决策树算法分析及其在实际应用中的改进
2010-10-12张林张昊
张林 张昊
(1.安徽三联学院,安徽合肥230601;2.铜陵学院,安徽铜陵244000)
决策树算法分析及其在实际应用中的改进
张林1张昊2
(1.安徽三联学院,安徽合肥230601;2.铜陵学院,安徽铜陵244000)
决策树算法是数据挖掘常用算法之一,属于归纳学习方法的一种。它以样本为基础,主要用于分类和预测,其结果比较容易转换为分类规则。ID3算法是一种以贪心算法为核心的典型的归纳学习算法,它采用自顶向下的递归方式生成一棵决策树。ID3算法中使用的数据是理想情况下的数据,在实际应用中,数据在大多数情况下是不能满足算法在理想情况下要求条件,因而也就不能直接使用决策树算法进行分类。所以,在实际应用决策树算法之前,还需要先对数据进行一些处理或改进。
决策树;ID3;算法
1. 引言
决策树算法是数据挖掘常用算法之一,属于归纳学习方法的一种。它以样本为基础,主要用于分类和预测,其结果比较容易转换为分类规则。
决策树是一种类似于流程图的树型结构,树的内部节点为属性或属性集合,树的分枝为对属性值的判断,而树叶节点则表示样本所属类或类的分布,即结论。
决策树算法属于贪心算法的一种,通常采用自顶向下的递归方式来构造一棵决策树。在学习过程中只要样本能够用“属性——值”的方式来表示即可使用该算法,而无需用户了解更多的背景知识。
2. 算法的描述
建立决策树的算法有很多,每种算法都有自己的优势和不足,本文主要介绍经典的由J.R.Quinlan于1986年提出的ID3算法。
ID3算法是一种以贪心算法为核心的典型的归纳学习算法,它采用自顶向下的递归方式生成一棵决策树[1][5],其挖掘模型如图1所示:
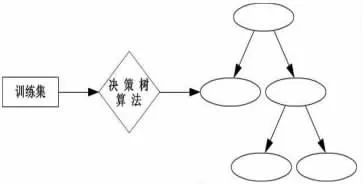
图1 决策树算法挖掘模型
2.1 主算法描述
(1)从训练集中随机选择一个既含正例又含反例的子集。
(2)用下述“建树算法”对当前子集构造一棵决策树。
(3)用训练集中子集以外的例子对所得到的决策树进行判定,找出判断错误的例子。
(4)若存在判断错误的例子则将该例子插入到子集中并转到(1)继续执行,否则程序结束。
2.2 建树算法描述
(1)对于当前例子集合,计算各属性特征的互信息。
(2)选择互信息最大的属性特征Ak。
(3)把在Ak处取值相同的例子归于同一子集。
(4)对既含正例又含反例的子集递归调用建树算法,而对仅含正例或反例的子集则返回调用处。
3. 决策树算法的优缺点
3.1 优点
决策树算法具有以下一些优点
(1)能够生成可理解的规则。
决策树是以树型结构表示最终分类结果的,是一种比较接近于人们对现实世界事务认知的表示方式[2][3]。因此,决策树算法的可解释性和所生成的可理解的规则就显得非常重要了。
(2)计算量相对于其它算法来说是比较小的。
在系统开发的过程中,工作效率通常是比较重要的。决策树算法的计算量相对其它算法来说不是很大,这可以在很大程度上缩短计算时间,提高系统的执行效率。
(3)运算速度相对来说比较快。
在计算量相对较小的情况下,比较容易转化成分类规则。只要沿着树根向下一直走到树叶,沿途的分裂条件就能够唯一确定一条分类的谓词。
(4)准确性相对较高,可以较为清晰的显示出属性的重要程度。
信息熵是描述属性重要程度的度量标识,而决策树正是通过计算信息熵来选择分裂属性的[4]。因此,通过决策树,用户可以很清晰地了解哪些字段比较重要。而系统开发者在进行系统开发的过程中,也可利用决策树算法挖掘出准确性较高且易于理解的分类规则。
3.2 缺点
决策树算法虽是一个很有实用价值的较为简单的示例学习算法,但也存在着一些缺点:
(1)决策树算法往往偏向于选择取值较多的属性为分支点,而取值较多的属性在很多情况下却未必是最优的属性,因此,即使按照熵值最小的原则进行属性划分,在实际情况中,应该首先判断的属性却未必那么重要。
