基于组特征过滤器的僵尸主机检测方法的研究
2010-08-04王劲松刘帆张健
王劲松,刘帆,张健
(1.天津理工大学 计算机视觉与系统省部共建教育部重点实验室,天津 300191;2.天津理工大学 智能计算及软件新技术天津市重点实验室,天津 300191; 3.国家计算机病毒应急处理中心,天津 300457)
1 引言
随着互联网的普及,安全问题变得越来越严重。据CNCERT/CC2008年度上半年报告[1]显示:在境内外控制者利用木马控制端对主机进行控制的事件中,木马控制端IP地址总数为280 068个,被控制端IP地址总数为1 485 868个,我国大陆地区302 526个IP地址的主机被植入木马。
针对这一现状,学术界已进行了很多相关研究并先后提出了很多方法来尝试解决这一问题。近年来,基于P2P模型的僵尸网络逐渐发展壮大起来,因此对P2P模型僵尸网络的研究也成为了网络安全领域的热点话题[2,3],目前国内外的僵尸网络检测技术可以分为如下3类[4]。
1) 基于蜜罐的检测方法。蜜罐技术通过模拟真实主机来诱骗攻击者,从而捕获僵尸程序样本,然后通过逆向工程等手段获取并分析隐藏在代码中的僵尸网络相关信息。文献[5]介绍了诸葛建伟等人设计开发的一种基于高交互式蜜罐技术的恶意代码自动捕获器——HoneyBow,它能够高效地对互联网上实际传播的恶意代码和网络攻击进行自动捕获,并提交到集中的样本服务器上。以该系统研究成果为基础,CNCERT/CC在全国15个省市自治区部署了一个名为Matrix的分布式蜜网试验系统[6],用于捕获恶意代码和跟踪僵尸网络。蜜罐技术可以检测未知类型的僵尸程序,但是部署成本较高,而且对于已经停止传播的僵尸网络无法检测[7]。
此外,蜜罐系统还必须能够较好地伪装自己以不被攻击者识破,文献[8]重点研究了这一问题。
2) 基于网络异常的检测方法。此类方法着眼于僵尸网络中的受控主机(僵尸)在接受来自控制端的命令、发起攻击或进行扫描以求扩散恶意代码等的行为与其他正常网络应用的不同,但由于忽略数据流的具体内容而造成误报漏报率较高,而且有可能局限于特定结构的僵尸网络,不能实时检测。
Guofei Gu等人在文献[9]中设计并实现了通过对网络流量进行聚类分析从而达到与协议和结构无关的僵尸网络检测器 BotMinner,但是这种检测方法的准确度不够理想,误报、漏报率较高,检测速度也无法达到实时在线检测的要求。
Chet Langin等人提出一种基于自组映射(SOM)的恶意流量检测方法[10]:将边缘防火墙的日志记录作为向量输入到自组映射中,经过运算之后得出结果,可以识别未知僵尸通信,其缺点是依赖于边缘网络的防火墙,生成的报告也有明显的延迟。
3) 基于流分类技术的检测方法。与基于网络异常的检测方法不同,基于流分类技术的僵尸网络监测方法主要根据数据流的特点将其区分为各种网络应用,包括正常的和异常的。该类方法大多误报漏报率较低,其难点在于找到合适的依据对网络数据流进行分类。
Sang-Kyun Noh等人介绍了一种可用于检测P2P僵尸网络的多阶段流模型[11],这一颇具新意的方法将网络流作为输入对象,克服了对边缘网络的依赖性,但使用了马尔科夫链等复杂模型,对网络数据流量处理能力有限,并且误报率较高。
Tao Wang等人采用流聚合[12]的思想,利用僵尸主机间通信的相似性和同步性特点来实时在线检测僵尸主机,可以检测出未知类型的僵尸流量,但是这一模型需要白名单的支持,在系统白名单尚不健全时,误报率会比较高。
