一种基于支持向量机的行人识别方法研究
2011-02-08张明恒李琳辉赵一兵
郭 烈, 张明恒, 李琳辉, 赵一兵
(1.大连理工大学工业装备结构分析国家重点实验室,辽宁大连116024;2.大连理工大学汽车工程学院,辽宁大连116024)
0 引 言
作为一项汽车主动安全技术,行人检测系统能及时为驾驶员提供预防碰撞行人的警示信息,保障行人和驾驶员的安全.目前,越来越多的单位和机构开始行人检测技术的研究,如欧盟的PROTECTOR计划和SAVE-U计划,均采用多传感器信息融合来保护行人或骑自行车人等弱势交通参与者;法国的PAROTO项目融合雷达和红外图像来探测车辆前方的行人或车辆等障碍物,并对其进行运动分析[1、2].国外大学如Parma、CMU、MIT和国内的西安交通大学、清华大学、吉林大学以及中国科学院自动化研究所等也在该领域开展了相关研究[3、4].
目前,行人识别主要依据行人的周期性运动特性或者行人的形状特征.通常,人体在行走时,其步态会呈现周期性特性,结合图像序列进行分析,可确定其是否为运动的行人.如Heisele等[5]用时滞神经网络的聚类算法分析行人脚部的周期性运动模式来识别行人.但是,该方法只对运动的行人有效,并需要多帧图像序列才能得出结果,导致响应时间滞后.基于行人形状特征的方法主要是采用统计学习的方法来分析候选区域,判断其是否为行人.这种方法对车辆前方静止和运动的行人均有效,但人形状的多样性,导致其对假目标比较敏感,因此,需要提取有效的特征进行训练和分类器设计[6].
本文综合行人的形态特征以及AdaBoost算法简单、实时性好的特点,首先利用AdaBoost算法训练得到的级联分类器快速获得图像中可能存在行人的候选区域;然后采用支持向量机SVM对表征行人的多维特征向量进行训练,从而得到识别行人的分类器,开展基于SVM的行人识别方法研究.
1 行人候选区域的分割
候选区域分割的目的是从图像中提取可能存在行人的窗口区域作进一步验证,避免穷尽搜索,以提高系统的速度.AdaBoost算法基本思想是学习得到一系列弱分类器,并按照一定的叠加方法构成一个强分类器,若干个强分类器再串联组成级联分类器.最后,利用这个级联分类器来完成对图像的搜索[7].
为快速分割图像中的行人候选区域,本文选择样本的类Haar特征进行训练.类Haar的每个特征由2~3个矩形组成,分别检测边缘和线性特征,其特征值是所组成的矩形区域的灰度积分之和[8]:

式中:w i∈R为矩形的权值,RecSum(ni)为矩形ni区域的灰度积分,k是矩形个数.
强分类器训练步骤如下:首先,给定N对训练样本(x1,y1),(x2,y2),…,(x N,y N),其中x i为表征样本的特征向量,yi∈{0,1}对应于非行人和行人样本.已知训练样本中有k个非行人和l个行人样本;初始化误差权重w1,i=D(i),当样本为行人时,D(i)=1/2l;当样本为非行人时,D(i)=1/2k.假设训练轮数为t=1,2,…,T,循环执行如下操作.
(1)权重标准化

(2)训练得到对应每个特征j的弱分类器

式中:p j表示不等式的方向,只能取1或-1;f j(x)表示特征值;θj为阈值.
(3)选择具有最小误差εt的简单分类器h t(x)并加入到强分类器中

(4)按照最佳的简单分类器ht(x)更新每个样本所对应的权重

其中如果第i个样本的特征向量x i被正确分类,ei=0,反之ei=1;βt=εt/(1-εt).
最后得到的强分类器如下:


上述训练过程表明,样本权重的调整主要依据分类器是否能对样本正确分类,如果分类正确,则减少这些样本的权重;如果分类错误,则增加其权重并进一步训练,强化对这些错误分类样本的训练.最终,所有的弱分类器以不同的权重组合形成一个强分类器.
样本的特征提取和分类器的训练是离线进行的,训练样本共980幅,其中行人样本516幅,非行人样本464幅,并将尺寸缩放成16×32,如图1所示.训练时,设置训练阶段数为18、每个阶段的检测率为0.995、虚警率为0.5.按照这个设置训练得到了18个强分类器,每个强分类器包含了若干个弱分类器及其分割阈值.表1列出了训练得到的前8个强分类器中所包含的类Haar特征及其数量.

