多步桥接精化迁移学习*
2011-01-24覃姜维郑启伦马千里韦佳林古立
覃姜维 郑启伦 马千里 韦佳 林古立
(华南理工大学计算机科学与工程学院,广东广州510006)
传统机器学习方法基于假设训练数据和测试数据分布一致的前提,这大大限制了其应用范围[1].当假设条件不满足的时候,传统分类器的性能可能出现下降.最常见的情况是对一个新领域数据进行分类时,由于几乎没有标记数据,传统机器学习方法无法训练出可靠的分类器.比如说,大量研究发掘的生物信息数据和快速增长的网络信息数据都包含着丰富的待挖掘信息,但是由于这些数据缺乏标记,而人工进行标记也费时费力,要分析这些数据隐含的信息就变得非常困难.此外,在相关领域存在大量的标记数据却无法直接使用[1].因此,有必要探寻相关领域数据与目标领域数据的联系,并利用相关领域中的监督信息来指导目标领域中的任务学习.
近来,受到人类认知学习过程中迁移学习的启发[2],相关学者提出了机器学习中的迁移学习方法[3-5],目的是解决跨领域、跨任务的学习问题.早期关于迁移学习的工作有 learning to learning[3]、lifelong learning[4]、learning one more thing 和多任务学习[5-6].其中和迁移学习最为相似的是多任务学习,但多任务学习研究的是若干个任务共同学习的情况,并没有考虑对与源数据分布不一致的目标数据的学习.一般来说,迁移学习方法可以分为实例迁移、特征迁移、参数迁移和关联知识迁移[7].在这几类迁移方法中,实例迁移和特征迁移被广泛地进行研究.其中,实例迁移强调对样本层面的信息进行重用,而特征迁移着重研究特征层面上的联系.
研究者们从不同的角度来研究迁移机制的实现.由于数据散布在不同的领域,迁移的前提是找寻可供迁移的共同映射,并建立这个映射的桥梁.Mahmud[8]定义了一种任务相似度的衡量机制,并以此为基础来定量地决定任务间迁移的信息量.Ruckert等[9]提出了一种基于核方法的迁移算法,即先在源数据上学习一系列泛化性能良好的核函数,然后以最小化准则将其结合起来用于预测目标数据的标签.Dai等[10]定义出源数据和目标数据的共同特征,并以此为桥梁执行协同聚类算法,使源数据的标签结构影响目标数据的标签结构.Dai等[11]还将该算法扩展到源领域数据标签缺失的情况,提出了一种无监督迁移学习方法.Ling等[12]提出一种基于谱分类的迁移框架,目标是在源数据的监督信息和目标领域的自有结构当中找到一个平衡.文献[13]提出的方法也是基于谱分析的方法,归纳了几种迁移学习的情形,得出了一种迁移框架.这些方法以找寻源和目标领域的共同表示为目标,但忽略了目标领域数据的自身特性.Daume等[14]假设源和目标领域包含相同和不同的组成成分,提出利用混合模型来进行学习.他们将两个来自不同领域的数据看成是3个不同分布数据的混合结果,并共享一个相同的分布数据.Storkey等[15]考虑了一种更为普遍的情况,认为源领域和目标领域共享多个混合成分,从而更为细致地考虑了混合模型的组成.这两种方法在求解一个公共模型的基础上再使用期望最大化(EM)算法来对目标领域的模型进行修正.
大部分研究通过参数化的估计方法来学习模型,当数据量小的时候,存在参数估计困难的问题.为避免对分布参数进行估计,本研究提出了一种非参数化的迁移学习算法——多步桥接精化(Multi-Step Bridged Refinement,简称MSBR)来解决训练数据和测试数据分布不一致的分类问题.首先通过构造一系列中间模型来建立源领域和目标领域之间的连接,进而进行标签传播,最终完成从源领域到目标领域的判别信息的迁移.由于构造的中间模型两两间的数据分布相似,原来被认为较难的迁移过程被分解成为一系列相对容易解决的子迁移.
