基于粗糙集的CBR系统案例检索策略
2010-09-27孙岩清1尹树华林初善
孙岩清1,2,尹树华,林初善
(1.西安通信学院 研究生管理大队,西安 710106;2.中国酒泉卫星发射中心 指挥通信室,甘肃 酒泉 732750;3.西安通信学院 军用光纤通信教研室,西安 710106)
1 引 言
基于案例推理(Case-Based Reasoning, CBR)是通过回忆一个或几个过去发生的具体案例,进而采用类比的推理方法,提出解决新问题的方案,其一般过程为“检索-重用-修正-存储”,检索是其中的关键,直接决定了案例推理系统的性能。目前,研究较多的检索方法有决策树[1]、KNN[2-3]、神经网络[4-5]、支持向量机[6]等,但其每一种具体算法都有一定的局限性,不能够在CBR系统中得到很好的应用。其中,决策树法存在案例库改变时需要重新建树且存储、开销大的缺点;神经网络法存在案例属性较多时训练耗时,只能给出单个相似案例的缺点;KNN算法存在计算量大、效率不高和在案例较多时检索耗时的缺点;支持向量机则存在随着案例或案例属性增加而检索耗时、计算复杂的缺点。
因此,已有检索方法存在各自问题,不能很好地应用于实际的CBR系统,故本文提出基于粗糙集理论进行属性约简,删除案例冗余属性,完成案例库优化,再结合相似度计算方法和概率神经网络算法进行不同情况下的案例检索策略,做到既保证检索的精度,尽可能地检索出要求的所有相似案例,又避免检索时间随案例增加而线性增长。
2 粗糙集相关概念
2.1 属性重要度定义
定义1:设S=(U,A,V,f)为一个信息系统,A=C∪D,∀R⊆C,属性依赖度表示为r(R,D)=|PosR(D)|/|PosC(D)|,则∀c∈R的属性重要度可表示为依赖度的差值:
(1)
定义2:设S=(U,A,V,f)为一个信息系统,A=C∪D,∀R⊆C,且R在对象集合U上产生的划分为:U/R={X1,X2,…,Xn},则知识P的熵为
式中,p(Xi)=|Xi|/|U|。
则决策表中任一条件属性本身的重要度可以由它所引起的信息熵的变化来衡量,即已知属性集R⊆C,∀c∈C-R的重要度可定义为
SIG2(c,R,C)=H(R∪c)-H(R)
(2)
对于CBR系统,约简应既能很好地反映专家经验知识,又能生成正确的决策规则,因此,应该综合考虑属性决策分类和本身重要度两方面的因素。
定义3:对于决策信息系统S=(U,A,V,f),A=C∪D,n=U,属性c∈R⊆C在R中的重要度为
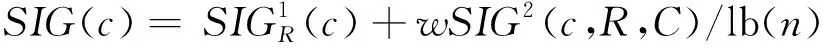
(3)
式中,0≤w≤1。当w=1时,同等考虑属性对决策分类的影响度和属性本身的重要度,最大化地反映领域专家的经验知识;当w=0时,仅考虑属性对决策分类的影响,而一般情况下,对于CBR系统采取前者的定义。
2.2 知识约简定义