图1 行人分割训练样本Fig.1 Sample images used for pedestrians segmentation training
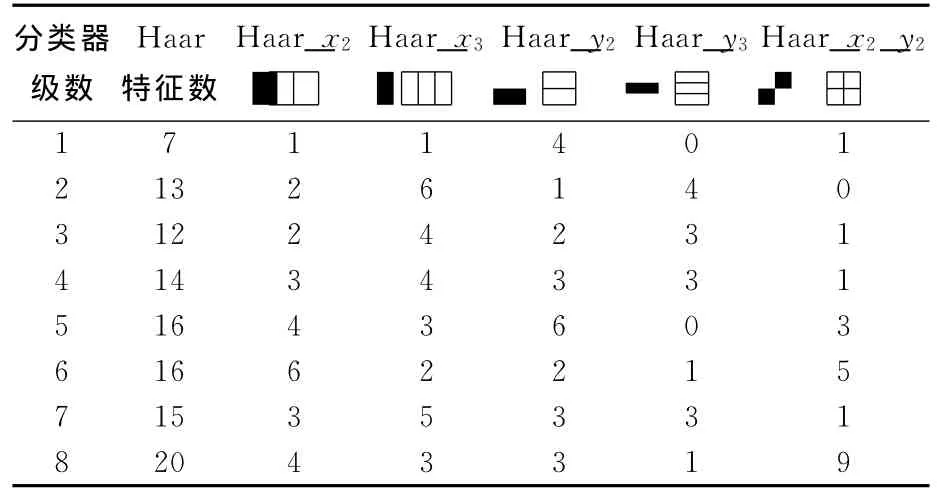
表1 前8个强分类器所包含的类Haar特征及其数量Tab.1 Haar-like feature and number of the first 8 strong classifiers
本文通过缩放检测矩形框来遍历扫描待检图像,以分割图像中大小未知的行人目标.本文待检图像大小为320×240,最小检测矩形框为32×64,根据试验确定将矩形框缩放1.2倍.具体扫描过程如下:(1)从待检图像的左下角开始,逐行每隔一个像素向右移动矩形框,直至达到图像边缘为止;(2)利用训练得到的级联分类器对待检矩形框进行判决:通过所有强分类器才被判定为行人窗口,否则,判定为非行人窗口;(3)将检测矩形框放大1.2倍,并按上述步骤重新对整幅图像进行扫描.
图2是行人候选区域的分割结果,由于道路两侧树木、电线杆以及其他道路设施等干扰,分割结果中可能存在一些误判为行人的候选区域.为此,需要进一步对候选区域进行判别分类,实现行人的识别.

图2 行人候选区域分割结果Fig.2 Results of the candidate pedestrians segmentation
2 基于支持向量机的行人识别
2.1 行人的特征提取
在进行训练之前,需要提取一系列描述待检目标的特征.通常,待检目标在很大程度上决定了提取什么样的特征.本文以行人作为待检目标,考虑到人体形状多样性和光照条件变化等因素的影响,将提取的行人样本灰度图像纹理和对称性特征以及边缘图像边界矩和梯度特征作为训练分类器的输入.
2.1.1 样本灰度图像的特征提取 通过分析样本图像发现,行人在图像中纹理特征比较丰富,尤其在行人脚与地面的接触区域、行人头部或肩膀与背景的分界处.而其他的一些干扰,如路面上车辆、道路两侧的树木等,其灰度分布一般比较杂乱,导致其纹理特征不明显.因此,本文采用纹理特征作为区分行人与非行人的特征之一.
目前,广泛采用的纹理分析方法是基于灰度共生矩阵方法,利用灰度共生矩阵来计算表征图像纹理粗细、惯性矩、纹理复杂度以及局部均匀性等特征[9].本文主要选用以下几个纹理特征来表征行人.
能量:反映纹理的粗细,计算公式为
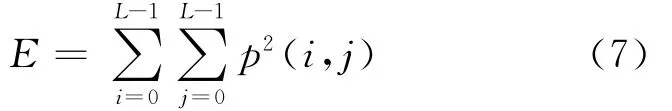
熵:表征图像纹理的复杂程度,计算公式为

