认知无线Mesh网络自适应多路径算法*
2010-09-26章国安丁晨莉包志华
章国安,2,丁晨莉,包志华
(1.南通大学 电子信息学院,江苏 南通 226019;2.东南大学 移动通信国家重点实验室,南京 210096)
1 引 言
认知无线Mesh网络(Cognitive Wireless Mesh Networks, CogWMN)是一种利用 认知无线电(Cognitive Radio,CR)技术的无线Mesh网络,配有CR模块的CMesh(Cognitive Mesh)节点能够感知主系统的空闲频谱、动态接入空闲频谱。CogWMN是一种结合CR与WMN新型的网络形式[1-2]。
在认知无线Mesh网络环境下,即使寻找到最优的一条路径传输业务数据流,也仍然会因避让首要用户使用授权信道而暂时中断业务流的传输,导致数据流延时。利用多路径传输,即使其中一条路径被破坏,其它路径节点也可以继续传输数据包,减少数据包延时,保障服务质量。文献[3]指出相比无认知环境的网络,在认知环境下,网络内多路径传输的延时、平均丢包率、平均队列时间均有所下降。
近年来,强化学习被应用在无线网络内。多agent系统可用来很自然地模拟与抽象现实中分布、动态、开放、复杂的问题[4],在认知环境下,多agent强化学习能够帮助节点感知更多的频谱或者进行有效的功率控制[5-6]。为了减小变化的频谱空穴给路径传输带来的负面影响,使网络节点能够自适应选择较优路径传输数据,本文提出了基于多agent强化学习的多路径自适应路由(Multi-Path Q Reinforcement Learning Algorithm,MPQRLA),能够适应认知无线Mesh网络动态变化的环境。
2 基于多agent的自适应多路径算法
2.1 多agent的强化学习模型
如图1所示,配有认知无线电模块的CMesh节点根据认知环境感知信道和估计其周围首要用户的功率、距离等,进入初始状态,经过一系列中间状态及其行动选择,达到较理想的状态,即传输业务流状态。CMesh节点通过求解策略π、感知突发环境的变化以及回报结果选择路径,估计下一个传输状态。然后通过动作选择器,向下一跳邻节点发送数据包、计算链路拥塞指数等参数,判断满意度是否满足目标阈值,决定是否继续该路径的使用。当节点进行数据业务传输时,计算满意度,对放弃该路径、改变路径或者切换信道等作出抉择。