1 多步桥接精化迁移
1.1 问题定义
1.2 交互精化
本研究借助标签传播的原理来求目标领域数据的标签[16].标签传播受到 PageRank 算法的启发[17].PageRank算法通过网页间的链接关系来对网页的重要性进行评分,一个网页的权值受到链接到该网页的页面的影响.假设u为一个网页,其权值评估公式为

式中:R表示页面的权值;E表示网页的初始权值;Bu为指向u的页面集合;Nu为集合u指向的网页集合的数量;η为平衡因子.公式(1)利用页面间相互连接的关系来表明指向一个页面的邻居页面的权值越高,其页面权值也就越大.公式(1)包含了交互精化的思想,页面的权值被其邻居页面的权值精化,同时又对其邻居页面的权值进行精化.更进一步,可以认为相似的网页间具有相互链接的关系.本研究以此为基础得到一个基于交互精化的标签传播模型.在图1中,假设有标记数据 x1、x2、x3属于类别a,标记数据 x4、x5、x6属于类别 b.其中,x1、x3、x5是u1的邻居,而x2、x4、x6是 u2的邻居.如果每个邻居对未标记数据的标签贡献程度一致,那么可以认为u1属于a的概率大于属于b的概率,而u2属于b的概率大于属于a的概率.
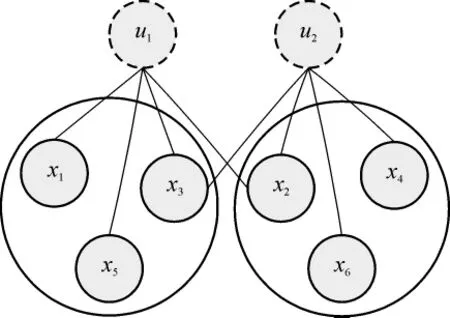
图1 标签传播Fig.1 Label propagation
因此,一个样本的邻居所属类别的情况反映出该样本所属类别的情形.也就是说,当一个样本的邻居属于某个类别的概率越大,则这个样本属于该类别的概率也就越大.然而,该模型的讨论是在数据分布一致的前提下进行的,在本研究的问题中,源数据和目标数据的分布并不相同,为此,本研究将模型应用到迁移问题的场景中.
1.3 多步桥接精化
为了让目标数据获得源数据的标签信息,本研究借助中间模型在两个领域数据间执行交互精化算法来进行标签传播.一般来说,很难直接在不同分布的数据间执行交互精化算法,但是当分布非常相似的时候,可以认为标签传播条件近似成立,从而达到标签结构迁移的目的.通过引进一个中间模型M,将整个迁移过程分成两步,首先是从源数据到中间模型的迁移,其次是从中间模型到目标数据的迁移.由于中间模型M由源数据和目标数据构成,其分布DM与DS和DT的距离相对接近,因而在DS和DM或者在DM和DT之间进行迁移相对于在DS和DT之间迁移要容易.虽然源数据和目标数据来源于不同分布的领域,但由于领域间相关,它们存在一定的联系.假设P(c|d)表示数据的所属类别的条件概率,给定样本d,有
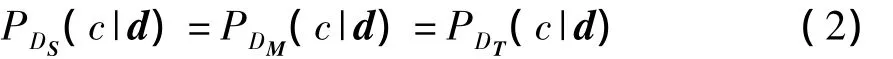
这是由源数据和目标数据共享相同的标签空间决定的.因此能够在M中利用这个关系让源数据对目标数据的标签进行精化.借助中间模型,能够在迁移的过程中分步实施交互精化算法,从而达到标签传播的目的.
通过引入中间模型M,使得在不同领域间的数据间的标签传播成为可能.但是,当数据分布具有显著差异的时候,仅仅依靠单个中间模型是不够的.为此,需要提供更为可靠的迁移环境.对中间模型进行变换,构造一系列的桥接模型,这些模型中两两的分布更为接近.由于相似的数据分布让迁移成为可能,那么本研究中构造的近似分布中间模型可以使得迁移更加平滑和可靠.具体来说,本研究是在构造的中间模型中两两相互执行交互精化算法,进而实现从源数据到目标数据的标签传播.
