基于本体的G3M语义增强策略
2010-11-29左琼曹忠升王元珍周强
左琼,曹忠升,王元珍,周强
(华中科技大学 计算机科学与技术学院,湖北 武汉,430074)
对多媒体数据进行有效管理离不开元数据的支持。当前,一些研究者常选多媒体内容描述接口MPEG-7作为语义提取、检索和系统集成的依据,然而,MPEG-7存在2个大缺陷:(1) 由于MPEG-7基于XML,使得它缺乏对高级语义的规范描述能力[1−2],具有歧义性,不利于系统互连;(2) MPEG-7描述的多媒体数据中的元数据、结构和内容中都含有大量隐含语义,未被有效提取和规范描述。虽然多媒体特征检索和基于关键词的相似性检索技术已较成熟,但仍远不能满足高级语义检索的需求。为了解决这些问题,Rahman等[1−5]将 MPEG-7元数据转换为知识本体,从而把多媒体语义描述和推理转向了语义Web研究领域。事实证明,知识本体能有效地协助多媒体语义描述,可用于建立多媒体索引[3−4]、规范查询条件[5]、自动提取高级语义和异构系统互连等[3,6−8],如:Hunter等[7−8]提出将MPEG-7语义元数据转换为DAML+OIL和 RDF模式(最终 OWL)形式,用于提供异构系统互连;DS-MIRF框架[9]是一个用来开发基于知识多媒体应用的软件工程框架,支持 MPEG-7/21元数据与OWL表示的本体相集成,将 2个领域的查询结果合并,形成多媒体数据上更有效的检索和用户交互,并运用到个性化检索上;Hammiche等[10]提出在MPEG-7元数据层上增加一个概念层,利用领域知识中的概念词汇和规则语言 CARIN来辅助多媒体内容检索,并支持查询重写发掘隐含信息。以上这些方法主要存在3个问题:
(1) 由于MPEG-7多媒体描述方案的MDS繁多,并面向多种应用,MPEG-7向知识本体转换的工作量庞大;不少系统[7−10]仅实现了MPEG-7中部分描述方案向本体的转换,没有充分利用MPEG-7元数据信息;有些系统不支持推理机制[7−8],无法得到实际应用。
(2) 大量多媒体元数据和实例存放在数据库 DB中,然而,DB用户无法对语义Web中的知识本体进行直接引用。
(3) 不少系统将知识推理查询和多媒体结构查询分别在语义Web和DBMS中完成,然后,组合生成查询结果,无法利用DBMS查询优化策略,大大降低了查询效率。
随着数据管理与知识管理结合越来越紧密,传统数据库厂商开始将知识运用到DBMS中,验证了将知识无缝结合到DB数据中的可能性,如:Oracle扩展了一组系统表及SQL操作符来存储OWL本体,支持基于本体的语义匹配[11];IBM DB2采用虚拟视图集成数据和领域知识[12],用XQuery和SQL/XML重写基于本体的查询[13]。虽然传统数据库对本体的支持仍有限,但其强大的事务管理能力、SQL查询方式和查询优化策略等,为基于本体的查询提供了良好的服务。G3M[14]是本实验室在对象关系模型上建立的一个基于 MPEG-7的通用多媒体数据库模型。为了解决从MPEG-7继承的缺陷,同时利用经典RDBMS的优点,本文作者将知识本体及其规则引入 G3M 数据库模式中,用于消除结构上的歧义性,在内容上提供有效的抽象语义表达和检索。
1 在G3M上引入知识本体
1.1 G3M体系结构及存在的问题
