基于数据挖掘的首批创业板上市公司财务分析
2010-10-09魏乐
魏乐
(赤峰学院 经济与管理学院,内蒙古 赤峰 024000)
基于数据挖掘的首批创业板上市公司财务分析
魏乐
(赤峰学院 经济与管理学院,内蒙古 赤峰 024000)
本文利用数据挖掘技术中的聚类分析方法,对创业板首批上市的28家公司进行财务分析,将其分类,为投资者提供有价值的决策依据.
数据挖掘;聚类分析;创业板上市公司;财务分析
2009年10月23日创业板开板仪式后,首批28家创业板公司已于10月30日集中在深交所挂牌上市.这意味着备受市场关注的创业板市场正式开市交易.所以,此时研究创业板公司的财务状况具有十分重要的现实意义.
1 创业板的概念及特点
创业板又称二板市场,是指主板之外的专为暂时无法上市的中小企业和新兴公司提供融资途径和成长空间的证券交易市场,是对主板市场的有效补充,在资本市场中占据着重要的位置.创业板市场的的主要目的是扶持中小企业,尤其是高成长性企业,为风险投资和创投企业建立正常的退出机制,为自主创新国家战略提供融资平台,为多层次的资本市场体系建设添砖加瓦.因此,在创业板市场上市的公司大多从事高科技业务,具有较高的成长性,经营机制更为灵活,经营模式和盈利模式多元化特征更为突出.同时,此类公司往往成立时间较短,股本规模小,经营不确定性大,抵御外部风险能力较弱,公司治理基础相对薄弱.故对投资者来说,投资创业板市场的风险要比主板市场高得多,得到更大收益的可能性也较高.
2 首批创业板上市公司财务分析的特点
创业板上市公司的发展受到内外部诸多因素的影响,致使得其财务分析工作面临很多新的课题和挑战.所以,对创业板企业的财务分析要特别注意与传统企业财务分析在以下几个方面的区别:[1](1)财务分析指标体系需要准确、全面把握创新型企业高投入、高风险、高收益的特点;(2)创业板企业的技术、市场环境可以说是千差万别和瞬息万变,而传统的综合评价的方法如模糊综合评判法、人工神经网络、灰色系统评价法以及数据包络分析法(D E A)等.由于存在较大的缺陷,如指标变量之间的相关性复杂、指标层次较多等,故造成评价成本过高以及适用性差.[2](3)高科技企业的发展历史相对较短,往往缺乏历史数据,并且技术千差万别,很难找到行业、技术、规模等相近的可比企业,使得对业绩的预测和推断相对困难,对于本文研究对象——创业板首批上市的28家公司更是如此,上市时间较短,公开数据较少.(4)高科技企业的非线性发展规律,意味着很难根据企业现在的盈利来计算盈利增长率,如果仅仅使用传统的市盈率估值方法显然是远远不够的.基于上述原因,本文决定采用数据挖掘技术对创业板首批上市的28家公司进行财务分析.数据挖掘是从“海量”数据中获取有效的、新颖的、潜在有用的、最终可理解的模式的过程.诚然,大多数公司的财务分析所需要的一些数据相对有限,尚不能称得上“海量”,但是如果能从另一个角度去换位思考,或许能得到意想不到的效果,为更深层次的财务分析做准备.[3]
3 创业板上市公司聚类分析研究
3.1 确定挖掘对象
财务分析为企业的投资者、债权人、经营者及其他利益相关者了解企业过去、评价企业现状、预测企业未来,做出正确决策提供准确的信息或依据.财务状况是指一定时期的企业经营活动体现在财务上的资金筹集与资金运用状况,它是企业一定期间内经济活动过程及其结果的综合反映.本文选取了创业板首批上市的28家公司进行分析:特锐德(300001)、神州泰岳(300002)、乐普医疗(300003)等,分别用X1,X2,X3,…X28,表示.可以预测大部分公司将归为一类,少部分公司归为一类,即业绩表现优良或是较差.再利用辅助指标进行判断.