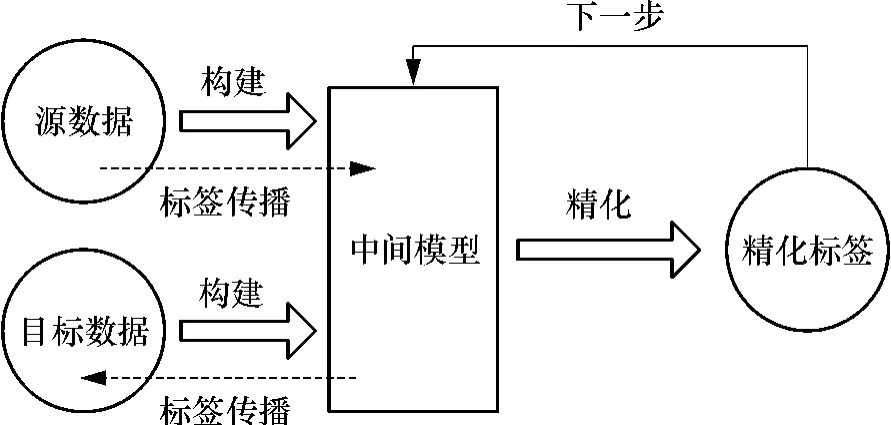
图2 多步桥接精化模型Fig.2 Multi-step bridged refinement model
具体的中间模型的构造过程见图2,中间模型都由标记数据和未标记数据构成,他们的比例由λ进行控制.定义模型中的数据组成为

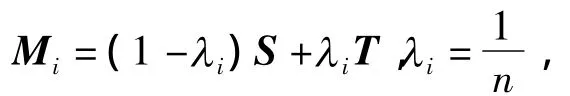
近邻的模型在分布上相似,可以执行交互精化来进行标签传播,其过程如下.令 f为精化结果,f0是初始值,fi,j为样本 di属于类别 j的概率,O(i)为di的邻居集合,K为邻居个数,则模型间执行交互精化的过程为
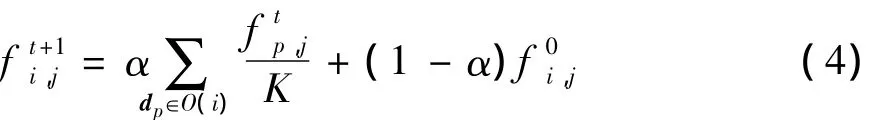
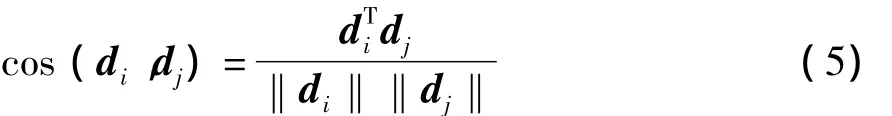
在交互精化的过程中,fi作为下一步精化过程的初始输入f0.在完成n次精化过程后,根据对样本的标签进行赋值.
MSBR算法伪码描述如下:

1.4 算法的收敛性
根据文献[14],式(4)可以重写为式(6)或(7),其中L是根据样本邻居构造的邻接矩阵.
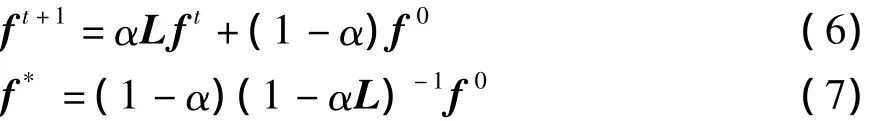
每步精化过程的结果都会收敛到一个稳定值f*.在多步精化的过程中,可以将全部的精化过程定义为:
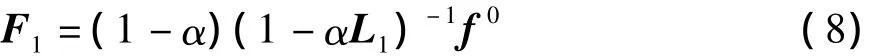
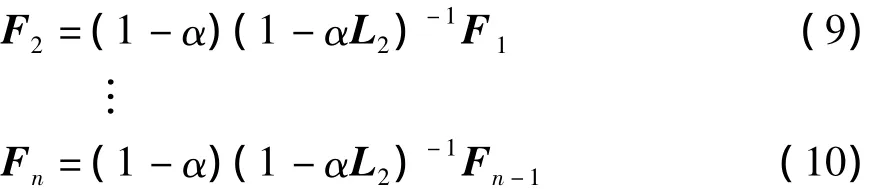
式中:Fi表示第i次精化的结果.将式(8)-(10)的左右相乘,得到式(11),算法最终收敛于Fn.
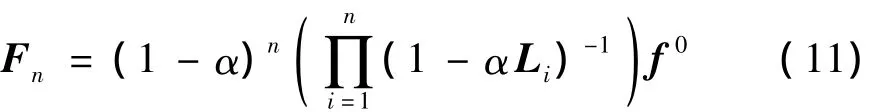
2 实验
2.1 数据集
本研究采用两个标准文本数据20Newsgroup(http:∥people.csail.mit.edu/jrennie/20Newsgroups)和 SRAA(http:∥www.cs.umass.edu/~ mccallum/code-data.html)作为实验数据集.为了使数据集满足迁移场景,本研究对数据集进行了重构.由于以上选择的数据集都包含分属不同顶层类别的子主题,可以将相同顶层类别的子主题划分出来与不同顶层类别的子主题构成不同的领域数据.基于这种重构,本研究认为由于源领域数据和目标领域数据来源于不同的子主题,所以存在差异,但因为其中的子主题共享顶层主题,因此两个领域数据间又存在联系.本研究分别对20Newsgroup和SRAA做如下重构:
(1)20Newsgroup是一个包含近20000个新闻组的文档集,大约分成20类,包含6个顶层类别.将其中的空白类别删除掉,利用剩余的数据生成数据集(见表1).
