基于语义角色标注的新闻领域复述句识别方法
2010-06-19吴晓锋宗成庆
吴晓锋,宗成庆
(中国科学院自动化研究所模式识别国家重点实验室,北京 100190)
1 引言
从某种意义上讲,复述(Paraphrase)可以看作文本蕴含(Text Entailment)的一个子问题。对于两个语言片段(短语、句子或篇章)A和B,如果能从A的语义中推理出B,那我们说A蕴含B,反之说B蕴含A,而复述则可以看作A蕴含B且B也蕴含A。
最早研究复述的工作见于文献[1],复述在自然语言处理中有许多应用:如在机器翻译中可以借鉴复述识别中的技术处理实时处理遇到的未登录短语[2-5];在自动问答系统中用于识别多种问句形式来提高系统性能[6];在多文档自动摘要系统中用于句子生成、压缩、相似句子识别等等[7-8]。
作为一个独立的问题提出,句子级的复述识别(Paraphrase Recognition)一般指的是对于给定的两个句子,判断其是否在语义上一致,见下面的例子:
(1)Amrozi accused his brother,whom he called“the witness” ,of deliberately distorting his evidence.
(2)Referring to him as only“the witness”,Amrozi accused his brother of deliberately distorting his evidence.
(1)和(2)两个句子是互为复述句,直观地看,虽然单从用词的重合度上看这两个句子很类似,但从句法角度讲它们差别很大;
(3)Armstrong,31,beat testicular cancer that had spread to his lungs and brain.
(4)Armstrong,31,battled testicular cancer that spread to his brain.
(3)和(4)不是复述句,用词重合度也比较大,并且句法也类似,但是第一句包含有一些第二句没有的信息。
本文的工作主要致力于句子级别的复述识别方法研究。我们提出了如下方法:采用经过语义角色标注后的信息为特征,然后通过机器学习算法来识别复述句。虽然文献[9]也曾通过语义角色标注来识别复述句,但本文将从一个新的角度来获取特征,并考虑了新闻语句本身的特点。实验证明,本文的方法能够取得满意的结果。
论文其余部分如下组织:第2节介绍前人在复述识别上的相关工作,第3节介绍本文的设计思路及语义角色工具包SRL,第4节介绍相关语料和实验结果,最后一节为本文的结论。
2 相关工作
我们将复述识别的方法大致分为三类,一种是基于词集信息的,第二种是基于句法信息的,第三种是基于深层语义的。下面从这三个方面简要介绍前人的相关工作。
2.1 基于词集信息的方法
虽然复述问题的提出是鼓励学者从语义角度寻找判断两个句子是否可以相互替代的方法,但因为语义角色标注正确率有待提高,所以从实用的角度,还是有许多学者尝试用表层信息来解决这个问题。基于词集的方法中向量模型是最主要的方法,这种方法广泛应用于文本分类,信息检索,以及句子相似度计算,在此方法上的改进一般包括:去停用词、词干化(Stemming)、POS标注以及词义扩展等。
文献[10]在词集的基本思想下,引入基于WordNet[11]的世界知识,并且将传统的词到词的相似性计算方法扩展到文本到文本。其方法是将两段文本的相似性定义成了文本中名词和动词的加权函数,以及从别的语料中得到的倒排文档频率。该作者在有监督和无监督条件下分别测试了该扩展方法,取得了比较明显的效果。
在机器翻译中的自动评测启发下(以BLEU[12]为例,其核心思想是计算n元文法匹配的对数几何平均),文献[13]采用机器翻译中常用的自动评测机制BLEU、NIST、WER以及PER来提取特征对分类器进行训练,并进行句子的语义相似性计算。
另外有基于隐含语义标题(LSI)[12]的计算相似度方法,但LSI缺乏合理的物理解释,并且计算复杂度较高。
基于词集信息的方法往往简单、实用,但是很明显,这样做违背了复述这个问题提出的初衷。单纯采用词集信息,不能也肯定不会达到很好的效果。
2.2 基于句法信息的方法
两个意思相近的句子虽然有可能在句法上有差异,但是其内部子结构往往能找到很多相似之处,而且,依存句法和语义表示有一定的相似性,所以有不少学者试图在句法层面上寻找复述问题的解决办法。
文献[14]提出了使用基于反向转换文法(ITG)为复述问题建模的方法。简单讲,ITG实际上是面向双语的上下文无关文法,其目的是让双语平行语料分析的鲁棒性最大化,而不是验证语料的合法性,从而应用于平行语料的标注,包括划界、对齐、切分等[12]。借助ITG模型,文献[14]没有采用任何外部知识,而是仅仅凭借句法层面上的相似就取得了不错的效果。
文献[15]提出了一种基于词汇—句法的方法,该方法要求判断蕴含时,不但要比较两句话词汇上的一致性,还要比较句法上的一致性。这种词汇—句法关系包括由词形变化引起的句法改变、动词的被动到主动的变化、共指等等。通过实验,文献[15]证明词汇—句法方法优于仅仅基于词汇的方法。
文献[16]系统归纳了17个特征用于训练分类器来识别复述句。这17个特征中前9个为词汇特征,10~15个为依存句法特征,16~17个为句长特征。
文献[17]的理论假设是:如果两个句子是依存句,则它们的句法树虽然可以允许有不同,但总体应该对齐的比不是依存句的好。文献[17]结合词汇、句法信息,采用准同步依存文法(Quasisynchronous Dependency Grammar)建模。
文献[18]采用了依存句法分析将被动句式变为主动句式,然后采用如编辑距离、词汇相似度、以及类似于BLEU的n元文法作为特征进行训练。
从句法的角度尝试复述问题比单纯从词汇的角度有说服力,而且效果也普遍比后者好。可是句法层毕竟离语义层还有很大差距,使用句法特征也都只能集中在句法的某个片段上,无法从整体句法树上寻找句子间的相似性。
2.3 基于深层语义分析的方法
文献[9]是基于语义角色标注的复述识别方法,文中不再单纯用词片段或句法树片段作为信息单位,而是用基于 PropBank[19]的谓词论元结构(Predicate Argument Structure,结构化地表示一个动词谓词及其参量——也就是论元,见例句1)。这种结构可以很好地表示动作、概念及其相互关系。而单纯用动词、名词来表示这个含义有可能面临相同的词集但却不同意义的情况(如:“猫吃老鼠”和“老鼠吃猫”意义正好相反),例句1:

文献[9]的系统流程图见图1。首先将句子对用Charniak句法分析器[20]进行句法分析,并用语义角色标注工具ASSERT[21]进行语义标注,找到句子里的谓词论元结构;然后通过贪婪算法寻找匹配的谓词论元结构,在这个过程中用到了外部词库;没有匹配上的其他成分被送进一个有监督分类器,来判断这些成分是否为重要成分,并做出是否这两个句子互为复述的判断。
送入分类器的特征有两类:一类是句法树路径特征,指的是在句法树上的未匹配的单元与最近的有公共父节点的匹配单元之间的距离。文献[9]的作者认为这个特征可以在一定程度上表征这个未匹配部分的重要性。另一类是谓词论元结构中谓词,也就是动词之间的相似性。
基于深层语义分析的方法相对较少,其原因之一是语义角色标注本身正确率有待提高。虽然如此,从语义层考虑复述问题,毕竟最合乎逻辑。我们认为,要想做到真正实用的句子复述识别,必须要从这个角度着手加以研究。

图1 文献[9]方法流程
3 论文动因及设计思路
3.1 论文动因
我们分析了文献[9]中采用的方法,认为其主要针对情况是论元互换(类似于例句1),以及主动语态和被动语态等,这些现象从句法分析以及词汇分析上不易得出正确的语义。因为ASSERT语义角色工具包只能保证谓词的arg0和arg1的一致性,所以其方法仅仅能识别最基本的谓词以及这个谓词的发起者和接收者(arg0,arg1),并没有利用更多的语义角色标注信息识别句子里的其他成分。然而现实中很多复述问题要面临的情况非常复杂,比如一个单纯的补语或状语的不同,就有可能导致两个极为相似的句子不称其为复述:如“我在家吃饭”和“我在学校吃饭”。这些情况恰恰在新闻语料中非常常见,也是新闻语料的一个特点。
为了得到更丰富的语义角色,我们选用伊利诺伊斯大学认知计算组(Cognitive Computational Group,UIUC)的语义角色标注工具包SRL。SRL工具包有比较好的语义角色标注效果,对时间、地点、数字、指代等都有很好的识别结果,其标注信息见表1。
图2给出了采用SRL标注好的两个复述句。这两句话均来自微软的复述语料库(Microsoft Paraphrase Corpus,MSR[22])。以图2a为例,SRL针对每一个动词(包括publish,offer,add)给出了谓词论元结构,也就是着色的三列,其中不同的颜色代表不同的论元。

