基于事件项语义图聚类的多文档摘要方法
2010-06-05刘茂福李文捷姬东鸿
刘茂福,李文捷,姬东鸿
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;
2.香港理工大学 计算机系,香港;3.武汉大学 计算机学院,湖北 武汉 430072)
1 引言
抽取式自动摘要方法着重于从文档选取包含重要概念的句子。近年来,越来越多的研究者用事件代表概念并提出了基于事件的抽取式自动摘要方法[1-2]。基于事件的抽取式自动摘要主要是从单文档或多文档中抽取并重组那些描述重要事件的句子,因此,基于事件的句子重要性计算成为了当前的研究热点。
对于事件的定义,不同领域有不同的看法,信息检索领域将之定义在文档级别上,而信息抽取却在句子级别上定义事件[3-4]。但不同领域的一致观点是事件应包含一个或多个参与者、发生时间和地点,因此,在基于事件的自动摘要中,一般将事件形式化为“[Who] did [What] to [Whom] [When] and [Where]”;其中,“did [What]”指示行为,是事件的核心要素,其他的皆为补充成分。故而,我们将在句子级别上识别事件并重点研究“did [What]”,将文档中的动词和动名词都看成事件项,这些事件项可以完全或部分标识事件的发生。
目前,基于事件的自动摘要方法主要强调源文档中单个事件的统计特征,忽略了事件之间的关联。而在自动摘要中,尤其是具有同一或相似主题的多篇文档,多个事件肯定是相关的。对事件分布相似性的研究表明,在自动摘要中考虑事件统计关系特征会提高摘要的质量[5]。这促使我们在基于事件的自动摘要中进一步研究事件语义关系,尤其是如何利用这些事件语义关系。在本文中,通过事件项语义关系来部分表示事件语义关系,事件项是指文档中的动词和动名词;因此,本文的目的就是研究如何利用事件项之间的语义关系来提高多文档自动摘要的质量。
一旦从源文档抽取了所有事件项后,根据外部动词语义资源,可以获取事件项之间的语义关系,从而基于这些语义关系生成事件项语义关系图。在事件语义关系图的基础上,DBSCAN图聚类算法被用来对事件项进行聚类,从而生成多个事件项类,同一类的事件项之间由事件语义关系相连。
我们假设多篇源文档有一系列的事件组成,聚在同一类中的两个或多个事件项描述了相似甚至相同的事件。在这种情况下,完全可以为每类事件项选择一个代表项,只要保证这个代表项能出现在最终摘要中,就不失一般性。
我们也可以假设多篇源文档具有同一个主题,而多个事件项类别中的最重要的那个事件项类恰好描述了这一主题。在这种情况下,可以把最重要的事件项类中的所有事件项作为代表项,在代表项的基础上选择句子生成最终摘要。
除上面提到的Filatova等人基于事件和事件关系研究自动摘要技术外,徐永东等人通过系统地描述不同层面的文本单元之间的相互关系以及文档集合蕴含的事件在时间上的发生及演变,将多篇文档在不损失文档集合原有信息的前提下实现信息融合,并在此基础上为多篇文档生成摘要[6]。吴中勤等人基于语义关系三元组来完成问答式自动摘要系统,语义关系三元组由一句中的实词对以及表示该实词对语义关系的关系词组成[7]。