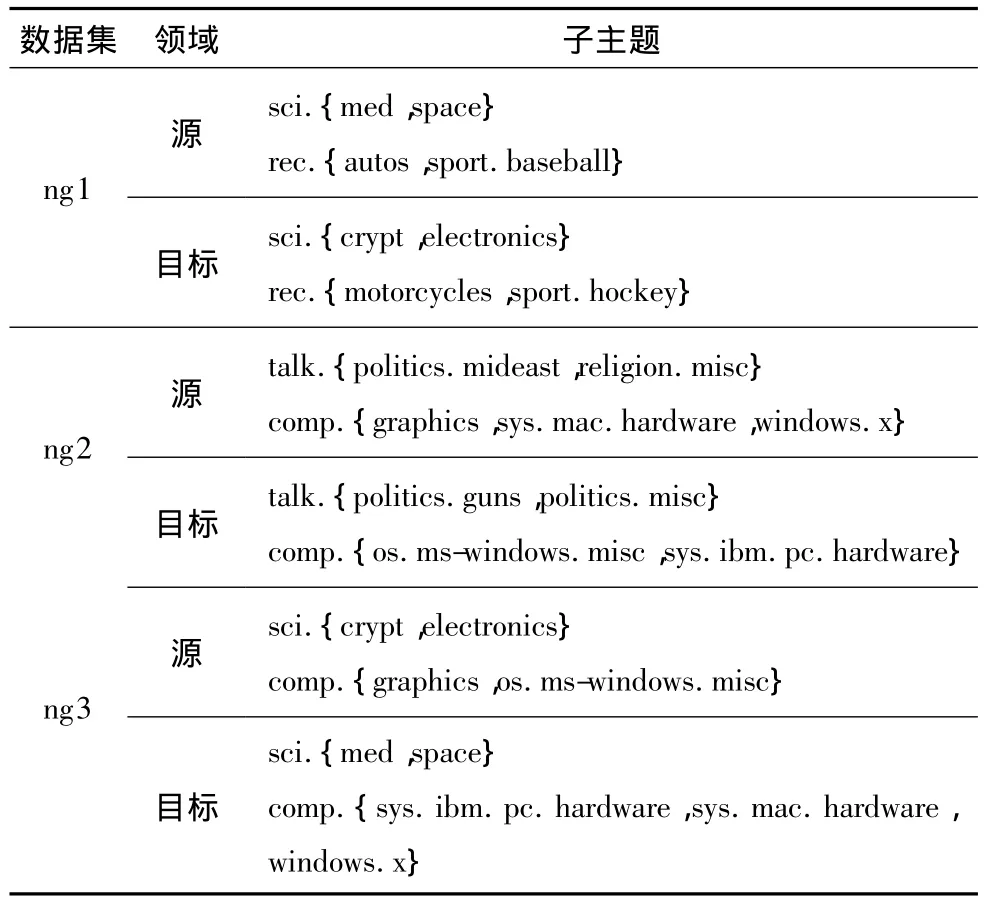
表1 基于20Newsgroup构建的数据集Table 1 Data sets constructed from 20Newsgroup
(2)SRAA是一个包含73218篇文档的文本数据集,可以分成 simuauto、simuavation、realauto和realavation 4个类别.根据文档内容的描述,本研究选择任意的两个主题作为源领域数据而剩余的主题作为目标领域数据,生成的数据集见表2.

表2 基于SRAA构建的数据集Table 2 Data sets constructed from SRAA
本研究利用向量空间模型(VSM)对文本数据进行处理[18].整个过程包括大小写转换、提取词干、去除停用词、特征选择和计算 TF/IDf值[19].此外,将词频设为5.
2.2 实验方法
本研究利用传统分类器求得目标数据的初始标签,然后利用文中提出的算法对目标数据的初始标签进行精化.本研究选择了3种经典的监督分类器和半监督分类器,即支持向量机(SVM)[20],朴素贝叶斯(NB)和转导式支持向量机(TSVM)[21-22].为了知道迁移是否起作用,本研究同时也将文中提出的算法的结果与传统分类器做对比.