惯性矩:反映局部像素对的灰度差别,计算公式为

局部平稳性:反映图像局部灰度均匀性,计算公式为
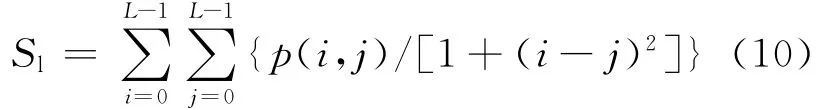
式中:p(i,j)为灰度共生矩阵第i行第j列的元素,L为灰度级数.
为消除光照不均对纹理特征提取结果的影响,本文将样本图像缩放成64×128,并进行直方图均衡化处理[10].同时,为保证提取纹理特征的旋转不变性,抑制方向对其影响,本文分块处理计算图像的纹理特征,最后取平均.分块原则是两像素间隔为5、块大小为16×16,按0°、45°、90°、135° 4个方向计算灰度共生矩阵.这样,每种特征在每个方向上都有特征值,取这4个方向的平均值作为样本的纹理特征.图3是提取的部分纹理特征.

图3 训练样本纹理特征比较Fig.3 Comparison of the texture features of sample images
灰度图像的另一特征就是对称性.由于行人衣着颜色和腿部形状通常是左右对称的,在灰度图像中往往表现出明显的对称性特征[11].灰度对称性的计算基于以下思想:图像的每行灰度值可当成水平像素坐标的一维函数g(x),该函数是偶函数ge(x)和奇函数go(x)之和,利用奇函数和偶函数的相对大小来反映函数的对称度,偶函数占的比重越大,该行像素越对称.对称性测度计算公式如下[12]:

式中:xs为对称轴位置,b为对称宽度,Eo为奇函数的能量函数,E′e为归一化偶函数的能量函数.对称性测度s为区间[-1,1]内的任意数,s=1表示完全对称,s=-1表示完全不对称.本文依次以图像中央20列中每列为对称轴,计算该列两侧22个像素范围的对称性,并取平均值作为该列的对称性测度,最后取各列中的最大值作为该样本的灰度对称性特征值.
2.1.2 样本边缘图像的特征提取 通过对样本边缘图像分析发现,行人的外形轮廓使其具有明显的边缘,呈现丰富的边缘特征,尤其是在行人的腿部区域,行人的垂直边缘比较明显,并且比水平边缘多.而对于非行人样本边缘图像,其边缘通常是不规则的,有的具有丰富的水平边缘,有的具有丰富的垂直边缘.因此,为了消除光照对行人识别的影响,本文还提取了表征行人的边缘图像特征进行分类器的训练.
在众多的边缘提取算子中,Canny算子在图像去噪和细节保留上取得了较好的平衡,能在图像边缘模糊的情况下较好地提取边缘[13].图4(a)为原始图像,本文采用Canny算子对样本进行边缘检测,如图4(b)所示.从图中可以看出,该算子能较好地提取行人的边缘轮廓,但同时也存在一些干扰噪声,如行人头部与背景部分边缘较多.为去除部分不连续边缘的干扰,减少计算的复杂度,本文对边缘提取结果进行了边界跟踪,并记录跟踪的边缘点数,保留边缘点数超过20个像素点的边缘作为人体轮廓,如图4(c)所示.

图4 样本的边缘提取及边界跟踪结果Fig.4 The edge abstraction and tracking of sample images
从边界跟踪结果可知,人体特定形状使其具有一定的轮廓和矩,可利用跟踪的边界像素计算各种边界矩特征.文献[14]介绍了只利用目标边界信息来计算矩的方法,并推导证明了由此算得的Hu不变矩同样具有平移、旋转和尺度缩放不变性.本文选用前两个Hu不变矩作为表征行人的边界特征,部分行人和非行人样本边界矩如图5所示.
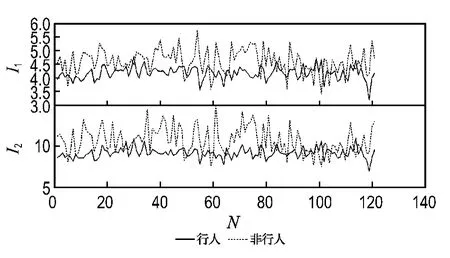
图5 样本图像的前两个Hu不变矩Fig.5 The first two Hu invariable moments of samples images
利用Canny算子提取边缘的同时,还能获得图像的梯度方向.梯度方向值一般在[0,π),为了形象地表示图像的梯度方向,本文将其用0~255的灰度值来表示,值越大表示梯度方向值越大,如图6所示.梯度方向的最大值一般出现在一些边缘比较明显的地方,而在一些纹理比较一致的区域,其值一般很小.行人的上半身,尤其是行人头部所在的区域,由于复杂背景的干扰,其梯度方向值变化比较显著;而行人的下半身所在的区域,由于背景是灰度比较均匀的路面图像,而腿部占据图像比例较大,其边缘比较明显,导致在某些梯度方向上存在最大值[15].

