基于双信息源的协同过滤算法研究
2010-10-25董全德
董全德
(1.合肥工业大学 计算机与信息学院,安徽 合肥 230009;2.宿州学院 信息工程学院,安徽 宿州 234000)
0 引 言
随着电子商务的发展,个性化推荐系统已经成为电子商务服务中一个重要元素和保持电子商务网站竞争力的重要保证。协同过滤(Collaborative Filtering,简称CF)是最成功的个性化推荐技术,它借助已知的一组用户兴趣或项目特征来实现对目标用户或目标项目的推荐。协同过滤技术在许多的商务网站中得到了成功的应用[1]。然而,传统CF技术遇到一些较难解决的问题[2],如冷启动、数据的稀疏性和推荐的可靠性等问题。特别是CF在处理交互性强和需要专门技能知识的领域,更显得力不从心。
为解决上述问题,提高CF技术的效能,很多学者提出了一些改进传统CF算法。文献[3]提出了基于模式协同过滤算法,利用朴素的贝叶斯网络(NB)、tree-argument NB、NB-ELR 或者TAN-ELR分类器增强处理稀疏数据方面的能力,对用户-项目矩阵中缺失的评分实现填充,这种方法对解决数据的稀疏性问题有一定的效果,但对传统CF算法性能的改变意义不大;文献[4]提出了混合的推荐系统(Hybrid CF Algorithm,简称HCF),试图克服单个系统的缺点。最有代表性HCF是content-boosted CF,应用NB网络,填充CF评分矩阵中缺失的数据项,构成一个不完全真实的用户评分矩阵。然后,借助带有权重的Pearson correlation应用到这个用户评分矩阵中,形成特殊的对用户的项目推荐。但该算法未考虑需要专门知识领域的推荐项目,而且项目的内容信息并不是都能得到,特别是对于有许多产品种类的大型电子商务网站而言,为了实现基于内容协同过滤算法,需要提取这些产品种类的许多特征,这项工作是非常困难的。
到目前为止,所有CF算法把它们的推荐建立在一个单一的推荐组中,为了解决数据稀疏性,针对具有专门知识背景的项目推荐,本文提出了基于双信息源模式的协同过滤算法(Dual Information Source Model-Based Collaborative Filtering Algorithms,简称DISCF),该方法判断活动用户对目标项目的兴趣程度建立在相似用户推荐组(最近邻居集合)与专家推荐组的基础上,把2个推荐组的建议结合起来,形成可靠的信息源,然后分析各自影响活动用户对目标项目的权重,计算活动用户的最终兴趣度,实现系统推荐。
1 DISCF算法的相关基础知识
1.1 DISCF算法流程图
DISCF算法流程如图1所示。
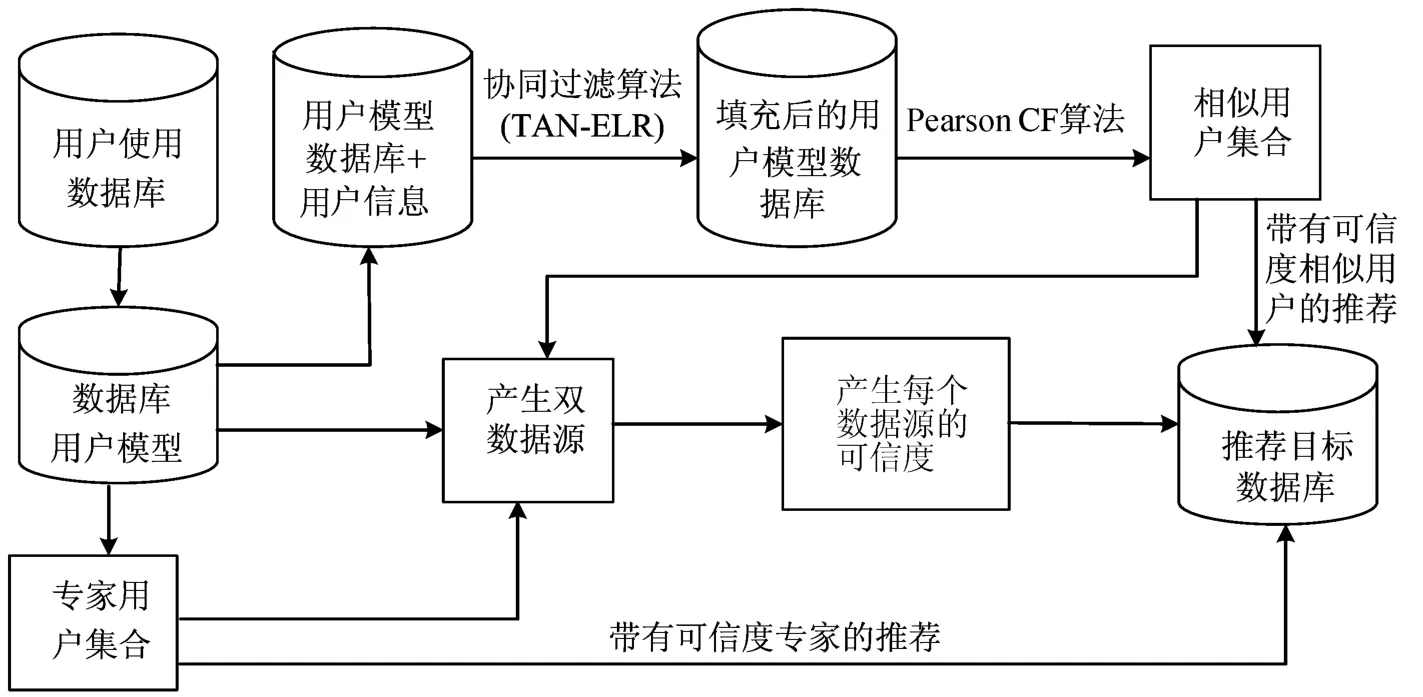
图1 DISCF算法流程图
1.2 DISCF算法的消费心理学基础
DISCF算法是建立在消费者心理学观点基础上的,影响消费者购买行为的因素很多,这些因素产生的作用也不相同,如产品的特性、产品与消费者的密切关系和消费者对产品的了解[5]。
在现实生活中,一个消费者在选择观看电影或购买日用品等小型商品时,可能仅仅会征求具有相同兴趣爱好的相似用户(最近邻居集)的意见,但是,当他们在选择价格比较昂贵的产品时,如一台笔记本电脑,往往更多会选择征询专业人士的意见,这就是推荐信息源的多样性;不同的消费者在相同产品领域中对推荐源的选择也是不同的,有的消费者会选择有着相同兴趣的最近邻居的观点,有的会从更多的专业人士身上获取建议,这就是推荐信息源的可信度;有些产品的消费者愿意花大量的时间与精力去了解产品的特性,有的消费者瞬间就能做出购买决定,这代表产品的关联度水平。现有的CF算法没有综合考虑推荐源的多样性、多样的推荐源的信任度及产品的关联度水平。