相比之下,使用特征串过滤器对数据分组进行过滤的僵尸网络检测方法的优点是准确性高、健壮性好、具有分类功能等[13],并且可以检测已经停止传播的僵尸程序。使用特征码过滤器的方法检测僵尸网络是从网络通信流量分析的角度,通过在网络拓扑中的关键节点部署数据分组监听软件或设备,按照预定义的特征码对捕获到的数据分组进行匹配,一旦匹配成功则说明网络上某对IP地址主机之间存在着被检测的网络应用,如僵尸程序。这一方法的缺点是对数据分组过滤系统的性能要求较高,并且传统的分组过滤系统的特征码一般都是基于单一数据分组的,当某种僵尸程序的数据分组特征过于短小或不够明显时,如果仍然使用单分组特征码进行过滤,可能单位时间内会匹配大量的正常网络应用的数据分组,这无疑大大降低了检测结果的准确性。
针对这一问题,本文提出了一种基于组特征过滤器的僵尸网络检测方法,可以有效地应对特征码的非单分组分布,准确找出使用了待检测网络应用的IP主机,并且用实验证明该方法也可以对已经停止传播的僵尸网络进行准确检测,算法空间复杂度为O(tmn)。表1对上述几种类型的僵尸网络检测方法做了简单对比。

表1 几种僵尸网络检测方法对比
2 僵尸数据分组特征的多分组分布
僵尸网络客户端为了使自己不被用户和反病毒软件发现,一般都要将自己隐藏起来,这里所提到的隐藏包括2方面内容:一方面是对文件系统的隐藏,僵尸客户端大多通过进程注入、修改自身的非关键代码等方式来实现,这种隐藏可以逃避反病毒软件的检测。另一方面是对网络的隐藏,由于僵尸客户端都需要与位于互联网上的僵尸控制端进行网络通信,因此僵尸客户端大多通过端口重用、反弹连接等方法来逃避防火墙的拦截。无论何种隐藏,由于对于僵尸主机来说网络通信总是必要的,所以可以通过分析其数据分组的特征字串来实现从网络上对僵尸网络的检测。这种方法的依据是:僵尸客户端可以接受多种不同的命令从而采取相应的动作,所以其数据分组特征是客观存在的,一旦网络上出现一个与预定义特征串相匹配的数据分组,则可以认定该数据分组所指出的一对IP主机属于某个僵尸网络。
通过研究发现一些僵尸客户端开始从数据分组层隐藏自己,具体表现为特征串简短化,并分散于多个数据分组中。在这种情况下如果仍然使用单分组特征串进行过滤,由于特征串长度过短而造成的可区分度大幅下降,造成短时间内有大量数据分组发生匹配,而这些数据分组大多是正常的网络应用所产生的,从而使得过滤结果没有实际意义,也丧失了基于数据分组过滤的僵尸主机检测方法原本的精确性。
3 基于组特征过滤器的僵尸主机检测
为了解决在僵尸数据分组特征简短化和多分组分布的情况下数据分组过滤精确度大幅降低的问题,本文提出了一种新的基于组特征过滤器的检测方法。
3.1 组特征过滤器
定义 1 设集合 S={s1,s2,…,sn,a} ,n ∈N+,a∈N+,1≤a≤n,若si与sj(1≤i,j≤n)是2个不同的数据分组过滤特征串,a是一固定常数,那么集合S称为组特征过滤器,si或sj称为组特征过滤器S的成员特征,正整数n称为组特征过滤器S的维度,a称为组特征过滤器S的警戒值。
当使用维度为n的组特征过滤器S对一个数据分组进行过滤匹配时,等价于使用 si(si∈ S ,1≤i≤n)对该数据分组逐一进行过滤匹配,并将匹配结果写入S所对应的位向量表中。
3.2 位向量表
定义2 有m个n维向量构成的集合V={v1,v2,…,vm},m∈N+,若对于任意vi=(vi1,vi2,…,vin)(vi∈V,1≤i≤m,i∈N+)的每一个分量vij(1≤j≤n)的值都满足vij∈{0,1},即向量vi是位向量,那么集合V称为位向量表。
实际使用时,位向量表将与组特征过滤器协同工作,位向量表中的一个向量对应一个IP地址,用于保存一个组特征过滤器的数据分组匹配结果。当有多于一个的组特征过滤器工作时,就需要多个位向量表分别与之对应。
3.3 动态过滤器
