Bloom Filter研究进展*
2010-06-11严华云关佶红
严华云,关佶红
(1.湖州师范学院信息与工程学院 湖州 313000;2.同济大学电子与信息工程学院 上海 201804)
1 引言
在计算机应用领域,信息的表示和查询是核心问题,这两个问题常常是相关的。其中,表示意味着根据一定的规则组织信息,查询则意味着判断一个给定属性值的元素是否属于某一集合。
Bloom filter[1]是一种节省空间、高效率的数据表示和查询结构。它利用位数组很简洁地表示一个集合,并能以很高的概率判断一个元素是否属于这个集合。因此,这种数据结构适合应用在能容忍低错误率的场合。
Burton H.Bloom于1970年提出Bloom filter用以解决某(些)元素是否为集合中元素的判断问题。它突破了传统哈希函数的映射和存储元素的方式,通过一定的错误率换取了空间的节省和查询的高效。在20世纪70年代,其应用价值并没有体现出来。80年代,随着PC应用的推广,Bloom filter的应用开始推广,如高效地解决拼写检查问题[2],解决多处理器计算机中数据库的连接问题[3]。网络时代的到来使得Bloom filter具有越来越多的应用,如应用到分布式数据库中进行查询[4,5],应用到网络中取代ICP以进行高速缓存查询[6],应用到P2P中进行高效的联合查询[7,8]等。肖明忠、Broder、谢鲲等分别于2003年、2004年、2007年写了Bloom filter的综述性文献[9~11]。近几年,Bloom filter及其应用又取得了新的进展,本文对Bloom filter在通信领域的研究进行归纳和展望,并介绍了Bloom filter的典型应用。
2 标准的Bloom filter
标准Bloom filter的工作原理如图1所示。为了表达S={x1,x2,…,xn}这样一个有n个元素的集合,Bloom filter使用k个相互独立的哈希函数(hash function),它们分别将集合中的每个元素映射到位数组BFV的k个位中(BFV共有m位)。对任意一个元素x,第i个哈希函数映射的位置 hi(x)就会被置为 1(1≤i≤k),如果一个位置已经为 1,那么随后映射到该位置时其值将不变。
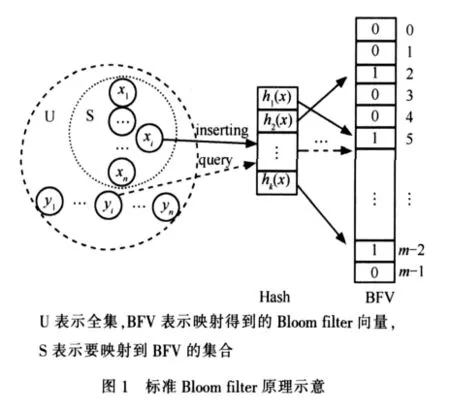
当查询元素zi时,用Bloom filter中的k个哈希函数映射到BFV中,如果每一个哈希函数映射到的位都为1,则认为zi属于S,否则 zi不属于S。
与经典的哈希函数相比,Bloom filter最大的优势是它的空间效率。另外,由于Bloom filter不用处理碰撞,无论集合中元素有多少,也无论多少集合元素已经加入到了位向量中,Bloom filter在增加或查找集合元素时所用的时间都为哈希函数的计算时间。由于Bloom filter对集合中的元素进行了编码,因此想从Bloom filter的位向量中恢复集合元素并不容易,如果不想让别人直接看到集合元素,这样的编码处理相当于一种加密,从而有利于保护隐私。
Bloom filter的这些优点是有一定代价的:在判断某一个元素zi是否属于集合S时,有可能会把不属于S中的元素误认为属于S,这种情况称为“假阳性”的“错误率”(false positive),这个错误率可以通过概率的方法计算出来。因此,Bloom filter不适合那些“零错误”的应用场合。
在标准的Bloom filter中,对于使用k个哈希函数,向m位长的Bloom filter中装入n个元素后,位向量中某一位仍然为0的概率p为:

则错误率fp为:

在式(2)中,令g=-(m/n)ln(p)ln(1-p),根据对称性法则可知,当p=1/2,g取到最小值,则fp取到最小值。
错误率fp最小的条件为:

由此可见,标准Bloom filter中参数m、n的比值是已知的,为了保证错误率最小,则要求k=(m/n)ln2,此时BFV中某一位为零的概率为1/2(即p=1/2)。将式(3)代入式(2)有:

由式(3)和式(4)可知,当m和n的比值越大则要求哈希函数的个数k越大,并且其错误率越小。
3 Bloom filter结构的各种经典变体
自从Bloom filter在通信领域得到广泛应用后,研究人员在不同的应用背景下对Bloom filter进行了一些改进,下面对Bloom filter的一些典型变体进行介绍。
3.1 可删除元素的Bloom filter
由于在Bloom filter中不可以删除元素,参考文献[6]在对网页进行缓存时(集合中元素不重合),为了更新并淘汰过时的网页,设计了一种称为Couting Bloom filter(计数型CBF)的变体,其具体办法为:将图1中向量BFV的每一位扩展成几位(详细如图2所示的CBFV,文中称扩展成的这几位为一个计数器 (counter))。
经扩展后,当某一个元素要插入集合S时,分别用k个哈希函数映射到CBFV的k位计数器,将这些计数器增加1;当某一个元素要从集合S删除时,分别用k个哈希函数映射到CBFV上的k个计数器,并将这些计数器减少1个。通过扩展BFV的位成为CBFV计数器后的CBF,就能够处理元素删除的操作。对于网页缓存这类不重复元素问题,当CBF中计数器用4位时,经过相应推导,出现溢出的概率为:

式(5)表示的是计数器中最大值大于等于16出现的概率,其中m是CBFV的长度。即使某一位计数器出现溢出,也不会导致马上出现错误,而是删除元素直到该位计数器为零后才会出现所谓的 “假阴性”的 “错误率”(false negative),即把属于该集合的元素误认为不属于该集合的错误,因此出现“假阴性”的“错误率”的概率为式(5)的2倍。因此,将CBF的计数器设计成4位是合理的。
针对CBF可能溢出的问题,有一种解决方法叫做d-Left Counting Bloom filter(dlCBF)[12]。
dlCBF通过引入一种叫做d-Left hash的更均衡的哈希函数来降低CBF向量中counter的位数。在添加一个key时,先对其作一次hash,得到d个存储位置和一个fingerprint,然后判断d个位置中的负载情况,并在负载最轻的几个位置中选择最左边的插入。如果选择的位置已经存储了相同的fingerprint,就把那个cell的counter加1。在删除一个key时,同样地作一次hash,然后在d个存储位置查找相应的fingerprint,如果找到就将这个cell置空或者将相应的counter减1。
在集合中删除元素时可能会出现:不同的两个元素的hash值(fingerprint)相同,从而删除元素时不好判断将哪一个counter减1。为了解决这个问题,该文引入随机置换避免了位置重合,从而使问题得以解决。
为了节省CBF的存储空间,提出了MultiLayer compressed counting bloom filter[13],该 Bloom filter也支持集合中删除元素的操作。
3.2 可统计元素频次的Bloom filter
当应用中需要统计元素出现的频次(即重复元素问题)时,由于CBF的计数器采用固定长度的位数,会产生溢出(overflow)的问题。为了解决这种溢出,相关文献提出了两种方法:一种是参考文献[14]提出的Spectral Bloom filter(SBF),由于SBF中要建立索引,查询起来比较费时;为进一步解决SBF访问速度的问题,参考文献[15]提出了另一种数据结构Dynamic count filter(DCF)。对于动态计数型的Bloom filter,下面选择DCF进行介绍。
DCF的数据结构如图2所示,它由两部分组成,一部分是前面提到的CBFV向量,其位长度x由集合中数据元素的总个数M和集合中不同元素的总个数n的比值取2为底的对数确定;另一部分是为了处理CBFV溢出而设计的OFV向量,其位数y值是动态变化的(DCF的动态体现在这里),其值由集合中元素出现的最高频次所决定。DCF中计数器的值Value是由OFV和CBFV中相同下标位的二进制数连接而成。当需要查询某元素在DCF的出现频次时,就用DCF的k个哈希函数映射到DCF数据结构上,其中的最小值(value)就被认为是其频次(最小值不是频次的情况是k个位置同时出现了碰撞,这个概率和误判率的概率相同)。
3.3 可处理动态数据集的Bloom filter
前面所介绍的Bloom filter应用有一个共同点,即事先能够确定集合S中的元素个数m。事实上,很多应用在事先并不清楚要处理多大的数据集;或者要处理很大的一个数据集,但数据元素的加入是缓慢的。参考文献[16]称这种问题为增长问题,这种情况在P2P环境中经常出现。为了处理这类问题,出现了一类可以拉伸位数组 (BF)个数的Bloom filter[16~19]。下面介绍 Dynamic Bloom filter(DBF,动 态Bloom filter)。
DBF的办法是先用一个能处理较少元素的Bloom filter来处理,当此Bloom filter达到处理元素的极限时,再生成一个和初始Bloom filter长度相同的Bloom filter,如此这般。新元素加入时映射到最新生成的Bloom filter中,查询时在几个子Bloom filter都同时进行查询,只要映射到DBF中的一个子Bloom filter的k个位置的值都为1,则认为该元素为集合中的元素。
由于这种方法可以看成由多个Bloom filter向量组成的一个矩阵,由应用需要取其中一个或多个Bloom filter进行使用,因此参考文献[16]称之为拆分型Bloom filter。