MPEG-7的最大优点是能对复杂的多媒体数据从结构、内容和元数据等多个层面提供多种描述。G3M充分利用了该特点,采用多级数据抽象机制[15]将整个模型划分为6层:原数据层、元数据层、段层、低级特征层、时空语义层和高级语义层,其中,段层描述结构、连接特征和语义。由于G3M源于MPEG-7,其缺陷也被一并继承,如:在段划分上,主要按媒体源、时空或语义来划分,但无法明确描述相同的段划分在不同应用中的不同含义;在高级语义描述上,能对概念对象/事件、物理对象/事件进行抽象描述,但缺乏对多个概念、多元关系、关系特性等规范进行描述,无法推理获取隐含语义信息。为此,本文作者采用与文献[10]中相似的方法,在G3M原有的6层模型上增加了1层知识概念层,如图1所示。利用本体对概念化的显式描述能力[16−17],提高 G3M 语义描述能力。它与文献[10]中的方法区别在于:知识本体被引入关系数据库系统中,能更好地与DB中存储的多媒体元数据及实例相结合,提供 G3M 上的知识集成和检索服务。
1.2 G3M中知识本体KO的形式化定义
要将本体集成到G3M中,首先要解决的问题是:如何在G3M中表示和存储知识本体。G3M以轻量级本体(Lightweight ontology)和领域模型(Domain model)定义[18]为参考,定义多媒体数据上的知识。将知识本体及其规则引入 G3M 数据库模式中,建立本体中概念、属性和关系与 G3M 多媒体数据模式和实例紧密联接。以下给出G3M上知识本体的形式化定义。
定义 G3M知识本体KO由一组概念、属性、概念间关系、知识规则、对象实例和对象关系实例等组成。定义为1个15元组:KO(IdKO, NKO, UC, UT, UAC, AKO,UD, TKO, LKO, FCC, CFCC,≤CC, Rul, FKM, FKI)。其中:
(1) IdKO和NKO分别为1个知识本体KO的唯一标号和名字。
(2) UC为知识概念集合,是一组描述词汇,可描述多媒体对象结构或语义,具体对应 G3M 模式定义的段划分、低级特征、时空语义或高级语义集合,或语义集合内部对象、事件、概念词等;UT为概念的数据类型及取值范围定义;UAC为概念上的属性关系集合,用来联接概念和其对应的取值。
(3) AKO为KO的类别。知识可以与领域/应用相关或无关(即上层本体)。若该 KO与领域相关,则由领域集合UD中的领域标号标明相关领域或应用,表示该KO专门为该领域/应用服务。
(4) TKO和LKO分别为概念出现/发生的时间和地点限制,可用来刻画物理对象或事件间的时空语义,或用于多媒体数据按时空关系组合。
(5) FCC表示概念间的非层次关系。对于结构概念,FCC描述结构上的时间关系、空间关系、结构语义等,对应G3M中段划分中的段间关系或其在特定领域/应用中所代表的语义;对语义概念,FCC描述概念上的各种关联关系,对应 G3M 中的对象间关系、事件间关系、事件对象关系、时空语义关系、段与高级语义间的关系等;CFCC描述 FCC中关系的特性,包括传递性、对称性、函数性等,可以用于关系上的查询条件重写。
(6) ≤CC为概念间的层次或分类关系,常用“is-a”来描述,用于知识推理或概念上的主题索引。层次关系用XML类型很好地表达,因此,将≤CC单独定义。
(7) Rul描述概念上的隐含语义关系或知识规则。为了能描述概念或其属性、关系上的各种内在关系特别是多元关系,仅仅用前面定义的 FCC,CFCC和≤CC是不够的。在知识本体表示中,通常用Datalog rule[9]来表示,G3M 把它转换为相应的“if (满足逻辑组合条件) then (断言/赋值)”语句。