实际上,很多研究者已经在自动摘要中尝试过各种聚类方法。Hatzivassiloglou等人使用原子和组合特征将高度相似的不同文档段落聚集到不同的类中,然后从每个段落类中选择代表段落生成摘要[8-10]。Zha等人基于各种特征使用基于图的聚类算法对句子进行聚类,然后从句子类中选择句子生成摘要[11-15]。以上聚类的对象一般是段落或句子,进行聚类时使用粗粒度;而本文选择事件项作为聚类单位并在事件项语义关系的基础上执行聚类算法。实际上,本文是在我们文献[16]工作基础上的扩展。
2 ESRCS框架模型
在基于事件项语义关系图聚类的自动摘要(ESRCS)方法中,经过源文档集预处理、事件项语义图创建、事件项聚类、类排序、事件项选择与排序以及、句子重要性计算、句子抽取等六个阶段的处理后,最终为包含多个文档的源文档集生成摘要。具体的框架模型如图1所示。
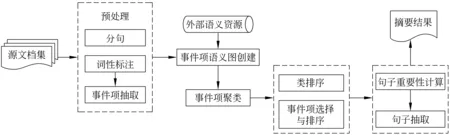
图1 ESRCS框架模型
在源文档集预处理阶段,首先对源文档进行分句和词性标注,然后从标注了词性的文档中抽取事件项,本文的事件项包括动词和动名词。根据从外部语义资源VerbOcean[17]中获取的事件项语义关系创建事件项语义图,本文主要关注VerbOcean中的stronger-than类型的动词语义关系。在事件项语义图表示的事件项语义关系的基础上,使用改进的DBSCAN聚类算法对事件项进行聚类。
事件项的重要性计算可以从局部类和全局文档集两个不同角度来进行;然后根据类中包含的事件项的重要性对相应的事件项类进行类排序。完成类排序后,有两种代表项选择方法,一种是选择最重要的类来表示源文档集的主题,而将最重要类中的所有事件项作为代表项;另一种则是选择每类中最重要的事件项作为类代表项。一旦为每个事件项计算出重要性后,就可以为选择的最重要类中的所有代表项排序,但为每个类选择出的类代表项的排序却取决于前面的类排序。
只为那些包含代表项的句子计算重要性,计算的依据是句子包含的代表项的重要性;然后为每个代表项选择包含它们的最重要的句子组成最终摘要,被抽取的句子在最终摘要中的排序取决于它们所包含的代表项的排序。
3 基于事件项语义图聚类自动摘要方法
3.1 事件项语义图
本文在基于事件的自动摘要中引入动词语义关系资源VerbOcean,与WordNet以及其他语义资源不同的是,它在更细粒度的级别上定义了五类动词语义关系,这与我们要在摘要中研究事件项语义关系不谋而合。本文主要研究VerbOcean中的stronger-than关系,该类关系的含义是,当两个动词意思相近时,一个可能比另一个表示的含义更强烈。本文对VerbOcean进行相应处理后,共有22 306条有效关系记录,共包括3 072个动词;在22 306条有效关系记录中,stronger-than关系共有4 420条,涉及到1 794个动词。
下面是stronger-than关系的例子。
“destroy” stronger-than “damage”