表1 RSL中的标注
如动词publish,其主语A0为 They,宾语A1为an advertisement on the internet。另外SRL还清楚地找到了时间状语 on July 4,以及状语offering cargo for sale。
图2b给出了这句话的一个复述。可以看到,虽然这两句话句法结构有较大差异,但是在publish的论元中除了A0不一致外,其他语义角色都一致。

图2a SRL例句

图2b SRL例句
MSR语料均来自于不同的新闻文稿,所以,虽然在a句中出现了无法消解的代词They,以及后面的代词he,但是因为新闻背景关系,在其他语义角色相同或大致相同的情况下,还是认为这两句话是复述——这在MSR语料中是很常见的现象。
从新闻语句自身特点看,很多新闻句可能主、谓、宾都一致,但是不同的时间、不同的地点以及不同的宾补成分,都可能使得这两句看似相似的句子实际上在诉说不同的事情。分析这种情况,我们认为,单纯从由谓词、A0、A1论元组成的元组为单位寻找匹配并不能很好地解决新闻语句的复述识别问题,句子的各种修饰成分在复述句识别中同样占有很重要的作用。
3.2 设计思路
复述句识别方法多数采用有监督的训练方法,事实上几乎所有人的工作都集中在如何找到最能反应这个问题本质的特征上。在文献[9]的基础上,我们针对新闻复述句的特点,提出了一种基于语义角色标注的有监督新闻复述句识别方法,其流程见图3,下面介绍每个模块的功能,并给出选用的特征。

图3 系统流程
首先将复述句输入词频特征提取模块。在词频特征提取模块之中,我们首先对句子进行了去停词、词干化的工作,然后我们考虑了如下几个特征,我们称之为基本特征。
基本特征(BF)
BF1句长差特征:两个句子长度相减所得的差,可以为正值或负值。
BF2绝对句长差特征:对句长差特征取绝对值。
这两个特征参考了文献[16]。
BF3句子相似度特征:我们用如下公式(1)计算相似度。

BF4基于WordNet的相似度特征:对公式(1)中的分子,我们对词干化以前的词采用 WordNet 3.0计算相似度,为句子中的每个词寻找其对应复述句中相似度分值最高的词,然后将这些相似度叠加并乘以2。
同时我们也将句子输入UIUC的SRL标注工具模块,进行语义角色标注。得到标注好语义角色的句子后,将其输入SRL特征提取模块,我们提取了如下一些特征,我们称之为语义特征。
语义特征(SF)
SF1谓词数差特征:两句话的谓词数相减所得,可以为正值或负值。
SF2匹配的谓词数量特征:两句话中有多少谓词可以匹配。我们经验地规定两个谓词在WordNet上的相似度超过0.5即为匹配成功,我们最多寻找三对最相似的谓词。
SF3未匹配的谓词是否被其他谓词的论元覆盖:我们经验地判定一句话中越是重要的部分被各个谓词论元覆盖的次数越多。以图2a为例,T hey这个主语被三个论元所覆盖:publish的A0,offer的A0,以及add的A1,而对于谓词add以及其论元A0都只被覆盖了一次。
对于匹配的谓词,我们按照表1寻找是否有匹配的论元,并给出如下一组特征。
SF4句子1中的论元特征:第一句话中是否包含某个论元成分。这是个0、1特征。
SF5句子2中的论元特征:第二句话中是否包含某个论元成分,同上。这两个特征反应了论元的匹配情况。
SF6匹配的论元成分的相似度:我们用公式(2)计算相似度。

