基于信息熵的电力负荷预测算法研究
2010-09-01王鸿健
王鸿健
(邵阳医专 网络中心,湖南 邵阳 422000)
基于信息熵的电力负荷预测算法研究
王鸿健
(邵阳医专 网络中心,湖南 邵阳 422000)
从粗集理论和信息论出发,依据属性约简的判断标准,提出了基于信息熵的电力负荷预测最佳属性集发现方法.
数据挖掘;粗集理论;信息熵;属性集
1 引言
从粗集理论和信息论[1,2,3,4]出发,我们将电力负荷预测系统看作是一决策系统,相关环境因素变量即为条件属性,待预测负荷量即为决策属性.则从所有可能相关的环境因素中去除冗余或次要的环境因素以及选择重要的环境因素,即是属性约简[5,6,7]及属性重要性的衡量问题.
2 设待挖掘电力负荷数据库T=,其中C、D分别为相关环境因素属性集和待预测负荷量属性
方法包括两个主要步骤:
2.1 属性值离散化:对待挖掘电力负荷数据库T各属性上的取值分别进行合理分类,并以类别标识代替各记录在该属性上的取值,形成离散化后的负荷数据库TA.
2.2 电力负荷预测最佳属性集发现:由离散化后的电力负荷数据库TA,将全部相关环境因素属性集C作为初始条件属性集,依据粗集理论和信息论的属性重要性的衡量标准及属性约简的判断依据,对C进行逐步约简,删除冗余和次要的属性,得到电力负荷预测最佳属性集.
下面我们分别给出这两部分的实现算法.
3 基于信息熵的电力负荷预测最佳属性集发现算法
输入:离散化后的电力负荷数据库TA=
输出:相关环境因素属性集C的一个最佳属性集B
Step1:计算TA中D相对于C的条件熵H (D|C)
Step2:计算D相对每个属性ai∈C的条件熵H(D|{ai}),将ai按H(D|{ai})降序排列得队列QUEUE(ai)(ai∈C)
Step3:令B=C.设置属性重要程度阀值ε的初值
Repeat
(1)取队列QUEUE(ai)的头元素a1,并将a1从队列中删除
(2)计算属性集D相对属性集B在删掉ai后的条件熵H(D|B-{ai})
(3)如果H(D|C)=H(D|B-{ai})
表明属性ai为冗余属性,应当约简,B=B-{ai}否则
如果0<H(D|B-{ai})-H(D|C)<ε
表明属性ai为非重要属性,根据需要决定是否约简.若约简,B=B-{ai}
否则
表明属性ai是重要属性,不能被约简,B不变until属性集B不再发生变化
4 实例
我们以电力预测日整点时刻的负荷值时,确定选择哪些相关环境变量作为主要输入变量对提出的电力负荷预测最佳属性集发现算法进行了测试.我们的实验设计如下:
我们收集了湖南省电力局09.2.l-09.5.31的每日12点时刻的负荷值共120条记录样本信息(列出其中21条,表1),其中每个样本含有6个条件属性和1个决策属性.这些条件属性为C={当天最高温度、当天最低温度、当天日期类型、前1天12点时刻的负荷值,前2天12点时刻的负荷值,前7天12点时刻的负荷值}.决策属性为D={当天12点时刻的负荷值}.
利用该算法求最佳属性集的过程如下:
(1)按1.1所述方法进行属性值离散化.设属性重要程度阀值ε=0
(2)计算决策属性集D相对条件属性集C的条件熵为H(D|C)=0
(3)计算属性集D相对属性集B在删掉ai后的条件熵H(D|B-{ai}),得到结果如表2,在2中,前2天12点时刻的负荷值条件信息熵为0,说明前2天12点时刻的负荷值对预测当天12点时刻的负荷值没有什么帮助,可以约简.继续用同样的方法对剩下的属性进行计算,发现再无法找到其他满足条件的属性,因此算法结束.最后得到的属性集为{当天最高温度、当天最低温度、当天日期类型、前1天12点时刻的负荷值,前7天12点时刻的负荷值},图1的数学拟合曲线证明了该算法的有效性和科学性.
