基于ASR的呼叫中心系统设计与可靠性研究
2010-12-12广州市行政学院信息网络中心郭瑞GUORui
广州市行政学院信息网络中心 郭瑞GUO Rui
基于ASR的呼叫中心系统设计与可靠性研究
广州市行政学院信息网络中心 郭瑞GUO Rui
本文以I T运行维护的故障申报系统为例,介绍如何利用Nu a n c e Re c o g n i z e r 9.0自动语音识别系统和东进D 0 8 1 A模拟中继语音卡电话处理系统设计基于A S R(自动语音识别)的呼叫中心。文中不仅介绍了设计过程中的各个关键环节,而且对该系统的可靠性进行了深入讨论。其中包括如何合理设计语法文件以提高语音识别率;如何在系统运行期间进行同步保障,使系统逐步趋于完善。
自动语音识别(A S R);呼叫中心;语法文件;同步保障
1.景
由于信息技术的蓬勃发展,大到政府的服务机构,小到私营企业的服务部门,大都采用电话方式进行客户服务。随着服务任务量逐渐加大,呼叫中心孕育而生。呼叫中心的主要功能是接听客户来电并给予相应服务。早期的呼叫中心采用人工接听方式,这样需要消耗大量的人力。现在虽然有了让用户通过电话按键进行交互的自动呼叫中心,但在一次服务中用户往往需要反复选择按键多次,十分不便。采用自动语音识别方式将用户来电话音直接转换成计算机能自动处理的文本信息,可以令呼叫中心的服务更加自动化、人性化。
2.音识别原理
语音识别技术就是让计算机通过识别和理解过程把人类语音信号转变为相应的文本或命令的技术,其目的是让计算机"听懂"人类口述的语言。不同的语音识别系统,虽然具体实现细节有所不同,但所采用的识别原理程序基本相似:[1](见图1)
首先,确定语音识别单元的选取,语音识别单元有单词(句)、音节和音素等3种。单词(句)单元广泛应用于中小词汇语音识别系统,但不适合大词汇系统。因为汉语是单音节结构的语言,音节数量相对较少,所以音节单元多用于大词汇量汉语语音识别。音素单元以前多见于英语语音识别的研究中,现在也开始用于大词汇量汉语语音识别。之后,进行特征提取,去除语音中对识别无关紧要的冗余信息,然后,采用适当的语音识别方法,通过对确定的语音特征进行模拟训练得到模板库。最后,将待识别的语音信号特征与模板库进行模式匹配,从而达到识别目的。

3.统设计
自动语音识别(Automatic Speech Recognition,简称ASR)系统是一种可以识别非限定讲话者连续话音的识别软件系统。其功能是将人类的语音中的词汇内容转换为计算机可读的符号输入。呼叫中心是基于现代通讯技术,同时处理大量各种不同的电话呼入和呼出业务与服务的系统。
本文基于自动语音识别的IT运维呼叫中心系统(以下简称本系统),将实现从电话故障申报语音采集、语音转换成文本、文本信息提交IT运维管理工作流的一系列功能。本系统采用东进公司出品的D081A模拟中继语音卡电话处理系统,实现呼叫中心的基本功能;利用Nuance Recognizer 9.0自动语音识别系统对采样的话音进行处理,将话音转换成对应的文本,并以统一的XML格式文件作为输出,将故障申报信息提交给IT运维管理软件。(见图2)
由于东进公司和Nuance公司的SDK都是基于C语言的标准API函数接口,本系统使用VC++将电话呼叫中心与自动语音识别系统进行整合。
3.1.话呼叫中心
电话申报作为本系统的输入模块,直接将电话线上的话音信号采样保存为数字音频数据。东进公司的D081A模拟中继语音卡可以提供最多8个通道的模拟话音接入。申报过程设计成简单的一问一答形式。由于本系统采用自动语音识别功能,整个申报过程无需繁琐 的 按键选择。
电话接通后,系统将自动播放提示音,用户根据提示音作出相应回答即可。在此期间,系统记录用户话音,并交由自动语音识别软件处理。申报完成后,系统自动输出确认信息,告知用户故障的受理情况。本文中所涉及的呼叫中心关注故障申报人的姓名、故障发生地和故障描述这3个关键信息。申报流程设计如下:(见图3)
3.2.音识别机制
自动语音识别技术即 Automatic Speech Recognition(简称ASR),是指将人说话的语音信号自动转换为可被计算机程序所识别的符号信息,从而识别说话人的语音指令及文字内容的技术。
