基于态度的中文BBS信息过滤技术的探讨
2010-08-23刘健康
刘健康
LIU Jian-kang
(四川农业大学 商学院,都江堰 611830)
0 引言
随着互联网的发展和普及,网络上的信息与日俱增。BBS作为Internet 上一种新型的信息资源,成为网民获取信息资源的重要渠道之一。同时,它是一种通讯方式,每个BBS用户可以通过发帖的方式快捷地传递信息、发表意见、参与讨论。
BBS自由、开放、快捷的特点,为大家带来方便的同时,也迅速成为不良信息传播的主战场。因此,对BBS的信息监控与过滤是非常必要和紧迫的。目前的网页过滤技术主要有:网页分级、网址(Uniform Resource Locator,缩写为URL)过滤和内容过滤。有关研究表明,网页上的文字包含两种类型的信息:一种是事实(fact),另一种是态度(sentiment)。态度信息反映了说话人的情感和态度,也是文本信息的重要组成部分。对BBS帖子进行过滤,不仅需要对客观存在的事实进行分析,还需要获得发帖人通过文字所表述的态度倾向。基于关键词的内容过滤技术虽然分析了网页的内容,但忽略了与客观事实同等重要的态度信息。因此有必要对BBS内容进行态度挖掘。态度挖掘是近几年兴起来的一门交叉学科,涉及信息检索和计算机语言学的知识。它所关心的是文本所表达的主观性信息,而不是客观存在的事实。把态度挖掘运用到传统信息过滤系统中,对BBS中相同主题的帖子信息进行态度分类,进而决定最终应该过滤的信息,有助于提高信息过滤的准确率。
1 中文BBS信息过滤中的态度分类及规则的态度模型的实现

表1
对一篇文档而言,其态度倾向往往与构成这篇文档所用的词语的态度倾向密切相关,态度挖掘的基础是确定词语的态度倾向。如果一篇文本中存在表示态度倾向的词,那么就认为它是主观性文本,反之为客观性文本;如果表示正向态度的词语多于反向态度词,那么这篇文本的主观性为正,否则为反。本文从《知网》中获得一个较准确的正反态度词典,《知网》(英文名称为HowNet)是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库,表1列举了态度词典中的例子。