(8) FKM和FKI分别为KO与G3M中管理的多媒体元数据或实例间的对应关系,可以是概念对象、属性或关系上的对应关系,用来直接建立KO与DB数据间的连接。由FKM建立KO与G3M中数据库模式(对应元数据)的连接,相应地也建立了该组模式中存储的数据(即遵循该元数据描述的多媒体实例)与该知识本体间的对应关系,这是一种从抽象到具体的连接。
G3M利用KO描述的抽象概念,将符合其限制条件的实例聚集到一起,可用于主题索引或高级语义查询。用户可用FKI直接建立某个多媒体实例(数据库模式上的1个元组)与知识本体关联。这是一种从特殊到一般的连接,常为多媒体实例创建者专用,主要用于标明该实例具有特定的语义限制或应用范畴,或需要利用该KO上的特殊关系和规则为其服务。
2 建立KO与多媒体数据的无缝连接
G3M设计了一个客户端工具来引入已有的OWL本体或用户自定义本体。而本体要能真正起到知识引导的作用,必须与G3M存储的多媒体数据紧密结合。以下从多媒体结构和语义2个方面来建立本体与G3M数据间的对应关系,真正地将知识本体与各种粒度的多媒体元数据及相应实例连接起来。
2.1 KO与G3M多媒体结构的关联
在多媒体结构上,G3M主要解决的是从MPEG-7继承的描述结构歧义性问题,主要表现为:
(1) 同一结构在不同应用中可能含义不同。
(2) 不同结构可以用来描述相同的语义。这主要是MPEG-7只定义了描述结构,但没指明描述结构的应用领域和语义环境,允许用户任意使用造成的。在结构上,加载领域知识可以明确该结构的含义。
对问题(1),要主要明确相关多媒体结构上对应的隐含语义信息。如:段−子段关系,一般视频段分解顺序为段、场景、帧;但在新闻联播和足球比赛中,段划分的含义完全不同,为此,G3M首先建立段本体,用段本体上的≤CC记载段和子段之间的层次关系;将新闻联播、足球赛等设置为段本体作用的不同领域;本体概念在不同领域下取值不同,在规则中设置赋值条件;建立SegUnit模式与段本体的联接,如图2所示。这样,直接为SegUnit加上应用领域约束,从而解决段定义的歧义性。这种抽象语义概念与段结构的直接关联能够为多媒体文档或结构段上初步的语义信息提取提供支持。
对问题(2),如 MPEG-7中 AgentObject DS和Object DS都可以用来描述人,在一定的应用环境下,它们具有等价性。但在数据库中,它们可能对应2张数据库表。G3M允许定义它们公用的领域知识本体,在其中定义这2张表对应的概念AgentObj和Obj,并在其关联关系中指明AgentObj和Obj在某领域上具有等价性;在规则中,定义2张表中属性列之间的对应关系。这样,将这2张语义相同、结构不同的表聚集在一起,在语义描述上统一起来,便于下一步检索,提高查全率。
在语义Web界,通常将MPEG-7元数据转换为相
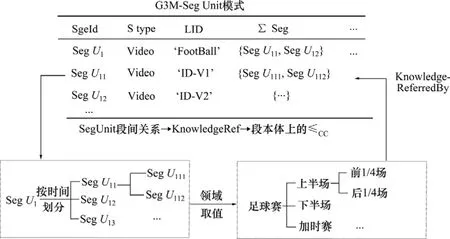
图2 利用领域知识限定G3M结构语义Fig.2 Ensuring G3M segment semantics with domain knowledge
应的上层本体,然后,在上层本体上定义领域本体来解决MPEG-7的歧义性问题[9]。G3M的优点在于:它省去了元数据向上层本体转换的繁琐工作,允许DB用户直接在数据库中引用领域知识,使得数据库模式具有明确的语义信息。
2.2 KO与G3M中多媒体语义的关联