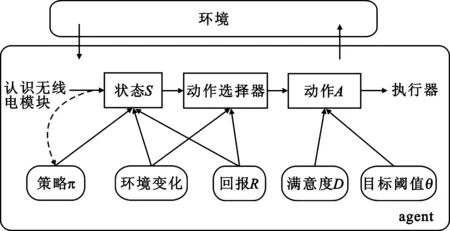
图1 多agent强化学习模型
2.2 基于Markov的多agent强化学习模型
定义七元组{N,S,A,T,R,D,θ}为基于Markov模型的多agent的强化学习模型[7],其中N表示n个agent集合,这些agent在网络内对应网络节点,包含CMesh节点和接入节点AP;S=(S1,S2,S3,…,Sn)表示n个agent离散状态有限集合;A=(A1,A2,A3,…,An) 表示n个agent行动集合;T:S×A×S→[0,1]表示状态转移;R=(R1,R2,R3,…,Rn)表示n个agent各自的回报函数;D表示学习满意度;θ表示目标阈值,如果满足D>θ,则在p概率下迁移到符合要求的状态。
2.3 Q值函数的描述

Q值函数最优值的计算:
(1)
路由f上Q总值计算:
(2)
路由f上Q总值更新值的计算:
Qf(s,a)=(1-α)Qf(s,a)+
α[R+γminQf(s′,a′)]
(3)
当频谱空穴改变,需要更换路径或者更换信道时,需要预估新的状态s′和动作a′。策略π是从Q总值中找到的,该策略旨在f所找到路由中有一条Q值最优的路径,定义为
π=minQf(s,a)
(4)
回报函数R定义为公式(5),表示预算数据流经过节点i到j的丢包、延时等,ploss,j以及pdelay,j为丢包和延时的惩罚因子,0 (5) 为了将S状态更明确,我们将S扩展得到: St,i={It,i,Pt,i,Ct,i,ch} (6) 式中,It,i表示SINR是否大于信干比的门限,取值为0或1;Pt,i表示功率水平,确保在限制的功率内,不会对周围首要用户造成干扰;Ct,i,ch表示信道ch的信道拥塞指数,指示是否接受邻节点的连接要求。 