“kill” stronger-than “injure”
“harm” stronger-than “disturb”
事件项语义图可以形式化定义为一个二元组G=(V,E),其中V是图中非空节点集,这里的节点指事件项,E是连接图中事件项之间的边集,这里的连接使用事件项之间的语义关系。如果连接事件项的语义关系具有对称性,则事件项语义图就是一个无向图;否则,事件项语义图是有向图。
图2是源自DUC 2001测试语料库某个多文档集的stronger-than事件项语义关系图的一部分,因stronger-than关系具有反对称性,所以图2是一个有向图。在图2中,“satisfy”表示“令人满意”,而“please”的含义是“使人高兴、讨人喜欢”,明显比“satisfy”强度大,“满意”的程度深,故而有从“please”到“satisfy”的有向边,表示“please stronger-than satisfy”。
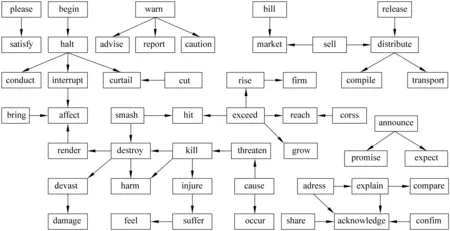
图2 stronger-than事件项语义关系图示例
从图2中可以看出,事件项之间经由表示语义关系的有向弧连接。有了事件项语义图,就可以利用图中信息,例如节点度,来计算事件项的重要性;当然也可以根据句子包含的事件项的重要性来决定该句子是否应出现在最终摘要中。
3.2 事件项语义图聚类
在图2中,“exceed”、“reach”与“grow”等是语义相关的,它们可能在描述同一或相似主题,应该归为一类;而“exceed”同“destroy”、“harm”以及“devast”是明显语义不相关的,应该将“destroy”、“harm”以及“devast”等归为另外一类。
本文使用DBSCAN聚类算法[18]来对语义相关的事件项进行归类,DBSCAN是一种基于密度的空间聚类算法。使用该算法,关键要确定两个参数,即Eps和MinPts,其中Eps指示在空间中的搜索半径,MinPts则表示节点领域中应该包含的其他节点的最小数目,这两个参数我们将在实验阶段给出。
除了两个关键参数外,我们对DBSCAN算法做了一些改进,使之更适合本文的事件项语义关系图。
(1) 如果使用DBSCAN算法给定的终止条件,事件项语义图中的大多数事件项会被聚在一类中,这是因为词的多义性会导致大多数的事件项都是语义相连的;在这种情况下,我们将DBSCAN的终止条件改为搜索步骤不超过3。实际上,随着搜索步骤和图中通路长度的增加,通路中两个端点的语义相关度会变得越来越小。
(2) 事件项语义图中存在只有入度没有出度的节点,如图2中的“acknowledge”和“hit”,我们将这些节点设置为为特殊事件项(SET:Special Event Term)。在搜索过程中,一旦到达了某个SET,便停止搜索。
(3) 同特殊事件项相连的节点可以分为两类,一类是除该特殊事件项外还有其他节点与之相连,如图2中相对与特殊事件项“hit”的“smash”;另一类是除该特殊事件项外没有其他节点相连,如图2中相对与特殊事件项“acknowledge”的“confirm”。对第一类节点不做任何处理,而将第二类节点同特殊事件项归并为一类。
