基于闭环反馈模式的弹性分组环多阻塞点公平算法
2010-08-14程方黄世广郁志勇张治中
程方,黄世广,郁志勇,张治中
(1. 重庆邮电大学 通信与信息工程学院,重庆 400065;2. 中兴通讯股份有限公司,广东 深圳 518057)
1 引言
弹性分组环(RPR, resilient packet ring)是一种新型的 MAC层协议[1],其拓扑类似于传统的FDDI[2]、令牌环[3]网络,均采用了双环结构。RPR集Ethernet的经济性,SDH的高带宽和高可靠性,IP技术的智能性于一体,受到了业界的广泛关注。迄今,对 RPR组网技术的研究大致可以分为 2大类[4~9]:MAC协议性能分析和公平算法。公平算法是指当网络发生拥塞时,控制环上的节点以便在拥塞链路上分配到公平的带宽。在公平算法研究方面,业界广泛采用的算法都是基于单阻塞点情况的,性能较好的有2种[10~12]:一种是循环排队多址接入(CQMA,cyclic queuing multiple access)算法;另一种是空间重用协议(SRP, spacial reuse protocol)算法。尽管CQMA和SRP都可以实现带宽的动态分配,但存在致命的缺点:算法存在振荡而导致带宽利用率不高。Gambiroza等人据此提出了环内分布式虚拟时间调度(DVSR, distributed virtual-time scheduling in rings)算法[9],在单阻塞点情况下,具有非常好的性能。当RPR网络规模较大,且业务动态变化时,已有的研究表明[10~12]:排头阻塞(head-of-line blocking)对网络性能的影响是非常严重的,在此情况下,即使阻塞点远离某节点的目的节点,其业务都会受到较大的限制,即导致大量业务受到不必要的“惩罚”。因此,包括DVSR在内的单阻塞点算法不能保证带宽的利用率。据此,研究了多阻塞点公平算法,目的在于解决单阻塞点公平性算法所存在的问题。
2 多阻塞点公平性评价准则
文献[9]针对RPR单阻塞点情况提出了RIAS公平性评价准则,虽然保证了MAC协议公平性的要求,在提高网络利用率方面取得较大突破,但是它并不适合于多阻塞点情况。本文借鉴了文献[8]的思想,提出了一种适合于多阻塞点情况的评价准则。
不失一般性,设 RPR环网是有向的,包括 N个节点(0<N≤255),每条链路的带宽相等,均为C。一条流(flow)就是在一个确定的输入输出节点对之间的业务,记入节点i和出节点j之间的业务为flow(i, j)。令Rij代表节点i和j间的公平速率,则在链路n上已分配的速率Fn为
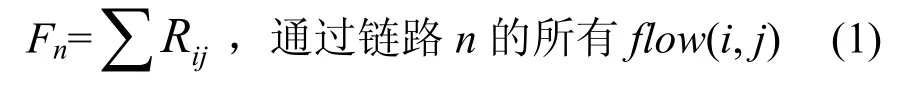
对于已分配的速率矩阵R={Rij},有以下约束条件:

定义1 矩阵R满足式(2)和式(3)的约束条件,就说R是可行且是唯一的。
定义2 设θi为源节点i的加权值,θij为流(i, j)的加权值,如果存在一个可行的速率矩阵R,使得下述条件成立,则称链路n是穿过链路n的flow(a,b)与R相关的瓶颈段,记为Bn(a, b)。
1) Fn=Cn,1≤n≤N;
2) Rab/θab=max{Rij/θij}(1≤i j≤N,且 i=a), 穿过链路n的流都由节点a发出;
3) IAn(a)/θa=max{IAn(i)/θi}(1 ≤ i≤ N), 且Rab/θab=max{Rij/θij}(1≤i, j≤N,且 i=a),穿过链路n的流由多个源节点发出。
定义 3 设θi和θi′分别为源节点i与源节点 i′的加权值,θij和θi′j′分别为 flow(i, j)与 flow(i′, j′)的加权值,RBn(i,j)为穿过瓶颈段Bn(i, j)的流,一个可行的速率矩阵R如果满足下述条件,则被认为是满足多阻塞点公平性评价准则的。
在保证可行性且 flow(i, j)与 flow(i′, j′)经过的链路至少有一段相同的前提下,若要增加Rij,除非减小 Ri′j′ (1≤i,i′,j,j′≤N),且
1) Rij/θiθij≥Ri′j′/θi′θi′j′, i=i′;
RBn(i,j)>0, R[Bn(i,j),Bn′(i′,j′)]>0, n ≠ n′;
3) IAn(i)/θi≥IAn(i′)/θi′, 除上述条件以外。
由以上定义,如果 flow(i, j)与 flow(i′, j′)的源节点相同,则前者的速率与相应的加权值之比不小于后者;如果网络上存在不同的瓶颈段,2条流至少穿过一个相同的瓶颈段,则穿过瓶颈段较少的流的速率与相应的加权值之比不小于穿过较多瓶颈段的流的速率与相应的加权值之比;除上述2种情况外,穿过同样的链路 n,且源节点为i的流的速率之和与节点 i的加权值之比不小于源节点为 i′的流的速率之和与节点i′的加权值之比。
为便于理解,对多阻塞点公平性评价准则举例予以说明。如图1所示,各条流的容量需求为无限大,多阻塞点公平性评价准则共享带宽如下:R14=R15=R25=R45=0.333C,R12=0.667C。如果考虑flow(1,2),当flow(1,5)没有减少速率,增加flow(1,2)的速率是不可行的,违反了条件 1)。如果考虑flow(2,4)和 flow(2,5),不减少 flow(1,5)或者 flow(4,5)的速率,而增加flow(2,4)和flow(2,5)的速率也是不可行的,违反了条件3)。对于条件2),假设网络上存在2个瓶颈段[S2,S3]和[S4,S5],要增flow(4, 5),只能减少flow(1,5)或者flow(2,5)的速率。
3 基于闭环反馈模式的多阻塞点公平算法
3.1 算法实现模块
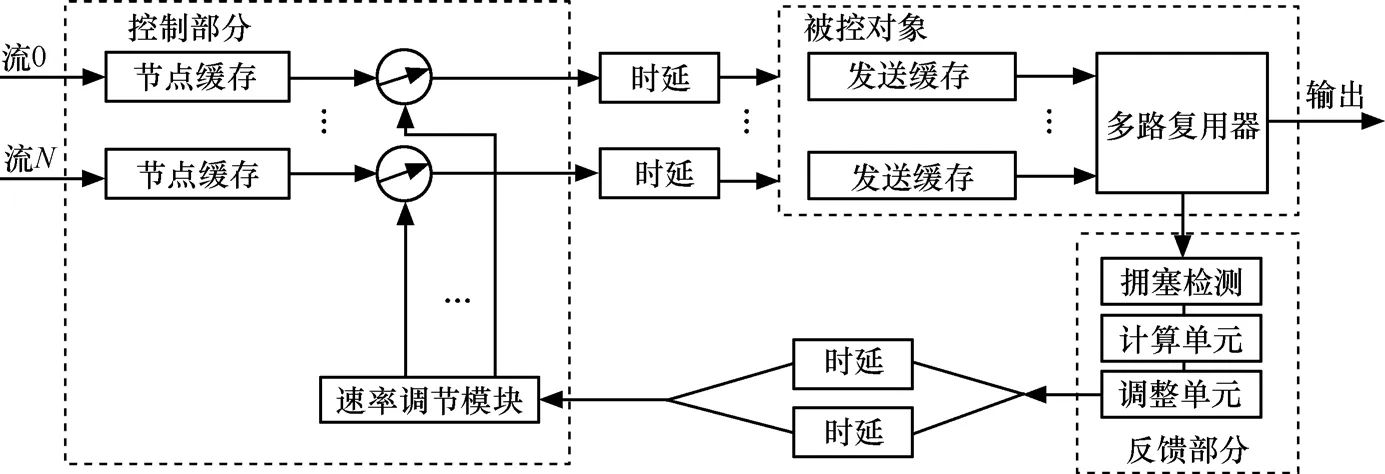
图2 基于闭环反馈模式的多阻塞点公平性算法的实现
基于闭环反馈模式的多阻塞点公平算法的组成模块如图2所示,主要包括被控对象、反馈部分和控制部分3部分。反馈部分又由3个模块组成:拥塞检测模块、计算单元模块和调整单元模块。算法的核心是确定反馈部分的公平速率值。
3.2 公平速率的确定
如图3所示,在节点S0和Sn之间,节点S0最多有1条业务流经过节点Sn,节点S1最多有2条业务流经过节点Sn,节点Sn-1最多有n条业务流经过节点Sn。设Sn为阻塞节点,节点S0,S1,…,Sn的权值分别为 a0,a2,…,an。
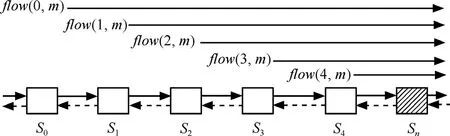
图3 算法模型
令m=a0+a1+…+an。对阻塞节点Sn,计算得到每条聚合流实际分配到的带宽分配矩阵为:

设bij为每条业务流的权值,。
则在理想状态下,每一条业务流实际分配的带宽为:

假设第i个节点预留的A类业务和B-CIR(承诺速率)类业务的带宽为mi,其剩余的C类和B-EIR(额外速率)类的业务流的分配权值为wij,有:

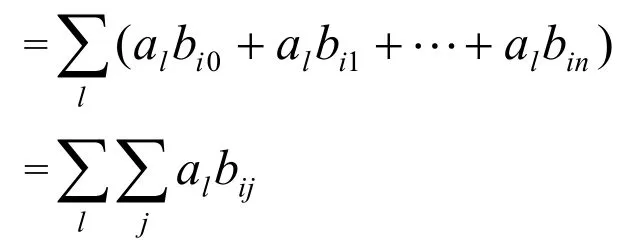
令wij= albij,则每条业务流的本地公平带宽Cw可以表示为:
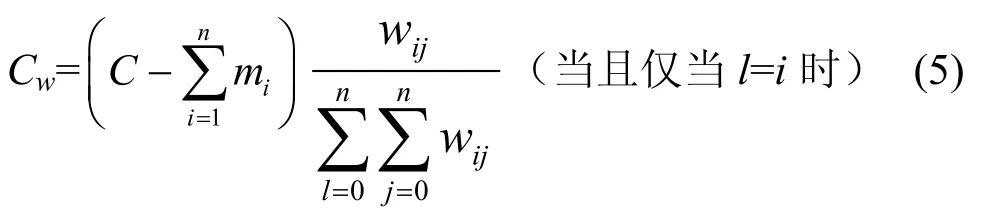
对于某一阻塞点来说,它将下游阻塞节点所广播的公平帧的内容和自己计算的本地公平速率进行比较,选择其中较小者广播给上游节点。假设Cwr为第r个阻塞节点所分配的公平速率值,某条业务流经过调整后所分配到的公平带宽为 C′w,则本地的公平带宽C′w为:
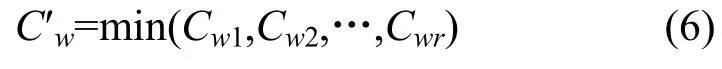
经过式(6)调整后,链路可能尚有剩余的带宽,为了最大限度利用链路资源,实现空间重用,剩下的业务流所分配到的带宽需要进一步调整,如图 4所示。

图4 多阻塞点网络参考模型
对于图 4,根据式(6),需要调节的业务流为flow(2,7)和 flow(3,7),那么 flow(1,4)和 flow(2,4)要共享剩余的带宽不小于式(5)得到的带宽。这里采用通用的做法,令所有节点和业务流的权值相等(即al=a,bij=b),则本地阻塞节点在分配了通过本地节点又通过下游阻塞节点的业务流后,剩余的业务流所分配到的带宽 C′w为
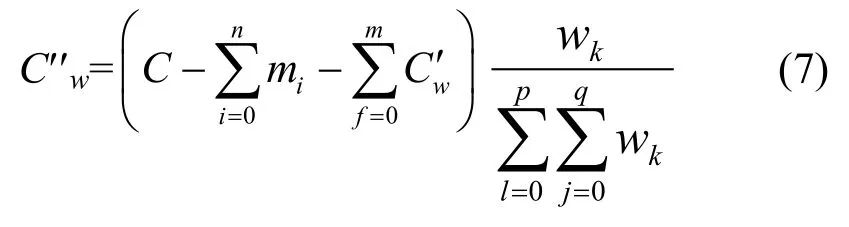
其中,m为在某一阻塞节点经过式(6)调节的业务流总数;p为产生业务流且有业务流不需式(6)调节的节点总数;q为第l个节点所发出的,不需要式(6)调节的业务流总目。wk为业务流的分配权值,wk=ab。
式(5)~式(7)在理论上很好地解决了多阻塞点带宽分配的问题,但在工程应用上,算法实现难度偏高。可将式(5)~ 式(7)进一步转换成式(8)。

