基于规则的网络教育资源分类技术研究
2010-12-07谭金波
□ 谭金波
基于规则的网络教育资源分类技术研究
□ 谭金波
本文结合网络教育资源的特征,提出了一个面向网络教育资源的基于规则的Web分类方法。该方法首先构造了规则集,并建立支持规则的主题词库,然后对含有学科概念词的网页锚文本进行分类。实验表明该分类器性能良好,产生的规则易于被人理解,而且容易更新和调整。
规则分类;文本分类;网络教育资源
教育资源库建设是教育信息化的基础,面对网上的海量信息,人工选择下载并加以分类整理的做法不但耗费大量的人力、物力,而且还存在分类结果和实际结果一致性不高的问题。文本自动分类技术为解决这个问题提供了一个新的思路。国内外在文本自动分类方面的研究主要是基于统计方法并取得了可喜成果,其主要算法有支持向量机(SVM)、Rocchio算法、K近邻法(KNN)等[1]。这些分类方法需要根据训练语料得到各类别的模板,进而根据模板进行分类[2]。其优点是训练简单方便,一般情况下分类精度高。其缺点主要有两点:一是对训练语料的数量与质量具有较严要求,如果语料不全面,代表性不强,则会直接影响自动分类的精度;二是当类别之间交叉现象比较严重时,分类器的精度会降低很多,尤其是在层次分类中,有些子类之间的特征交叉更为严重,比如小学语文、初中语文、高中语文这些子类之间的特征交叉比较严重,研究表明,采用统计分类的精度较低[3]。调研发现,网络教育资源的很多锚文本中含有学科概念词,从这些概念词可以直接判断它所链接网页的类别。鉴于此,本文主要研究如下两个问题:可不可以利用规则的方法直接对锚文本进行分类,从而判断链接网页的类别?如果可行,分类效果如何?在下文中,首先根据学科资源的特点,人工构造规则,并建立支持规则的主题词库;然后对锚文本含有的信息进行分类实验,并与基于统计的分类方法进行比较。
一、学科资源的概念层次
1.概念层次表示
在数据挖掘中,概念层次由于能够以层次的形式和偏序的关系组织数据和概念,以易于理解的高层概念表示数据库中数据的关系,因而在数据处理中往往起着举足轻重的作用[4]。本系统是对网络教育学科资源进行分类的,其背景知识可定义成图1所示的概念层次。本文将教育学科资源归纳为三种属性,即学科属性、学段属性和资源类型属性,如“《数列》教案.html”网页属于高中数学(学科) 教案(类型)。为方便起见,采用了集合的表示方法,偏序关系为⊂。

图1 学科资源的概念层次
图1中的概念层次由并列关系和包含关系构成,学科、学段、类型等资源属性之间属于并列关系,这些资源属性内部是包含关系,如高中数学的子概念构成高中数学的概念集合,小学数学、初中数学、高中数学中的共同概念构成数学的概念集合,从而便于网页根据锚文本进行分类。
2.主题词加权方法
本文构建的学科主题词库主要来源于各学科的章节目录名称(对于文科指课文名称),因为目录名称含有各学科的主要特征词,能够表征学科的知识点,这些特征词常在基础教育网页的锚文本中出现。另外,锚文本中也会经常含有表征学段特征和资源类型特征的词条(如初二物理试题),所以,主题词库也包含这些关键词,从而增强分类的正确性。
考虑到主题词的长度、所属类别的数量等对分类的贡献度不同,因而需要给不同类型的主题词赋予相应的权重。对主题词加权的操作过程是:首先,从网上查找并下载学科目录;然后,学科专家对目录进行分词,切分出有用词条,根据词条的重要程度进行加权。
针对主题词与类号可能出现的不同情况,根据下列原则指定词与类号之间联系的权值赋予规则:
(1)一个词就可以准确定类者,赋予最高的权值,如类别名称词;
(2)一个词只与一个类号有联系或者没有其它词出现也能准确定类者,分配次高的权值,如学科目录;
(3)当其它词出现,可能改变或确认该词所定类别时,给予该词中等的权值,如从学科目录分词后得到的主题词;
(4)给予跨类词较低的权值,而对于同一大类下的多个子类有相同的词,则将该词从子类中取出加到大类中,并给以相应的权重,具体策略如下:

(5)给予单字词最低的权值。