通过和仿真拟合曲线的对比,发现这种算法能够比较准确的反映真实值,预测误差很低,不到5%,达到了理想的预测效果,证明了这种算法的科学和可行.

表1 湖南省电力局09年4月份负荷数据表

表2 各条件属性的条件信息熵
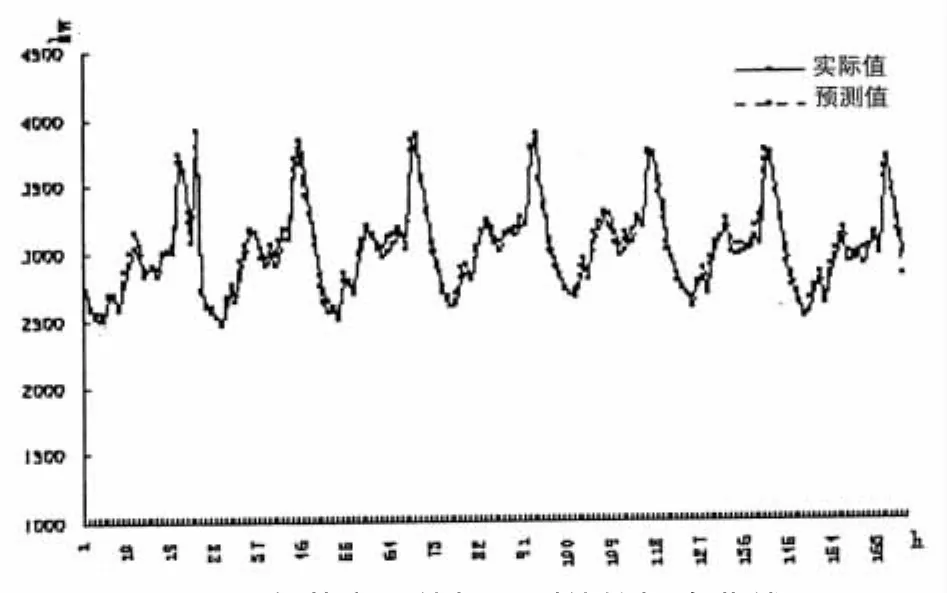
图1 负荷实际值与预测值的拟合曲线
5 结论
a.该算法设计简单,分类适中,利用该算法能够比较准确的预测.
b.仿真和实例证明,在分类复杂或过少的不全面的前提下,该算法能够迅速提炼最佳属性集,能够比较真实的预测实际值,大大减少工作的复杂度,提高工作效率.
〔1〕Pawlak Z,Grzymala-Busse J,Slow inskiR,et al.Rough sets.Communication ofthe ACM, 1995,38(11):88-95.
〔2〕Ivo Duntsch, Gunther Gediga.Uncertainty measures of rough set prediction.Artificial Intelligence,1998.106,109-137.
〔3〕Hu X, Cercone N.Learning in relation database:A Rough set approach.International Journal of Computational Intelligence,1995,11(2):323-338.
〔4〕苗夺谦,王钰.粗糙集理论中概念与运算的信息表示[J].软件学报,1999,10(2):113-116.
〔5〕常犁云,王国胤,吴渝.一种Rough Set理论的属性约简及规则提取方法[J].软件学报,1999,10(11):1206-1211.
〔6〕Miao Duoqian,WangJue.An informationbased algorithm forreduction ofknowledge.IEEE ICIPS’97,1997.1155-1158.
〔7〕苗夺谦,胡桂荣.知识约简的一种启发式算法[J].计算机研究与发展,1999,36(6):681-684.
〔8〕Jiawei Han,Micheline Kamber.数据挖掘概念与技术[M].北京:机械工业出版社,2001.
TM715
A
1673-260X(2010)05-0098-03