图6 样本图像的梯度、梯度方向及区域划分Fig.6 The sample images gradient,gradient orientation and the area to be considered
为降低计算的复杂度,本文只分析了存在行人腿部的下半部分的梯度方向特征,如图6(d)所示,根据左右腿可能存在的区域,将图像的下半部分对称分为a、b两个区域,将梯度方向值按20°间距等分为8个区间,统计图像中每点梯度方向落在各个区间的概率.因此,对于a、b这两个区域均能得到8个区间的概率值.这样,每个样本就有16个梯度方向概率值,并以此作为该样本的梯度方向特征.
2.2 基于支持向量机的行人识别
决策识别是行人检测系统的核心,它对分割的候选区域进行验证,以判断其是否包含行人,分类性能决定了整个检测系统的精度和鲁棒性.在统计学习理论中,支持向量机能获得比传统学习方法更好的泛化和推广能力,尤其是在解决小样本、非线性学习问题,在高维输入矢量或者没有先验知识的情况下,对于二类分类识别是一个理想的选择.本文的识别目标为行人,是一个典型的二类模式分类问题,因此,本文选择支持向量机学习方法,对所提取的多维特征向量进行训练,得到识别行人的分类器.
支持向量机方法通过适当的内积函数实现某一非线性变换,将不可分的样本转化为高维特征空间,使其在该特征空间中线性可分,得到最优分类面[16].支持向量机的决策函数在形式上与神经网络类似,函数的输出是各中间节点的线性组合,每个中间节点就是一个支持向量,其结构示意图如图7所示.
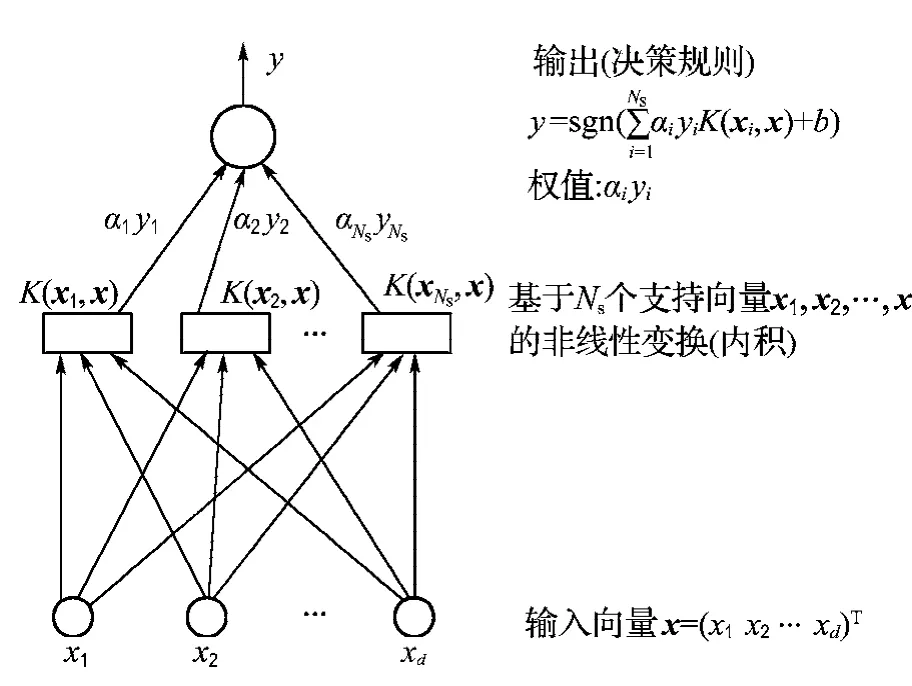
图7 支持向量机结构示意图Fig.7 The architecture of support vector machines
3 试验结果与分析
3.1 分类器训练的输入
为了得到行人识别分类器,本文选取与分割训练样本数一致的由516个行人和464个非行人组成的另一组样本集,共计980个样本,样本大小为64×128.训练的输入x是一个23维的特征向量,依次为4个纹理特征、1个对称性特征、2个边界矩特征和16个梯度方向特征.训练的输出为y,当样本为行人时,其值为1;当样本为非行人时,其值为-1.
为了避免输入向量中一些较大的特征数值占有主导地位,而影响一些小数值范围的特征,有必要在进行训练之前对其进行归一化处理,从而减小计算的复杂程度.本文将输入向量的每个特征线性地归一化至区间[-1,1].
为测试与评价训练得到的分类器性能,本文选取了由260个行人和240个非行人样本组成的测试样本集,并采用与训练样本相同的预处理和特征提取方法得到测试样本集的特征向量.
3.2 训练参数的选择
分类器性能的好坏在很大程度上取决于核函数的类型、惩罚系数C以及核函数参数.常用的核函数是多项式核函数、径向基核函数以及Sigmoid核函数.本文在设置相同的惩罚函数的前提下,用对比分析的方法来确定适合的核函数,并用测试样本集进行分类器性能的测试,结果如表2所示,检测率Rd和虚警率Rf定义为[17]