预算满意度D的计算公式: (7) 式中,BWf代表要求的网络带宽,bwf代表实际传输的带宽。满意度不满足阈值时,将可能放弃该路径。 实际满意度D的计算公式如下: (8) 式中,THRf代表要求的吞吐量,thrf代表实际传输的吞吐量。满意度小于其阈值时,将更换路径或信道。 多agent强化学习的目标是使节点能计算出最佳路径,源节点计算出最佳路径后,只有一条路径传输数据。为了能实现多路径的传输,这里设定, 源节点经过T时间,依据环境变化等因素,计算第二条最佳路径,两条路径同时传输,达到负载平衡的目的。假若其中任意一条路径因满意度下降到阈值后或因其它因素,放弃该路径,仍然有一条路径继续传输数据,这样延时波动不会较大。源节点经过T时间,计算第二条最佳路径,此路径为除正使用路径外的最佳路径,恢复两条路径同时传输数据。多路径的调度策略可使源节点到目的节点总有一条路径在传输,并且可能是暂时的最优路径在传输,保证服务质量。多路径策略框图如图2所示。 图2 多路径策略流程图 Q值函数路由表是一张二维表格,表示节点i到节点j的单跳最优Q值,通过Q值路由表可计算出路由f上Q总值以及路由f上Q总值的更新值。 如图3(a)所示,网络内5个CMesh节点,其中节点4~5有两个可用信道1和5,根据公式(1)和(2)分别计算单跳节点Q值和总Q值,由于Q值路由表记录的第4行第5列格子中是5号信道的Q值2,因此节点4~5的5号信道Q值最小。根据公式(4)的策略π,得到路径1-3-4-5为最佳路径。 (a)简单网络模型 (b)Q值路由表 当该路径中的节点3~4可用信道变化时,如图4(a)所示。设定折扣因子和学习速率为0.2和0.5,由公式(3)和公式(5),可得更新后的最佳路径为1-2-4-5,如图4(b)所示。 (a)变化后的网络模型 (b)更新后的Q值路由表 多agent强化学习的目标是使节点能计算出最佳路径,当网络内节点感知空闲的可用信道后,进入最佳路径的选择阶段,其算法如下: (1)初始化节点S和A; (2)通过公用控制信道,当相邻节点可用信道交集非空时,计算所有路径f,以及ξ(f)和N(i); (3)根据公式(1)和(2),分别计算单跳节点最优Q值,得到Q值路由表,计算路径总Q值; (4)根据公式(4),获得最优路径传输业务,转入多路径的调度策略; (5)当频谱空穴变化后需要变更信道时,观察回报值R,更新单跳Q值,转入步骤6;当放弃路径或者重新选择路径时,转入步骤1; (6)根据公式(7),预算变更信道的满意度D,选择D>θ的新状态s′和动作a′; (7)存储Q值和更新Q值总值,根据策略π,更新最佳路径; (8)根据公式(8),当正在使用的路径满意度下降到θ以下后,放弃该路径并更改路径,转入步骤5。 本文使用Matlab语言仿真基于多agent强化学习多路径CogWMN自适应路由算法性能。网络内有40个CMesh节点,随机分布在500 m×500 m的范围内,仿真时间为1 000 s。假设首要用户工作在712~757 MHz的频段内,每信道带宽为5 MHz,共有10个信道。丢包和延时的惩罚因子都为0.5,折扣因子为0.2,学习率为0.85,满意度阈值为0.8。在CogWMN内,更换路径的主要原因之一是因可用信道变化使传输路径暂时不可用,导致CMesh节点退避延时。将本文提出的自适应多路径算法与随机(Random)路由与信道分配算法和Dijkstra最短路径(Shortest Path,SP)算法分别应用于AODV路由协议,并比较三者之间的满意度、平均端到端延时、丢包率以及分组成功投递率。 图5所示为满意度对比,由于预设的目标阈值是0.8,所以MPQRLA的满意度一直都在0.8以上,而对比的两种算法满意度不如MPQRLA。 图5 满意度 图6所示是平均端到端延时对比,从图中看出MPQRLA的延时比SP和random小,这是因为计算Q值函数时考虑了数据包在邻节点间来回所需的时间。 图6 平均端到端延时 图7所示为丢包率的对比,由于MPQRLA采用了多路径的调度策略,任意一条路径因满意度下降到阈值后或因其它因素,放弃该路径,仍然有一条路径继续传输数据,这样丢包情况有所控制。 图7 丢包率 图8所示是网络节点的分组成功投递率,从图中看出,MPQRLA的成功率较高。 