3.2 数据准备
3.2.1 数据选取
以2009年9月30日为时点,选取创业板首批上市的28家公司以下7个关键财务指标数据:流动资产合计、总资产合计、流动负债合计、长期负债合计、资本公积、盈余公积、未分配利润,分别用L1,L2,L3,…L7,表示(见表1).
3.2.2 数据处理
数据预处理是数据分析过程中不可缺少的一个关键环节,它服务于数据分析和建模.数据预处理需要解决的问题有很多,例如,缺省值和异常数据的处理,数据的转换处理、数据抽样和选取变量.[3]本文利用最小—最大规范化方法对数据进行标准化处理,设minL和m a xL分别为属性L的最小值和最大值,则利用公式L'=(L-minL)/(m a xL-minL),对原样本进行标准化处理,将7个关键财务指标数按比例缩放,使之落入到一个小的特定区间(0~1),从而实现数据的预处理.
3.3 利用数据挖掘软件SPSS进行聚类分析
将表1数据输入到SPSS软件编辑窗口,点击“Analyze→Classify→HierarchicalCluster”选择层次聚类.本文采用最小距离方法,具体操作时选择,“Nearestneighbor”即最短距离法,得到相异度矩阵,见表2(截取部分数据).
表3反映了聚类分析的凝聚过程.

表1 28家创业板上市公司财务数据
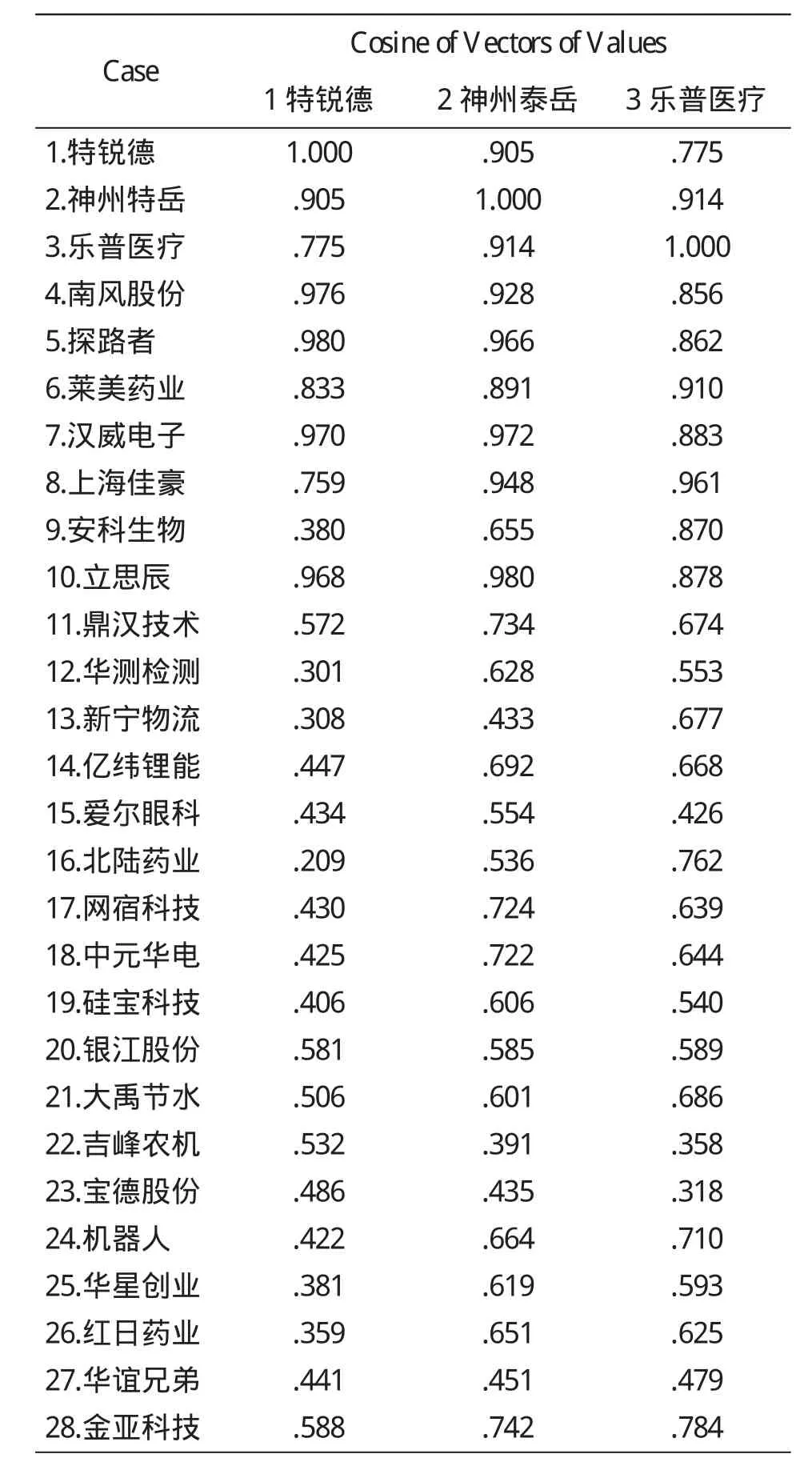
表2 相异度矩阵(部分)
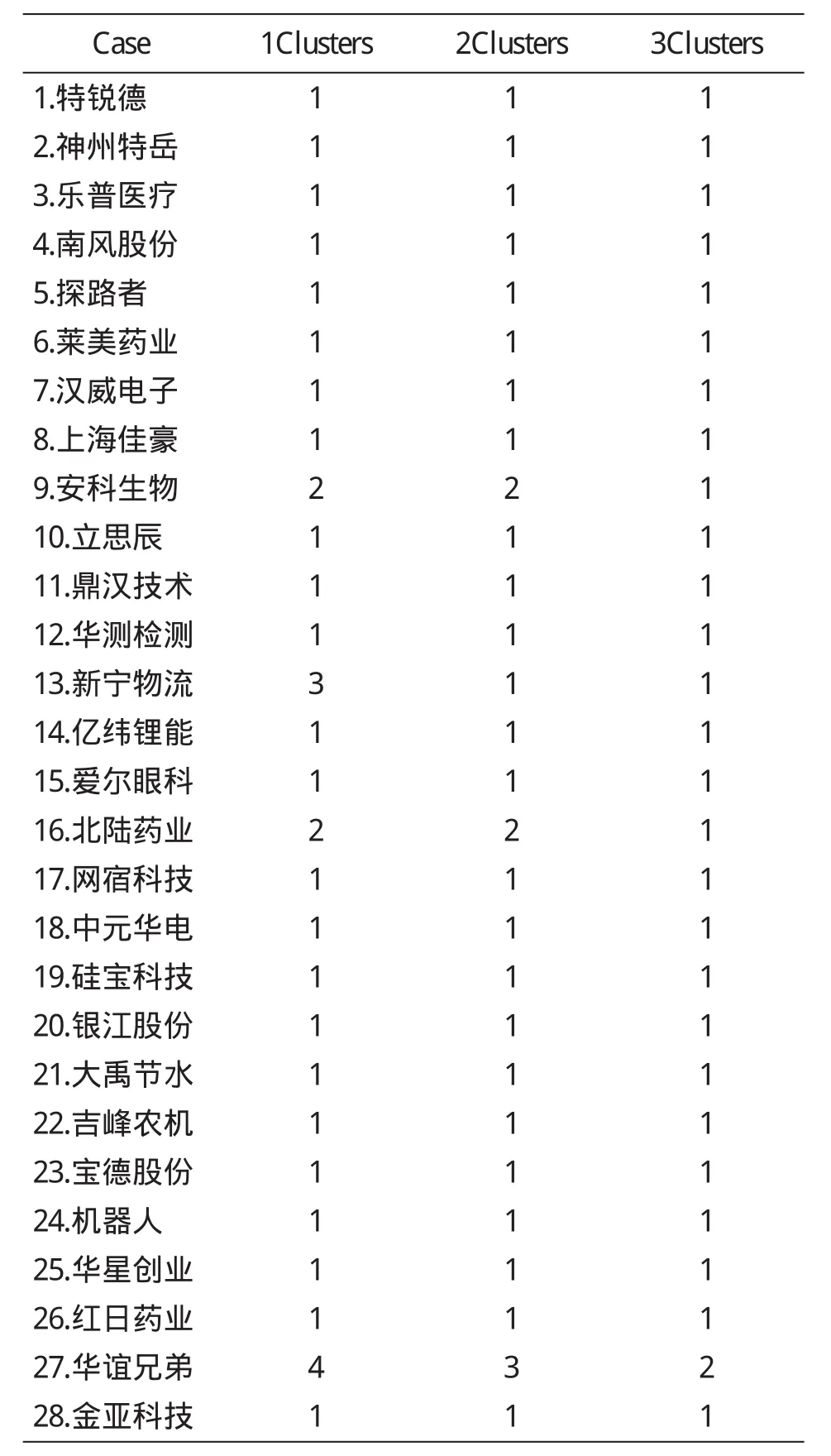
表4 聚类结果的类成员表
第一列表示聚类分析的步骤,在本次分析中共进行了27次.第二列和第三列表示哪两个样本聚成了一类.第四列表示两个样本的相似系数.第五列表示两个参与聚类的是样本还是类,0表示样本,非0数字N表示第N步产生的聚类参与本步聚类.第七列表示本步骤聚类结果将在以后的第几步中用到.
第一列表示表示7和10两个样本最先进行了聚类,样本间相似系数为0.997,本次聚类结果将在以后的第二步中用到;以此类推,将28个样本全部聚类.
表4是最终聚类结果的类成员表,在利用SPSS分析过程中,本文设置分为2~4类,从而输出了划分2~4类时每个样本属于每一类的结果.

表3 凝聚顺序表
4 结论
聚类分析事前并没有制定分类的标准。本文划分为两类的时候,只有华谊兄弟和其他不同类,通过传统的财务分析发现,其总资产增长率、总资产报酬率、流动比率和速动比率均呈逐年平稳递增的趋势,而净资产报酬率和每股收益呈下降趋势。当划分为三类时,安科生物和北陆药业成为一类;华谊兄弟自成一类。安科生物和北陆药业同属制药行业,二者的流动比率和速动比率增长较快,总资产周转率呈下降趋势。当划分为四类时,安科生物和北陆药业成为一类;华谊兄弟自成一类;新宁物流自成一类,其总资产增长率呈下降趋势。聚类分析提供了一个可以横向比较同类上市公司的工具,投资者掌握这一技术,可以为投资决策提供更有价值的财务信息。
〔1〕证监会有关部门负责人就创业板上市公司监管答问.中国 网 ,http://www.china.com.cn/finance/txt/2009-10/ 27/content_18777271.htm.
〔2〕胡玉柱,等.基于主成分分析的高新技术企业业绩评价研究[J],财会通讯·学术,2008(7):62-65.
〔3〕赵磊.数据挖掘技术在财务分析中的应用[J].中国管理信息化,2009(1):34-38.
〔4〕薛薇.基于SPSS的数据分析[M].中国人民大学出版社,2006.
〔5〕赵选民,薛建楼.利用数据挖掘技术分析上市公司财务状况[J].中国管理信息化,2009(2):30-32.
F275
A
1673-260X(2010)08-0064-03