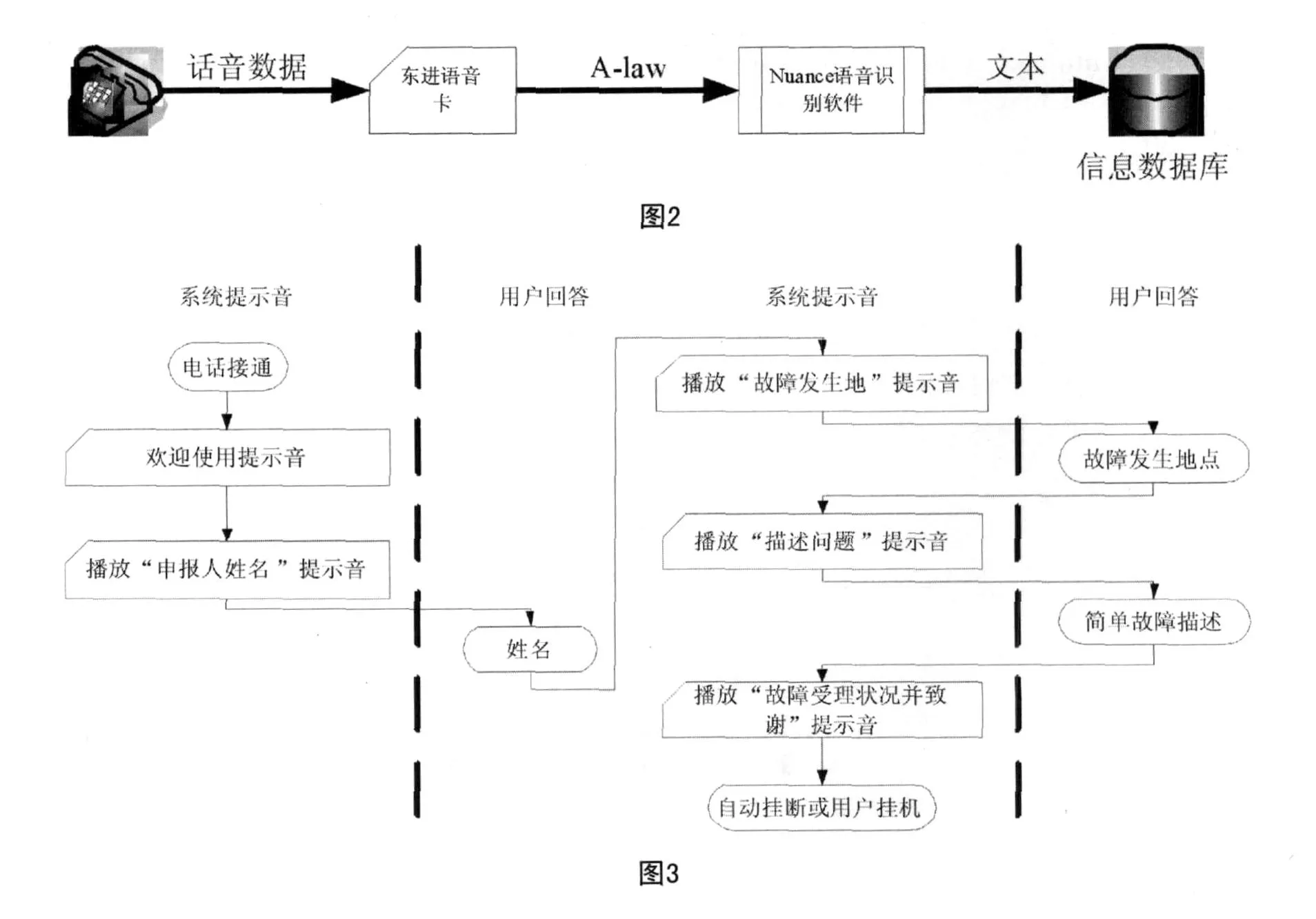
本系统使用Nuance Recognizer 9.0语音识别软件(以下简称该软件)实现ASR功能。该软件是一款非特定人语音、大词汇量、连续语音识别软件。该软件进行语音识别的核心是标准声音库文件和用户语法文件,本系统使用中文普通话语音库。识别过程中,该软件首先从系统导入用户语法文件,通过语法文件中按照一定逻辑结构组织的文本信息在标准声音库文件中选择相应的声音数据作为模式匹配的样本。这样做的好处是,无需在整个声音库文件中进行模式匹配,大大加快了识别的速度。(见图4)
语法文件作为所需识别内容的总体范围,所识别的字、词在语法文件中按照一定的语言逻辑关系进行组织。这样做的优点是,在识别之前无需对说话人的语音进行采样学习。语法文件采用Nuance公司定义的grxml格式,它是基于xml标准的一种语法扩展。由于自动语音识别结果的文本内容直接来自语法文件,所以语法文件的内容直接关系到识别的成功率。开发者必须根据实际应用需要编写ASR的语法文件,并不断充实完善它。
以下是本系统中识别房间号码的语法文件:
〈?xml version='1.0'encoding='GB'?>
〈grammar xml:lang="zh-cn"version="1.0"xmlns="http://www.w3.org/2001/06/grammar"root="RoomNum">
〈meta name="swirec_max_speech_duration"content="14000"/>
〈meta name="incompletetimeout" content="1500"/>
〈rule id="RoomNum"scope="public">
〈tag>name=''〈/tag>
〈Item>办公楼〈tag>name="办公楼"〈/tag>〈/
item>
〈Item>〈ruleref uri="#S"/>〈tag>name+=S.V
〈/tag>〈/item> 〈item>〈tag>SWI_meaning
=name;RESULT=SWI_meaning〈/tag>〈/item>
〈/rule>
〈rule id="S">
〈ruleref uri="#DIGIT"tag="V=DIGIT.V"/>
〈ruleref uri="#DIGIT"tag="V+=DIGIT.V"/>
〈ruleref uri="#DIGIT"tag="V+=DIGIT.V"/>
〈/rule>
〈rule id="DIGIT">
〈one-of>
〈item tag="V='0'">零〈/item>
〈item tag="V='1'">
〈one-of>
〈Item>一〈/item>

〈item>幺〈/item>
〈/one-of>
〈/item>
〈item tag="V='2'">二〈/item>
〈item tag="V='3'">三〈/item>
〈item tag="V='4'">四〈/item>
〈item tag="V='5'">五〈/item>
〈item tag="V='6'">六〈/item>
〈item tag="V='7'">七〈/item>
〈item tag="V='8'">八〈/item>
〈item tag="V='9'">九〈/item>
〈/one-of>
〈/rule>
〈/grammar>
3.3.音识别实现
本系统利用该软件的SDK实现自动语音识别功能。SDK由多个模块组成,每个模块提供一组API函数实现特定功能。本系统使用其中话音检测器(Speech detector)和语音识别器(Recognizer)两个模块。话音检测器用于对输入的数字音频数据进行预处理,经过预处理的数据输入到语音识别器中进行识别分析。(图5)
要实现语音识别功能,API接口函数必须被正确按顺序调用。(见图6)
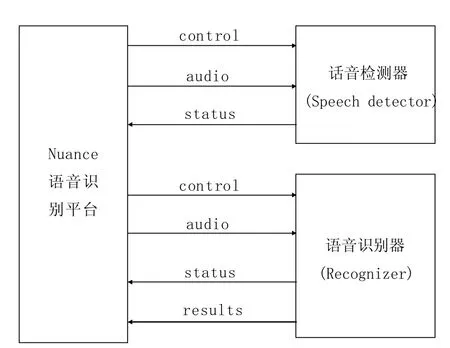
图5.
