改进遗传神经网络在甘蔗产量预测中的应用
2010-11-10徐永春张森文
徐永春,张森文
(1 华南农业大学工程学院,广东广州 510642;2 广东理工职业学院计算机系,广东广州 510091;3 暨南大学应用力学研究所,广东广州 510632)
甘蔗产量的预测是制糖工业的一项重要技术管理工作,对优化提高甘蔗生产作业及统筹管理具有指导作用.在甘蔗产量预测中,农作物产量、气象等是重要影响因子,应用传统数理统计方法对农作物产量、气象等的预测预报的研究已较为成熟,但该法对受外界多因素关联作用的农作物产量预测存在预测难度大、精度差、准确度低等问题,在实际应用中难以符合需求.近年来,神经网络在人工智能领域的应用研究十分活跃,但仍存在训练时间长、收敛于局部极小值等不足,使得传统的神经网络算法在网络学习训练中所获得的网络权、阀值在训练效率和精度上都有所下降[1-2],而与之对比的人工智能算法——遗传算法则具有简单通用、鲁棒性强和并行运算等优点,二者的结合将强化BP学习训练、优化BP神经网络权阀值,促进BP神经网络的快速收敛,提高BP网络神经预测的效率与精度.但传统遗传算法存在一些具有超高适应度的个体,它们在选择算子时,会以很大的概率参加繁殖,引起群体平均适应度饱和、个体间竞争力减弱,导致运算收敛速度下降,甚至是未成熟收敛,出现“早熟”现象[3-4].为有效发挥遗传算法的特色优势,在应用中需对算子选择方法、判别做适度改进.
甘蔗生产是市场调节、种植规模、气候调节多因素作用关联的大系统.在甘蔗产量预测中,简化农作物产量、气象等输入因子对于构建规模适度的BP网络模型,提高BP网络的训练效率和精度有直接的作用.本文通过多元逐步回归简化输入参量,有效结合遗传算法与神经网络算法,构建改进的遗传神经网络甘蔗产量预测模型,并以实例验证.
1 改进遗传神经网络设计
1.1 遗传算法改进设计方案
神经网络的优化设计问题属于高维连续的寻优问题.根据BP网络输入节点设计的需要,本文采用搜索精度高、搜索空间大的实数编码方案,可以较好地解决因空间不足而导致算法收敛缓慢问题.
在遗传算子的改进方案中,遗传参数中的交叉概率pc和变异概率pm是决定遗传算法(GA)性能的关键,无论过大还是过小,都会直接影响算法的收敛性和收敛速度,但很难找到一个适应每个问题的最佳值,对于不同的优化问题需要反复试验来确定pc和 pm.Scinivas 等[5]和 Fogarty[6]提出了种群随迭代次数增加而收敛调整pc和pm的概率值,控制pc和pm最小范围,但算法的自适应能力较差.本文在文献[7]基础上,改进自适应交叉和变异算子,设计自适应的交叉和变异公式(1)和(2),在预测仿真前实例验证,证明变异概率随指数下降有很好的性能,其自适应的交叉和变异公式为:

式中,t为遗传迭代次数;t_max为最大遗传代数;λ、k为常数,根据种群分布大小取值,一般为[5,10];pc1、pm1分别为固定交叉概率和变异概率.通过式(1)和式(2)可控制 pc取值在[0.5,1]之间,而 pm取值在[0,0.5]之间.通过自适应交叉和变异处理的遗传算法,出现适应值高于群体平均值的个体有更大的概率进入下一代,而适应值低于群体平均值的个体则将被淘汰,从而可大大加快遗传算法收敛.
1.2 基于改进遗传算法优化的BP网络设计
利用改进遗传算法与BP网络形成混合训练算法,使每个个体包含若干条染色体,每条染色体对应1个权值或阀值,染色体采用实数编码,通过上述改进策略,则改进的遗传BP网络模型设计框架主要是以权阀值训练为主.首先由改进GA进行全局搜索,将搜索范围缩小后,交与BP网络执行局部寻优,发挥其局部寻优的高精确性,具体步骤如下:
1)初始化网络,初始化群体;
2)计算神经网络误差函数个体适应度,若达到预定精度要求则转5);
3)遗传操作(选择、交叉、变异),产生新一代个体;
4)改进自适应交叉和变异算子更新;
5)解码,获得优化的BP网络权阀值;
6)再以优化的权、阀值进行BP模型的数据仿真预测.