定义4:设S=(U,A,V,f)为一个信息系统,A=C∪D,∀P⊆C,如果P满足下面两个条件,则P是一个Pawlak约简:
(1)PosP(D)=PosC(D);
(2)∀a∈P,PosP-{a}(D)≠PosC(D)。
上面定义中,第一个条件保证了相同决策规则的生成,第二个条件保证了约简的独立性。
3 相似案例检索思想
3.1 案例相似度定义及分析
设F为一案例库,且其中案例的属性均已进行归一化处理。
定义5:以dist(A,B)、sim(A,B)分别表示案例A、B之间的距离和相似度,则在最近邻实例检索中sim(A,B)=1-dist(A,B),那么,sim(A,B)应满足以下条件和性质:
(1)sim(A,B)∈[0,1],sim(A,B)=1,当且仅当A=B,即自反性;
(2)sim(A,B)=sim(B,A),即对称性;
(3)对任意的案例A,B,C⊂F,有sim(A,B)≥sim(A,C)+sim(B,C)-1,即满足三角不等式关系。
由定义5可知,采用最近邻进行检索案例的核心工作就是计算目标案例与待检案例之间的距离,而后选取距离最小者作为最相似案例。在实际应用中多采用欧几里得距离法,同时,为满足条件(1),对传统距离公式进行改进,对距离进行归一化处理,有:
(4)
式中,wi为案例的第i个属性权值,可以在属性约简的过程中获得,其值越大则表示该属性越重要;n为属性个数;A(i)、B(i)分别表示案例A、B的第i个属性值。
3.2 案例检索过程
图1为案例检索流程图。
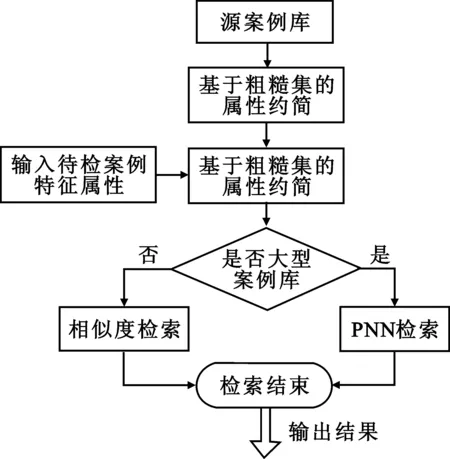
图1 案例检索流程图Fig.1 Case retrieval flowchart
利用粗糙集理论首先对案例库进行属性约简,并计算约简后的属性重要度权值,而后在小案例库时采取相似度计算方法检索案例,在大案例库时采用概率神经网络实现,从而充分利用相似度计算和神经网络的优点,取长补短,达到CBR系统案例检索的最优效果。
4 实验结果和分析
为验证文中检索策略的正确性,采用UCI数据集和人工数据集相结合的方法进行,仿真环境为Matlab R2006a,计算机配置为AMD Athlon 64位处理器,1G内存。其中,UCI数据集主要采用了Wine、Riply和Iris 3种,分别用于验证时间复杂度和检索精度,同时在小数据集下运用人工数据集对检索精度进行了验证。
4.1 案例检索时间复杂度验证
采用Wine数据集进行时间复杂度验证,它包括178个样本、13个条件属性和3个决策属性。实验以成倍增加案例的方式进行,任选其中的一个案例作为待检测样本,同时,为避免检索时间的随机性,降低仿真误差,采取每次检索仿真10次,取平均值作为最终检索时间的方法。仿真结果如图2所示。
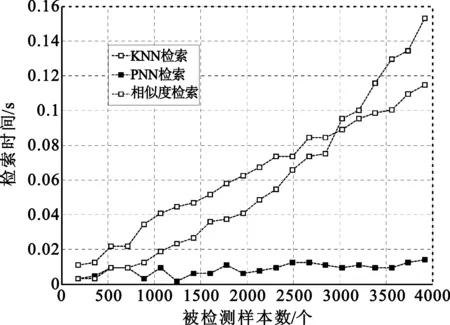