本文将主题词的权值根据以上规则分为5等,即5、4、3、2、1。比如,“高中数学”是类别名称,如果在锚文本中出现这几个词,则该网页可以确定为高中数学类,所以赋予最高权值5;“直线的倾斜角与斜率”是高中数学的某章目录,只与高中数学类有联系,如果锚文本只出现该词,则可确定为高中数学类,所以分配次高权值4;另外,可以将“直线的倾斜角与斜率”切分为直线、倾斜角、斜率,“倾斜角”和“斜率”虽为高中数学类独有的单词,但如果出现其它词也可能改变其所属类别,所以分配给它们中等权值3;“直线”是高中数学类和高中物理类中共有的单词,属于跨类的词,它的重要性较其它几个要差,因而赋予权重为2;“函数”是高中数学和初中数学共有的词,并且其它学科没有该单词,因而将它作为数学类的主题词,权重为4;“家”虽然是高中语文的课文目录,但从独立的角度看,这个单字无法表征高中语文,因而给它赋予最低权重1。
二、基于规则的Web文档分类系统
1.分类规则的表达
教育学科资源具有三种属性,即学科属性、资源类型属性、学段属性,根据学科专家对这些属性的认识编写一定量的主题词模式规则,编写规则的原则是规则既不能过分细化,缺乏可推广性,又不能过分泛化,精确度不够。也就是说,要求规则集最大地覆盖正面实例,避免反面实例,从而形成一个全局优化的规则集。
定义1 设I={i1,i2,…,im}是一组物品集,D是一组事务集(称之为事务数据库)。D中的每个事务T是一组物品,显然满足T⊆I。如果X⊆T,称事务T支持物品集X。关联规则是如下形式的一种蕴含:X→Y,其中X⊆I,Y⊆I,且X∩Y=φ。[5]
根据这个定义,假设每类主题词的类标签为C,词条为T(T={t1,t2,…,tm}),那么可以用事务D:{C,t1,t2,…,tm}来表示该类词的模型,则主题词库可表示成事务集,其项集由主题词条和词条所属类别组成。所有的关联规则均从表示主题词集的事务集中产生。
对于建立一个分类器来说,本文感兴趣的是形如:T⇒C(T为词条项集,C为类标签)的事务。由此,本文定义如下的规则:
学科资源具有的属性描述为:父学科(即大类)属性(tp,weight,p_subject),学科(即小类)属性(ts,weight,subject),学段属性(tg,weight,grade),资源类型属性(tt,weight,s_type)。第一个参数表示词条,第二个参数表示词条的权值,第三个参数表示所属类别。
根据这些属性,可以定义四种规则,即父学科规则、学科规则、学段规则、资源类型规则。
(1) 父学科规则 Rulep:IF Weight(tp1+…+tpi)≥α THEN tp1∧…∧tpi⇒Cp
即单个锚文本中出现父学科某类的主题词权值之和不小于α,则可判断其链接网页为该类。
(2) 学科规则 Rules1:IF Weight(ts1+…+tsi)≥α THEN ts1∧…∧tsi⇒Cs
即单个锚文本中出现学科某类的主题词权值之和不小于α,则可判断其链接网页为该类。
Rules2:IF Weight(tpi+tsi+…+tgi)≥α THEN tsi∧tpi∧…∧tgi⇒Cs
即单个锚文本中出现父学科(或学科)中的主题词权值和学段中主题词权值组合后的权值之和不小于α,则可判断其链接网页为学科中该类。
(3) 学段规则 Ruleg:IF Weight(tg)≥α THEN tg⇒Cg
即从学段的主题词可以直接判断学段。
(4) 资源类型规则 Rulet:IF Weight(tt)≥α THEN tt⇒Ct
即从资源类型的主题词可以直接判断资源类型。
2.基于规则的分类
在基于规则的Web文档分类中,本文主要研究对超链接的锚文本(anchor)中的信息进行分类,下面给出这些信息的关系属性:
link_to( hyperlink, source_page, target_page):此关系式表明网页的超链接结构,第一个参数是超链接的标识,第二个参数表示hyperlink所属的网页,第三个参数表示hyperlink指向的网页。has_anchor_word(hyperlink):指超链接中锚文本的词。
对新的Web文档进行分类处理的过程如下:首先提取锚文本,进行分词,去除副词、连词、某些代词等对分类意义不大的停用词;然后搜索基于主题词库的规则集,对清理后的词条产生一个规则列表,将规则列表按类标签分组,设定一个期望阈值,将低于该阈值的匹配规则从分组中删除,接着将分组按词的权值之和排序,优先选择最大值分组的标签作为该文档的类标签。