1.3 DISCF算法数据准备
实现DISCF算法关键是找到活动用户的相似用户集和专家用户集,并分别求出对目标项目的推荐值及推荐值的可信度,需要利用用户-项目评分矩阵。但对于一个大型电子商务网站,用户-项目评分矩阵是非常稀疏的,为提高计算相似用户的准确率,解决数据稀疏性,本文用TAN-ELR方法对用户-项目评分矩阵中未评分项做出预测。
现有的混合推荐系统多数用NB作为内容的预测器。NB的问题在于给定的分类参数中,把属性作为独立的内容来考虑,而树增强型简单贝叶斯网络(TAN)能够充分考虑属性之间的关联,比NB产生更好的分类效果。然而,NB和TAN都需要寻找产生最好效果的分类器,而最好的目标是事物的回归模型鉴别器-LR(Logistic Regression,简称LR)能找到使鉴别效果达到最好的参数,但是LR需要一个像NB网络一样简单的结构。TAN-ELR把它们之间的优点结合了起来,首先找到一个能使鉴别效果最优化的NB结构,然后找到一个效率高的分类参数,文献[3]证实了TAN-ELR在面对完全或不完全的数据时都表现出较好的分类效果。因此,本文使用TAN-ELR作为内容的预测器。用户原有评分表作为等级值,把关联的用户信息作为属性值来训练TAN-ELR模式,通过这种模式对未评分的项目,结合其内容信息给出评分的预测值。在评分矩阵中对每一列(每一个项目)均重复上述过程,在评分矩阵中未被评分的项目会被用这种模式得到的预测值填满从而得到一个改善的用户评分矩阵,解决了数据稀疏性的问题。
2 DISCF算法的实现
2.1 构造DISCF算法的双信息源
经过数据准备,首先通过计算目标用户a的最近邻居集,并且求出它们对目标项目i的兴趣度,构造相似用户的信息源。最近邻居集是指与目标用户a有相同的用户兴趣评分表。在相似度计算上,使用在传统的CF系统中应用最广泛的Pearson's关联系数,目标用户a与其它用户u的相似度定义为:

其中,Ru,i为用户u对项目i的评分;Ra,i为目标用户对项目i的评分。
在文献[6]的研究基础上,选择相似度数值超过0.3的用户形成目标用户的最近邻居集。求出最近邻居集对目标项目i的预测值S(a,i),这里利用相似用户的特性加权数值,而不是简单的相似用户兴趣度的平均值,其计算公式为:
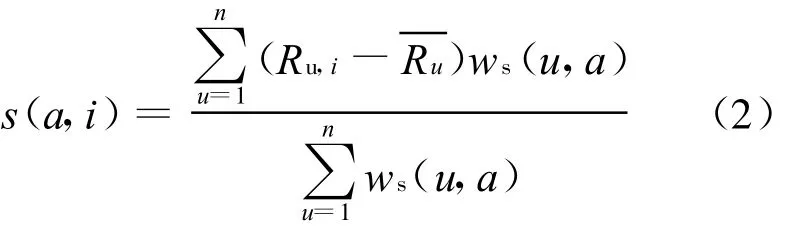
其中,Ru,i为邻居用户u对项目i的评分值;n代表目标用户a邻居用户的个数。
然后,找到专家用户集合,计算出它们的预测值,形成第2个信息源——专家信息源。在文献[7]和理解专业知识概念的基础上,本文给出专家用户组的定义:在包含待推荐项目的领域中,已经做了大量的工作,它们有足够的能力对其它用户做出正确的推荐建议,并设计出一个能反映用户能力或预测能力的专业知识技能的度量方法。专业知识技能可以描述为整体水平(如电影专家)、类别水平(如动作电影专家)和个别水平(如电影《赤壁》的专家)。文献[8]中说明在实现推荐的过程中,越具体描述的专家,越能实现更好的推荐。然而,在现实生活中,非常具体、个别化水平的专业知识对协同推荐意义不大。
因此,本文中度量专业知识技能是用类别项目水平。用ωe定义专家知识水平,它表示用户u对类别c的专业知识技能水平,其计算公式为:
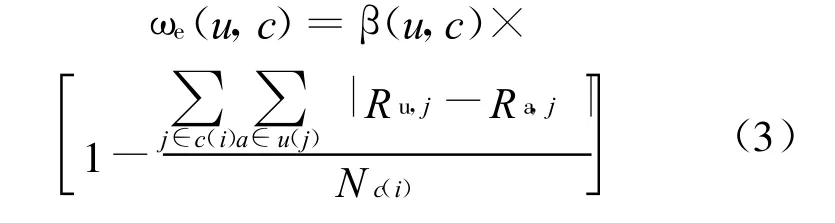
其中,U(j)为除了用户u之外的、对项目j有操作行为的所有用户的集合;C(i)是与目标项目i属于同一种类的所有Web中被访问过所有项目的集合;Nc(i)为C(i)的基数;β(u,c)为一个可以变化的权重值,可定义为1-1/n(n是在类别中被评分的次数)。当一个用户在类别中评分的次数越多,就能得到一个较高的知识水平的值。从每一个类别领域中具有专业技能知识的用户中选择最高的3%,组成专家用户组。
专家用户组的推荐能力用E(i)表示,其计算公式为:
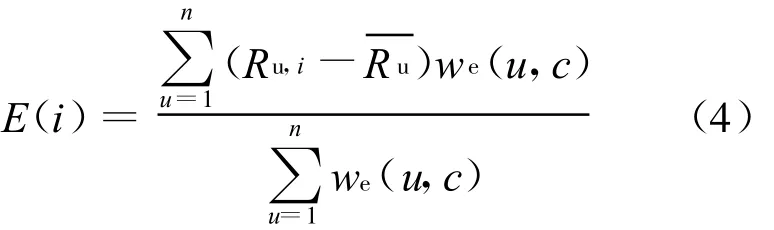
其中,Ru,i为专家用户u对目标项目i的评分;n为在专家用户组中专家的数目。
2.2 DISCF算法双信息源的可信度计算
通过计算,可获得每个信息源对目标用户和目标项目的推荐值,下一步计算目标用户对2个信息源的可信度。假设每一个用户对任意的信息源的可信度都不一样,本文提出的推荐源可信度模式为:
其中,a、i代表目标用户与项目的编号;Ks与Ke分别为目标用户a对最近邻居集与专家用户集可信度。可利用最小二乘法的多重回归积分分析的方法求出它们的值。如果相似用户与专家用户有重叠的部分,S(a,i)和E(i)就会发生多重共线性问题,在这种情况下,计算Ks与Ke就可能变得很困难。如果在2个变量之间存在多重共线性(当膨胀因子值大于10时,冲突存在),借助回归分析计算Ks和Ke。最后完成对推荐项目的预测评分,其计算公式为:
在实现推荐的过程中,可能会遇到2种特殊的情况:①只存在一个信息源(如没有最近邻居集),DISCF算法将在存在的信息源中寻求对应的可信度;②新用户或者新项目的推荐,为一个新用户找到最近邻居是非常困难的,DISCF算法对新用户的推荐只能借助专家用户组的推荐建议。同样,在一个项目的初始状态下,找到与之关联的用户也变得很困难,对新项目的推荐,也需要求助专家信息源的推荐建议。
2.3 DISCF算法实现过程


3 DISCF算法试验设计与结果分析
3.1 DISCF算法的试验设计与数据准备
为了评价DISCF算法的性能,设计其与3个系统 进行 比较:① SCF (Similarity-based CF)——基于单信息源相似用户系统;②ECF(Expertise-based CF)——基于单信息源专家用户系统;③ HCF(Hybrid CF with similarity weighting and expertise eighting)——具有权重的相似用户和专家用户的混合推荐系统。
本文采用MovieLens工作组提供的用户对电影评价的数据集,随机截取100个用户对900部电影评分数据,整个实验数据集按0.8的比率进一步划分为训练集和测试集,即在整个数据集中,训练集占 80%,测试集占 20%。评价值为1~5的整数,数值越高表明用户对该电影的偏爱程度越高。
采用在评价推荐系统推荐质量中被广泛应用的MAE做为评价指标,它是系统预测的评分与真实评分的平均值,其计算公式为:
其中,N为所有用户评分的总和;pij为用户i对项目j的预测评分;rij为用户i对项目j的真实评分。MAE值越小,说明推荐系统的预测效果越好。
3.2 DISCF算法的试验结果及分析
实验结果,见表1所列。
表1 DISCF系统与3种典型的协同过滤算法推荐性能比较