实验策略为:
(1)在源数据上利用传统分类器训练分类模型,并将其直接用于目标数据的分类;
(2)在传统分类器对目标数据的分类结果上,利用BRTL对传统分类器的结果进行精化[23];
(3)在传统分类器对目标数据的分类结果上,利用文中提出的算法对传统分类器的结果进行精化,为了与BRTL做对比,本研究将参数α设置为0.7;
(4)直接利用BRTL和文中提出的MSBR对目标数据进行精化.
2.3 实验结果和讨论
表3-5给出了4种不同策略上的计算结果,从表中可以看到,传统分类器在跨领域的数据分类中性能较差,而两种迁移学习方法在学习精度上要优于传统分类器.对比传统分类器(SVM、NB、TSVM)和迁移分类器(BRTL、MSBR)在所有问题上的平均分类精度,BRTL相对传统分类器提高了22%,而文中提出的MSBR相对传统分类器提高了48%.可以看到迁移算法对跨领域环境下的数据分类精度与传统分数器相比有很明显的提升.
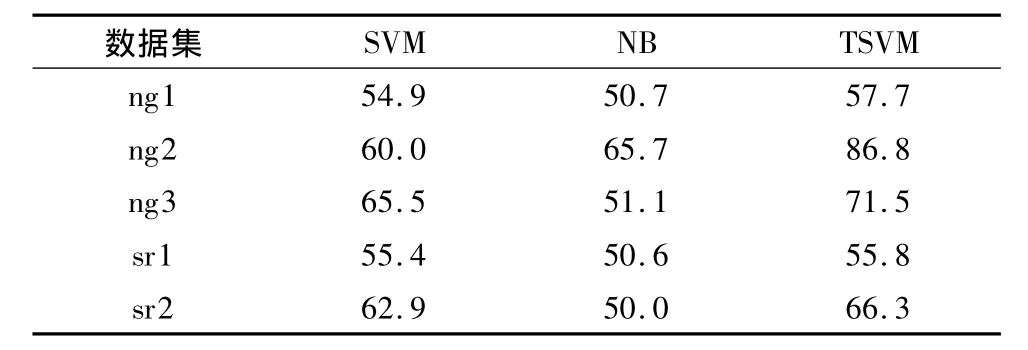
表3 传统分类器SVM、NB、TSVM在数据集上的分类精度Table 3 Classification accuracy of the traditional classifiers SVM,NB,TSVM on the data sets %
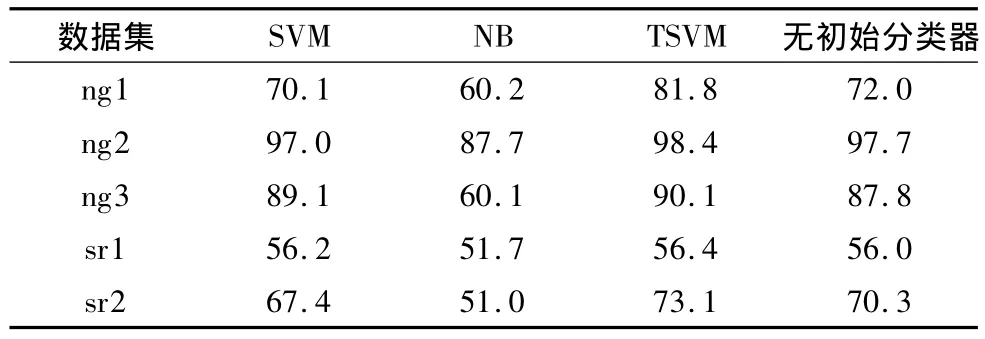
表4 BRTL在数据集上的分类精度Table 4 Classification accuracy of BRTL on the data sets %
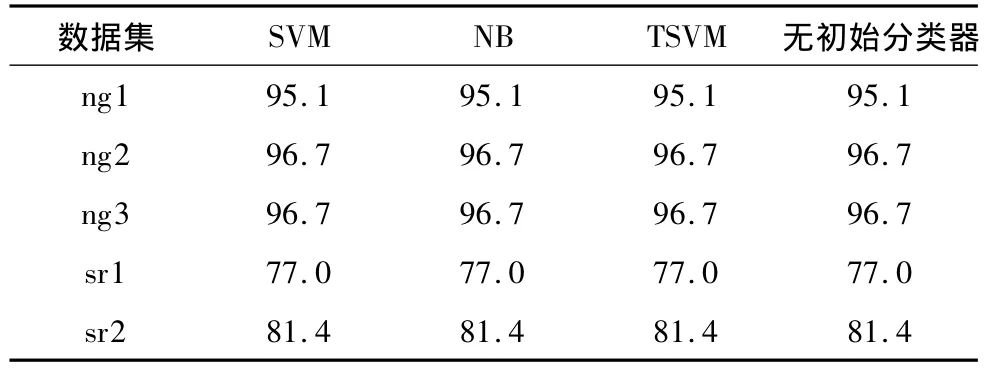
表5 MSBR在数据集上的分类精度Table 5 Classification accuracy of MSBR on the data sets %
从表4可以看出,BRTL敏感于初始分类器的选择,因此对同样的数据集在不同的初始条件下得到的结果是不一样的.比如说,TSVM在ng1上的结果要优于SVM和NB,因此BRTL在基于TSVM初始结果上的精化结果要优于基于SVM和NB的精化结果.由于对初始分类器的选择较敏感,使得BRTL的结果变得不可靠.而表5中,MSBR对于每个问题的最终精化结果是一致的.