2 甘蔗生产预测仿真
在甘蔗产量预测模型研究中,外界因子如气象、品种资源分布率、化肥、人工技术等均对甘蔗产量预测有显著的关联作用.因此本文构建的改进遗传算法BP模型选取对产量有显著影响的气象、优化品种种植分布率作为输入外界因子.因气象、品种资源等外界因子在预测过程中,不能够独立提供预测模型参数,故气象、品种资源需要进行自我学习、训练完成下一步的预测工作[8-9].
在模型仿真训练中,本文采用1995—2004年10年间的气象、品种资源分布率等作为外界因子.
气象因子主要包括温度、湿度、降雨量和日照,而在每年甘蔗生产中,只有若干季度是甘蔗最主要的外界生产影响条件,每年12个月中有48个外界气象因子、若干品种资源分布数据及年甘蔗产量,通过组合改进遗传算法BP模型输入因子达到58个,使预报因子数目过大,导致计算复杂,降低了模型的预报精度,因此根据BP模型训练需要,通过多元逐步回归简化而得到甘蔗生产最终输入的关键输入向量,其数学方程如下:
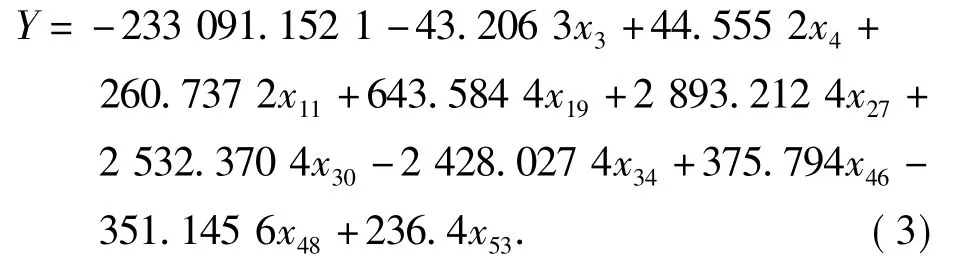
在式(3)的输入向量中,x1~x12分别为1—12月的气温输入向量因子,x13~x24分别为1—12月的日照输入向量因子,x25~x36分别为1—12月的降雨输入向量因子,x37~x48分别为1—12月的湿度输入向量因子,x49~x57分别为品种资源输入向量因子.最后通过多元逐步回归方程简化可得其最终决策外界因子为:x3,x4,x11,x19,x27,x30,x34,x46,x48及 x53等 10 个输入因子.
由于采用自学习样本,因此本文的模型数据设计即为以1994—2003年训练样本由甘蔗均产及外界因子等9×11个变量所构成,同理,2004—2006年3组样本(3×11)作为教师样本.
为验证预测仿真的精度及效率,本文同时采用灰色线性外推法、SBP、SGA-BP、SBP、RINAGA-BP 等多种算法对甘蔗产量进行预测.各BP模型参数的设置均为:动量系数(lr)=0.95,迭代次数(MAXGEN)=10000,误差精度(e)=0.00001;不同模型所获得预测及误差如表1、2.

表1 不同模型预测的甘蔗产量Tab.1 Result by different model kg·hm -2
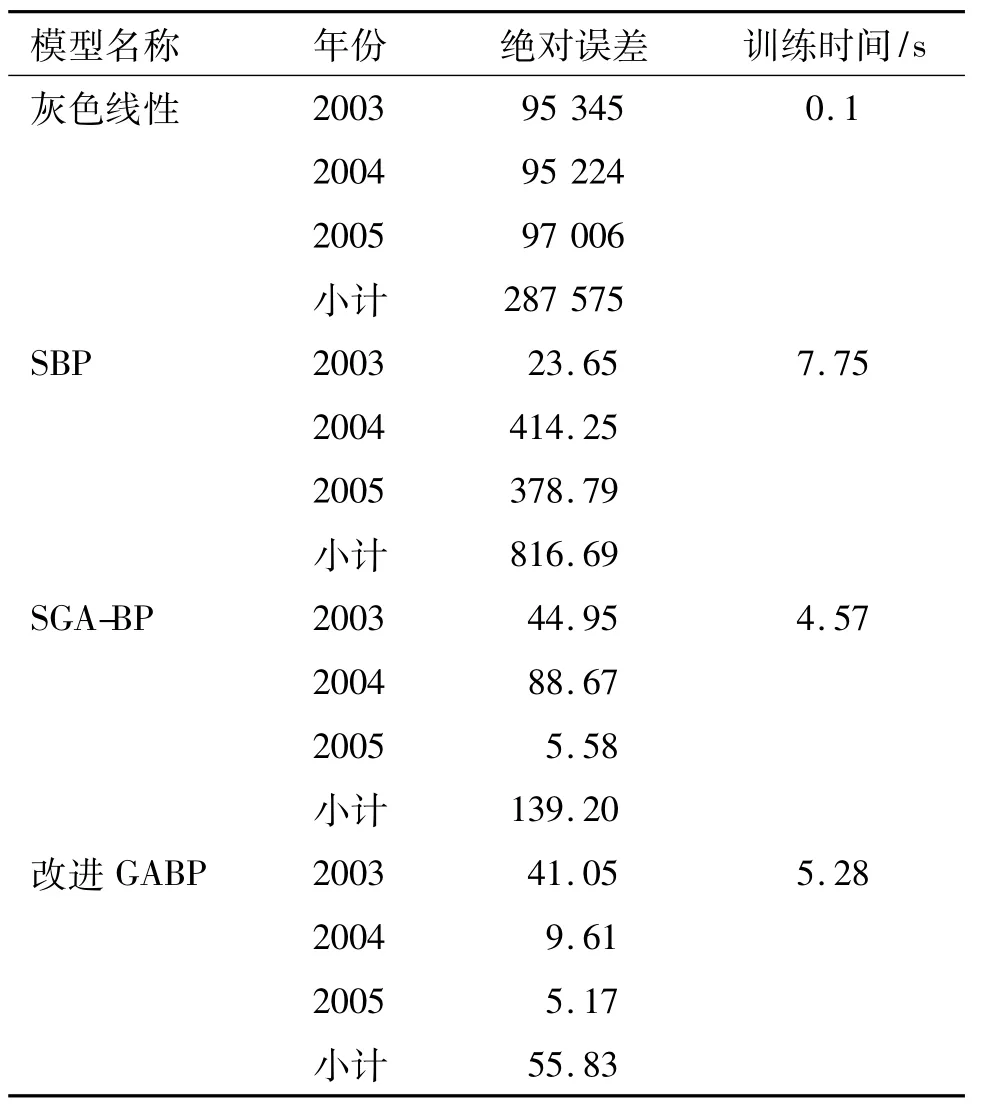
表2 不同模型的预测训练时间及误差和Tab.2 Training time and erroneous sum with different model of forecast