图3是使用改进后的DBSCAN算法对图2的事件项进行聚类的结果。“confirm”和“acknowledge”在同一类,而“smash”和“hit”被聚在了不同类中。使用DBSCAN算法进行每类的搜索时,开始事件项都用粗体进行标示,本文使用开始事件项标示该类,如“warn”标示有“warn”、“advise”、“report”和“caution”组成的事件项类。
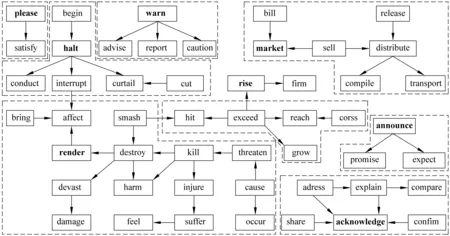
图3 事件项语义关系图的聚类结果
3.3 类排序
可以根据类重要性对使用DBSCAN算法获取的每个事件项类进行排序。类重要性可以使用如下公式(1)计算得到。
(1)
其中,dt是事件项语义图中指定事件项t的度(在有向图中为节点入度与出度的和);C是所有的事件项类集合,而Ci是第i个事件项类。公式(1)从全局角度计算事件项类的重要性,也就是说使用某类中所有事件项的度数和与所有类中所有事件项度数和的商来表示。
3.4 事件项选择与排序
我们可以依据事件项的重要性来选择代表项并基于类排序结果对代表项进行排序,可以从局部(Local)和全局(Global)两个角度来计算事件项重要性。
从局部事件项类的角度计算类中事件项的重要性,如公式(2)所示,用事件项在事件项语义图中的度数除以该事件项所在类的所有事件项的总度数。
(2)
从全局事件项类的角度计算某个事件项类中事件项的重要性,如公式(3)所示,用事件项在事件项语义图中的度数除以所有事件项类的所有事件项的总度数。
(3)
获得事件项的重要性后,可以采用两种策略从事件项类中选择代表项,即OTAC(One Term All Cluster)和OCAT(One Cluster All Term);OTAC是指从每个事件项类中抽取该类中最重要的事件项,而OCAT则是指选取最重要的事件项类中的所有事件项。
在OTAC选择策略中,从每个事件项类选择其中最重要的事件项作为代表项。在此种选择策略中,事件项类中每个事件项的重要性只用于在当前类中竞争,一旦为每类选择了代表项,代表项排序与其类排序相同。例如,在图3的类排序中,“render”类比“market”类靠前,在“market”类中选择事件项“distribute”,而事件项“destroy”则在“render”类中胜出,虽然计算所得的重要性“distribute”比“destroy”高,但在最终的代表项排序中,仍然是事件项“destroy”在前。
在OCAT选择策略中,在类排序结果中选择最靠前的类,被选择类的所有事件项都作为代表项,代表项按照它们在被选择类中的竞争结果来排序。
3.5 句子评价与抽取
代表项一般会出现在源文档集的多个句子中,在这种情况下,需要评价这些句子并从中抽取最重要的,可以使用MAX和SUM这种方法来计算句子重要性。
在MAX方法中,把出现在句子中的最重要事件项的重要性作为整个句子的重要性。如果事件项重要性是使用公式(2)计算的,句子重要性则只在与代表项同类的事件项范围内进行计算,因为类别不同的事件项之间没有可比性。若事件项重要性是使用公式(3)计算的,则类别不同的事件项之间具有可比性,句子重要性将在所有事件项范围内进行计算。