图2 3种检索方法的时间对比Fig.2 The time comparison of three retrieval methods
由图2可以看出,在小数据集时,3种检索算法耗时均很小,且相似度计算方法性能更优;而随着案例的增多,基于相似度计算和KNN算法的检索时间会线性增长,神经网络算法则在一定的时间点或范围内保持稳态。
4.2 案例检索精度验证
采用Riply数据集进行检索精度的验证,Riply数据集包括训练样本250个、检测样本1 000个、条件属性2个、决策属性2个。检索结果如表1所示,其中相似度检索选择了两种模式,即取一个相似案例和两个相似案例。

表1 3种算法检索结果对比Table 1 The retrieval result comparison of three algorithms
由表1可知,在只追求单个最相似案例的情况下,概率神经网络检索更加精确,K近邻次之,相似度检索算法较差。但前两种算法却不能够给出多个相似案例,存在局限;而相似度检索算法则能够给出多个相似案例,一般选择2个,在此情况下,相似度检索算法具有相当高的精度,优势比较突出。
4.3 基于粗糙集的案例检索验证及应用
由以上实验可以看出:在小数据集时,相似度计算检索既能保证检索精度,又能保证检索的时间复杂度;在大数据集时,神经网络算法则可以保证检索精度,且能够避免检索时间的线性增长。因此,文中提出的案例检索策略能够有效提高CBR系统的性能,适合于案例推理的实际应用,结合粗糙集理论则能够进一步优化检索的时间复杂度问题。
用Iris数据集进行实验,它包括150个案例样本、4个条件属性和3个决策属性,用其中90个样本进行训练,其余60个样本用于测试。运用Matlab对3种算法进行仿真,检索时间采取10次仿真的加权平均值,约简后训练数据集包含88个样本、3个条件属性,属性重要度值分别为1.071 1、0.755 7和1.602 1。检索结果如表2所示。
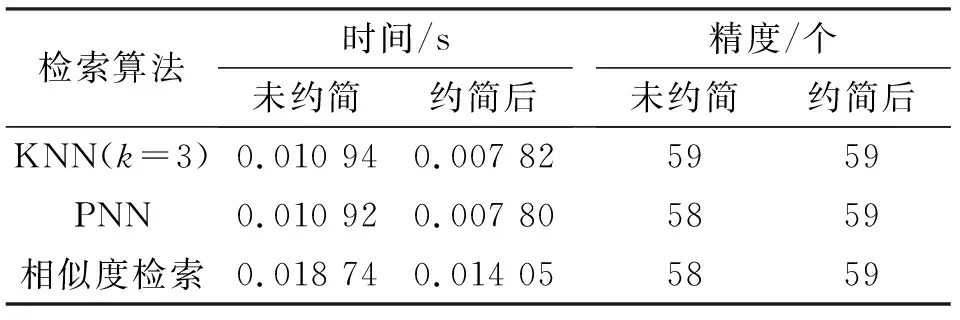
表2 约简前后的检索结果对比Table 2 The retrieval result comparison of before-and-after reduction
由表2可以看出,经过粗糙集约简后的案例检索算法,在案例检索效率和精度方面都有一定提高,尤其对于相似度检索方法,效果更加明显。由此可以看出,利用粗糙集方法对案例库优化能够有效提高案例推理系统的检索效率,从而能够提高CBR系统的整体性能。
将基于粗糙集的案例检索策略应用于数字数据网故障诊断系统中,收集了网络运行中出现的46个典型案例,包括9个条件属性和9个决策属性,限于篇幅,具体含义不作详述。其中38个案例用于训练、8个用于测试,分别如表3和表4所示。
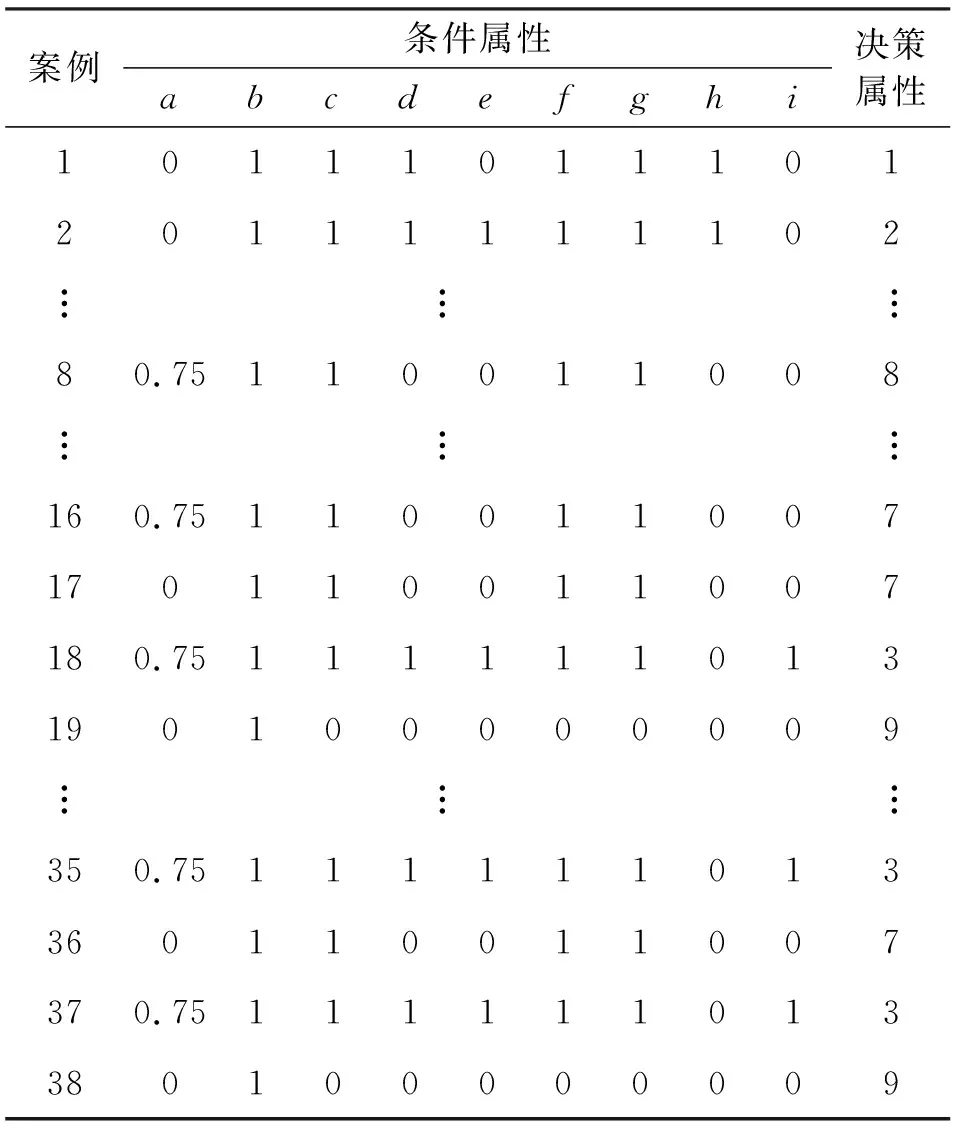
