基于模糊聚类的车内空气质量评价
2010-06-13赵建文
赵建文
(浙江海洋学院萧山科技学院,浙江杭州 311200)
随着家用汽车消费的快速增长,汽车室内空气质量问题也越来越引起人们关注,车内空气污染物主要是由甲醛、苯、TVOC等对人体有害物质构成,各污染物的浓度可由相关专业机构检测,目前在国内尚无车内空气污染物浓度限值标准的情况下,对各种不同车型、车辆的车内空气污染水平做科学合理的分类与评价是很有意义的。
本文拟用模糊聚类分析方法[1],综合甲醛、苯、TVOC指标浓度,对不同车辆车内空气质量做出分类、评价。
1 模糊聚类分析原理和主要步骤[2-5]
聚类是根据一定的规则,按照事物某些属性,合理划分未分类事物的集合,得到确定事物分类的过程。模糊聚类是采用模糊数学方法,依据客观事物间的特征、亲疏程度和相似性,通过建立模糊相似关系,并在此基础上根据一定的隶属度来确定分类关系,也就是用模糊数学的方法把样本之间的模糊关系(相似性)加以定量的确定,从而客观且准确地进行分类。由于现实的分类过程往往伴随着模糊性,所以用模糊数学的方法来进行聚类分析会显得更自然、更符合客观实际。
1.1 聚类对象定义
设论域 U={x1,x2,…xn}为被聚类的对象集,其中x(ii=1,2,…n)称为一个样本;每个样本有m个特征指标,即:xi=(xi1,xi2,…xim),全部原始数据构成数据矩阵X=(xi)jn×m
1.2 样本数据标准化
为使不同量纲的数据可以相比较,通常需要将原始数据xij压缩至[0,1]区间,这一过程称为数据标准化。可以通过以下平移极差变换实现数据标准化:

1.3 模糊相似矩阵
为了确定各个样本之间的关系,通常采用两种度量来表示样本之间的接近程度[6]:(1)相似系数r:用来表示样本之间相似程度,r越接近1,则两个样本之间的相似程度就越高。常用的相似系数有夹角余弦、相关系数等;(2)距离d:将n个样本看作是m维空间的n个点,定义点与点之间的距离d,d越小两样本越接近。常用的距离如欧氏距离,明氏距离等。不失一般性,本文用夹角余弦来计算样本之间的相似系数,公式如下:

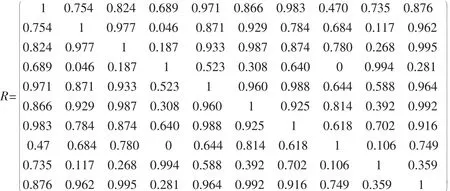
rij表示2个样本xi与xj之间的相似程度,由此建立模糊相似矩阵(也称之为模糊相似关系)R=(rij)n×m。
1.4 传递闭包
模糊相似关系R一般具有自反性和对称性,若还满足传递性满足(即R◦R⊆R),则称R为模糊等价关系。这里R◦R称相似矩阵R进行自乘操作,即:R◦R=R'(rij')n×m,其中

式中∧表示并运算(取最小值),∨表示或运算(取最大值)。运算过程为:R矩阵的第i行取小值,然后再取其中的最大值。
通过上述方法得到的模糊相似矩阵R一般只具有自反性和对称性,不满足传递性。其传递性可通过传递闭包变换实现。
传递闭包法,又称为Washall算法,其思想是把一个相似矩阵R进行自乘操作(R◦R),并且检验R是否满足传递性,如果R满足传递性,不再继续往下进行自乘操作。传递闭包法聚类首先需要通过标定的模糊相似矩阵R,然后求出包含矩阵R的最小模糊传递矩阵,即R的传递闭包TR,最后依据TR进行聚类。
定理 设R是n阶模糊相似关系,则存在一个最小自然数k(k≤n),使得R的传递闭包TR=Rk,且对一切大于k的自然数L,恒有RL=Rk。该定理说明,在不超过n次运算内,即可求得R的传递闭包TR,从而得到一个模糊等价矩阵。为提高运算速度,可用平方法依次计算R2,R4,R8,…一定可找到k,使得Rk◦Rk=Rk,于是,TR=Rk。
1.5 截集取得聚类矩阵
取适当阈值 λ(λ∈[0,1]),对模糊等价矩阵 TR 作截集处理,求出聚类矩阵 R″=(rij″)n×m其中:

将rij″为1的相应样本聚合为同一类,聚类完成。容易证明,λ值选取越大,聚合出的类别数越多,选取得越小,则聚合出的类别数越少。但聚类结果并不矛盾:较粗类别是较细类别的上位类,利用λ取值不同,可获得不同程度的聚类,形成多层次分类结构。特别当λ=0时聚类最粗,λ=1时聚类最细。
2 车内空气质量的聚类评价
2.1 原始数据的获取
选择10辆家用小汽车,要求使用时间在3个月以内,且行驶里程在12 000 km以内,没有经过内饰改装或除甲醛等处理,车辆使用者无在车内吸烟等习惯,平时没有装载其他会增加或减少车辆异味的物品。在外部空气质量和天气状况良好,室外温度20~30℃的情况下检测其车内空气中甲醛、苯、TVOC的浓度,选取样本的原始检测数据如下表:
2.2 原始数据标准化
对表1数据(甲醛、苯、TVOC的浓度)用平移极差变换(公式1),得到标准化的数据如下:
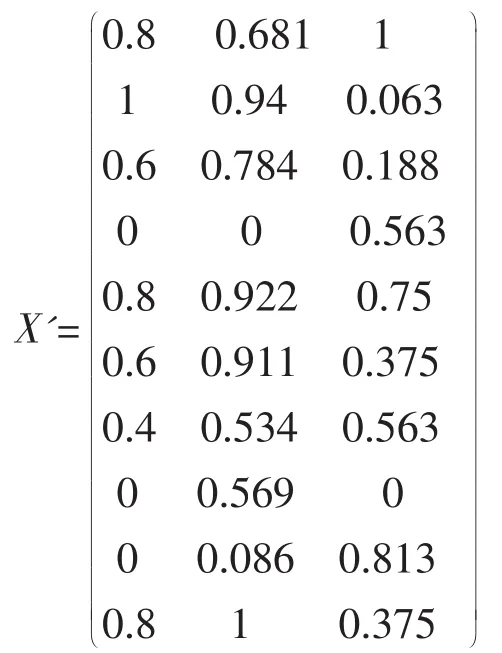
2.3 建立模糊相似矩阵
采用夹角余弦法(公式2)可以得到以下糊相似矩阵:
2.4 计算传递闭包并聚类
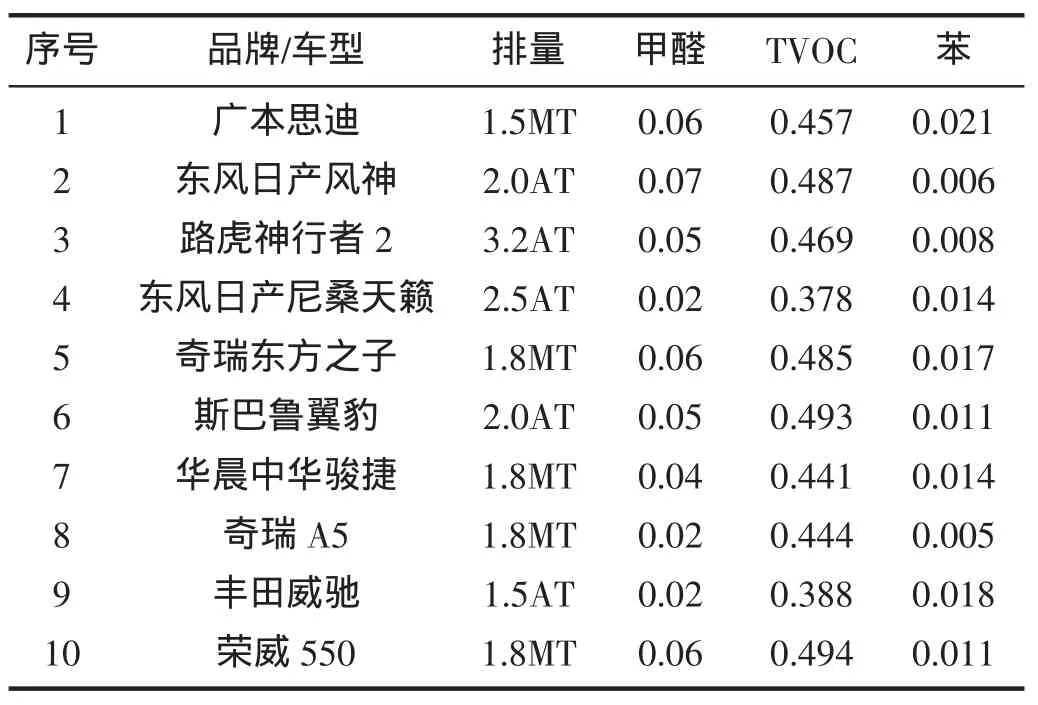
表1 不同车型甲醛、苯、TVOC的浓度Tab.1 The concentration of formaldehyde,benzene and TVOC in different car models
计算传递闭包TR如下:

取λ=0.977截取TR(公式4),得到等价关系Rλ如下:

从而得到 10 辆汽车车内空气污染聚类为 C1={1,5,7},C2={2,3,6,10},C3={4,9},C4={8}。
2.5 结果分析
聚类分析的原理是越先聚为一类的样本越相似。本例中rij取的是模型相似系数,聚成4类时,即相似水平为时λ=0.977,表1中汽车{1,5,7}车内空气质量最相似,其特点是车内空气中甲醛、苯、TVOC的浓度都较高,第二类{2,3,6,10}车内苯的浓度较低但甲醛和TVOC的浓度都较高,第三类{4,9}车内甲醛、苯、TVOC的浓度都较低,而第四类{8}车内甲醛、苯浓度较低而TVOC的浓度稍高于第三类。
3 结束语
模糊聚类分析是基于样本之间的相似性,将最相似的样本聚成一类。它无需依赖其他先验信息,只需根据对象指标数据直接导出聚类结果,更具科学性和客观性。同时,如果的计算方法不同,相同的样本也会得出不同的分类结果。所以,在分类过程中,要根据问题的实际情况选择相似系数的计算方法。本文中车内空气质量的模糊聚类,很好的实现了评价分析的功能,但不能直接实现传统意义的名次排序。
[1]高新波.模糊聚类分析及其应用[M].西安:西安电子科技大学出版社,2004.
[2]罗兰星.基于传递闭包法的西南5城市环境质量评价分析[J].上海理工大学学报,2009,31(3):303-306.
[3]冯 梅.基于模糊聚类分析的教师课堂教学质量评价[J].数学的实践与认识,2008,38(2):12-15.
[4]张秀梅,王 涛.模糊聚类分析方法在学生成绩评价中的应用[J].渤海大学学报:自然科学版,2007,28(2):169-172.
[5]张东生,季 超,郑文奎.基于模糊聚类的考试分析方法[J].电脑知识与技术,2009,5(33):9 579-9 580;9 590.
[6]邵峰晶,于忠清,王金龙,等.数据挖掘原理与算法[M].第2版.北京:科学出版社,2008:181-182.