其中,Ai=1,2表示句子1和2在某个谓词下相对应的论元。和计算相似度特征的方法一样,我们这里也采用了WordNet外部知识。对于不存在的论元成分,这个特征取零。这个特征会产生3×15个子特征,它们的设立是考虑到不同的论元成分,哪怕是一些修饰成分,在新闻语料中都可能扮演很重要的角色这个特点。
SF7代词特征:我们从SRL中得出的结果并没有考虑指代消解,我们用这个特征给出某个论元成分中是否包含代词。给出这个特征,是因为考虑到新闻语料中的复述句往往来自不同的新闻机构或者不同的日期,单纯从孤立的句子上看,会有一些无法消解的指代,比如图2a中的 They和he。图2a和2b这两句话在新闻背景下是复述句,但是严格意义上说,它们不应该是互为复述句的。
SF8扩展的句子相似度特征:在语义角色标注后,我们引入了一个新的计算句子相似度方法,其公式如下:
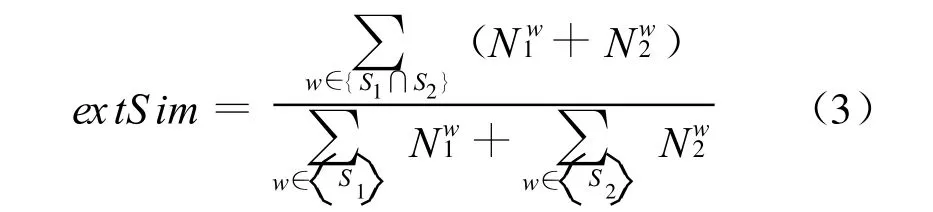
公式(3)中的Nwi表示有多少个谓词论元成分覆盖了这个词,如图2a中的offering为3,added为1。选用这个特征也是基于这样直观的假设:越是重要的成分被覆盖的越多。
这些特征的设计都是充分考虑了新闻领域中语句识别复述与普通领域的语句复述的不同。
我们将得到的特征直接送入SVM分类器进行训练和测试,并由SVM输出最终结果。
4 实验
这一部分介绍我们采用语料和实验结果。
4.1 MSR语料介绍
我们的实验里采用的是MSR语料[22]。MSR是一个用于一般用途的复述语料库,它来源于在线新闻网站。其创建分两步,第一步是由仅仅依靠编辑距离过滤词汇上不相似的句对,这样共得到了5801 个句子对;第二步为人工标注,其中3900 个句子对标为正例,其余为反例。这样这个语料中的句子单从词汇上看句对间相似度很大,给复述识别任务提出了更高的要求。第一节中的例子里给出的两组句子均来自MSR,其中第二个例子稍微做了一点改动。
4.2 评测标准
为便于比较,我们的评测采用F1值作为评测标准,和文献[9]的评测方法一致,见公式(4)。

4.3 实验及结果
在MSR语料中,训练集有2753 个正例,1323 个反例;测试集中有1147 个正例,578个反例。从训练集抽取特征后我们用SVM分类器进行训练,然后在测试集上做测试。
我们选用基于语义角色标注的方法Qiu[9]和基于句法的方法Zhang[18]以及Wu[14]作为Baseline。在实验中,我们先测试了传统的基于基本特征(BF)的结果,然后给出基于语义特征(SF)的结果,最后将这二者结合给出SF+BF的结果。实验结果及Baseline在表2给出。