在SUM方法中,把出现在句子中的所有事件项的重要性的和作为整个句子的重要性。对事件项重要性计算公式的处理与MAX方法相同。
一旦得到句子重要性,就可以依据句子重要性对其进行排序并抽取包含代表项的最重要的句子,最后将这些句子进行重组成摘要。抽取的句子在重组摘要中的顺序与其代表项的排序结果一致。仍然基于前面的例子进行说明,已经为“render”类选择了事件项“destroy”,为“market”类选择了“distribute”,现在假设为“distribute”选择了句子s1,为“destroy”选择了句子s2,,那么在最终摘要中,句子s2在句子s1前。
4 实验结果
使用DUC 2001多文档摘要测试语料库对本文提出的方法进行评价,DUC 2001测试语料库共有30个文档集。经过分句、词性标注、事件项抽取等预处理后,每个文档集的事件项数目以及具有stronger-than关系的事件项数目如图4所示。
使用改进的DBSCAN算法对DUC 2001测试语料库的每个文档集的stronger-than关系进行聚类后,得到的事件项类别个数信息如图5所示。
使用自动评测工具ROUGE[19]对生成的摘要进行评测,观察ROUGE-1、ROUGE-2和ROUGE-W三个评测值,本文实验中生成的摘要长度为200字。
TF×IDF是自动摘要中常用的基于词频的统计特征,本文使用句子中所有非停用词的TF×IDF特征值的和来评价句子的重要性。PageRank[20]是最著名的基于图的排序算法,本文在生成事件项语义图后,使用PageRank计算图中事件项的重要性。基于词频的TF×IDF方法和PageRank方法的ROUGE结果如表1所示。
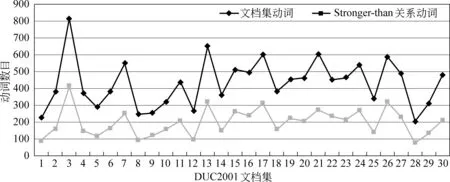
图4 DUC 2001测试语料库的每个文档集事件项信息
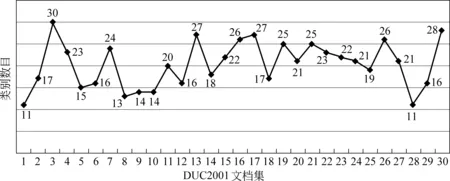
图5 每个文档集事件项聚类后的事件项类别个数信息
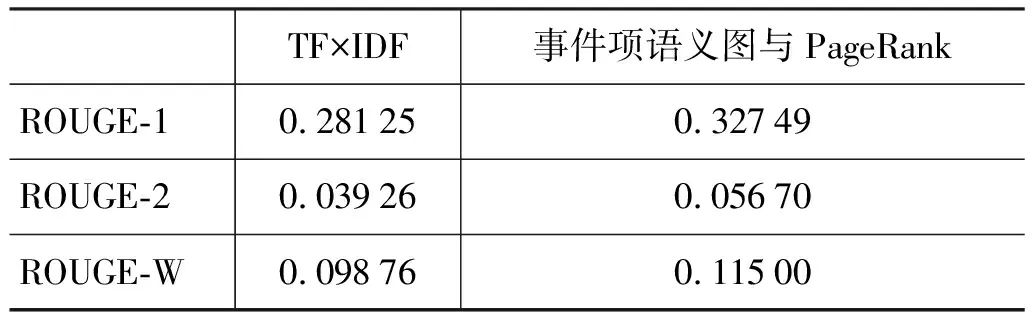
表1 TF×IDF和PageRank的ROUGE结果
在改进的DBSCAN聚类算法中,考虑到事件项语义图中没有明确的距离概念,参数Eps的值给定为一个语义关系步,而参数MinPts赋值为经验值3。
如果基于公式(2)从局部事件项类角度计算事件项的重要性并采用OTAC策略来为每类选择代表项,然后分别使用MAX和SUM方法来选择句子,实验结果如表2所示。

表2 局部角度(Local)和OTAC的ROUGE结果
从表2可以看出,SUM方法的结果好于MAX方法。可能原因是MAX方法在计算句子重要性时只考虑了代表项的重要性,而SUM不仅考虑代表项,并且还考虑了出现在句子中与代表项同类的非代表项,因而与MAX方法相比,SUM方法利用了比较多的信息。