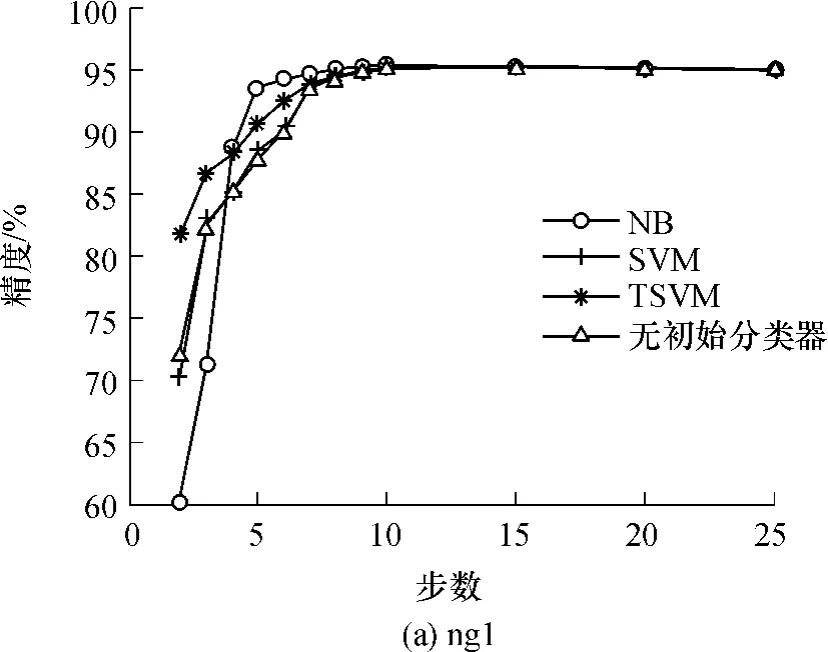
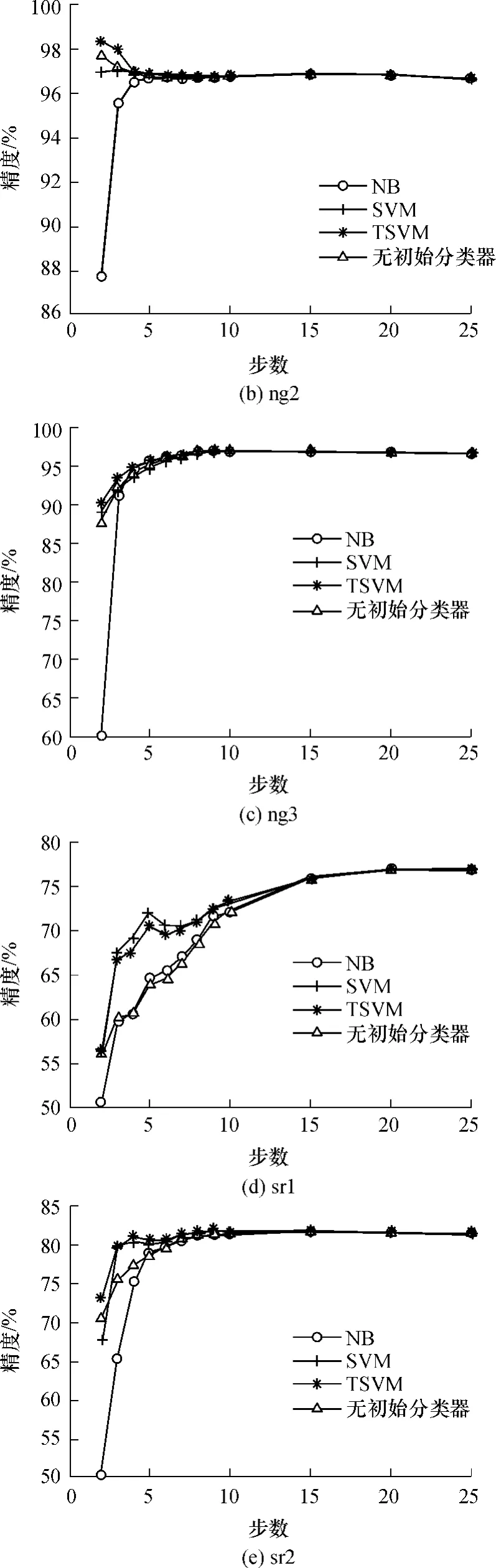
图3 精化步数对结果的影响Fig.3 Effect of different refinement steps on the results
为了探讨中间模型的变化对目标数据分类精度的影响,本研究分别绘出多步情况下MSBR算法在各数据集上的精度变化曲线,如图3所示.由图3可见,对于每个问题来说,MSBR算法最后得到的精度一致.换句话说,初始分类器的选择没有影响MSBR算法的最后结果.这有别于文献[21]认为迁移效果受限于初始分类器的选择的结论.本研究认为在精化步数足够的条件下,算法在每个问题上的结果应该是一致的,这是由于从源数据迁移到目标数据的监督信息是一定的.然而两步精化不足以优化目标数据的标签结构,在多个中间模型的桥接下,源数据的标签信息才能完全地被用来影响目标领域的标签结构.
由图3还可知,借助相关领域数据的监督信息可以改善目标领域在没有标记数据情况下的分类精度,但是并不是在所有情况下都是如此.如图3(b)所示,随着精化步数n的增大,精度略微出现了下降.