表3 训练案例表Table 3 The training case table
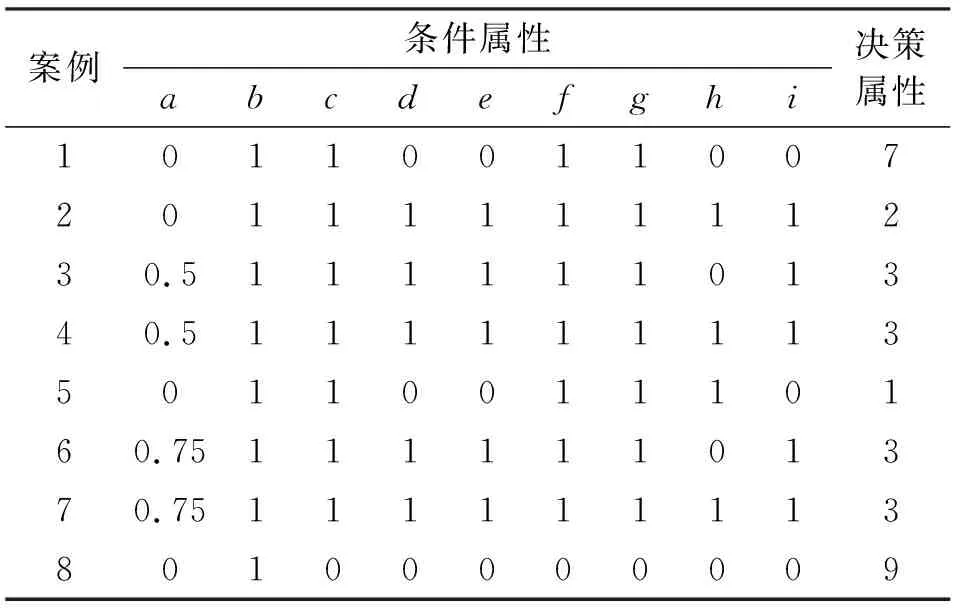
表4 测试案例表Table 4 The testing case table
显然,表3中案例8和案例16为噪声案例,案例36、37、38为冗余案例。运用粗糙集进行属性约简,得到约简后的决策表,即删除了相同冗余案例37、38,合并噪声案例8和16成一个新案例,约去了冗余属性c。
由于案例库较小,采用相似度检索算法实现。约简后各属性重要度如表5所示,可以看出属性“a”和“g”的重要度明显大于其它属性的重要度,而它们分别代表终端数据收发情况和信道连接情况,对于信道类故障,它们也正是故障案例的重要特征,是专家判断故障类型的主要依据。可见,基于粗糙集的属性重要度值能真实反映属性的重要程度及专家经验。

表5 基于粗糙集的属性重要度表
检索结果如表6所示,“/”两端分别表示基于粗糙集的属性重要度和默认属性重要度检索结果。当取相似案例数为1时,能够得到绝大部分待检案例的正确故障类别;当取相似案例数为2时,基于粗糙集重要度的相似度检索得到了所有正确类别,而基于一般默认属性重要度的相似度检索则仍不能涵盖所有的正确类别;当取数为3时,两种情况均涵盖了所有的正确类别。
因此,在实际应用中,相似度检索方法在案例库较小时能够尽可能地检索到所有相似案例,用于指导实际的故障诊断,而采用粗糙集重要度则能够进一步提高案例检索准确度,相对于一般默认属性重要度都为1的情况,案例的检索效率更高,也更有利于提高故障诊断的准确性。
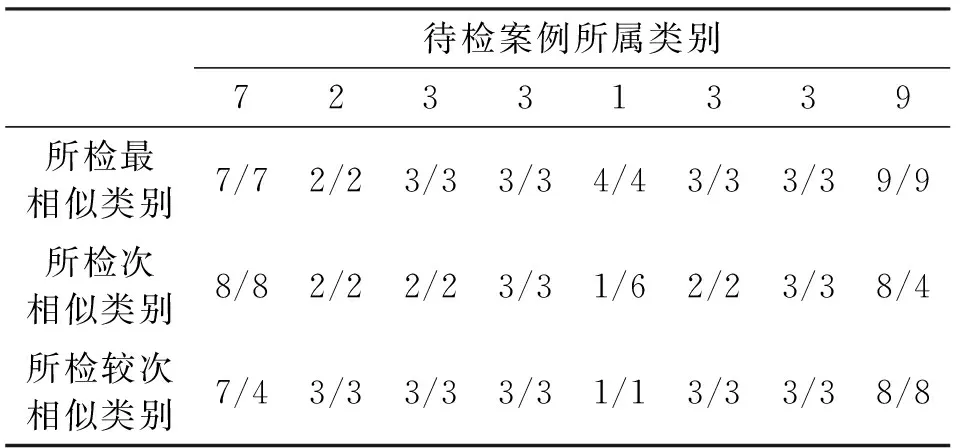
表6 粗糙集与默认属性重要度的相似度检索结果Table 6 The similarity retrieval result of rough set and default attribute significance
5 结 论
根据案例推理系统的实际,分析了反映专家经验的属性重要度,结合粗糙集理论,提出了不同案例库下的案例检索方法,十分适用于增长式的案例推理系统。与前人单纯检索策略相比,文中充分利用粗糙集理论、相似度计算和神经网络等方法的各自优点,保证了CBR系统案例检索的精度和时间效率。实验结果表明,检索策略能够有效避免神经网络方法小案例库的精度较低和大案例库时相似度计算及KNN算法检索时间线性增长的缺点,将其应用于数字数据网故障诊断中,可以显著提高案例检索的精度,降低检索时间。但此检索策略不适用于动态案例库的情况,这方面的工作需要进一步研究。
参考文献:
[1] 王波,宋东,姜华男.基于粗糙集的CBR故障诊断案例的检索方法研究[J].计算机测量与控制,2007,15(11):1430-1433.