系统启动时,必须用 SWIepInit()和SWIrec-Init()函数初始化话音检测器和语音识别器。否则其它API函数无法工作。之后用SWIepDetectorCreate()和SWIrecRecognizerCreate()函数分别创建话音检测器和语音识别器对象。
启动完成后,首先用SWIrecGrammarLoad()函数加载用户定义的语法文件,并用SWIrecGrammar-Activate()函数将其激活。每次识别前,必须使用SWIrecSessionStart()和SWIrecAcousticState-Reset()函数对声学处理模块进行复位。
本系统的语音识别采用多线程设计,每次语音识别都作为一个独立线程。在单个线程中,语音识别器将启用话音检测器载入数字音频数据并进行预处理。预处理开始前,必须使用SWIepSessionSta-Rt()函数开启话音检测会话,并使用SWIepAcous-TicStateReset()函数复位声学处理模块的相关组件。预处理过程中,SWIepStart()和SWIepStop()函数控制话音检测器工作和停止;利用SWIepWrite()函数向话音检测器中写入需要预处理的数字音频数据;处理完毕后,利用SWIepRead()函数从话音检测器中读取处理结果数据。语音识别器使用SWIrecRecognizerCompute()函数根据所载入的语法文件对经过预处理的话音数据进行识别。
识别结束后,利用SWIrecGetXMLResult()函数将识别结果保存为XML格式的标准文件作为语音识别的输出。同时利用SWIrecGetWaveform()和SWIrecLogEvent()函数记录预处理后的波形数据和系统运行状态信息。
关闭系统时,必须使用SWIrecGrammarFree()函数释放语法文件资源,并用SWIepDetectorDest-Roy()和SWIrecRecognizerDeStroy()函数销毁所有话音检测器和语音识别器对象。之后利用SWIepTerminate()和SWIrecTerminAte()函数终止话音检测器和语音识别器组建,释放所有资源。值得注意的是,在终止之前,必须将所有话音检测器和语音识别器对象销毁,否则终止操作将会失败。
3.4.音识别结果
语音识别结果以XML文件格式输出。对于同一段话音,难免出现发音相近的识别结果,这时,系统将根据匹配度从高到低的顺序对识别结果进行排序。下面是一段识别结果的XML文件示例,可见“电脑坏了”的匹配度为“90”,而“编码坏了”的匹配度为“8”,于是“电脑坏了”将作为结果输出。
〈result>
〈interpretation grammar="DigitsGrammar"confidence="90">
〈input mode="speech">〈nomatch>电 脑 坏 了〈/nomatch>〈/input>〈instance/>
〈/Interpretation>
〈interpretation grammar="Digits_Grammar"
Confidence="8">
〈input mode="speech">〈nomatch>编 码 坏 了〈/nomatch>〈/input>〈instance/>
〈/interpretation>
〈/result>
4.统可靠性
可靠性是系统质量的重要指标,语音识别率是本系统可靠性的关键环节。完善系统可靠性是一个长期的过程,贯穿于软件的整个生命周期。
4.1.步保障
为了保障系统正常运行,不断提高其可靠性,本系统采用了同步保障机制。每次故障申报电话的音频数据将自动保存到系统数据库中,一旦发现识别率下降,立即调出相应的话音数据进行比对,从中分析出识别率下降的原因并作出改进。采用这一机制后,数据库中的音频数据量势必随着运行时间的增长而逐渐加大。考虑到人说话的声音频率在100Hz~8KHz范围,采用A-law标准将话音数据压缩成8KHz、8bit、单声道的数字音频文件。这样既能保证话音的保真度,又能有效节约存储空间。通过同步保障的机制,语音识别率将保持在一个较高水平,系统可靠性得以保证。
4.2.实语法文件