由表2可知,灰色线性外推法误差和最大,时间最短,但决策可用性极低;BP模型可显著降低预测误差.不同BP模型训练误差、训练时间差异较大,SGA-BP训练时间消耗最小,改进遗传算法的BP预测其次,但其误差累计和最小,其模拟预测的精度最高,综合而言,效果最优.
3 结论
通过编码、遗传算子的改进,提高传统遗传算法的全局搜索和收敛效率,并以改进遗传算法对BP网络权阀值进行全局优化,提高了BP神经网络运行速度,从而有效克服了传统BP网络方法的缺点;针对甘蔗复杂的输入因子进行多元逐步简化,优化和提高了改进遗传BP在甘蔗生产预测仿真的学习效率.该预测模型与多种预测方法对比,验证了在多因素作用关联下的甘蔗产量预测效率和精度.结果显示,改进遗传算法在BP方法上的优越性和合理性,这对于甘蔗产量的多因素关联作用的预测预报应用具有重要参考价值.
[1]沈清.神经网络应用技术[M].长沙:国防科技大学出版社,1993:45-85.
[2]徐永春,张森文.遗传K均值方法在品种资源分类中的应用[J].华南农业大学学报,2009,30(2):97-100.
[3]陈国良,王熙法,庄镇泉,等.遗传算法及其应用[M].北京:人民邮电出版社,1996:80-81.
[4]谢凯.排挤小生境遗传算法的研究与应用[D].合肥:安徽理工大学计算机科学与工程学院,2005:43-53.
[5]SCINVIVAS M,PATNAIK L M.Adaptive probabilities of crossover and mutation in genetic algorithms[J].IEEE Trans SMC,1994,24(4):656-666.
[6]FOGARTY T C.Varying the probability of mutation in genetic algorithms[C]∥Anon.Proceedings of the 3rd International Conference on Genetic Algorithms.Boston:Boc.,1989:104-109.
[7]徐永春.基于智能算法的甘蔗生产决策模型研究与应用[D].广州:华南农业大学工程学院,2008.
[8]高大启.有教师的线性基本函数前向三层神经网络结构研究[J].计算机学报,1998,21(1):80-86.
[9]陈磊,张士乔,吕谋,等.自适应遗传算法优化管网状态估计神经网络模型[J].水利水电技术,2004,35(10):61-63.