定义3 当确定某对IP主机之间存在僵尸通信,则新增一个过滤器 s′={IPs,I Pd,TC,TH}用于过滤该对IP主机之间的通信数据,其中IPs表示源IP地址,IPd表示目的IP地址,TC表示s′的生成时间,TH表示s′的最后一次匹配时间,s′称为动态过滤器。
3.4 基于组特征过滤器系统工作机制
当数据分组与一个组特征过滤器的发生匹配(即与一个成员特征发生匹配)时,应当将匹配结果保存起来。保存发生匹配的数据分组的所有内容显然是不现实的,而如果只保存数据分组的源 IP地址和目的IP地址将节省很大的空间。事实上,网络管理员由于自身管理权限有限,往往难以对来自外网的主机施加干预,而对内网主机拥有较高的管理权限。因此在没有断定某台主机上运行了僵尸客户端之前只需记录数据分组的内网IP地址,当匹配了多次并足以断言一对 IP地址的主机在进行僵尸通信时再同时保存源IP地址和目的IP地址,甚至数据分组全文。组特征过滤器系统工作流程。

1) 建立内网IP地址与位向量表中位向量的映射关系。例如,对于一个B类子网,使用以下散列函数建立映射关系:式(1)中,IP_Addr表示内网中任意一个IP地址,Byte1表示一个IP地址从低位到高位的第一字节,同理Byte2表示第二字节,函数MAKEWORD将 2个单字节数拼凑成为1个双字节数。内网中一个IP地址的散列结果HashIndex就是这个地址所对应的位向量表中位向量的序号。
2) 若个数据分组Pck与维度为n,警戒值为a的组特征过滤器S发生匹配,且相匹配的成员特征是si,则找到数据分组Pck的内网端IP地址,并将IP地址带入式(1)中得到散列值HashIndex,根据HashIndex的值将位向量表V中的位向量vHashIndex的第i个分量置为1,然后计算。
4) 显然,s′应在S之前尝试与数据分组进行匹配。当存在多个动态过滤器时,这一点仍然适用。一旦数据分组与任何一个过滤器发生匹配,则应立即停止与后续过滤器的尝试匹配步骤。
若同时存在t个组特征过滤器 S1,S2,…,St(t > 1,t ∈ N+),则应同时具备相同个数的位向量表 V1,V2,…,Vt(t > 1,t ∈ N+)与之分别对应。
设动态过滤器s′={IPs,I Pd,TC,TH}是由组特征过滤器S生成的,S所对应的位向量表是V,假设IPs是内网IP地址,由式(1)得出的IPs散列值为Hs',则S的匹配信息保存于位向量vHs'中。指定时间差阈值Tt,如果一个数据分组 Pck与s′发生匹配,则首先置TH为系统当前时间,并判断TH-TC≤Tt是否成立,若成立,则将Pck保存,若不成立,则Pck不必保存,同时应删除s′,并将位向量vHs'置为零向量。这样做的目的在于避免当IPs与IPd之间的僵尸通信已经结束时,过滤系统仍然保存过多的无用数据分组。为了更好地达到这一目的,可以指定匹配次数阈值Ht,当s′匹配了足够多次后就将其删除,并将位向量vHs'置为零向量。当过滤系统只为能识别内网某IP进行了僵尸通信,而不必还原其通信数据时,这一设置将节省出一定的内存空间。
组特征过滤器系统模型如图1所示。
4 算法分析
4.1 复杂度分析
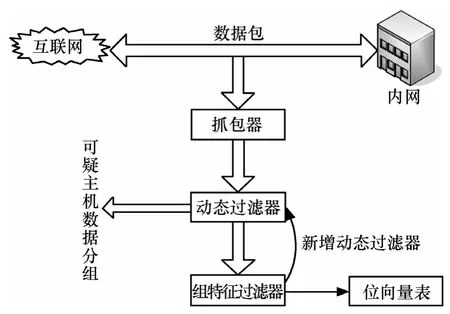
图1 组特征过滤器系统模型
由上述的过滤步骤不难看出,基于组特征过滤器的过滤算法与传统的单分组特征过滤算法相比,增加了位向量表用于保存每个组特征过滤器的匹配结果信息。设式(1)的值域中共有m(m ≥1,m ∈N+)个 可 能 的 值 , 与 维 度 为n(n ≥1,n ∈N+)的组特征向量过滤器Si所对应的位向量表是Vi,则有 Vi={vi1,vi2,…,vim},其中,对于每个 vik(1≤k≤m,k ∈ N+),都满足dim(vik)=n。因此,由Si所引入的空间复杂度为O(mn),若在系统中同时存在t个组特征过滤器,相应的空间复杂度增加到O(tmn)。