在多媒体高级语义上,G3M关注KO中的抽象概念、属性和关系,特别是概念间的层次关系、属性取值、属性上的层次关系、概念间的各种关联关系及规则。有必要建立KO与G3M模式上元数据或实例中的各种具体对象、属性或关系间的对应关系。
为了建立知识本体与多媒体数据的关联,G3M完成以下辅助工作:
(1) 在高级语义集合Sem∑中定义概念对象/事件来汇集在段上出现的物理对象/事件。允许直接关联知识概念与G3M中的概念对象/事件,这种关联关系将自动传递到相关的物理对象/事件上。
(2) 特别定义“引用知识关系”(KnowledgeRef)和“知识被引用关系”(KnowledgeReferredBy),支持用户显式指明知识本体与数据的关联,如图2所示。
(3) 支持物理对象/事件上的显著低级特征描述。因此,假设已知概念实体及其部分显著的低级特征/属性,并把它们引入 G3M 中,将有助于物理实体的提取。在领域内交流,还可避免语义歧义性。
(4) G3M能灵活地表达多种概念在实体上、属性上、概念与属性上本体与实例上的关系,以便充分描述、正确引入知识。
除了本体与实例间的 4种基本关系(即 partOf,kindOf,instanceOf和 attributeOf)外,G3M 还支持多种特殊关系定义,如:specializationOf和generalizationOf表示专用和通用;componentOf 和hasComponentOf表示组成或层次关系,支持属性继承和重用;resultOf和causeOf表示因果关系;similarTo和oppositeTo表示相似与否等,并支持自定义关系。这些关系可以用于完善查询条件,支持查询推理,提高查询效率。
语义关联的建立有助于 G3M 利用特定应用领域知识或者用户背景知识,对多媒体数据描述的语义主题进行较完整的知识补充和聚集,如:假设一组图片主题为鸟,在 G3M 中引入鸟本体定义,将各种属于鸟纲的动物定义在概念集合中,给出它们的关联关系、从属关系、属性定义和规则定义,建立鸟本体概念与G3M中存储的图片中物理对象间的关联。这样,包含鸟科动物的图片信息能根据鸟本体概念聚集起来。这种将描述相同主题概念的多媒体实体聚集的方式,能大大提高查询效率。
3 G3M上基于KO的多媒体语义检索
由KO定义可知:KO可以分为上层知识或领域/应用相关知识,对 G3M 的语义检索具有不同的指导作用。
3.1 上层知识在查询中的运用
G3M 定义了大量的上层通用关系[14],如时空关系、对象间关系、对象事件关系、事件间关系等。这些关系多有自身特性,如互补性、对称性、传递性和函数依赖性。在关键词查询中,人们往往忽视这些关系特性,而导致查询条件不完整或与MPEG-7语义描述不匹配。例如:寻找1张多媒体图片,其中出现了对象A和B,且A在B的前面。其对应的SQL语句为:
SELECT * FROM SegUnit WHERE SType=’image’
AND ExistObj(‘A’) and ExistObj(‘B’)
AND HasTempRelation(‘A’, ‘B’,before)该语句直接用于DB查询时,查询结果可能不完全。如DB中可能存在这样的描述:对象B在对象A的后面。由于’before’和’after’是 1 对互补关系,“A before B”和“B after A”在语义上是等价的,但不满足关键词查询条件。