式(8)中,num为流经本地节点的业务流总数;LCw(k)0为本地节点的公平速率;RC+1为下一状态的剩余带宽;RC0为当前状态下的剩余带宽;FCw(k)0为本地节点向上游节点广播的公平速率值;FCw(k)-1为下游阻塞节点向本地节点广播的公平速率值。
式(8)由上而下计算,主要思想如下。
1) 由式(8a)估算第 k条 flow(i,j)的本地节点公平速率值。
2) 每处理一条业务流,num自减1。
3) 通过式(8c),选择 LCw(k)0和 FCw(k)-1中的较小者,封装成多阻塞点公平帧,向上游节点广播。
4) 通过式(8d)计算下一状态的剩余带宽RC+1。
对于单一阻塞节点来说,式(5)~式(7)组合而成的算法时间复杂度是O(sn2),式(8)的算法时间复杂度是O(n2)。但对整个网络来说,如果存在s个阻塞节点,由式(5)~式(7)组合而成的算法需要等待下游阻塞节点完成带宽的公平分配后才能公平分配本地公平带宽,因此时间复杂度是O(sn2)。式(8)则是一旦接收到某条数据流的公平帧就调整该条数据流,不需要等待下游阻塞节点完成带宽的公平分配,所以式(8)的时间复杂度是 O(n2)。可见,在多阻塞状态下,式(8)更优越。
3.3 算法的选择
对于图 4,不失一般性,设剩余带宽为 1,每条流的分配权值为1,节点S3和节点S6为阻塞节点。
算法 1 由式(5)~式(7)确定多阻塞点的公平速率值。
根据式(5),得到节点 S6估算的本地公平速率值为
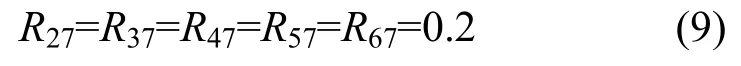
节点S3估算的本地公平速率值为
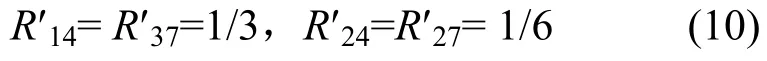
当节点S6的公平帧反馈到节点S3后,经比较,有 R27>R′27,R37<R′37,依据式(6),R′27和 R′37被调整为

为了最大限度利用剩余带宽,根据式(7),重新计算 R′14和 R′24为

所以系统最终构建的公平带宽为

算法2 由式(8)确定多阻塞点的公平速率值。
由图4可得,wk=ab=1,流经阻塞节点S6的业务流总数为5,由式(8)得到
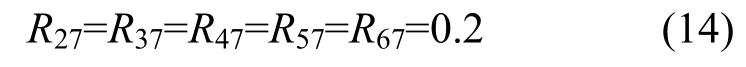
当阻塞节点S6将flow(2,7)的公平速率值(0.2)反馈到阻塞节点S3后,S3由式(8a)得到公平速率估算值为

经比较,节点S3将0.2封装到MCFF中,再发送给上游节点,即R′27最终的公平速率值R′27=0.2。此时,下一状态的剩余带宽为(1-0.2)=0.8,流经S3的业务流的总数目num变为3。
同理,当阻塞节点S6将flow(3,7)的公平速率值0.2反馈到阻塞节点S3后,S3通过计算,得到公平速率的估算值为
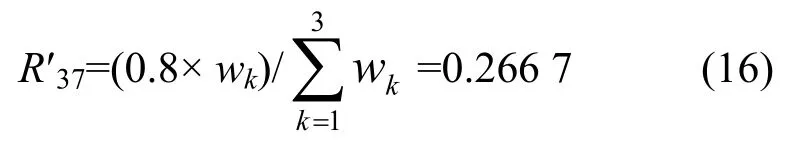
经比较得出 R′37最终的公平速率值 R′37=0.2。此时,剩余带宽为(0.8-0.2)=0.6,流经S3的业务流的总数目num变为2。
由于flow(1,4)和flow(2,4)没有流经阻塞节点S6,对S6不产生影响,所以它们的公平速率值由式(8a)求得:R′14= R′24=0.3。则最终的公平速率为

