一种基于统计的数字电视信息过滤算法*
2010-06-25刘春英吴德华
刘春英,吴德华,宋 烨
(长沙航空职业技术学院,湖南 长沙 410124)
1 引言
随着数字电视和通信技术的不断发展,用户除了能看到越来越多的电视节目,更能享受到个性化信息服务等数字电视增值业务。但是,用户在享受电视资讯服务的同时,同样受到“信息迷向”和“信息过载”问题的困扰[1]。
虽然数字电视的基本工作方式是广播式的,但其发送数字信息的颗粒度仍然较高,流量仍然很大。如何从用户终端的大量信息中筛选出用户真正需要的信息,已成为这项增值业务能否让用户满意的瓶颈。面对信息流量大而机顶盒存储能力有限的矛盾,信息过滤技术在数字电视的个性化信息服务[2-3]中的应用是推动数字电视增值业务更好、更快发展的必然趋势。因此,迫切需要一个信息过滤系统来满足电视观众日益俱增的个性化需求,实现数字电视平台上的个性化信息服务。
2 数字电视信息过滤与网络信息过滤技术对比
信息过滤的主要任务是将信息源与用户兴趣模型进行比较,根据比较结果过滤掉不相关的信息,选出用户关注的信息。网络信息过滤系统一般包括信息源、过滤部分、用户和用户兴趣模型4个基本组成部分[4]。为了提高过滤的效率与精度,系统还可根据过滤结果提供相应的反馈机制来不断更新用户兴趣模型[5],使用户的信息需求越来越明确,其工作过程见图1。
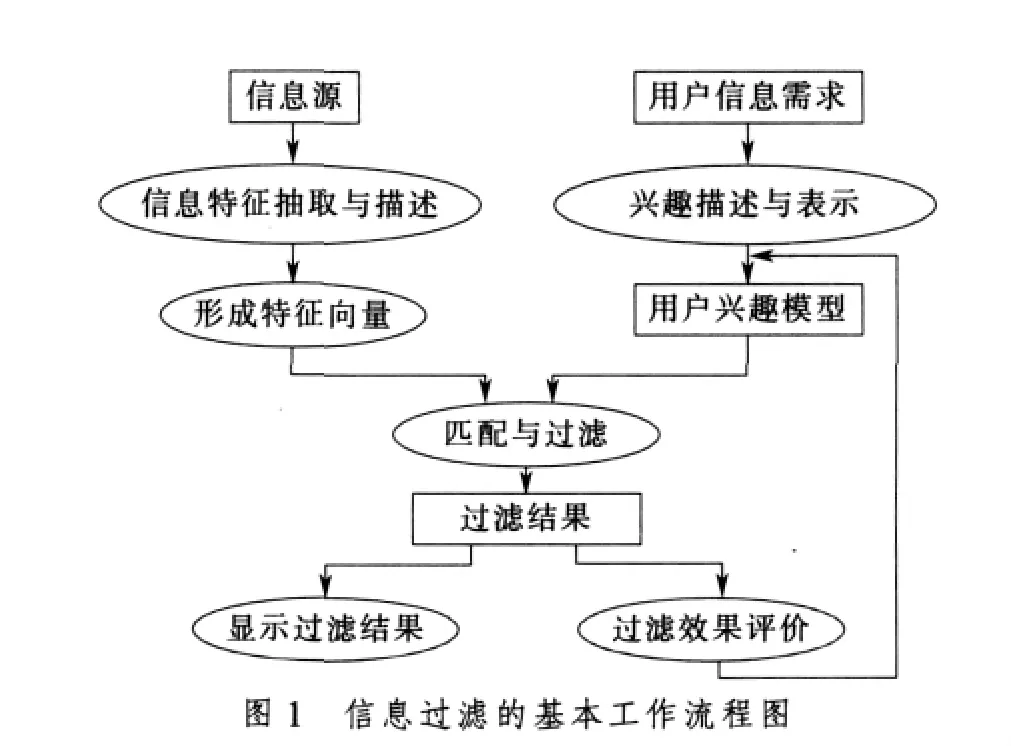
数字电视信息过滤系统在技术上与网络上的信息过滤类似,所不同的是它以广播式信道为基础,具有单向性的特点。而网络上的商业化搜索引擎的搜索对象是半结构化的,工作环境是强大的服务器集群,检索结果也不尽理想。例如,谷歌(Google)的查准率很高,但冗余率也很高,一般只有搜索结果的前几项是用户感兴趣的内容。而数字电视信息过滤系统的处理对象是非结构化的TS码流,工作平台是数字电视终端(目前主要是机顶盒),可利用的软硬件资源都十分有限,不适于使用网络信息过滤技术。另一方面,机顶盒是一个小平台,无法完成信息过滤的所有工作,如中文分词、特征抽取等工作只能在广播网络前端完成。因此,怎样结合数字电视的特点,寻求一种行之有效的用户兴趣模型、精简的信息过滤算法和学习算法是在数字电视中实现信息过滤技术的关键所在。