图8 分组成功投递率 在认知无线Mesh网络环境下,即使寻找到最优单路径传输数据流,也仍然会因避让首要用户使用主信道而暂时中断数据流的传输。本文提出的多agent自适应多路径算法,节点感知环境后进入初始状态,通过Q-学习算法更新Q值路由表学习最佳路径,并结合多路径调度策略实现多路径传输。当频谱空穴变化后需要更换路径时,通过观察回报值、计算满意度等,自适应学习恢复多路径传输,保障服务质量。仿真结果表明,该算法能够提高网络性能,在满意度、平均端到端延时、丢包率以及分组成功投递率上都有较好的表现。 参考文献: [1] 丁晨莉,章国安,包志华.基于模糊推理的认知无线Mesh网络路由算法[J].电讯技术,2009,49(11):35-39. DING Chen-li,ZHANG Guo-an,BAO Zhi-hua.A CogWMN Routing Algorithm Based on Fuzzy Petri Net [J].Telecommunication Engineering,2009,49(11):35-39.(in Chinese) [2] Chen T, Zhang H, Matinmikko M, et al. CogMesh: Cognitive Wireless Mesh Networks[C]// Proceedings of IEEE Global Telecommunications Conference. New Orleans, LA:IEEE,2008:1-6. [3] Javadi F, Jamalipour A. Multi-Path Routing for a Cognitive Wireless Mesh Network[C]//Proceedings of International Conference on Radio and Wireless Symposium. New Orleans, LA:IEEE,2009:232-235. [4] 陈宗海,杨志华,王海波,等.