其中N为测试集中的行人样本总数,本文N=260;n为分类器正确检测到的行人样本数;m为被分类器确定为行人的非行人样本数.
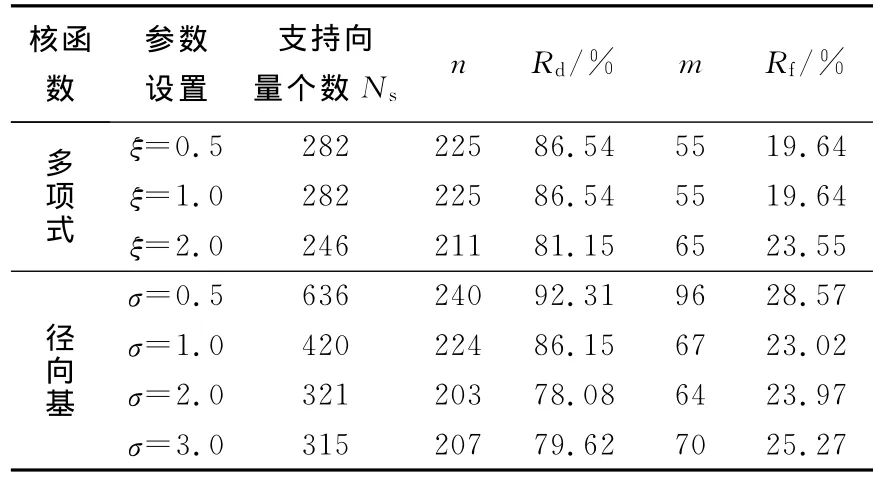
表2 不同核函数下SVM测试性能(C=1 000)Tab.2 The testing performance of SVM under different kernel functions(C=1 000)
从表2可知,要想获得相近的检测率,如86%左右,采用多项式核函数需要282个支持向量,而径向基核函数则需要420个支持向量,比多项式核函数方法多138个支持向量.支持向量数越多,意味着在分类决策时内积运算量越大.考虑实时性的要求,本文用多项式核函数方法实现特征向量的内积运算.
确定训练核函数后,下一步需要选择惩罚系数C以及核函数的阶数ξ.引入惩罚系数C是为了限制Lagrange乘子的范围,使得0≤αi≤C.由图7中的决策规则可知,惩罚系数越小,最优分类面的权系数就越小,从而扩大分类面的间隔,增强支持向量机的泛化能力,但可能导致其分类准确率降低.相反,如果惩罚系数越大,两类之间的分类面间隔就越小,从而降低了支持向量机的泛化能力,但这时的分类准确率可以得到提高.图8为各训练参数对分类器性能的影响,从图中可以看出,惩罚系数C和阶数ξ越大,支持向量个数越少,但分类器的检测性能变差.
通过比较,本文的训练参数确定为多项式阶数ξ=2、惩罚系数C=100,得到的分类器中支持向量个数Ns为238,包括123个行人样本和115个非行人样本.用测试样本测试该分类器,在虚警率为21.1%时,检测率达到81.9%.
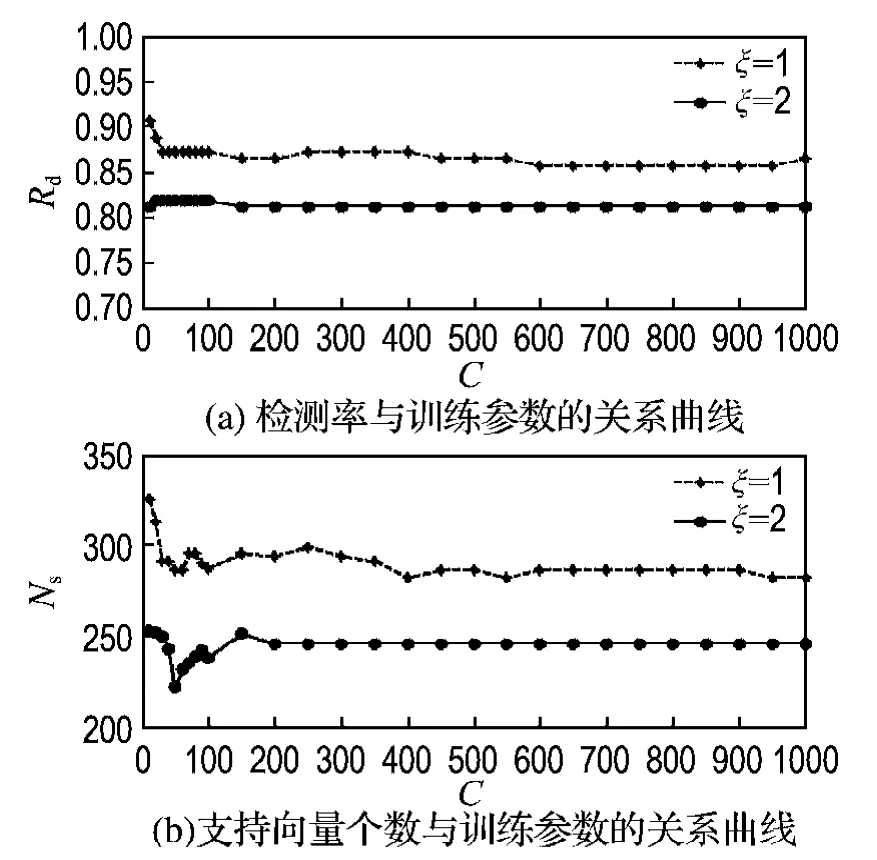
图8 训练参数对检测率和支持向量个数的影响Fig.8 The influence of training parameters to the detection rate and the number of support vector
3.3 行人的在线识别
本文行人识别分类器是在离线状态下用Matlab训练得到的,再用VC加载分类器的支持向量、Lagrange乘子αi及分类的阈值b,进行行人的在线识别.具体过程如下:
(1)根据级联分类器分割车辆前方可能是行人的候选区域,并将其像素尺寸缩放成64×128;
(2)提取该区域的纹理特征、对称特征、边界矩特征以及梯度方向特征,得到描述该候选区域的23维特征向量;
(3)利用行人识别分类函数对候选区域进行判别,如果输出为1,则判断该区域存在行人,否则将其剔除.
为验证算法的有效性,本文对所研究的方法进行了试验验证.试验平台为一台商用面包车,选用德国Basler公司生产的602f相机,安装在车辆前挡风玻璃后面.CCD获取的图像大小为320× 240,每幅图像处理时间为55~100 ms,处理速度为10~18幅/s,这与图像中行人数量和背景有关.采用跟踪算法后,算法时间还能减少.试验采集了80幅图像,其中有行人图像60幅(包含单个或多个行人83个)、无行人图像20幅(包含除行人之外的目标,如树木、汽车等),利用本文算法从图像中识别出89个行人,其中从有行人图像中正确识别的行人为62个,正确检测率约为74.7%.