G3M 用一个特殊的上层关系本体来存储其所有关系名、关系间的关联关系和关系特性。当1条查询语句到来时,查询引擎首先将语句中出现的关系谓词或参数是否与关系本体中的关系名概念相匹配。若存在,则按照关系特性或规则对查询条件进行第1次查询重写。例如:上例中有关关系的条件被重写为:
…AND ( HasTempRelation(‘A’, ‘B’,before)
OR HasTempRelation(‘B’ , ‘A’, after))这次查询重写的结果并不一定是最优的,需要利用RDBMS上经典的关系优化策略进行优化,生成相对最优的查询计划并执行。这样,直接将查询优化策略运用到基于本体的查询上,提高了基于本体查询的效率。与将多媒体实例和本体分别在DB和语义Web中进行处理,然后合并查询结果的方法相比,本文查询方法具有明显优势。
3.2 领域知识在查询中的运用
多媒体数据包含丰富的语义信息。不同用户拥有不同的背景知识,对同一个多媒体对象的关注点和理解可能完全不同,因此,G3M 允许指明特定领域/应用本体与多媒体数据的对应关系。领域知识的利用将有助于挖掘数据中存在的隐含语义。
以前面提到的鸟为例。假设用户要查询“候鸟”,在图片注释信息中,可能根本没有“候鸟”这个词,这时,用户若直接查询“寻找包含对象名为候鸟的图片”,则无法得到想要的查询结果。
按照人脑思维,首先联想所有属于“候鸟”的鸟类,将查询转换为对属于候鸟的鸟类查询;若候鸟概念不清楚,则根据候鸟定义生成相应的查询条件,如“当适宜温度低于 25 ℃时,过冬方式为向南飞翔的鸟”,寻找所有满足此条件的鸟类。从知识本体角度看,以上查询实际上是对鸟本体中候鸟概念集合的遍历及鸟属性“适宜温度”和“过冬方式”的匹配,而候鸟定义可以视为1个规则。为此,在RDBMS原有的查询引擎上增加1个G3M语义添加器模拟人脑,以实现这种基于知识的查询。
当 G3M 查询引擎发现查询条件与本体概念或属性关联时,系统会进行第2次查询重写。将在本体上按照关系或规则推理得到的新概念、属性或关系,添加为新的查询条件,接着按照第1次查询重写后的步骤来实现查询优化处理。这样,关键词检索在 G3M内部被转换为高级语义检索,从而有效地挖掘了多媒体数据上的隐含信息。
4 实验验证
以下对所提出的基于本体的查询推理方法进行实验验证,从查全率和查准率上验证此方法的可行性。测试硬件平台为奔腾双核 2.80 GHz,2 G内存;操作系统为Windows XP;开发工具为JAVA+Eclipse;后台数据库为IBM DB2 V9。
在G3M数据库中准备了3 000个关于鸟的图片实例,将对象鸟的描述存储在语义对象表semanticsT中。在知识本体模式中准备了1个鸟本体,建立鸟本体中概念、属性、规则和表semanticsT中属性列的关联,并进行如下5类语义查询。
Q1:查询所有包含“燕子”的图片,以测试概念间层次关系树中的叶子节点。
Q2:查询所有包含“鸥类”的图片,以测试概念间层次关系树中的内部节点。
Q3:查询所有包含“武汉燕子”的图片,以测试概念间层次关系树中的叶子节点和属性取值层次关系树中的叶子节点。
Q4:查询所有包含“北京涉禽”的图片,以测试概念间层次关系树中的内部节点和属性取值层次关系树中的内部节点。
Q5:查询所有包含“候鸟”的图片,以测试基于知识规则推理的查询。