由前述可知:2种方案都实现了多阻塞点公平算法的带宽分配,且实现了阻塞链路上剩余带宽的最大分配(流经阻塞节点S3、S6的业务流的速率和为1)。然而,算法1需要对flow(2,7)和flow(3,7)调节完成后,才能得到flow(1,4)和flow(2,4)的最终公平速率值,而算法2无此要求,因此算法2的复杂度更低。不过,算法2牺牲了某些业务流的公平性。例如,比较式(13)和式(17)可知,flow(1,4)和flow(2,4)所期待的公平速率值为方案1中的速率,即0.316 7,但实际只分配了0.3;flow(2,7)所期待的公平速率为方案1中的0.167,实际上为0.2。
总体来看,2个算法的性能相差不大,但算法2的复杂度更低,有利于快速解决网络中的阻塞状态。
3.4 伪代码
设k为时间周期T内到达阻塞节点的业务流数目,MCFF[i]为本地节点接收到下游阻塞节点反馈来的第i条业务流的公平速率;Rcapacity为链路的剩余带宽;vi表示阻塞节点计算出业务流 i的公平速率,则算法的伪代码可表示为:

4 仿真实验
基于OPNET modeler(Version 10.5)[13],设计了RPR的节点仿真模型和链路仿真模型,仿真节点通过链路连接构成RPR双纤反向传输环仿真环境,如图5所示。其中node_A表示数据源,node_1表示RPR节点,1~4起滤波作用。图6为RPR节点仿真模型结构,其中的核心是MAC功能实现模块;Sink模块是本地数据下载模块;src_Tx和src_Rx分别是数据源的发送和接收模块;0_Rx_0、0_Tx_0、1_Rx_1、1_Tx_1分别是4个物理层的收发模块。

图5 RPR仿真平台
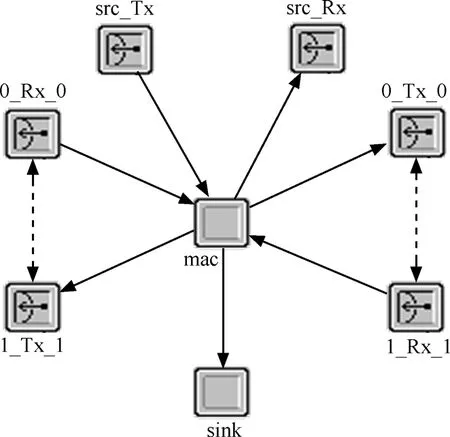
图6 RPR节点模型
本文选择了典型的“停车场景[9,10]”对上述算法进行了仿真研究,输出指标主要是算法的公平性、收敛时间和带宽利用率。为便于衡量本文算法性能,对单阻塞点和多阻塞点2种情况均进行了仿真。仿真参数设置见表1。

表1 仿真参数
4.1 单阻塞点情况
如图7所示,本文选择了典型的上游并行停车场景来考察算法在单阻塞点情况下的性能。节点 1以300kbit/s速率向节点4发送数据,节点2~5分别在时刻0.05s、0.1s、0.15s、0.2s,均以300kbit/s速率发送数据到节点6。仿真结果如图8所示。

图7 上游并行停车场景
结果分析:如图 8(b)~图 8(d),在 0.2s后,各流都能快速收敛,不存在大的振荡,而且稳定的流速率接近于依据公平性评价准则计算所得到的值,R26≈R36≈R46≈R56≈250kbit/s。
图8(a)表示节点S1在0.23s左右接收到阻塞节点反馈回来的公平帧后,速率收敛于500kbit/s。该值充分说明,本文提出的基于反馈模式的多阻塞点公平算法:①能实现带宽的空间重用;②目的地在阻塞点上游的任何业务流都能最大限度的利用剩余带宽,不会受到阻塞点的影响。

图8 单阻塞点情况下的仿真结果
4.2 多阻塞点情况
如图9所示的多阻塞点停车场景,节点1在0s向节点10发送数据,节点2、3、4在时刻0.05s、0.1s、0.15s向节点5发送数据,而节点6、7、8、9在时刻 0.2s、0.25s、0.3s、0.35s向节点 10发送数据,且它们的发送速率均为300kbit/s,仿真时间为2s。结果如图10所示。