在试验中发现一些行人漏检和行人误识别的现象.行人漏检主要是由于行人的重叠造成将两个或多个行人当成一个行人目标;行人误识别主要是由于道路两侧的复杂背景,一些类似行人目标的物体容易被误识别成行人,尤其是道路两侧的树木和电线杆等,其存在一定的灰度对称性和边缘特征等类似行人的特征.
4 结 语
本文提出了一种基于多特征的行人识别方法,首先利用AdaBoost训练得到的级联分类器按不同尺度遍历待检图像,去除绝大部分的非行人目标,分割出可能是行人的候选区域,然后利用SVM训练得到的分类器对各个候选区域进行识别确认,将不是行人的候选区域进一步排除,从而检测出图像中的行人目标.
本文通过试验验证了所提方法的有效性,同时,也发现了本文工作的不足,如由于行人的重叠造成的行人漏检和由于背景复杂性造成的行人误识别等问题,下一步工作希望提取有效表征行人的特征,研究行人跟踪方法并结合多幅图像检测结果来解决行人重叠问题,结合行人的步态特征来消除非行人物体的误判.
由于道路交通的复杂性,在行人检测系统的应用方面,还有很多问题亟待解决.在性能测试方面,还没有统一的测试数据和标准,需要建立一个公共的数据库和测试方法.在传感器方面,视觉传感器也有其局限性,首先是受光照和天气的影响较大,很难开发出适用于各种环境的算法;其次是视觉测距的精度很差,很难估算出行人的精确位置,这给评估行人的危险程度和开发准确的预警系统都带来一定的困难.未来不但需要提高视觉识别的可靠性,还要与其他传感信息进行信息融合,为实现可靠的预防碰撞行人系统提供准确的信息.
[1]GANDHI T,TRIVEDI M M.Pedestrian protection systems:issues,survey,and challenges[J].IEEE Transactions on Intelligent Transportation Systems,2007,8(3):413-430
[2]MEINECKE M M,OBOJSKI O M.Enhancing pedestrian safety by using the SAVE-U pre-crash system[C]//IEEE World Congress on Intelligent Transportation Systems and Services—World Congress.San Francisco:ITSWC,2005
[3]许 言,曹先彬,乔 红.行人检测系统研究新进展及关键技术展望[J].电子学报,2008,36(5):962-968
[4]郭 烈.基于单目视觉的车辆前方行人检测技术研究[D].长春:吉林大学,2007
[5]HEISELE B,WHLER C.Motion-based recognition of pedestrians[C]//Proceedings of the 14th International Conference on Pattern Recognition.Washington D C:IEEE Computer Society,1998:1325-1330