表2 试验结果
4.4 结果分析
从表2我们看到,当取依赖于词频等表层信息的基本特征BF时结果为最低0.789,而加入语义特征SF后,系统性能得到很大改善,取得了3.7%的相对提高,达到0.818。这证明我们采用的语义特征效果比较明显。
我们的结果比依赖句法和词集特征的 Wu和Zhang的方法都有较明显提高。前面提到Zhang[18]的方法依赖依存句法分析对句式做了调整,如将被动句式变为主动句式等。这种方法效果并不理想,仅取得了0.807的F1值。这个结果正反映出新闻语料自身的特点,即是否是复述句很大程度上依赖于句子中某些状语、补语等修饰成分。我们的方法和Qiu[9]给出的方法相比提高虽然并不明显,但是我们的方法是在完全不依赖句法特征的条件下做出的,如何能将句法特征有效地融入我们的方法,也是我们下一步将要进一步研究的问题。
5 结论
本文介绍了一种新的基于语义角色标注的新闻复述语句识别方法。针对新闻语句不容易从词频、句法等信息做出复述判断的特点,对经过语义角色标注的新闻语句,我们提取了能反映句子不同成分匹配情况的更为丰富的特征。从实验结果看,我们的结果比依赖词集信息以及句法信息的方法都有明显的提高。
[1]Mc Keown,K.Paraphrasing using given and new information in a question-answer system[C]//Association for Computational Linguistics.1979.
[2]Callison-Burch,C.,P.Koehn,and M.Osborne.Improved statistical machine translation using paraphrases[C]//Association for Computational Linguistics Morristown,NJ,USA..2006.
[3]宗成庆,等.面向口语翻译的汉语语句改写方法[J].Journal of Chinese Language and Computing,2002,12(1):63-77.
[4]Zong,C.,et al.,Approach to Spoken Chinese Paraphrasing Based on Feature Extraction[C]//Proceedings of the 6th Natural Language Processing Pacific Rim Symposium(NLPRS).Tokyo,Japan.2001:551-556.
[5]车万翔,等.基于改进编辑距离的中文相似句子检索[J].高技术通讯,2004.14(7):15-19.
[6]Harabagiu,S.and A.Hickl.Methods for using textual entailment in open-domain question answering[C]//Association for Computational Linguistics Morristown,NJ,USA.2006.
[7]Barzilay,R.,K.McKeown,and M.Elhadad.Information fusion in the context of multi-document summarization [C]//1999: Association for Computational Linguistics Morristown,NJ,USA.
[8]秦兵,等.多文档自动文摘综述[J].中文信息学报,2005,19(6):14-20.
[9]Qiu,L.,M.Kan,and T.Chua.Paraphrase recognition via dissimilarity significance classification[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing.2006.
[10]Corley,C.and R.Mihalcea,M easuring the semantic similarity of texts[C]//Ann Arbor,2005.
[11]Fellbaum,C.,WordNet:An electronic lexical database[M].1998:MIT press Cambridge,MA.
[12]宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008.
[13]Finch,A.,Y.Hwang,and E.Sumita.Using machine translation evaluation techniques to determine sentence-level semantic equivalence[C]//Proceedings of the 3rd IN ternational Workshop on Paraphrasin.2005.
[14]Wu,D.,Recognizing paraphrases and textual entailment usinginversion transduction grammars[C]//Ann Arbor,2005.
[15]Bar-Haim,R.,I.Szpektor,and O.Glickman,Definition and analysis of intermediate entailment levels[C]//Empirical Modeling of Semantic Equivalence and Entailment,2005.100:55.
[16]Wan,S.,et al.,Using dependency-based features to take the“para-farce” out of paraphrase[C]//Proc.of ALTW,2006.
[17]Das,D.and N.Smith,Paraphrase identification as probabilistic quasi-synchronous recognition[C]//Proc.of ACL-IJCNLP,2009.
[18]Zhang,Y.and J.Patrick.Paraphrase identification by text canonicalization[C]//Proc.of Australiasian Language Technology Workshop.2005.
[19]Paul Kingsbury,M.P.,and Mitch Marcus,Adding semantic annotation to the penn treebank[C]//Proceedings of the Human Language Technology Conference,2002.
[20]Charniak,E.A maximum-entropy-inspired parser[C]//Proceedings of the First Annual Meeting of the North American Chapter of the Association for Computational Linguistics(NAACL'2000).2000.
[21]Pradhan,S.,et al.Shallow semantic parsing using support vector machines[C]//Proceedings of HLT/NAACL.Boston,USA,2004.
[22]Dolan, B., C.Quirk, and C.Brockett.Unsupervised construction of large paraphrase corpora:Exploiting massively parallel news sources[C]//Association for Computational Linguistics Morristown,NJ,USA.2004.