本文提出的DISCF算法系统的MAE值,分别比SCF、ECF和 HCF系统低 4.5%、8.7%和5.8%,虽然数值不是很高,但体现了DISCF算法系统预测效果的优越性,随着预测项目交互性和数据稀疏性的增加,DISCF算法系统的优势会越来越明显。而且在预测的覆盖率方面,DISCF算法系统比 SCF系统高9.3%,比 HCF系统高2.9%。
4 结束语
本文提出的基于双信息源模式的协同过滤算法(DISCF),旨在解决数据稀疏性、针对具有专门知识背景和交互性强的项目推荐。实验结果表明,DISCF算法系统的MAE值和预测的覆盖率方面比传统的协同过滤算法优越。下一步的工作是将如何提高推荐项目的交互性,对推荐算法进行改进,提高系统的推荐效率。
[1] Sarwar B.Analy sis of recommendation alg orithms for ecommerce[C]//Proc 2nd ACM Conf Electronic Commerce(EC 00).ACM Press,2000:158—167.
[2] Adomavicius G,Tuzhilin A.Toward the next generation of recommender sy stems:a survey of the state-of-the-Art and possible extensions[J].IEEE Trans Knowledge and Data Eng,2005,17(6):734—749.
[3] G reiner R,Su X,Shen B,et al.Structural extension to logistic regression:discriminative parameter learning of belief netclassifiers[J].Machine Learning,2005,59(3):297-322.
[4] M elville P,Mooney R J,Nagarajan R.Content-boosted collaborative filtering for improved recommendations[C]//Proceeding s of the 18th National Conference of Artificial Intelligence,2002:187-192.
[5] Duhan D F.Influences on consumer use of word-of-mouth recommendation sources[J].J Academy of Marketing Science,1997,25:283—295.
[6] Herlocker J L,Konstan J A,T erveen L G,et al.Evaluating collaborative filtering recommender systems[J].ACM Trans Information Systems,2004,22(1):5—53.
[7] Robertson T S,Zielinski J,Ward S.Consumer behavior[M].New York:Scott,Foresman and Co,1984:5-50.
[8] Donovan J O,Smy th B.T rust in recommender sy stems[C]//Proc 10th Int Conf Intelligent User Interfaces(IUI 05).New York:ACM Press,2005:167—174.