基于规则的态度模型的具体实现过程可以描述为:
1)利用态度词典查找句中是否含有态度词。
2)匹配句中是否含有改变句子态度倾向的附加词。
3)返回句子的态度倾向得分。
其流程图如图1所示。

图1 基于规则的态度挖掘
2 基于SVM的态度分类算法
支持向量机(Support Vector Machine,简记为SVM)由Vapnik在1995年提出,是一种基于统计学习理论的新型的通用学习方法,它建立在统计学习理论的VC理论和结构风险最小化原理的基础上,根据有限样本信息在模型的复杂性(即对特定训练文本的学习精度)和学习能力(即无错误的识别任意样本的能力)之间寻求最佳折衷,以期获得更好的泛化能力。其基本思想是针对两类分类问题寻找一个满足分类要求的最有超平面,使得这个分类超平面在保证分类精度的同时,能够使得超平面两侧的空白区域最大化。
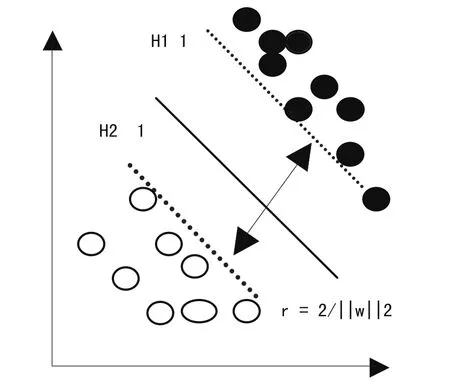
图2 支持向量机
假设训练文档集如下:
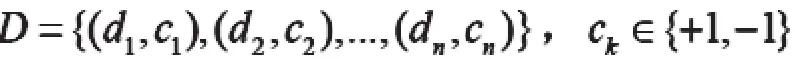
n为训练文档数,则两类分类问题就可以描述为:

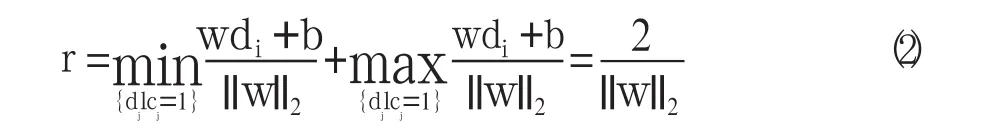
分类问题就转换为一个典型的二次规划问题,即在条件(1)下最大化(2),因此目标函数为:

其中,ai≥0是拉格朗日乘子。这样优化问题就可转化为对其“对偶”问题的求解,即:
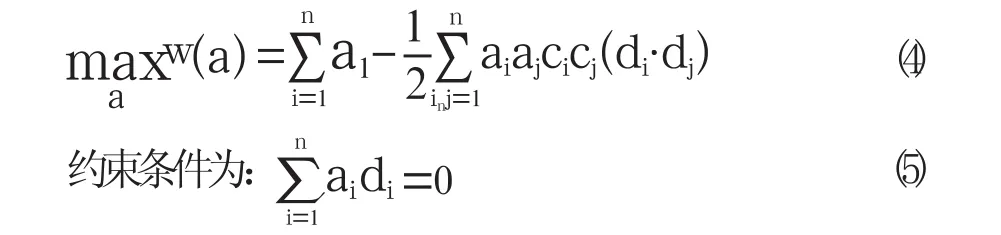
Karush-Kuhn-Tucher(KKT)条件对求解二次规划问题(4)(5)起重要作用,其解必满足:
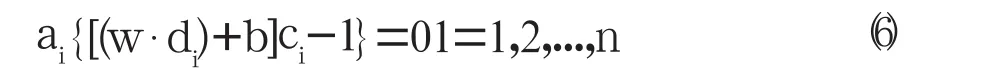