算法1 将新的网页文档分类。
输入:一篇新的待分网页锚文本Anchor={t1,t2,…,tn};规则分类器;期望阈值τ输出:待分网页文档的类标签方法:
(1) S←φ
(2) for each rule r in Rule base //根据规则前件和Anchor中的词条产生规则列表
(3) if (r Anchor>τ)
(4) S←S∪r
(5) 根据类标签将入选规则集分为若干个子集:S1,S2,…,Sn
(6) order subset S1,S2, …,Sn according to weight sum
(7) Assign the class to the new document
三、实验结果与分析
1.数据集
本文对14个学科建立了主题词库,即小学语文、初中语文、高中语文、小学数学、初中数学、高中数学、初中物理、高中物理、初中化学、高中化学、初中地理、高中地理、初中生物、高中生物。测试过程是:对网页的锚文本进行分词,去除停用词,根据上述的规则,计算保留的词相应类别的权值,将权值大于或等于4的文档进行归类,权值小于4的文档丢弃。
在实验基于统计的分类时,对上述14类中的学科每类选择300篇训练文档,训练后每类取3000维特征项。两种方法采用同一开放测试集,每类50篇,共700篇Web文档。
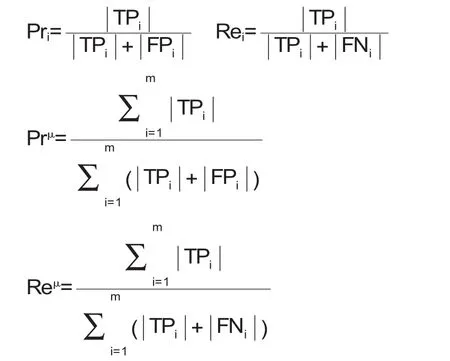
分类的评价方法采用精确率(Pri)、召回率(Rei)及微平均 Prμ/Reμ。
2.实验结果
表1给出了基于规则的分类结果,即每类的精确率和召回率,以及所有类的微平均精确率和召回率,并与基于统计的分类结果进行了比较,如表2所示。
从表1和2中可以看出,基于规则的分类精确率很高,微平均值为0.92,除了小学数学、高中语文、高中数学外,其它类的精确率都达到了0.9以上;但基于规则的分类召回率很低,微平均值为0.59,其中,小学语文、小学数学、初中地理、高中地理的召回率低于0.50。基于统计的分类与基于规则的分类相比,微平均精确率(0.73)降低了19%,但微平均召回率(0.69)提高了10%。

表1 基于规则的分类结果

表2 基于统计的分类结果
从两个分类实验的结果可以看出,两种分类方法各有利弊,规则分类只对锚文本分析,效率较高;统计分类对全文进行分析,效率较低。规则分类的精确率高,但是由于它丢弃了很多文本,因而召回率较低。
四、结束语
本文结合网络教育资源的特点,提出了一种针对网络教育资源的基于规则的分类方法,设计并实现了基于规则的Web文档层次分类系统,实验结果表明,性能良好。基于规则的分类效果取决于规则制定的好坏,所以要由领域专家不断修改、完善。当网页的标记信息无法准确表达主题概念时,这种方法将不再适用。下一步笔者打算将基于规则的方法与基于统计的方法相结合,以提高分类的整体效果。
[1]Ji He,Ah-Hwee Tan,Chew-Lim Tan.A Comparative Study on Chinese Text Categorization Methods[J].J.PRICAI Workshop on Text and Web Mining.2000:24-35.
[2]李渝勤,孙丽华.基于规则的自动分类在文本分类中的应用[J].中文信息学报,2004,18(4):9-14.
[3]谭金波.面向网络教育资源的文本自动分类系统的设计与实现[J].中国远程教育,2009,(4):68-70.
[4]杨学兵,蔡庆生.一种基于概念层次的分类规则挖掘算法研究[J].华中科技大学学报,2001,(9):18-20.
[5]马光志,张生庭.基于关联规则的Web文档分类[J].计算机工程与设计,2005,(9):2515-2518.
2009-11-30
谭金波,讲师,博士,山东师范大学教育技术系(250014)。
责任编辑 郑 重
G40-057
B
1009—458x(2010)03—0067—04