实际上,因为计算机最小处理单位为字节(byte),1 byte=8 bit,所以可以用1 byte的空间来存储一个8维位向量,并且使每个位向量的维度是8的整数倍,即满足dim(vik)=8×n/8。于是对于一个B类IP地址网段,与维度为 n(n ≥1,n ∈N+)的组特征向量过滤器Si对应的位向量表Vi所需的存储空间约为
MSi=65535×8×n/8bit=65535×n/8byte
一般情况下,维度n≤8时已能满足大多数需求,因此根据上式可知Vi所需存储空间约为65 535byte,即 64kbyte。若在系统中同时存在t个组特征过滤器,相应的所需空间64 t kbyte。
显然,在基于组特征过滤器的僵尸网络检测系统中,传统的单分组匹配算法仍然适用,所以不会改变过滤系统的时间复杂度。
4.2 对传统单分组匹配算法的兼容性
基于组特征过滤器的僵尸主机检测算法将检测对象由传统的数据分组间接转换为IP地址对,并且可以将一个传统的单分组过滤器转换为组特征过滤器,但这一转换往往是不可逆的。如果一个组特征过滤器S只有一个成员特征si,那么S等价于si所表示的单分组过滤器。
5 实验及结果分析
灰鸽子是国内一款“著名”远程控制软件,也是黑客们常用的后门软件,其主要功能有远程文件传输、执行,文件目录、进程列表的获取,截获屏幕等。RAdmin也是一款常见的远程控制型僵尸软件,其功能与灰鸽子基本相似,但影响范围和破坏力都略逊色于灰鸽子。通过研究发现,灰鸽子的通信流量可以通过单分组特征串来识别,而 RAdmin的通信数据分组单分组特征极不明显,且极易与正常流量相混淆,但是其数据分组之间存在明显的联系,因此可以使用组特征过滤器的方法来识别RAdmin的通信流量。
为验证方法的有效性,搭建了如图2所示的实验环境。

图2 实验环境
在IP为202.113.76.97的主机A上同时安装了灰鸽子控制端程序和RAdmin控制端程序,在IP为202.113.76.119的主机B上安装了灰鸽子受控端程序,在 IP为 202.113.76.115的主机 C上安装了RAdmin受控端程序,另有正常主机D~F。实验中主机B~F同时进行不间断的局域网文件传输,用以模拟正常流量。
按照上述特征串,针对灰鸽子建立了有1个成员特征的组特征过滤器并设置过滤器警戒值为 1;对于RAdmin建立了有8个成员的组特征过滤器,并设置过滤器警戒值为5。


指定B~F为内网主机,A为外网主机。实验开始后,先后在主机A上发现主机B和C都成功连接到了相应的控制端程序上,此时开启研发的数据分组检测工具BotCapD,之后利用安装在A上的灰鸽子控制端和RAdmin控制端分别给B、C主机发送一些控制命令,如传输、执行文件,监视屏幕等。灰鸽子控制端发送完一次控制命令后,BotCapD已经检测出网络中 2个主机之间存在疑似灰鸽子流量;RAdmin控制端在发送完两次命令后也被成功检测。检测结果如图3、图4所示。
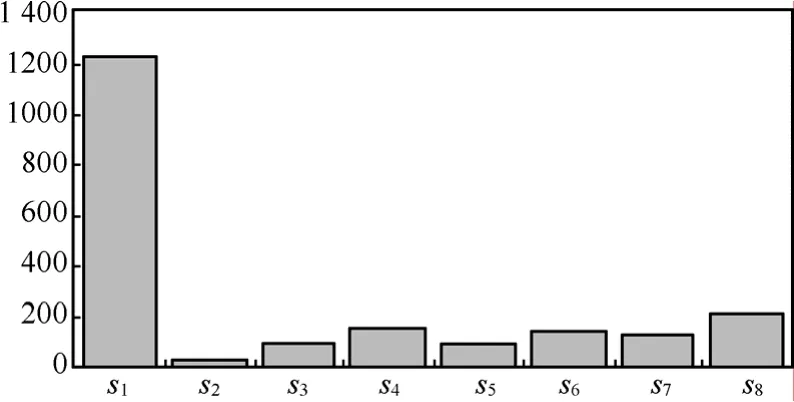
图3 Radmin组特征过滤器各成员特征匹配次数

图4 BotCapD对灰鸽子和RAdmin主机通信的检测结果
从图3中可以看出,在RAdmin的组特征的各个成员特征中 s1的匹配次数明显高于其他各成员,这是由于实验过程用于模拟正常流量的局域网文件传输数据分组大量与 s1发生匹配,但同时存在其他7个成员特征将s1的匹配失误所产生的负面影响减至最低。事实上,s2~s8也有可能存在匹配失误,但是考虑到只有 RAdmin的流量数据分组完整具有s1~s8全部特征,因此与它们匹配的主机对的集合的交集就是进行 RAdmin通信的一对主机。由于警戒值设置为5,所以上述实验中取了5个成员特征匹配集合的交集实现了对RAdmin通信流量的检测。如果从系统效率的角度考虑,s1匹配失误过多使得效率降低,应找到更适合的特征串替换s1。