图9 多阻塞点停车场景

图10 场景3情况下的仿真结果
结果分析:从图 10(a)可以看出,flow(1,10)先以初始速率300kbit/s发送数据,在0.18s左右收敛于公平速率250kbit/s,再经过0.23s后,收敛于节点S9计算得到的公平速率200kbit/s,该发送速率满足不大于源节点和目的节点之间所有阻塞点的公平速率。另外,由 250kbit/s收敛到200kbit/s的时间大约为30ms(小于50ms)。因此,本文公平算法能较快收敛于最小公平值,不存在较大的震荡。
图10(b)~图10(d)中的3条数据流在0.18s时刻收敛于节点 S4计算出的公平速率(250kbit/s)。在0.41s左右,由于节点S1发送的数据流进一步收敛于公平值200kbit/s,因此链路约有50kbit/s剩余带宽,为了进一步利用剩余带宽,上述3条流都进一步调整到公平性评价准则计算所得到的值266.7kbit/s,实现了带宽的空间重用,同时并没有引起较大震荡。各条流的传送速率的公平性评价指标均接近于1(FI2,5(t)≈FI3,5(t)≈FI4,5(t)≈1)。
由图 10(e)~图 10(h)可知,在 0.3s后,各条流先收敛到速率250kbit/s,接着在0.35s后,节点S9检测到自身为阻塞节点,对图9上的4条流进行进一步调整,最后各条流的稳定速率接近公平性评价准 则 计 算 所 得 到 的 值 ( R6,10≈R7,10≈R8,10≈R9,10≈200kbit/s)。由此,基于反馈模型的多阻塞点公平算法能100%地利用剩余带宽,实现带宽的公平分配。
5 算法的FPGA实现
如图11所示,基于闭环反馈模式的多阻塞点公平算法由公平帧调度模块、算法实现模块以及数据帧调度模块组成,算法实现模块又由阻塞监测、数据统计、带宽分配3部分组成。数据流进入弹性分组环的节点时,节点根据数据的操作请求,通过多阻塞点公平性算法实现模块,完成MAC协议公平性算法,实现带宽在各节点间快速、公平的分配。
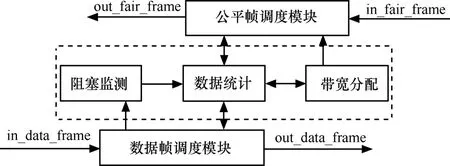
图11 多阻塞点公平算法FPGA实现
数据帧调度模块和公平帧调度模块:前者用来判断转发数据帧的起止位置,提取报头信息,完成转发数据帧和本地数据帧的调度,确定产生本地业务流量;后者根据转发公平帧提取有效报头信息,实现转发公平帧和本地公平帧的调度功能。
阻塞检测:以缓存器STQ的队列长度为检测对象,通过计算求出缓存深度平均值(avg),如果avg超过设定门限(阻塞门限),则判断本地节点发生阻塞。
数据统计:本地节点到目的节点的跳数(desthops)、数据帧中源节点到本地节点的跳数(srchops)、缓存地址值、映射地址、公平帧中的源MAC地址到本地节点的跳数、流经本地节点,又流经阻塞节点的业务流总数目、本地节点非阻塞时,流经本地节点,却没流经阻塞节点的业务流总数目。
带宽分配:完成本地节点公平速率的计算,以及根据接收到的公平速率进行比较,将较小值传递给上游节点。
参考图9的仿真模型,假设链路带宽为1 000,S4既是本地节点又是阻塞节点,S8、S9是下游阻塞节点。那么 S4在阻塞状态下收到节点 S8、S9广播的公平帧。根据式(8)可知,S9计算的公平速率为200,反馈到节点S4后,flow(2,5)、flow(3,5)、flow(4,5)的最大允许发送速率被调整到266左右。为了简化,减少仿真图中显示数据帧或公平帧的长度,并不失一般性,本文把流经数据帧调度模块和公平帧调度模块中的业务流的帧结构中的源MAC地址和目的MAC地址的宽度设置为8bit(有效地代表了环网中255个节点)。如一个简单的数据帧“7E0872080E7E”(16进制表示,不包含数据帧结构中“协议类型/长度”以下的内容),“7E”表示帧开始或结束标志位,TTL为“08”、目的MAC地址为“08”、源MAC地址为“0E”。模拟公平帧类似,但不包含目的MAC地址,且比模拟数据帧多了 16bit公平值。设flow(6,10)、flow(7,10)、flow(8,10)、flow(9,10)的模拟数据帧为“7E077209017E”、“7E017205027E”、“7E017205037E”、“7E017205047E”;收到阻塞节点S9反馈的模拟公平帧为“7E0B720900C87E”。
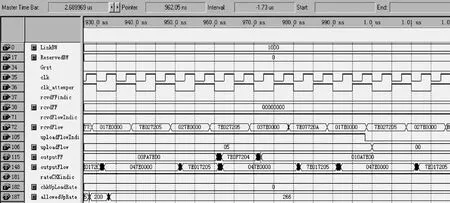
图12 多阻塞点停车场景时序仿真
由图12可见,节点S4产生了一个模拟公平帧“7E0F7204010A7E00”(端口 outputFF的输出),公平帧控制值的内容是“010A”(“010A”的十进制表示为“266”)。可见,在本地节点既是阻塞节点又接收到公平帧情况下,本文设计的算法在FPGA实现中满足了多阻塞点公平算法的要求。
6 结束语
本文对RPR多阻塞点公平算法进行了研究,提出了一种多阻塞点公平性评价准则,在此基础上给出了一种多阻塞点公平性算法,并对算法的公平性和链路利用率进行了仿真分析和FPGA实现。结果表明:本文算法能有效地控制链路速率的变化,避免排头阻塞的影响,在典型的停车场景中能够较快地收敛到公平值。与单阻塞点算法相比,由于本文算法只对阻塞域之间的链路进行调整,因而大大提高了资源利用率。
[1] DAVIK F, YILMAZ M, GJESSING S, UZUN N. IEEE 802.17 resilient packet ring tutoria[J]. IEEE Communications Magazine, 2004,42(3):112-118.