由式(6)知,ai=0的文本对分类起干扰作用。只有ai≠0的文本才会对求解w*、b*起作用,才能决定分类结果。这样的样本被定义为支持向量。对于线性不可分数据,支持向量机通过核函数把数据从低维空间映射到高维空间,然后在高维空间为低维数据构造线性可分超平面。支持向量机中最常用的3种核函数是多项式函数、径向基函数和多层神经网络函数。只要一种核函数K(c i ,cj )满足Mercer条件,它就对应某一空间中的内积。这样,在最优分类面中采用适当的核函数就可以实现某一非线性变换后的线性分类,而计算的复杂度并没有增加。此时,目标函数(4)变为:
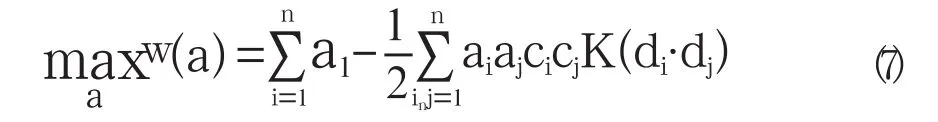
训练后的分类函数就为:
这称为支持向量机,它根据c(d)的符号来确定文本d的归属。本文在实验时,使用中科院的svmcls源程序,修改其特征提取方法。
3 基于SVM的态度分类实验
对基于SVM的态度分类模型进行两个对比实验,一个采用基于互信息的特征提取方法,一个采用本文提出的基于词典的特征提取策略,然后比较它们的态度分类效果。(本文的支持向量机使用中科院的svmcls源程序,修改其特征提取方法。实验选择的是线形核函数,其它参数用默认值)
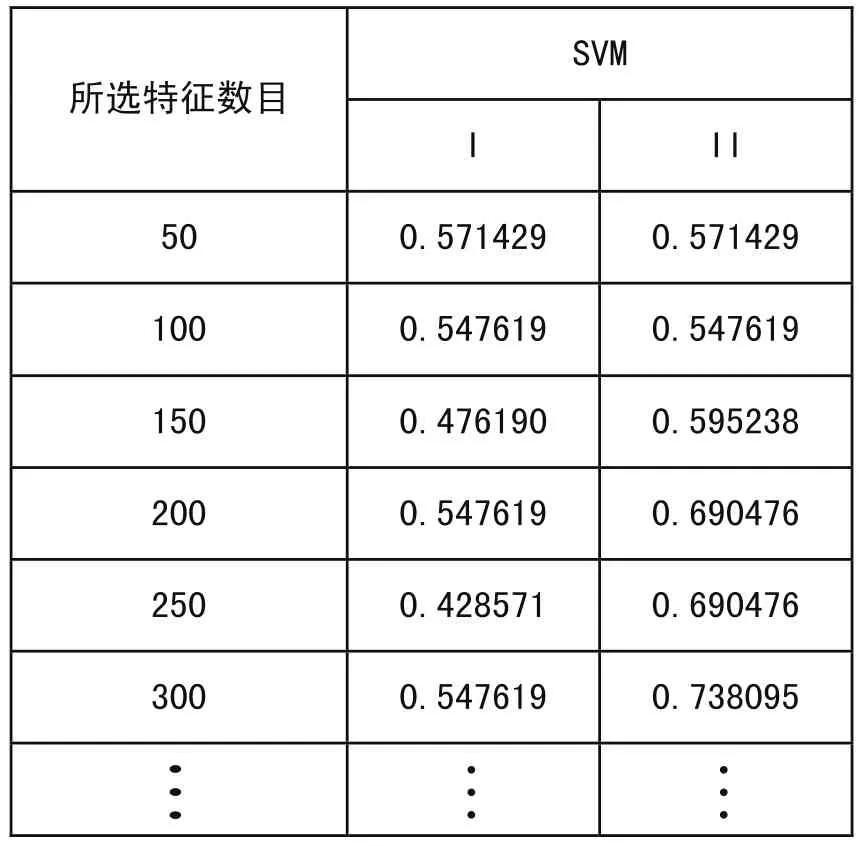
表2 不同特征数目下的两个SVM态度分类模型的F-Score值
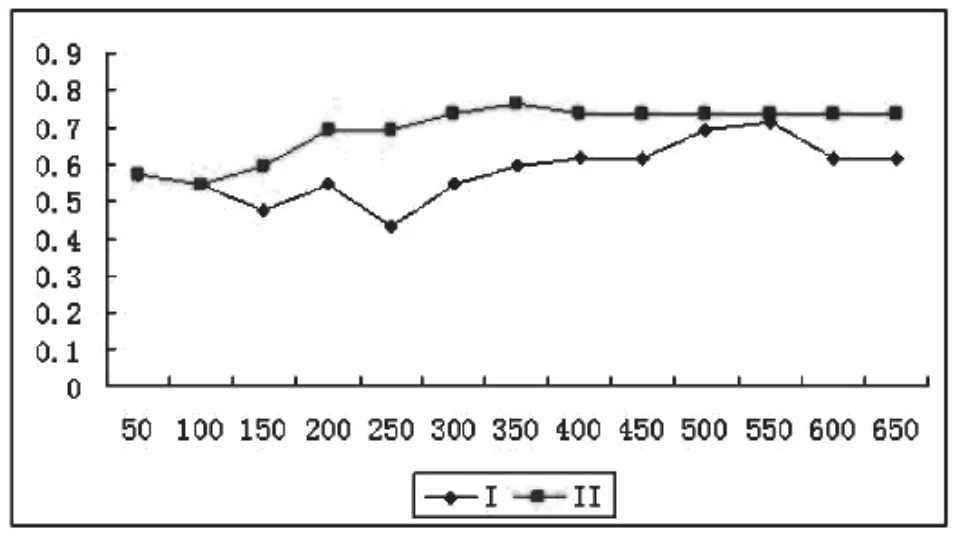
图3 两个基于 SVM 的态度分类模型比较
从表2可以看出基于词典的特征选择策略的SVM态度分类模型最高F-Score值可以达到0.761905,并且随着特征的增加F-Score值并没有降低,整个曲线呈迂回上升的形式。虽然基于传统特征选择的SVM态度分类模型也取得比较好的分类效果,但通过特征数目从0变化到400的过程中可以看出,在实验II中,由于选择的特征剔出了与态度分类无关的特征词,它的曲线几乎都位于实验I所形成的曲线之上。由于语料库的原因,特征词数目在400以后实验II中的特征词无变化,其F-Score也不发生改变。但总的来说,基于SVM的态度分类算法具有很好的分类效果。
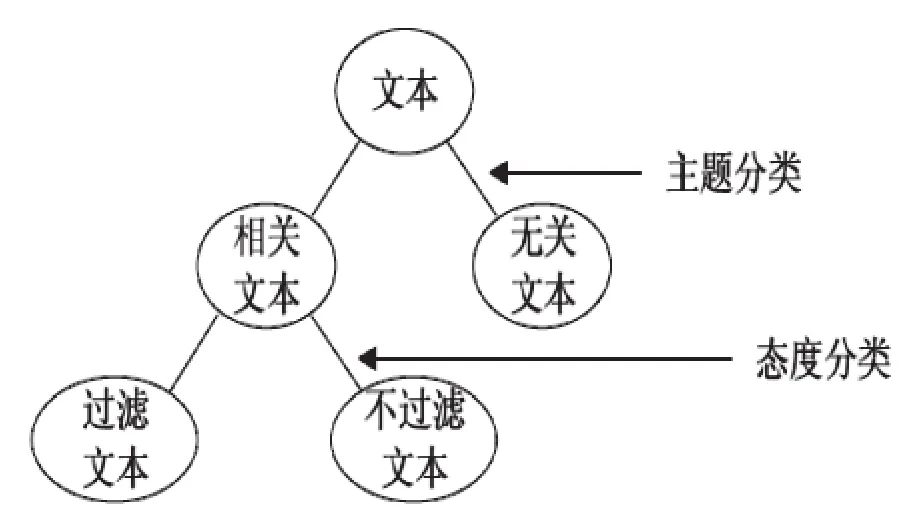
图4 两层过滤模型

图5 系统流程图
4 中文 BBS 信息过滤原型系统设计