对比普通查询和加入知识推理的查询结果,如表1所示。可见:在加入知识本体后,语义查询的查询率和查准率分别为 75.13%和 95.09%,大大高于普通查询结果的查询率和查准率。基于知识查询的查全率不够高的原因在于:实验数据是一些随机找到的包含鸟的多媒体图片,部分图片缺乏对鸟的原始注释信息。而查准率高是因为知识本体对鸟类的分类和规则定义是有效的,图片实例对鸟的描述方法和本体中对鸟的描述方法基本一致,因此,能够基于知识本体在基础数据上获得想要的查询结果。
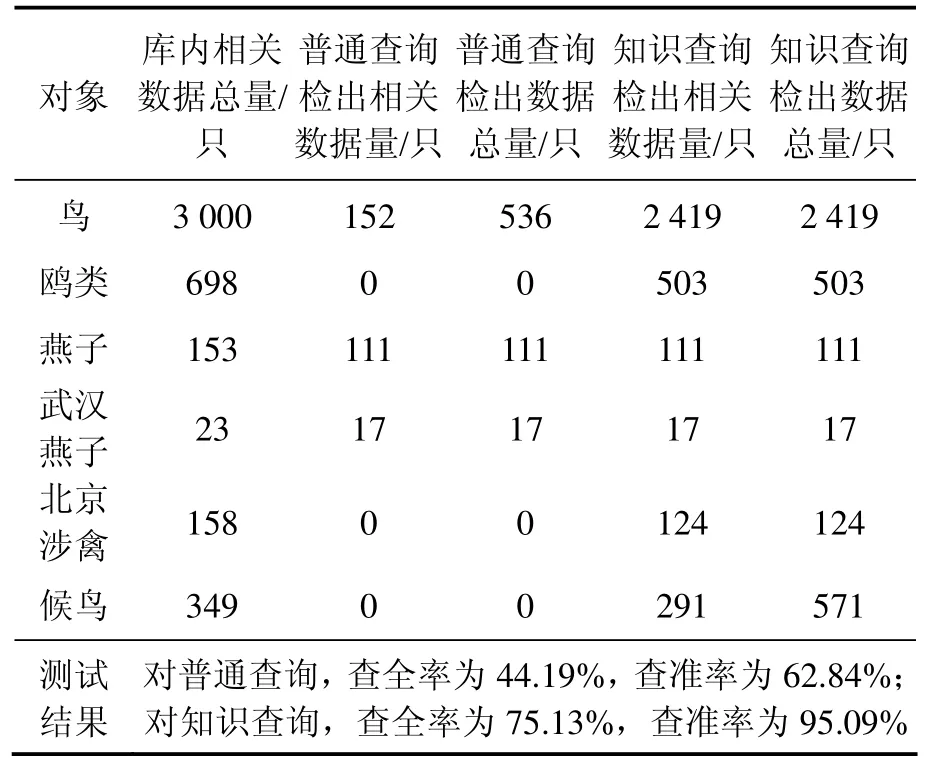
表1 G3M基于本体的语义查询查全率和查准率测试结果Table 1 Recall radios and precision radios of ontology-based semantic query of G3M
5 系统特色分析
将知识本体概念、属性、关系、规则直接引入G3M的优势包括如下4点:
(1) 免去了MPEG-7 MDS按某种本体描述语言转换为语义Web中上层本体的工作。G3M模式定义本质上是一种对媒体描述方法的规范,在DBMS中实现了知识语义-MPEG-7概念语义-时空语义-低级特征/多媒体物理组织结构之间的无缝联接。
(2) 避免了 MPEG-7描述的不规范性。通过在G3M 模式上直接加载领域/应用知识,在通用多媒体内容和结构描述上直接加注语义约束,变通用模型为专用模型,为系统互连及抽象语义提取提供基础。
(3) 能够更好地从知识层抽象的角度,根据本体中的相似概念、属性关系、归属关系定义等,进行多媒体内容的高级抽象,进行主题语义聚集,实现元数据的自动组织和合并,或在物理上按知识本体进行多媒体数据实例的聚集,能揭露元数据上未被识别的关联,引导数据库中查询结果或新知识的合成,有助于提高语义检索的效率。
(4) 定义上层本体,用于规范MPEG-7上已有的关系定义,提取关系上的隐含特性;利用查询重写,进行语义等价替换,完善用户的语义检索条件;同时,利用领域相关本体,自动在查询条件中添加知识推理出来的条件,充分利用RDBMS上的查询重写、查询优化策略,真正实现基于语义的检索,有助于发掘隐含语义信息。
参照王煜等[19]提出的丰富语义模型评价准则和它对多种视频模型的分析,G3M 在语义获取能力方面,能满足 5条评价准则中的 4条(领域知识引入DBMS、语义初步提取、推导隐含信息或新的抽象信息、支持不同用户在同一多媒体段具有不同视图),大大优于文献[19]中的11个视频语义模型。
6 结论
(1) 知识本体的引入去除了MPEG-7带给G3M的结构歧义缺陷,增强了G3M的开放性,提高了G3M对高级语义智能化提取、表达和检索能力,有助于隐含语义的发掘,真正实现了按多媒体语义检索。
(2) 实现了基于知识本体的智能语义查询。通过二次查询重写手段,将上层关系本体和领域知识本体运用到存储在 G3M 中的多媒体数据上,变推理规则为G3M语义查询条件。本体推理查询与G3M普通查询融合在DBMS中,充分利用了RDBMS上经典的查询优化技术和查询引擎。
[1]Rahman M A, Hossain M A, Kiringa I, et al. Ontology-based unification of MPEG-7 semantic descriptions[C]//The 4th International Conference on Electrical and Computer Engineering. Dhaka, Bangladesh, 2006: 291−294.