数字电视信息过滤系统的用户兴趣模型是对用户兴趣的描述,常用的模型主要以文本描述模型为基础,辅以对用户兴趣的描述,构成用户兴趣模型。信息过滤算法在用户兴趣模型与信息源之间进行匹配。用户兴趣学习算法的作用是对用户兴趣模型进行修正。数字电视信息过滤系统的处理对象的特殊性及数字电视终端的软硬件资源的有限性,决定了数字电视信息过滤系统中的信息过滤算法、用户兴趣模型和学习算法不能太复杂。
3 基于统计的数字电视信息过滤算法
根据数字电视的精简性要求及其工作的软硬环境,笔者提出了一种适用于数字电视的信息过滤算法,如图2所示。该过滤算法以向量空间模型为基础,重点是特征向量集的建立和修正以及特征向量匹配算法。索引及索引点击率顺序表则体现了用户兴趣。
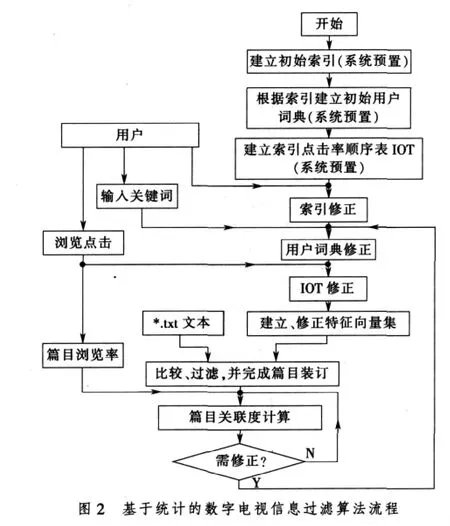
该算法的特点在于信息过滤系统不是简单地从用户词典中取出几个表示用户兴趣的关键词去匹配*.txt文本,而是用这些关键词及其概念范畴的合集组成特征向量集去匹配*.txt文本。由此得到的特征向量集更能体现用户兴趣。这样可以挖掘文本的潜在语义,避免某些包含同义词或多义词的文档被过滤系统遗漏,提高过滤效果。例如,用户词典中的关键词“足球”,它的概念范畴有“射门”、“门将”、“铲球”、“点球”、“进球”等若干词,则(门将,射门,铲球,点球,进球)就是匹配“足球”信息时用的初始特征向量,并且特征向量中每个关键词都带有权重。在用户动作之后,信息过滤系统要能根据用户的动作指令判断初始特征向量中的哪些分量的权重较高,要继续留下;哪些特征向量分量权重低于事先设定的阈值,要从特征向量中剔除掉。
本设计采用的是一种基于统计的方法,即通过统计各关键词的出现频率,来确定特征向量和特征向量分量的权重。此算法基于如下假设:1)用户输入的关键词是有限的;2)预先设计的索引结构和用户词典是合理的;3)用户浏览的点击率能比较可靠地体现用户兴趣。
4 实验结果分析
在本算法的研究过程中,采取了查全率和查准率[6]作为评价指标,对该信息过滤算法的效果进行模拟评价。在实验中,首先人为设置初始特征向量,然后选择了50篇文档进行测试,实验结果如表1所示。