合理设计语法文件,是提高系统可靠性的重要环节。人的话音千差万别,这就对语音识别产生极大挑战。比如某些人说话带有方言口音,极易造成识别错误。为了保证语音识别率,系统设计的语法文件需要尽量多 地 考虑到人们日常口语习惯。
首先是“一字多音”。比如“一”有可能念成“幺”,那么当接收到“幺”的话音应该同样识别为“一”。于是就有了如下语法文件,将两个读音统一识别为一个字。
〈item tag="V='1'">
〈one-of>
〈item>一〈/item>
〈item>幺〈/item>
〈/one-of>
〈/item>
其次是“一音多字”。这种情况更为普遍,特别是在人名中。比如“刘杰”、“刘洁”和“刘捷”等。在这种情况下,为了保证系统可靠运行,采用将多个人名同时作为识别结果输出的方式解决。如何区分具体人员,通过上层系统数据库中的信息进行二次确认。在语法文件中采用如下形式实现“一音多字”:
〈item>刘 杰 〈tag>V="刘 杰 ,刘 洁 ,刘 捷"〈/tag>〈/item>
除此之外,还有生僻字的问题。这种情况也主要出现在人名中。例如“燊”字,“彧”字等。如果生僻字出现在语法文件中,会造成语法文件编译错误而导致系统无法正常识别。解决办法是利用含有生僻字、繁体字的字库,在语法文件中使用GBK标准。
〈?Xml version='1.0'encoding='GBK'?>
5.结及展望
本文以IT运行维护系统为例,描述了利用东进D081A模拟中继语音卡电话处理系统和Nuance Recognizer 9.0自动语音识别系统实现基于ASR的呼叫中心的设计过程。本系统不仅适用于维护人员较少但维护任务较重的IT运维管理环境,而且可以根据需要移植到其它应用环境中。移植过程只需要根据具体应用情况重写语法文件,适当修改呼叫中心服务流程即可实现。
虽然本系统已经上线运行一段时间,但语音识别结果难免出现偏差。为了保证系统可靠运行,需要采用同步保障方式。系统同步保存客户话音作为参考数据,一旦出现识别问题,立即针对实际情况修改、充实语法文件,逐步提高系统的可靠性、健壮性,使系统趋于完善。
[1]《汉语大词汇量连续语音识别系统研究进展》倪崇嘉,刘文举,徐波 《中文信息学报》2 0 0 9年1月第2 3卷第1期
[2]《语音识别技术研究进展》柳春《甘肃科技》2 0 0 8年5月第2 4卷第9期
[3]《语音识别技术在数字图书馆检索系统中的应用》叶小榕,邵晴《科技导报》2 0 0 8,2 6(1 8)
[4]《基于Nu a n c e平台的语音识别环境设计》谭保华,熊健民,刘幺和 《湖北工业大学学报》2 0 0 4.6
Design and Reliability Analysis of ASR Call Center System
this article is the description ofASR(Automatic Speech Recognition)call center system design and reliability.as an example,this project uses nuance recognizer 9.0 andDONGJIN D081A analog speech cardto implement the system.the article not only describes eachmodule of the system,but also analyses the system reliability,include how to design grammar file to advance the speech recognition accuracy rate,and how to optimize the system reliabilityby synchronization maintenance.Keyword:ASR(Automatic speech recognition),call center,grammar file,synchronization maintenance,reliability