系统采用两层过滤模型如图4所示。
系统流程图如图5所示。
5 结束语
本文首次把态度挖掘应用到中文BBS信息过滤中,所有的工作还出于起步阶段,构建的基于态度的中文BBS信息过滤原型系统还有大量的工作需要做,并且还有许多地方需要改进和提高。
[1]黄晓斌,邱明辉.网络信息过滤系统研究[J].情报学报, 2004.
[2]阮彤,冯东雷,李京.基于贝叶斯网络的信息过滤模型研究[J].计算机研究与发展,2002.
[3]S.T.Dumais,et al.Using latent semantic analysis to improveinformation retrieval[C].In CHI'88 Proceedings,1988.
[4]Christopher D. Manning, Hinrich Schutze.Foundations of Statistical Natural Language,Processing[M]. Publishing House of Electronics Industry
[5]刘源,谭强,沈旭昆.信息处理用现代汉语分词规范及自动分词方法[M].清华大学出版社,1994.
[6]D.Roth.Learning to resolve natural language ambiguities:Aunified approach.InProceedings of the National Conference on Artifical Intelligence,1998.
[7]Vasehgi S V.State Duration Modeling in Hidden Markov Models[J].Signal processing,1995.
[8]Vladimir N,Vapnik. Statistical Learning Theory[M]. New York:John Wiley & Sons,Inc.,1998.
[9]姚天昉,娄德成.汉语语句主题语义倾向分析方法的研究[J].中文信息学报,2007,05.