[2]García R, Celma Ò. Semantic integration and retrieval of multimedia metadata[C]//The 5th International Workshop on Knowledge Markup and Semantic Annotation. Galway, Ireland,2005: 69−80.
[3]Tsinaraki C, Polydoros P, Kazasis F, et al. Ontology-based semantic indexing for MPEG-7 and TV-Anytime audiovisual content[J]. Multimedia Tools and Applications, 2005, 26(3):299−325.
[4]Mylonas P, Athanasiadis T, Wallace M, et al. Semantic representation of multimedia content: Knowledge representation and semantic indexing[J]. Multimedia Tools and Applications,2008, 39(3): 293−327.
[5]SUN Wei, LIU Da-xin. Using ontologies for semantic query optimization of XML database[C]//Nayak R, Zaki M J.Proceeding of 1st International Workshop on Knowledge Discovery from XML Documents. Heidelberg, Berlin:Springer-Verlag, 2006, 3915: 64−73.
[6]Naeve A. The human semantic web: Shifting form knowledge push to knowledge pull[J]. International Journal of Semantic Web and Information Systems, 2005, 1(3): 1−30.
[7]Hunter J. Adding multimedia to the semantic web-building an MPEG-7 ontology[C]//Proceeding of International Semantic Web Working Symposium. Stanford, California Amsterdam: IOS Press, 2001: 261−281.
[8]Hunter J. Enhancing the semantic interoperability of multimedia through a core ontology[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2003, 13(1): 49−58.
[9]Tsinaraki C, Polydoros P, Christodoulakis S. Interoperability support between MPEG-7/21 and OWL in DS-MIRF[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(2):219−232.
[10]Hammiche S, Lopez B, Benbernou S, et al. Query rewriting for semantic multimedia data retrieval[J]. Studies in Computational Intelligence, 2008, 116: 351−372.
[11]Das S, Chong E I, Eadon G, et al. Supporting ontology-based semantic matching in RDBMS[C]//Proc 30th VLDB Conf.Toronto, Canada: VLDB Endowment, 2004: 1054−1065.
[12]Lim L, WANG Hai-xun, WANG Min. Unifying data and domain knowledge using virtual views[C]//Proc 33rd VLDB Conf.Vienna, Austria: VLDB Endowment, 2007: 255−266.
[13]Lim L, WANG Hai-xun, WANG Min. Semantic data management: Towards querying data with their meaning[C]//Proceeding of the 23rd International Conference on Data Engineering. Istanbul, Turkey, 2007: 1438−1442.
[14]ZUO Qiong, CAO Zhong-sheng. G3M: A generalized multimedia data model based on MPEG-7[C]//Proceeding of the 2nd International Conference on Multimedia and Ubiquitous Engineering. Washington DC, USA: IEEE Computer Society,2008: 155−159.
[15]Megalou E, Hadzilacos T. Semantic abstractions in the multimedia domain[J]. IEEE Transactions on Knowledge and Knowledge and Data Engineering, 2003, 15(1): 136−160.
[16]Hammiche S, Benbernou S, Vakali A. A logic based approach for the multimedia data representation and retrieval[C]//Proceeding of the 7th IEEE International Symposium on Multimedia.California, 2005: 241−248.
[17]Benítez A. Multimedia knowledge: Discovery, classification,browsing, and retrieval[D]. New York: Columbia University.Electrical Engineering Department, 2005: 1−50.
[18]Hernandez N, Mothe J, Chrisment C, et al. Modeling context through domain ontologies[J]. Information Retrieval, 2007,10(2): 143−172.
[19]王煜, 周立柱, 邢春晓. 视频语义模型及评价准则[J]. 计算机学报, 2007, 30(3): 337−351.WANG Yu, ZHOU Li-zhu, XING Chun-xiao. Video semantic models and their evaluation criteria[J]. Chinese Journal of Computers, 2007, 30(3): 337−350.