实验证明,使用组特征过滤的方法时,可以通过只设置一个成员特征来实现单分组特征过滤;也可以设置一组成员特征来实现组过滤,并且在不需要设计开发新的模式匹配算法的前提之下实现了对僵尸主机间的通信数据的识别,进而检测出僵尸主机,同时,检测系统的内存占用和 CPU占用都在可接受范围内。
通过大量实验分析各种远程控制型僵尸通信时所用的内部协议,包括上兴远控(又名PCShare)、Boer、宁瑞、小熊远控(又名 Bear)、冰河等远程控制型僵尸主机通信找到了它们的通信特征,建立了相应的组特征库。
为了验证方法的有效性,在天津教育城域网中部署了 BotCapD,通过流量镜像对主干网上的部分流量进行僵尸主机检测,平均流量在 600~800Mbit/s之间。图5给出了BotCapD连续运行1个月后的检测结果,图中连线的汇聚点为疑似僵尸网络控制端主机。通过IP地址定位查询,在天津市教育网中找到了该主机,通过使用多种主机安全软件对该主机进行彻底查毒,查找到并删除了木马程序。在删除木马程序之后,BotCapD没有再捕捉到该主机的异常通信流量。实验证明组特征过滤的方法可以准确地检测出远程控制型僵尸程序的通信。
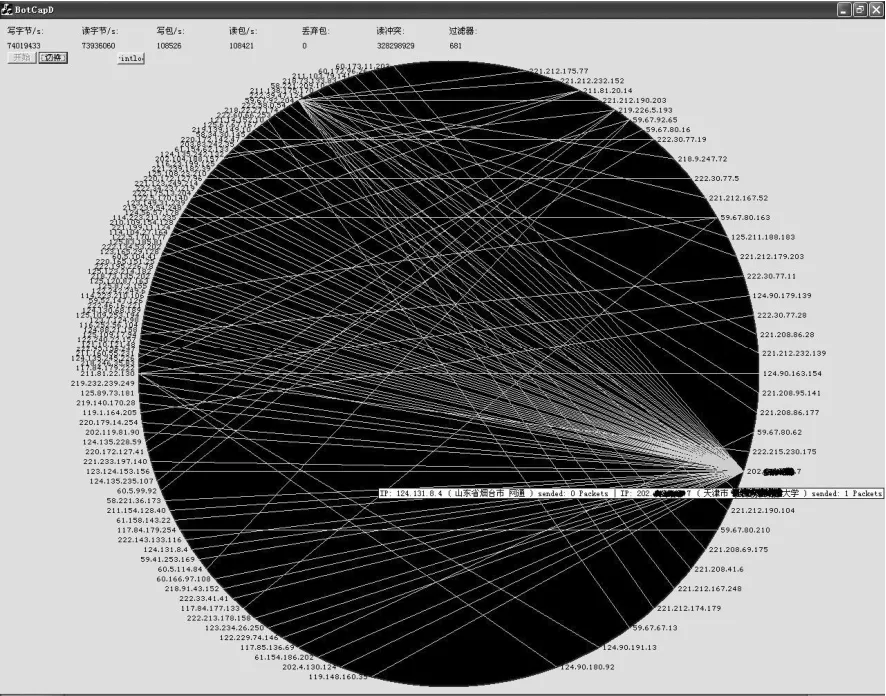
图5 BotCapD对天津教育城域网的流量检测
总体来说,由于受软件开发水平所限,很多僵尸通信数据分组不具备一定的协议格式,但如果将多个交互数据分组视作一组,却往往能体现出某种特异性。组特征过滤的思想正是利用了这一点。另一方面,一些影响较为广泛的远程控制僵尸系统在通信时都严格遵循其内部协议,每个数据分组都含有特征串,此时若能将一个特征串单独视为一组,那么显然也可以使用这样一个组特征过滤器来检测僵尸通信流量。
6 结束语
本文所介绍的基于组特征过滤器的僵尸网络检测方法,以增加O(tmn)在特征串较短,且分散于多个数据分组情况下的僵尸通信识别问题。同时,该方法可以实时对网络流量进行检测,能够即时生成检测报告。此外,检测系统允许部署在较大规模网络的主干网上,且不依赖于边缘网络设备,对各种网络协议上的僵尸通信流量都可以准确检测,并能够识别出具体的僵尸客户端。实验也验证了该检测方法的可行性、准确性和高效性。
但是,随着特征库的不断增长,检测系统的整体性能可能会有所下降,对资源的占用也会逐渐增加,另外,系统对新出现的僵尸通信无法识别,这也是 DPI算法的主要缺陷。因此,如何改进检测策略以尽量减少检测系统对资源的占用从而保证检测效率,如何在发现新的僵尸通信流量后能尽量方便地添加到检测系统中,将是下一步需要解决的问题。
[1] CNCERT/CC.CNCERT/CC Report of Network Security of First Half of 2008[R].2008.
[2] GRIZZARD J B,SHARMA V,NUNNERY C.Peer-to-peer botnets:overview and case study[A].Proc of the 1st Workshop on Hot Topics in Understanding Botnets(Hot-Bots 2007)[C] Boston,2007.
[3] DONG K K,LIU Y.Detection of peer-to-peer botnets[A].Information Security and Communications Privacy[C].2008.34-36.
