北京居民主观幸福感的实证分析
2010-07-23王华强
王华强
(首都经济贸易大学 统计学院,北京 100070)
0 引言
长期以来,心理学家、社会学家及经济学家对于主观幸福感的研究大多是对客观对应物的度量。通过社会统计学的方法对经济收入、年龄进行描述分析。然而,值得注意的是,抛弃对客观对应物的测量,转而通过生活满意度量表——对生活质量评价的方法更值得研究。Ed Diener和Eunkook Suh曾指出,社会指标(像身心健康、主观幸福感等)与经济指标具有很强的相关关系。而且,社会指标包含的信息超过了经济指标度量里所包含的信息。生活满意度量表并非仅仅依靠对映射的客观对应物,而是个体对主观幸福感作出的总体评价。年龄、收入、地域等只能代表个体的背景状况,财富只是为物质生活质量评价提供了相近的指标,而对主观幸福感作出评价时,这些资料已经在个体意识上形成了长期稳定的资源。因此,对生活质量评价是测度主观幸福感更直接更有效的方法。
1 数据收集及变量选取
为了全面了解北京市城镇居民的生活状况,首都经济贸易大学统计学院进行了北京生活指数的统计调查。2008年通过问卷调查的方式对近千名北京常住居民的幸福状况进行了调查。本文选取的样本包括8个城区的868个样本,结合生活质满意度量表度量幸福度的方法,变量指标选取幸福度(Y)及身心健康状况的评价(X1)、物质条件状况评价(X2)、生活安逸程度评价(X3)、人际关系状况评价(X4)、个人价值实现评价(X5)、家庭生活状况评价(X6)和工作满意程度评价(X7)等7个调查指标。关于幸福度的测量,被调查者需要从1~5做出选择,依次代表很幸福、比较幸福、一般、不太幸福、很不幸福5个选项。生活质量评价变量的度量值是从1到10,随着满意度的增加数值也增加,1为很不满意,10为很满意。
2 数据建模
2.1 建立模型
Logit回归模型是一种概率模型,其因变量为响应变量中某一结果发生与否的概率,自变量为影响该一结果发生的因素[5]。 本文中响应变量幸福度 Y 的取值为 1,2,3,4,5,根据Logit模型原理可以建立多维Logit模型的形式如下:

2.2 模型的检验
模型整体显著性检验是指检验自变量与响应变量的显著相关性。方法上可以通过空模型和全模型构造的广义似然比统计量deviance(残差平方和)来检验显著性,空模型是指除截距项外不包含任何其他的自变量的logit定序回归,全模型是指包含所有自变量的logit定序回归。表1是两个模型在R软件中的方差分析结果:
从表1可以看到,广义似然比统计量为325.3977,P值几乎为0,即高度显著。这说明全模型整体显著,即在所有的自变量中至少有一个因素对主观幸福感有显著影响。为了分别检验各个因素的显著性,对模型的系数卡方检验。结果如表2所示:

表1 两模型方差分析

表2 全模型卡方检验
从表2可以看出,在0.05的显著性水平下,个人价值实现评价没有通过显著性检验,不能拒绝其对幸福度无显著影响的原假设。表明个人价值实现并不是对幸福度影响显著的因素。
全模型由于加入了全部变量,据以上检验发现存在不显著的变量。理论上回归模型应选择显著性变量并且模型的拟合度最高的模型。在定性回归模型中,拟合优度选择可以通过计算模型的信息指标量AIC。其含义由AIC的定义式AIC=deviance+2df看出,AIC值越低表示模型的拟合优度越高。对本文而言,不同的变量组合可以回归出128种模型。在R中可以自动的根据AIC准则对这些模型进行选择,得出AIC最低的模型。表3为AIC准则下的最优模型:

模型的参数估计(见表3):
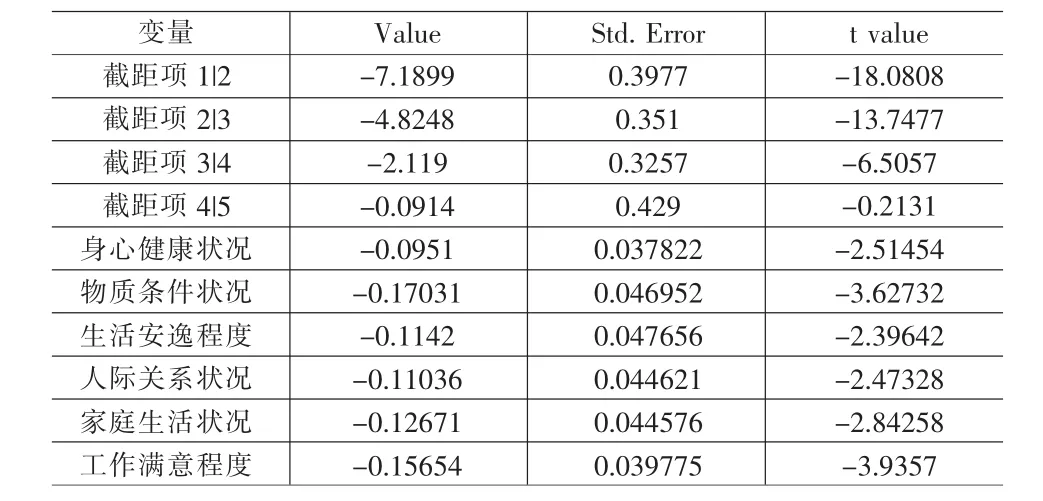
表3 最优模型参数估计

将参数估计值代入模型(2)中,模型的表达式应为:
2.3 模型的评测
模型的预测是指根据上述模型推导出幸福度概率模型,从而一旦某个体对生活质量作出评价便能够计算出该个体在各个幸福度选项上的概率。
贵州黄:观赏石界称国画石或画面石,主要产于黔东浅变质岩地区,石质为元古代黄褐色板岩,分布广,储量大,装饰性强,很有市场开发展价值。
由模型(2),令:
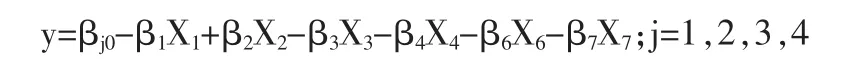
可以得到:

于是,某一幸福度的发生概率模型为:
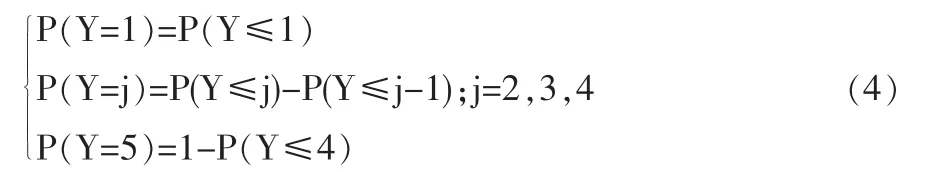
可以根据此概率模型对个体生活质量满意度评价预测其幸福度状况,由于对于每一个个体评价都会计算出各个幸福度上的发生概率,于是假设个体最终选择发生概率最大的幸福度。表4是R软件对调查样本数据的预测与汇总情况。
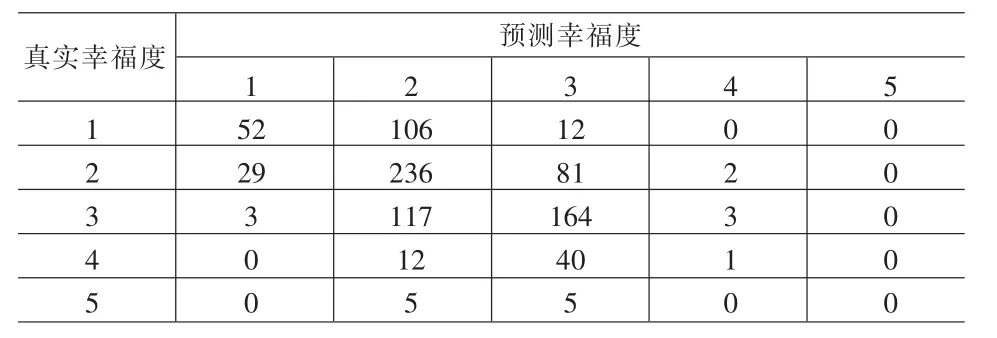
表4 模型预测结果
对角线上的元素为判断正确的样本数,共453个占整个检验样本的453/868=52.2%,预测误差为1个单位的样本个数共376个,占整个检验样本的376/868=43.3%,较大误差的样本个数为39个,占总检验样本的39/868=4.5%。这表明该模型的预测效果比较满意。
2.4 模型的应用——占优比率
Logit模型的一个重要应用是估计占优比率。优势是某一事件发生(成功)的概率与不发生(失败)的概率之比[5]。占优比率模型能够充分利用和反应定序变量的特点,用以分析某一自变量变化导致的优势变动,从而分析响应变量发生概率的变化情况。
根据模型 (1),定义占优比率为:

其中xi1、xi2为某一自变量所取的两个不同的值,在本文即表示生活质量评价某一变量的两个不同的满意度值。OR表示在控制其他自变量变量不变的情况下,x=xi1的优势占x=xi2优势的比率。
由此可以得到下面的占优比率模型:
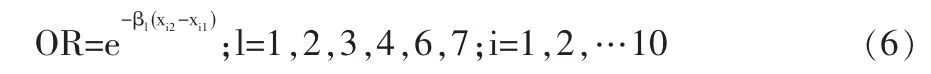
不失一般性,本文只计算相邻满意度值之间的占优比率。当j取不同的值时,优势比率都是一致的。OR表示在控制其他变量不变的条件下,每增加一个满意度导致的幸福度发生概率的变化情况。表5所示为占优比率估计的计算结果。

表5 占优比率估计
由表5可以看出:(1)OR的值均大于1,且置信区间的下线也是严格大于1的。说明各个变量中满意度大的个体的优势大于满意度小的个体的优势。以身心健康状况为例,在控制其他变量不变的情况下,对身心健康满意度高的人更倾向于认为很幸福的概率高于身心健康评价满意度低的人。其他变量可以类似解读。(2)尽管OR值均可在95%的置信区间下大于1,但是其数值仍然在1的附近。这说明尽管各个变量中满意度大的个体的优势大于满意度小的个体的优势,但是这种优势并不大。然而这是由于优势的比较仅在相差一个满意度的条件下,可以预计如果相差增大,这种优势会增大。(3)OR的估计中物质状况的满意度变量的占优值最大,说明相对而言提高物质生活满意度产生的幸福度优势比率大于其他变量,即提高个体物质生活满意度对评价主观幸福感倾向幸福的概率要大于其他变量。
3 结论
与人口统计学的角度不同,本文选择了直接对生活质量评价指标而非客观对应物变量,通过建立模型来研究。
生活质量评价是度量主观幸福感最直接最有效的方法。为了探索主观幸福感的影响因素并探讨提高人们幸福感的方法,本文通过建立逻辑回归模型、统计检验、统计推断等步骤得到拟合优度很好的模型。从中可以得到结论:身心健康状况的评价、物质条件状况评价、生活安逸程度评价、人际关系状况评价、家庭生活状况评价和工作满意程度评价等6个方面成为个体主观幸福感的来源。当人们对这些生活质量评价指标的满意度增大时,居民的主观幸福感就会增强。就北京地区而言,可以从这六个方面入手提高居民的幸福度。
在六个影响因素中,物质条件状况的满意度提高对幸福感倾向最大。这与从人口统计学的研究得到的结论——收入水平的提高增加幸福感——有共同之处。不同的是物质条件状况的范畴更加宽泛,除了收入之外,还有居住状况、交通状况以及其他一些人类生存生活所必需的东西。优越的物质条件越来越成为人们所追求的随着社会的目标,也成为提高人们主观幸福感的源泉。
显而易见,影响因素中身心健康评价的占优比率最小。现阶段,为了摆脱贫困落后的生活状况人们更多的是为工作而忙碌着,对身心健康的关注度显然是最低的。这一原由也解释了工作满意度评价的占优优势位居第二的位置。为了得到更多的报酬,人们的大部分时间用在了工作上,这期间有可能牺牲了身心健康、家庭生活、社交活动等幸福源泉。
相对其他变量来说,人们并不认为人际关系状况的改善能带来很大的幸福感的提升。交流是影响人们情感的重要因素之一,然而分析发现,居民虽然明白这一因素的重要性,但是并不认为由此可以获得很多的幸福感。与社会这个“大家庭”相比,个人家庭的生活状况显得更重要一些。家庭的和睦,亲情的融洽是增强幸福感的重要源泉。家庭是社会的一个细胞,家庭生活状况的提高也有利于促进社会的和谐。生活安逸状况是一个比较广泛的范畴,它与工作、生活、家庭都有关系。从模型中也可以看出,生活安逸状况的占优优势并不十分突出,居中间状况。
[1]吴明霞.30年来西方关于主观幸福感的理论发展[J].心理学动态,2000,(4).
[2]王燕.国内外主观幸福感的研究进展[J].科学对社会的影响,2006,(2).
[3]邢占军.主观幸福感测量研究综述[J].心理科学,2002,(3).
[4]E D Diener,Eunkook Suh.Measuring Quality of Life:Economic,Social,and Subjective Indicators[J].Social Indicators Research,1997,(40).
[5]易丹辉,何铮.Logistic模型及其应用[J].统计与决策,2003,(3).
[6]王汉生.应用商务统计分析[M].北京:北京大学出版社,2008.
[7]田国强,杨立岩.对“幸福—收入之谜”的一个解答[J].经济研究,2006,(11).
