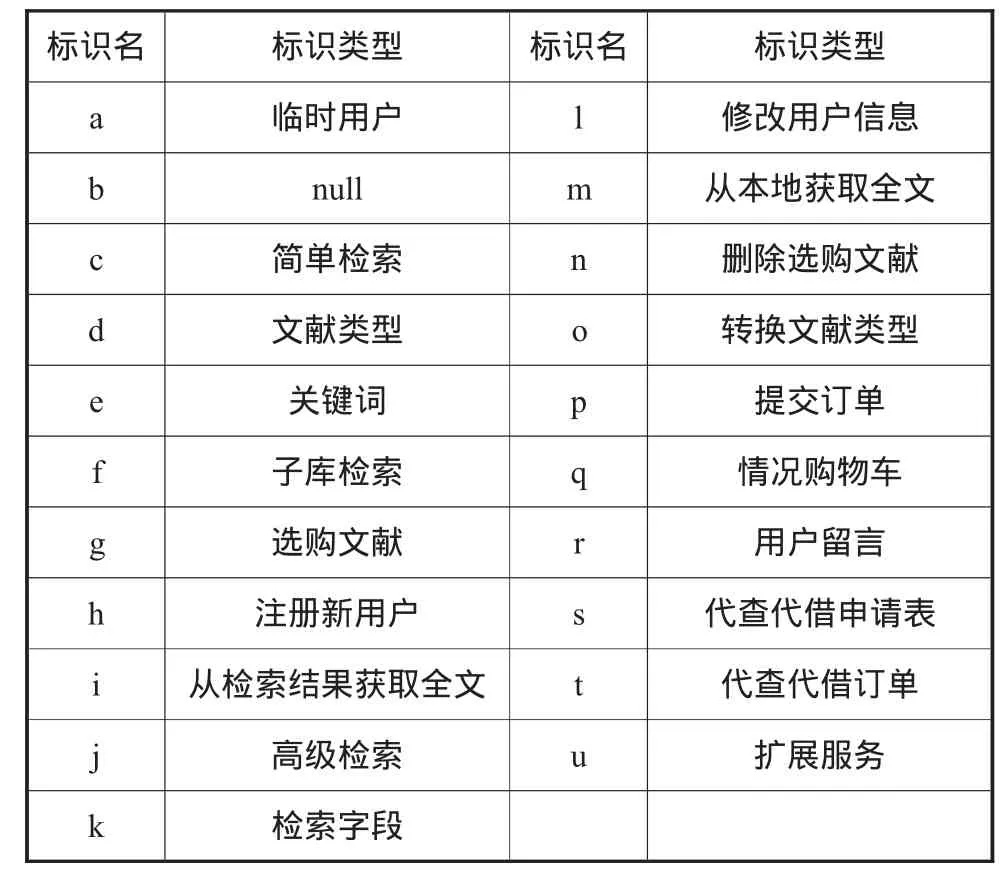
表2 用户操作类型
从图3实验结果可以看出,用户最常使用的方法是简单检索,分析原因可能有两点:用户不熟悉本系统的检索方法或者是系统没有提供个性化的服务功能。同时,还可以从图中看出,有一些显著的特征,分别是:高级检索、从检索结果获取全文、选购文献和提交订单。从特征的显著性程度看,高级检索与选购文献、提交订单有着相似之处,因此,分析他们之间有较强的相关性,个性化推荐时候,可以考虑这种类别的用户,重视推荐质量。相比较而言,用户更喜欢直接从检索结果中获取全文,符合人们的常规习惯和方法。
通过分类挖掘,可以发现用户感兴趣的内容、类别、属性,可以预测其潜在的客户价值并实现个性化内容推荐。

图3 J48分类用户操作类别
2.3 聚类
实验采用 Cobweb 算法[9][10],其特点是:通过添加新叶子节点、合并或者分裂的方法实现聚类,是一种增量学习算法(对用户和实例数目进行聚类实验结果见图4)。从图中可以看出,聚类结果为4类典型的用户特征。最显著聚类用户的特征是使用简单搜索、订购数量少和检索期刊等,这是大多数用户使用的方法。
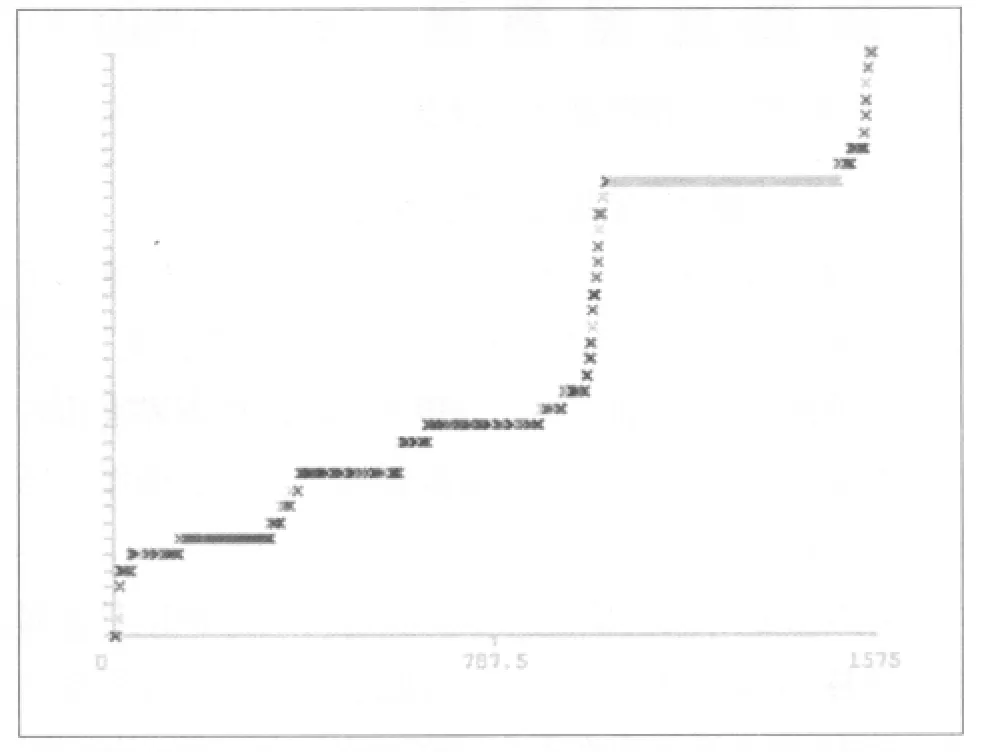
图4 Cobweb用户-访问实例聚类结果
找到为用户推荐的内容是聚类分析的关键,将用户访问的内容进行聚类,为相似用户推荐,实验结果见图5。图5中横向坐标表示检索内容的领域,纵向坐标表示文献类型。从图中可以看出,用户访问的文献领域分布比较广泛,但是文献类型主要分为两种。出现这种情况的原因是,采集到的日志数据时间间隔较短,可能用户研究方向各不相同,但是访问的文献类型较集中,再根据分类和关联实验结果分析,推测用户具有类似的访问行为。因此,推荐的时候,可以根据这些文献类型进行推荐,例如,重点推荐期刊相关的文献内容。
通过聚类分析,可以发现相似用户的访问行为和兴趣偏好,通过系统对相似用户的推荐,可以提高系统性能和效率,实现个性化推荐。定制的Web日志数据具有针对性强的特点,能够准确地记录用户的访问行为和操作内容,提高个性化推荐的精度。

图5 Cobweb检索领域—文献类型聚类结果
2.4 性能评价
在实验过程中,分别选取了几个操作类型进行记录日志前后计算时间的对比(实验结果见图6)。