WANG Bo,SONG Dong,JIANG Hua-nan.Case Retrieve of Fault Diagnosis Expert System Based on CBR[J].Computer Measurement & Control,2007,15(11):1430-1433.(in Chinese)
[2] LI Yan,Simon C K Shiu,Sankar K Pal.Combining Feature Reduction and Case Selection in Building CBR Classifiers[J].IEEE Transactions on Knowledge and data Engineering,2006,18(3):415-429.
[3] 蒋占四,陈立平,罗年猛.最近邻实例检索相似度分析[J].计算机集成制造系统,2007,13(6):1165-1168.
JIANG Zhan-si,CHEN Li-ping,LUO Nian-meng.Similarity analysis in nearest-neighbor case retrieval[J].Computer Integrated Manufacturing Systms,2007,13(6):1165-1168.(in Chinese)
[4] Piliouras N,Kalatzis I,Theocharakis P.Development of the probabilistic neural network-cubic least squares mapping classifier to assess carotid plaques risk[J].Pattern Recognition Letters,2004,25(2):249-258.
[5] WU Jian-da,CHIANG Peng-hsin,CHANG Yo-wei.An expert system for fault diagnosis in internal combustion engines using probability neural network[J].Expert Systems with Applications,2008,34(4):2704-2713.
[6] 刘江永,王大明.基于支持向量机的快速高光谱分类研究[J].陕西师范大学学报(自然科学版),2009,37(4):43-47.
LIU Jiang-yong, WANG Da-ming.Fast classification of hyperspectral data based on support vector machines[J].Journal of Shaanxi Normal University(Natural Science Edition),2009,37(4):43-47.(in Chinese)