[4] LU W,Mahbod tavallaee.botcop: an online botnet traffic classifier[A].Communication Networks and Services Research Conference,2009.CNSR '09[C].Seventh Annual,2009.
[5] ZHUGE J W,HAN X H,et al.Honeybow: an automated malware collection tool based on the high-interaction honeypot principle[J].Journal on Communications,2007,28(12):8-13.
[6] HAN X H,GUO J P.Investigation on the botnets activities[J].Journal on Communications,2007,28(12): 167-172.
[7] XIE K B,CAI W D,CAI J C.Decision tree based detection of botnet flow[A].Information Security and Communications Privacy[C].2008.76-77.
[8] ZOU C C,CUNNINGHAM R.Honeypot-aware advanced botnet construction and maintenance[A].Dependable Systems and Networks,2006.DSN 2006[C].2006,199-208.
[9] GU G F,PERDISCI R,ZHANG J J,et al.BotMiner: clustering analysis of network traffic for protocol and structure- independent botnet detection[A].17th Usenix Security Symposium[C].2008.8-18.
[10] LANGIN C,ZHOU H B,RAHIMI S H.A self-organizing map and its modeling for discovering malignant network traf fi c[A].IEEE Symposium on Computational Intelligence in Cyber Security[C].2009.122-129.
[11] NOH S K,OH J H,LEE J S.Detecting P2P botnets using a multi-phased flow model[A].Third International Conference on Digital Society[C].2009.247-253.
[12] WANG T,YU S Z.Parallel and distributed processing with applications[A].2009 IEEE International Symposium[C].2009.86-93.
[13] JIAN G Y.Research and Implementation of DeeP Packet Inspeetion P2P Flow Based on Heuristic Identification[D].Tianhe District,Guangzhou,Ji'nan University.2008.5.4