[6]LOMBARDI P.A survey on pedestrian detection for autonomous driving systems[R]//Technical Report.Pavia:University of Pavia,2001
[7]LIENHART R,MAYDT J.An extended set of Haar-like features for rapid object detection[C]//Proceedings of IEEE International Conference on Image Processing.New York:IEEE,2002:900-903
[8]KRUPPA H,CASTRILLON-SANTANA M,SCHIELE B.Fast and robust face finding via local context[C]//5th IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance.Piscataway:IEEE,2003:157-164
[9]HARALICK R M.Statistical and structural approaches to texture[J].Proceedings of the IEEE,
1979,67(5):786-804
[10]靳宏磊,张振华,李立源,等.基于纹理分析的表面粗糙度等级识别[J].中国图象图形学报,2000,5(7):612-615
[11]BROGGI A,BERTOZZI M,FASCIOLI A,etal.Shape-based pedestrian detection[C]//Proceedings of the IEEE Intelligent Vehicles Symposium 2000.Piscataway:IEEE,2000:215-220
[12]李 斌.智能车辆前方车辆探测及安全车距控制方法的研究[D].长春:吉林大学,2002
[13]CANNY J.A computational approach to edge detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,1986,8(6):679-698
[14]CHEN Chaur-chin.Improved moment invariant for shape discrimination[J].Pattern Recognition,1993,26(5):683-686
[15]FREDRIK A.Vision-based pedestrian detection system for use in smart cars[D].Sweden:School of Mechanical Engineering,Royal Institute of Technology,2005:63-72
[16]VAPNIK V.统计学习理论的本质[M].张学工,译.北京:清华大学出版社,2000
[17]冯元戬,施鹏飞.基于支持向量机的彩色图像人脸检测方法[J].上海交通大学学报,2003,37(6):947-955