本研究认为这是由于ng2中的源数据和目标数据分布非常相似,因此传统的分类器表现出较好的性能,而利用MSBR算法在桥接精化的过程中出现了标签信息的损失,从而造成精度下降.
由图3还可知,当n大于15时,算法精度趋于稳定,而后n的继续增大并不能改变算法的效果.由此可见,15步精化对MSBR来说已经足够.
由图4可见,对于MSBR来说,当α的取值范围在0.6到0.8之间时,算法精度J有较好的效果,本研究的实验中将α设置为0.7.
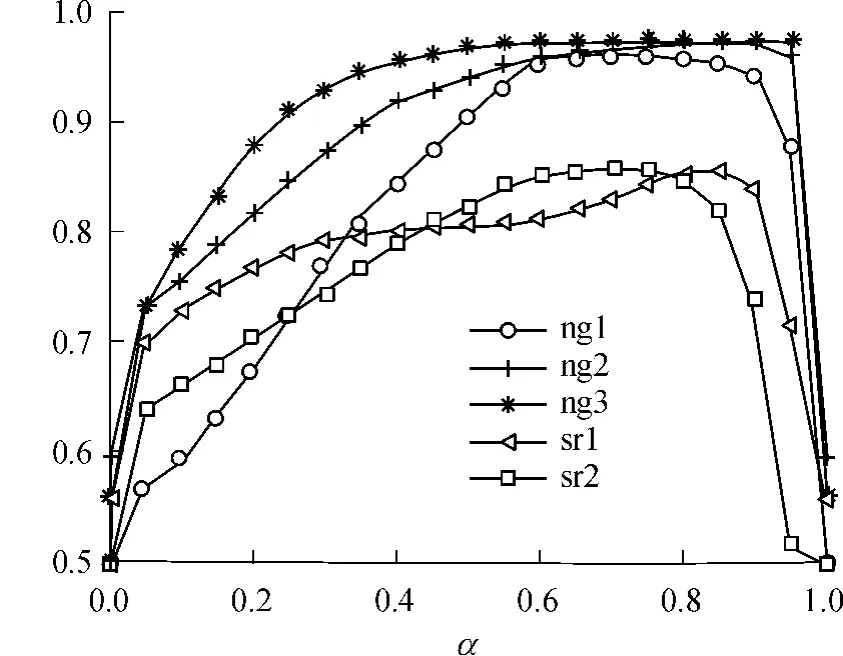
图4 α对MSBR结果的影响Fig.4 Effect of α on the results of MSBR
4 结语
本研究探讨了跨领域数据分类的问题,以桥接精化为基础,提出了一种迁移环境下的学习算法MSBR.即通过构造一系列中间模型建立起源数据与目标数据之间的连接,在此基础上对邻近的模型间执行交互精化,最终实现从源数据到目标数据的标签传播.该算法的优点是能够充分利用源数据的标签信息来影响目标数据的标签结构,并且不敏感于初始分类器的选择.实验表明,该算法在效果上优于对比的几个传统分类器和BRTL,是有效可行的.