[2] ROSS F E. Overview of FDDI: The fiber distributed data interface[J]. IEEE Journal on Selected Areas in Communication, 1989, 7(7):1043- 1051.
[3] SPADARO S, SOLE P J, CAREGLIO D, et al. Positioning of the RPR standard in contemporary operator environments[J]. IEEE Network,2004, 18(2):35-40.
[4] 王嵌, 吴重庆, 魏斌. 光弹性分组环节点光分组的组装及时延分析[J]. 光学学报, 2009, 29(4):897-901.WANG Q, WU C Q, WEI B. Assembly and delay analysis of optical resilient packet ring on packets encapsulation[J]. Acta Optica Sinica,2009, 29(4):897-901.
[5] SHOKRANI A, TALIM J L. Modeling and analysis of fair rate calculation in resilient packet ring conservative mode[A]. IEEE International Conference on Communications (IEEE ICC 2006)[C]. Istanbul,Turkey, 2006. 203-210.
[6] TANG H, LAMBADARIS I, MEHRVAR H, Performance evaluation of VSQ: a fair MAC scheme for packet ring networks[J]. IEEE Journal on Selected Areas in Communication, 2006(6):107-114.
[7] YILMAZ M, ANSARI N. Weighted fairness in resilient packet rings[A]. IEEE International Conference on Communications (IEEE ICC 2007)[C]. Glasgow, Scotland, 2007.2192-2197.
[8] ZHOU X B, LIU L, ZENG L G. A novel fairness algorithm for resilient packet ring based on feedback theory[A]. The 9th International Conference on Advanced Communication Technology[C]. Phoenix Park, Republic of Korea, 2007.1407-1411.
[9] GAMBIROZA V, YUAN PING, LAURA B E. Design, analysis, and implementation of DVSR: a fair high-performance protocol for packet ring[J]. IEEE/ACM Transaction on Networking, 2004,12(1):85-102.
[10] 陶滢. 弹性分组环若干关键问题的研究[D]. 北京:北方交通大学,2003.TAO Y. Studies on Some key Questions of Resilient Packet Ring[D].Beijing: Jiao Tong University, 2003.
[11] SHOKRANIT A, LAMBADARIS I, VINIOTIS Y. Configuring conservative mode fairness algorithm in resilient packet rings[A]. IEEE International Conference on Communications (IEEE ICC 2008)[C].Beijing: China, 2008.139-145.
[12] ZHOU S Y, WEI X. A fairness algorithm based on flow for register insertion ring[A]. Third International Conference on Communications and Networking[C]. Beijing, China, 2008.810-813.
[13] 张铭, 窦赫蕾, 常春藤. OPNET Modeler与网络仿真[M]. 北京: 人民邮电出版社, 2007.ZHANG M, DOU H L, CHANG C T. OPNET Modeler and Network Simulation[M]. Beijing: Posts & Telecom Press, 2007.