为了利用更多的信息,基于公式(3)从全局事件项类角度计算事件项的重要性,这样句子的重要性不仅依赖于代表项所在类的所有事件项,并且还依赖于其他所有类中的事件项。实验结果如表3所示。
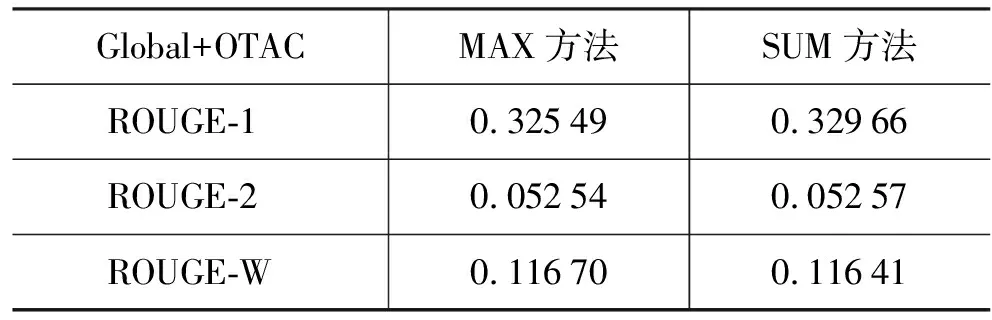
表3 全局角度(Global)和OTAC的ROUGE结果
表3的结果比表2的结果差,可能原因是当使用句子中所有的事件项来计算句子重要性时,代表项的作用被削弱;同时,长句子可能包含更多的事件项,使其重要性远远高于短句子,最终摘要选中的都是长句子,从而导致最终摘要中包括了太多的冗余信息。
如果基于公式(2)从局部事件项类范围内计算事件项的重要性并采用OCAT策略来选择最重要事件项类中的事件项作为代表项,然后分别使用MAX和SUM方法来选择句子,实验结果如表4所示。
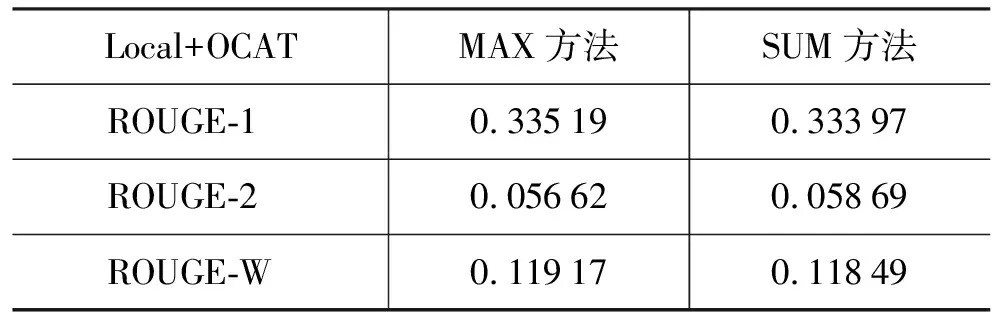
表4 局部角度(Local)和OCAT的ROUGE结果
如果基于公式(3)从全局事件项类角度计算事件项的重要性并采用OCAT策略来选择最重要事件项类中的事件项作为代表项,然后分别使用MAX和SUM方法来选择句子,实验结果如表5所示。
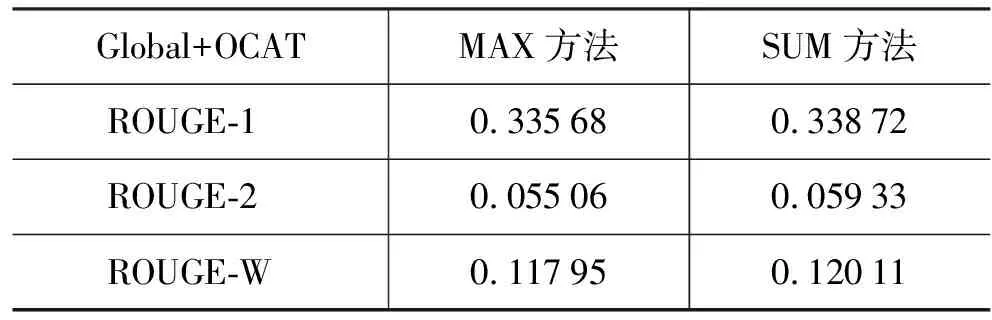
表5 全局角度(Global)和OCAT的ROUGE结果
表4和表5显示采用OCAT策略来选择最重要的事件项类并将该类的所有事件项作为代表项比OTAC策略的实验结果要好,这表明DUC 2001多文档摘要测试语料库的每个文档集中的每个文档都在描述同一个主题。
无论是OTAC策略还是OCAT策略,实验结果都远远好于基于词频TF×IDF方法。采用OCAT策略选择代表项并使用SUM方法计算句子重要性,ROUGE-1实验结果比基于PageRank的方法提高大概3.3%,而ROUGE-2实验结果提高了4.6%;这表明在事件项语义图的基础上对事件项进行聚类是有效的。
5 结论
通过对自动摘要语料库文档集的观察和预处理,本文提出两个假设。一个假设就是对于具有某类语义关系的两个事件项,它们代表了相同或相似的事件;而另一个假设则是指语料库的同一个文档集应该有一个代表性的主题事件。对于第一个假设,从每一个聚类中选择最重要的事件项作为该类的代表项;至于第二个假设,选择最重要的聚类并将该类的所有事件项作为代表项。针对每个代表项,则选择包含了该代表项的最重要的句子作为摘要候选句。
在事件项语义关系图上使用聚类算法获得事件项类后,本文分别从局部和全局两个角度基于策略OTAC和OCAT选择代表项,并使用ROUGE对生成的最终摘要进行评测,实验结果表明从全局范围使用OCAT策略和SUM方法生成的摘要明显好于基于词频TF×IDF和PageRank方法。
[1] Naomi Daniel, Dragomir Radev and Timothy Allison. Sub-event based Multi-document Summarization[C]//Proceedings of the HLT-NAACL Workshop on Text Summarization. 2003:9-16.