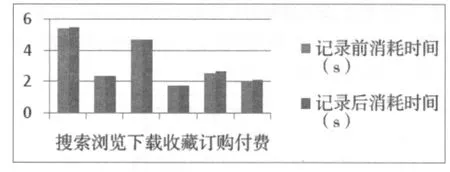
图6 记录日志前后时间对比
从图中可以看出,记录日志前后消耗的时间差别不明显。实际上,由于记录是在用户客户端收集信息,不消耗服务器的资源。同时,写回到服务器端的数据库表执行的是在表的尾部插入操作,不需要执行查找的操作。因此,记录日志的代价很小。
Web日志分类实验中,主要检验记录的操作对象属性完整性、准确性和唯一性,是否能够提高日志的数据质量。其中,完整性体现在用户操作过程是否连贯、完全,这些必要的信息缺失或者缺省会导致生成的日志数据无法识别用户偏好内容;信息准确或者精度不够,可能导致推荐精度不够,无法满足用户需求;数据的唯一性是数据库中该文献是否存在及存在情况等信息。
实验中,采用传统的关联、分类和聚类算法的目的有两个:一是保证实验的算法在成熟的情况下,实验结果具有普遍意义;二是利于发现实验中的Web日志模型存在的问题,促进该模型以后进一步完善。根据实验结果分析,生成的关联规则具有可用性,实验结果与人工分析进行比较,能够发现数据中存在的关联规则。用户操作方法的分类结果也基本与实际情况相符。聚类分析实验中,分别对用户访问的实例和操作对象进行分析,实验结果基本能够识别出用户所在类别,但是存在聚类不集中的情况。
根据以上分析,定制的Web日志数据能够同时满足发现关联规则、内容分类和用户聚类分析的需求,可以更好地满足个性化推荐精度的需求。同时,定制Web日志还具有简化数据预处理、多用途的优点。
3 结语
本文对数据建模技术进行研究,分析定制Web日志数据的建模方案。通过基于NSTL的日志数据模型原型的实验结果及分析,验证提出定制的Web日志数据建模方法和步骤。根据实验结果分析,该模型具有一定的可行性。但是,原型系统中还存在诸多问题需要进一步解决。如方案中还没有对捕获的日志数据如何进行具体结构化问题进行深入探讨,捕获的对象的命名方式还要进行标准化处理。此外,实验使用日志数据的完整性、准确性和唯一性问题,还需要进一步详细化、具体化和准确性解决。
[1]苏玉召,赵妍.个性化关键技术研究综述[J].图书与情报,2011,137(1):59-65.
[2]苏玉召等.一种基于智能过滤的Web个性化推荐模型[J].图书情报工作,2011,55(13):112-115.
[3]Sharon Allen,Evan Terry.Beginning Relational Data Modeling(Second Edition)[M].New York:Apress,2005.
[4]Reingruber,M.,W.Gregory.The Data Modeling Handbook[M].New York:Wiley,1994.
[5]Alan Chmura,J.Mark Heumann.Logical data modeling-What it is and How to do it[M].New York:Springer,2005:35-55.
[6]R.Agrawal,R.Srikant.Fast Algorithms for Mining Association Rules in Large Databases[C].The 20th Internatio nal Conference on Very Large Data Bases,1994:478-499.
[7]Bing Liu,Wynne Hsu,Yiming Ma.Integrating Classification and Association Rule Mining[C].the Fourth International Conference on Knowledge Discovery and Data Mining,1998:80-86.
[8]Ross Quinlan.C4.5:Programs for Machine Learning[M].San Mateo:Morgan Kaufmann Publishers,1993.
[9]D.Fisher.Knowledge acquisition via incremental conceptual clustering[J].Machine Learning,1987,2(2):139-172.
[10]J.H.Gennari,P.Langley,D.Fisher.Models of incremental concept formation[J].Artificial Intelligence,1990,(40):11-61.