进一步研究将探讨任务间的相似度如何影响迁移效果,同时也会考虑将MSBR应用到如从文本到图片或者视频的跨媒体场景中.
[1] Dietterich T G,Domingos P,Getoor L,et al.Structured machine learning:the next ten years[J].Machine Learning,2008,73(1):3-23.
[2] Brown A L,Kane M J.Preschool children can learn to transfer:learning to learn and learning from example[J].Cognitive Psychology,1998,20(4):493-523.
[3] Thrun S,Pratt L Y.Learning to learn[M].Boston:Kluwer Academic Publishers,1998:1-13.
[4] Thrun S.Is learning the n-th thing any easier than learning the first?[C]∥Proceedings of the 12th Neural Information Processing Systems.Cambridge:MIT Press,1995:640-646.
[5] Thrun S,Mitchell T M.Learning one more thing[C]∥Proceedings of the 14th International Joint Conference on Artificial Intelligence.Quebec:IJCAI,1995:1217-1225.
[6] Caruana R.Multitask learning [J].Machine Learning,1997,28(1):41-75.
[7] Pan S,Yang Q.A survey on transfer learning[J].IEEE Transactions on Knowledge and Data Engineering,2009,22(10):1345-1359.
[8] Mahmud M M H.On universal transfer learning[J].Theoretical Computer Science,2009,410(19):1826-1846.
[9] Ruckert U,Kramer S.Kernel-based inductive transfer[C]∥Machine Learning and Knowledge Discovery in Databases.Belgium:Springer,2008:220-233.
[10] Dai W,Xue G R,Yang Q,et al.Co-clustering based classification for out-of-domain documents[C]∥Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2007:210-219.
[11] Dai W,Yang Q,Xue G R,et al.Self-taught clustering[C]∥Proceedings of the Twenty-Fifth International Conference of Machine Learning.Helsinki:ACM,2008:200-207.
[12] Ling X,Dai W,Xue G R,et al.Spectral domain transfer learning[C]∥Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.Nevada:ACM,2008:488-496.
[13] Dai W,Jin O,Xue G R,et al.EigenTransfer:a unified framework for transfer learning[C]∥Proceedings of the 26th International Conference on Machine Learning.Montreal:ACM,2009:193-200.
[14] Daume III H,Marcu D.Domain adaptation for statistical classiers[J].Journal of Artificial Intelligence Research,2006,26(1):101-126.
[15] Storkey A J,Sugiyama M.Mixture regression for covariate shift[C]∥Proceedings of the 21st Neural Information Processing Systems.Cambridge:MIT Press,2007:1337-1344.
[16] Wang F,Zhang C S.Label propagation through linear neighborhoods[J].IEEE Transactions on Knowledge and Data Engineering,2008,20(1):55-67.
[17] Page L,Brin S,Motwani R,et al.The PageRank citation ranking:bringing order to the web[R].Stanford:Stanford Digital Library,1998.
[18] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3(1):993-1022.
[19] Sebastiani F.Machine learning in automated text categorization[J].ACM Computing Survey,2002,34(1):1-47.
[20] Joachims T.Making large-scale SVM learning practical[C]∥Advances in Kernel Methods:Support Vector Learning.Cambridge:MIT Press,1999:169-184.
[21] Rish I.An empirical study of the Naive Bayes classifier[C]∥Proceedings of IJCAI-01 Workshop on Empirical Methods in Artificial Intelligence.Washington:IJCAI,2001:41-46.
[22] Joachims T.Transductive inference for text classification using support vector machines[C]∥Proceedings of the 16th International Conference on Machine Learning.Slovenia:ACM,1999:200-209.
[23] Xing D,Dai W,Xue G R,et al.Bridged refinement for transfer learning[C]∥Proceedings of 11th European Conference on Practice of Knowledge Discovery in Databases.Warsaw:Springer,2007:324-335.