[2] Elena Filatova and Vasileios Hatzivassiloglou. Event-based Extractive Summarization[C]//Proceedings of ACL 2004 Workshop on Summarization, 2004:104-111.
[3] 吴平博,陈群秀,马亮.基于时空分析的线索性事件的抽取与集成系统研究[J].中文信息学报,2006,20(1):21-28.
[4] 袁毓林.用动词的论元结构跟事件模板相匹配——种由动词驱动的信息抽取方法[J].中文信息学报, 2005,19(5):37-43.
[5] Wenjie Li, Wei Xu, Mingli Wu, et al. Extractive Summarization using Inter- and Intra- Event Relevance[C]//Proceedings of ACL 2006:369-376.
[6] 徐永东,徐志明,王晓龙.基于信息融合的多文档自动文摘技术[J].计算机学报,2007,30(11):2048-2054.
[7] 吴中勤,黄萱菁,吴立德. 基于语义关系三元组的问答式文摘[J].计算机工程,2008,34(6):194-196.
[8] Vasileios Hatzivassiloglou, Judith L. Klavans, Melissa L. Holcombe, et al. Simfinder: A Flexible Clustering Tool for Summarization[C]//Workshop on Automatic Summarization, NAACL, 2001.
[9] Yohei Seki, Koji Eguchi and Noriko Kando. User-Focused Multi-Document Summarization with Paragraph Clustering and Sentence-Type Filtering[C]//Proceedings of the Fourth NTCIR Workshop on Research in Information Access Technologies: Information Retrieval, QuestionAnswering, and Summarization, 2004:459-466.
[10] 刘海涛,老松杨,韩智广.自动文摘系统中的段落自适应聚类研究[J].微计算机信息,2006,22(6):288-291.
[11] 陈戈,段建勇,陆汝占.基于潜在语义索引和句子聚类的中文自动文摘[J].计算机仿真,2008,25(7):82-85.
[12] Hongyuan Zha. Generic Summarization and keyphrase Extraction using Mutual Reinforcement Principle and Sentence Clustering[C]//Proceedings of the 25th annual international ACM SIGIR conference on Research and development in information retrieval, 2002:113-120.
[13] Advaith Siddharthan, Ani Nenkova and Kathleen McKeown. Syntactic Simplification for Improving Content Selection in Multi-Document Summarization[C]//Proceedings of the 20th International Conference on Computational Linguistics (COLING 2004), 2004:896-902.
[14] Yi Guo and George Stylios. An Intelligent Summarization System Based on Cognitive Psychology[J]. Journal of Information Sciences, 2005, 174(1-2):1-36.
[15] 郭庆琳,吴克河,吴慧芳,李存斌.基于文本聚类的多文档自动文摘研究[J].计算机研究与发展,2007,44(z2):140-144.
[16] Maofu Liu, Wenjie Li, Mingli Wu, et al. Extractive Summarization Based on Event Term Clustering[C]//Proceedings of ACL 2007, 185-188.
[17] Chklovski Timothy and Pantel Patrick. VerbOcean: Mining the Web for Fine-Grained Semantic Verb Relations[C]//Proceedings of Conference on Empirical Methods in Natural Language Processing, 2004.
[18] Martin Ester, Hans-peter Kriegel, S. J?rg, et al. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise [C]//Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, 1996:226-231.
[19] Chin-Yew Lin and Eduard Hovy. Automatic Evaluation of Summaries using N-gram Cooccurrence Statistics[C]//Proceedings of HLTNAACL 2003, 71-78.
[20] Page Lawrence, Brin Sergey, Motwani Rajeev and Winograd Terry. The PageRank CitationRanking: Bring Order to the Web[R]. Technical Report,Stanford University, 1998.