从知识的表达和运用综述强化学习研究[J].控制与决策,2008,23(9):961-975. CHEN Zong-hai, YANG Zhi-hua, WANG Hai-bo,et al. Overview of reinforcement learning from knowledge expression and handling[J]. Control and Decision, 2008, 23(9):961-975.(in Chinese) [5] Xia B, Wahab M H, Yang Y, et al. Reinforcement Learning Based Spectrum-aware Routing in Multi-hop Cognitive Radio Networks[C]// Proceedings of the 4th International Conference on Cognitive Radio Oriented Wireless Networks and Communications. Hannover:IEEE, 2009:1-5. [6] Serrano A G, Giupponi L. Aggregated Interference Control for Cognitive Radio Networks Based on Multi-agent Learning[C]//Proceedings of the 4th International Conference on Cognitive Radio Oriented Wireless Networks and Communications. Hannover:IEEE,2009:1-6. [7] 刘菲,曾广周.基于强化学习的多移动Agent学习算法[J].计算机工程与应用, 2006, 42(5):50-53. LIU Fei, ZENG Guang-zhou.Multi Mobile Agent Learning Algorithm Based on Reinforcement Learning [J].Computer Engineering and Applications,2006,42(5):50-53.(in Chinese) [8] Ziane S, Mellouk A. A QoS Adaptive Multi-path Reinforcement Learning Routing Algorithm for MANET[C]//Proceedings of ACS International Conference on Computer Systems and Applications.Amman,Jordan:IEEE/ACS,2007:659-664. [9] TaoT, Tagashira S, Fujita S. LQ-Routing Protocol for Mobile Ad-Hoc Networks[C]//Proceedings of the 4th ACIS International Conference on Computer and Information Science. Jeju Island, South Korea:IEEE,2005:441-446.2.4 多路径的调度策略
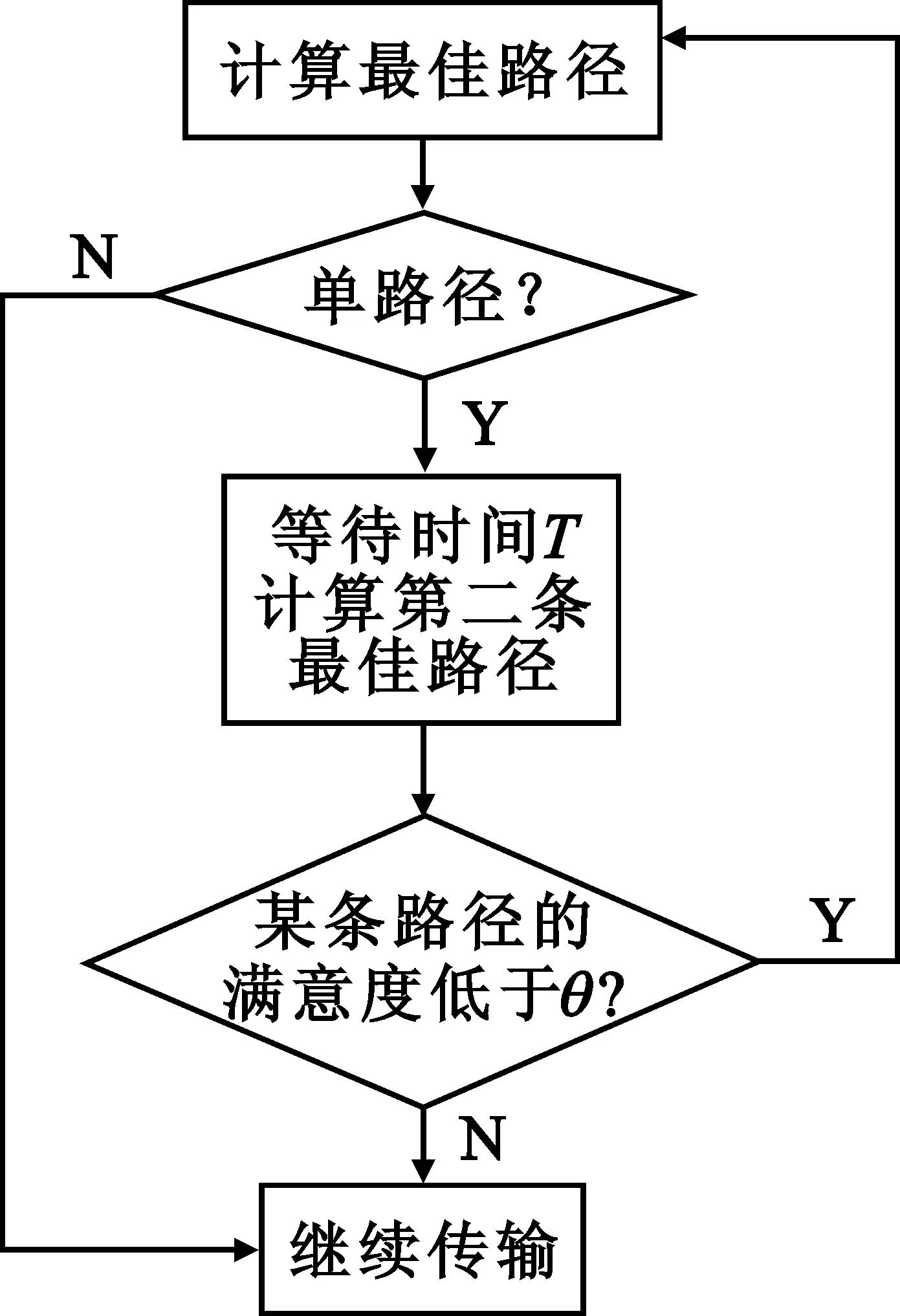
3 自适应路由算法描述
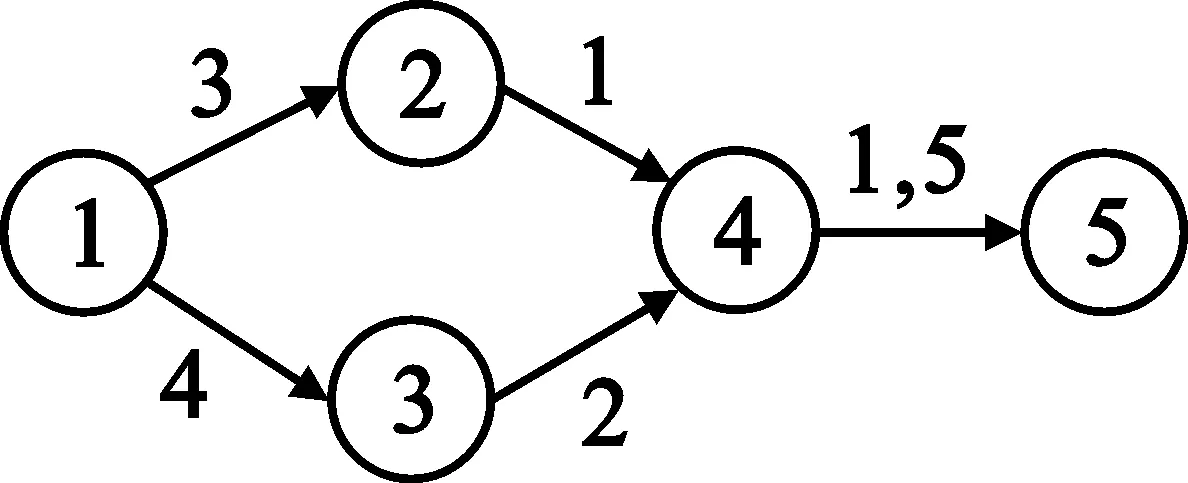
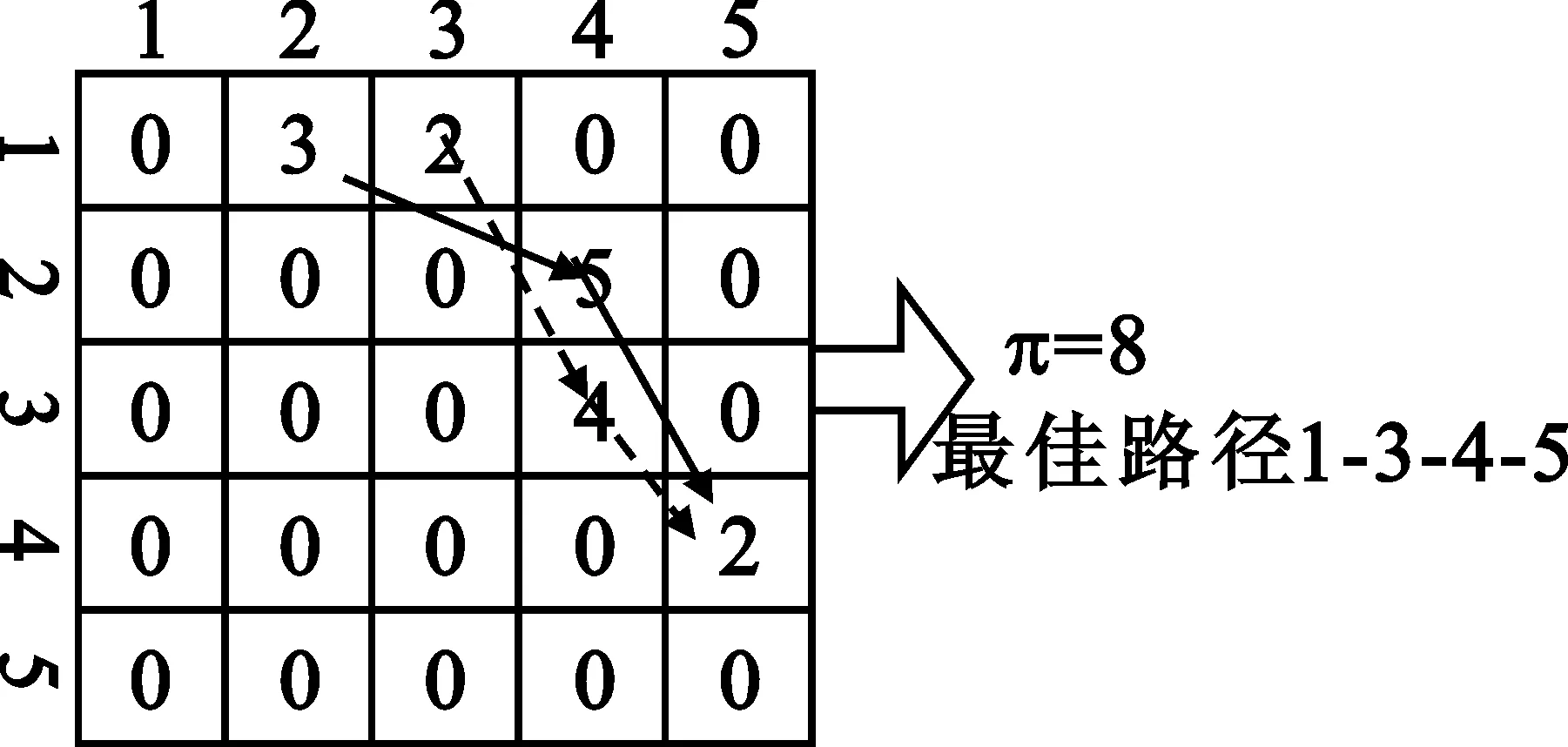
3.1 Q值函数路由表
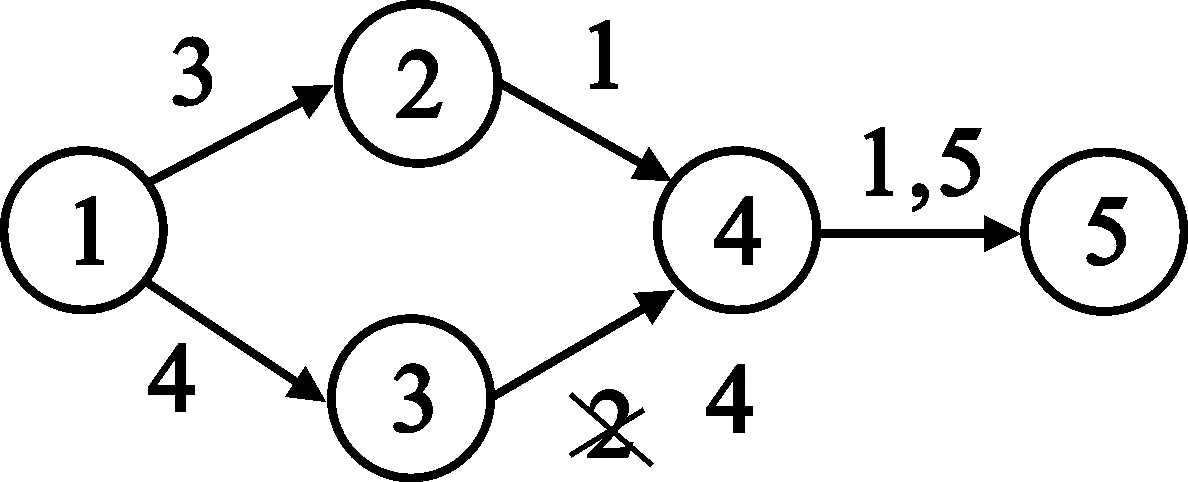

3.2 自适应多路径算法描述
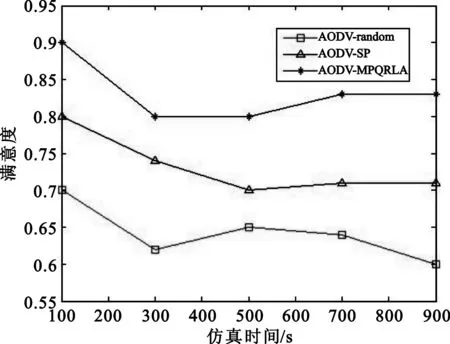
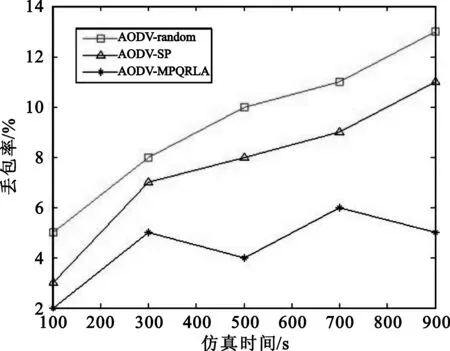
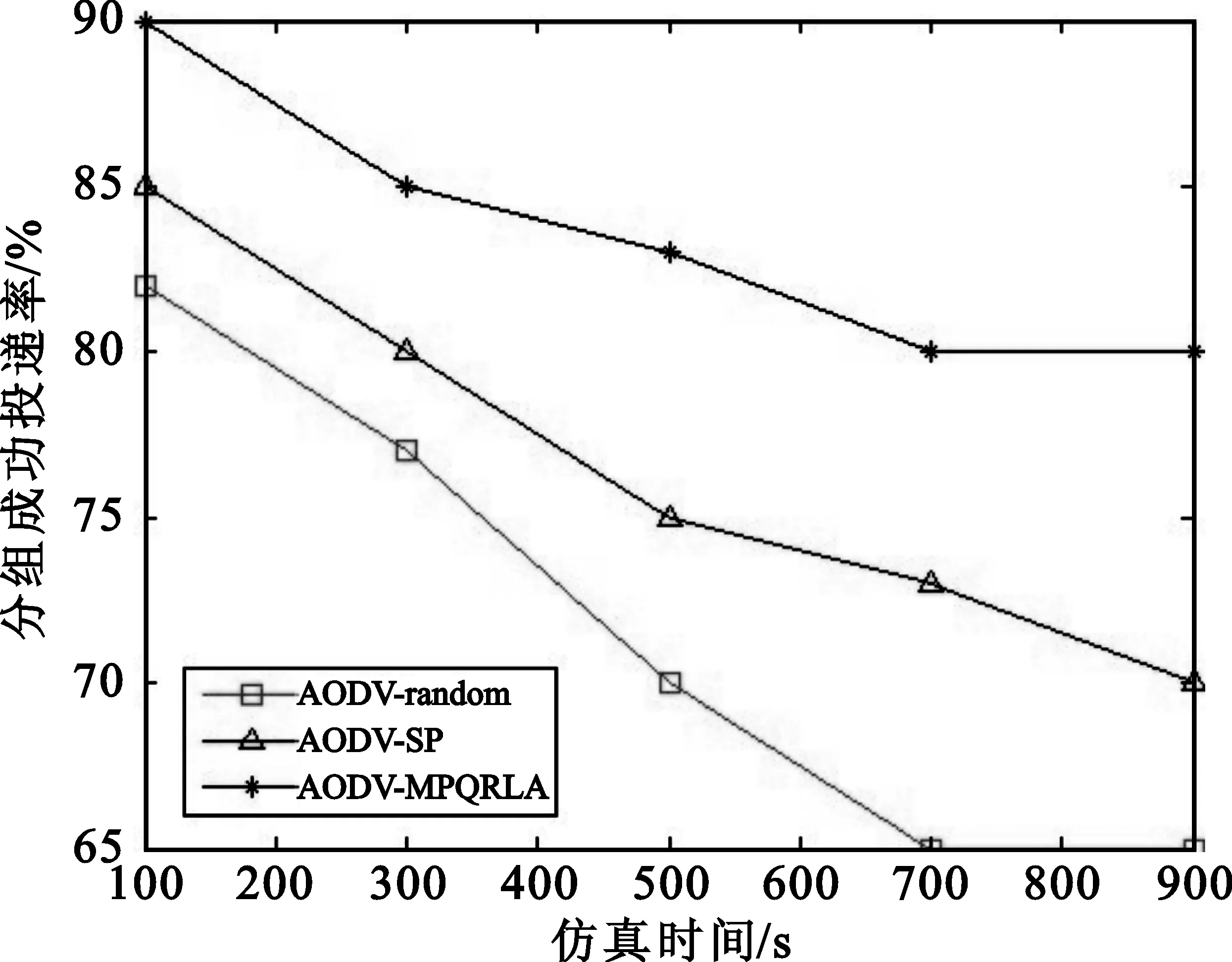
4 仿真结果与分析

5 结束语