(2)决策树算法是一种单变元算法,即每个节点仅含一个属性,各属性间的关联性不够紧密。
(3)决策树算法对噪声比较敏感,且不易去除,这容易使得特征的取值或分类出错。
(4)决策树算法在建树过程中比较依赖于训练集,当训练集改变时,各特征的互信息会随训练集中例子数量的改变而改变,从而导致决策树也随之变化,这不利于变化的数据集的学习。
4. 算法在实际应用中的改进
ID3算法中使用的数据是理想情况下的数据,在实际应用中,数据在大多数情况下是不能满足算法在理想情况下要求的条件的,因而也就不能直接使用决策树算法进行分类。所以,在实际应用决策树算法之前,还需要先对数据进行一些处理或改进。
4.1 算法的改进
(1)对定量属性的处理
在实际应用中,数据的属性除了有定性属性(即离散型属性)之外,还有大量的定量属性(即连续型属性)。ID3算法对所处理的属性,要求的是定性属性。因此,为了处理定量属性,就要求对算法进行扩展,使之能够处理连续型的定量属性。
事实上,ID3算法的提出者J.R.Quinlan于1993年又提出了ID3算法的改进版本——C4.5算法,该算法不仅继承了ID3算法的全部优点,还增加了对连续属性离散化等功能。
(2)缺失值情况的处理
在建立决策树的过程中,训练样本中经常会出现某些属性有缺失值的情况。对于这种情况一般有两种解决方法:一种方法是将缺失值看作属性的某种可能取值,另一种方法则是将有缺失值的实例全部忽略掉。若在某种程度上属性的缺失值情况明显的话,一般采用第一种方法,而如果缺失值的属性在决策中未发挥作用或作用不显著的话,则通常采用第二种方法。
(3)树的剪枝
决策树的剪枝问题是决策树技术中的一个重要部分。在决策树创建过程中,由于受到训练样本数、数据的噪音和孤立点等方面的影响,很多分支反映的是训练数据中的异常现象,一般性差,甚至可能出现荒谬的结论。为了解决这种过度拟合(Overfitting,即推出过多与训练数据集相一致的假设,因而不具有很好的预测性能)问题,我们需要对决策树进行必要的剪枝。
常用的树剪枝技术有先剪枝(pre-pruning)和后剪枝(post-pruning)两种。先剪枝也称为前剪枝或预剪枝,是一种限制决策树过度生长的技术,而后剪枝则是等决策树生成后再进行剪枝的一种剪枝技术。
(4)从决策树中提取分类规则
决策树的规则是以IF-THEN的形式表示的,从决策树中提取分类规则可分为两个步骤——获得简单规则和获得精简规则[5]。
(5)计算的简化
在利用决策树算法进行分类的过程中,我们需要计算各属性的互信息,并选择互信息最大的属性作为分支点。互信息I(U,V)=H(U)-H(U|V)。因为对于每个分支点来说信息熵H(U)是相同的,所以要求互信息最大的属性即求条件熵H(U|V)最小的属性。
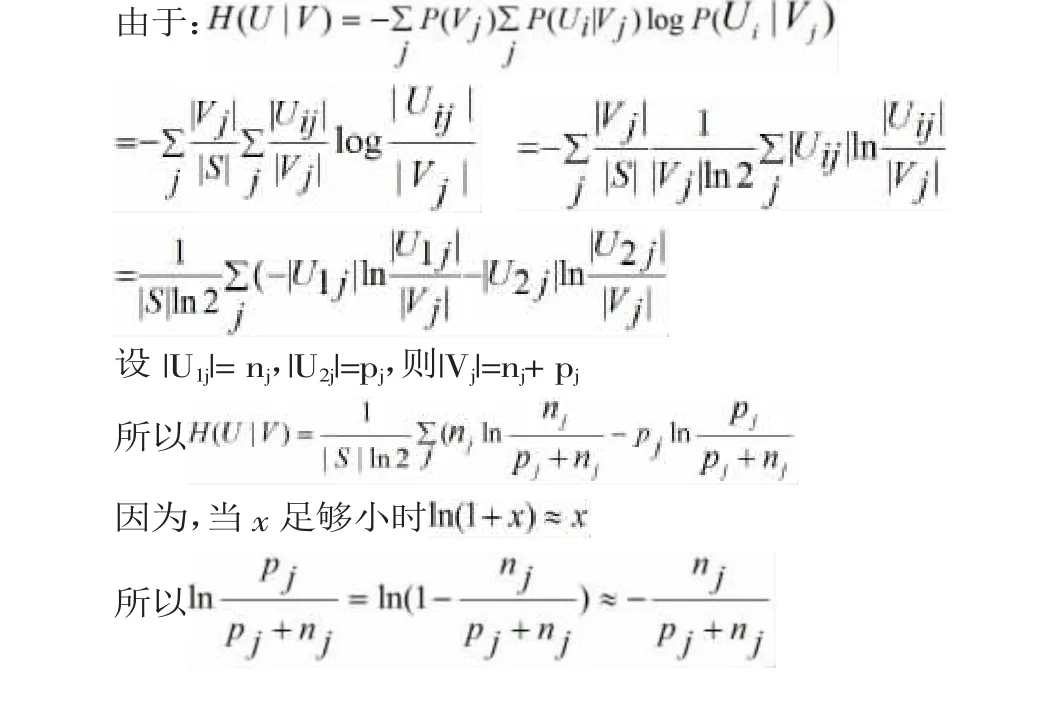


4.2 伪代码

5. 结束语
数据挖掘技术在信息社会中的地位已越来越重要,决策树算法作为分类数据挖掘中的重要方法,在未来的研究中将得到进一步的完善和发展。事实上,就决策树算法本身而言,还有很多问题亟待解决。例如:测试属性选择标准、数据预处理、决策树剪枝和应用领域的扩展等,都是值得研究的课题。
[1]谢印宝,宋道金.知识发现过程中数据采掘的方法和应用[J].青岛化工学院学报,2000,(3).
[2]孙艳.决策树挖掘算法在教评体系中的应用研究[J].廊坊师范学院学报(自然科学版),2009,(1).
[3]肖志明.决策树算法在高校教学评价中的应用研究[J].广西轻工业,2008,(2).
[4]徐小云,岳志强.数据挖掘中算法概述[J].科技信息,2008,(21).
[5]安淑芝.数据仓库与数据挖掘[M].北京:清华大学出版社,2005.
TP311.13
A
1672-0547(2010)06-0071-02
2010-10-16
张林(1981-),女,江苏南京人,安徽三联学院计算机系讲师,研究方向:数据挖掘,数据结构。