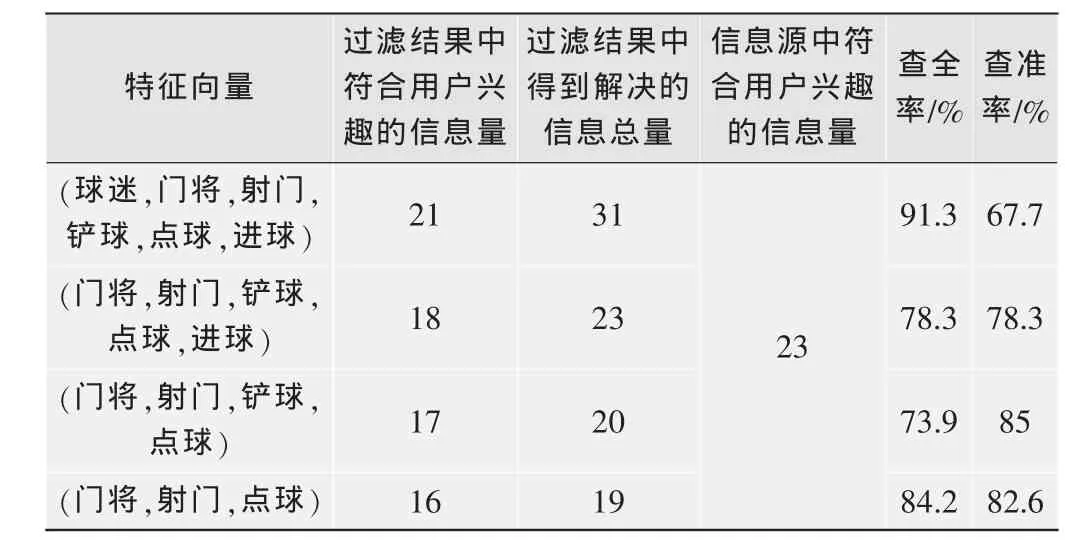
表1 实验结果
开始实验时,初始特征向量由系统预置,用该特征向量匹配出来的信息用户不一定感兴趣。例如,首先设置初始特征向量为(球迷,门将,射门,铲球,点球,进球),实验结果显示查准率很低。随着实验的进行,在用户动作指令的影响下,系统通过计算发现“球迷”的权重最低,将它从特征向量中剔除。依此类推,在特征向量的不断修正中,查全率与查准率逐步好转,最后达到比较理想的效果。
表1表示的只是将特征向量中权重较低的关键词逐一剔除后的情况。实际中,也可通过分析用户的浏览历史,将一些权重很高但并没有出现在初始特征向量的关键词添加进特征向量。当然,用查全率和查准率来评价数字电视中的信息过滤算法的效果存在一定的误差。原因在于:首先,该信息过滤算法设定只返回关联度大于某个固定阈值的信息,阈值的取值不同,返回的信息数量也会不同,因此采用查准率、查全率来衡量过滤效果就会造成误差。再者,数字电视中信息源(TS码流)不断动态变化,会导致计算查全率时无法特别准确地确定信息源中符合用户兴趣的全部信息量,从而无法很精确地计算查全率。
5 小结
为了提高信息过滤的效率和精度,让个性化信息过滤技术真正应用于数字电视,结合数字电视广播的特点,设计了一种适用于数字电视的个性化信息过滤算法,并通过一系列实验证明了该算法的可行性。不过,实验中也存在一些不足,一是用查全率和查准率指标评价该信息过滤算法的过滤效果不是很精确;二是目前没有将该算法加入机顶盒解码芯片进行实际验证,这都需要在今后的研究中继续努力。
[1]延霞.基于信息过滤技术的搜索引擎研究[J].深圳信息职业技术学院学报,2005(3):20-24.
[2]庞雅丽,王彩芬.个性化信息过滤技术[J].甘肃科技,2007(3):124-126.
[3]吴学辉,张敏.个性化信息过滤系统研究[J].重庆科技学院学报,2008(3):96-98.
[4]张园园.基于用户兴趣的个性化搜索引擎的分析与研究[D].秦皇岛:燕山大学,2006.
[5]王翠平.基于用户兴趣度的网络信息过滤模型研究[D].济南:山东师范大学,2007.
[6]牛洪波,丁华福.基于文本分类技术的信息过滤方法的研究[J].信息技术,2007(12):100-102.