3.4 压缩型Bloom filter
在标准Bloom filter中,已知参数m、n的比值,为使错误率最小,则要求k=(m/n)ln2(具体推导见参考文献[10])。参考文献[20]考虑在网络中传播消息时要进行压缩,这时Bloom filter不再是仅由m、n、k这3个参数决定错误率,应该加上z参数(表示Bloom filter的位向量被压缩后的长度),这4个参数一起决定了错误率,这就是所谓的Compressed Bloom filter(压缩型BF)。由于压缩编码时要服从香农编码原理,即压缩编码后的最大压缩比不小于信息熵H(P),即有最小的z=m H(P),引入z后的分析和标准的Bloom filter中的分析相同,即将z取代m代入错误率的表达式中。经过一定的变换分析得出:当p=1/2时,其错误率最大(此时的熵为1,即根本得不到压缩,此时和标准BF中的正好相反);当p越接近0时(k趋于无穷,此种情况不符合实际应用)和p越接近1时 (k趋于0,实际应用中1≤k≤(m/n)ln2),其错误率越小,其详细推导见参考文献[20]。为了对压缩型BF有更深的了解,表1列出了各个参数和错误率间的关系,其中z/n是固定的。

表1 压缩型Bloom filter中各参数和错误率的关系
表1中第一列数据(加粗的数据)是没有压缩的情况,此时需要k的个数最多,且错误率最高。随着压缩比越大,则需要k的个数越少,错误率也更低,这说明压缩能够降低错误率。
3.5 各种典型Bloom filter的比较
表2列出了几种经典Bloom filter的性能比较。从该表可以看出:所有的Bloom filter都具有基本的功能,即进行集合元素的表示和查询;支持元素频次查询操作的Bloom filter一定支持删除元素操作。

表2 几种经典Bloom filter的性能比较
4 Bloom filter的应用
Bloom filter的应用包括:它表示一种压缩数据集合,可以替代原始的数据集合,完成元素是否在集合的查询判断,如数据库操作、字典查询和文件操作[2,3,21~24]方面;Bloom filter也广泛应用到网络领域,包括P2P网络[7,8,25,26]、资源路由[27]、数据帧路由标签[28]、网络测量管理[29~32]、网络入侵检测[33]、传感器网络数据过滤和路由[34]等;第三类是元素表示的保密性。因此,凡是有上述3类要求的,并且能容忍一定错误率的应用都可以将Bloom filter派上用场。Broder和Mitzenmacher在2004年的综述论文[10]中预言:当前Bloom filter在网络上的应用还十分有限,随着Bloom filter被越来越多的研究人员认识和重视,它将在现代计算机网络和一些新的学术领域得到更为广泛的应用。确实,Bloom filter这几年的应用研究正在而且必将继续印证该论断。
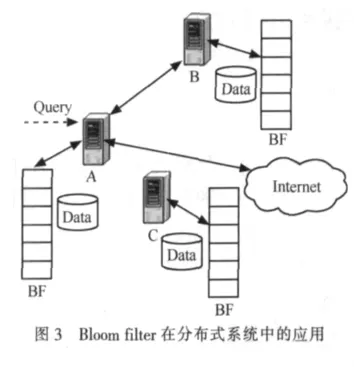
4.1 Bloom filter典型的分布式应用
图3为Bloom filter在分布式系统中的应用例子。当客户向服务器A提出请求时:A首先检查本身的缓存和其他近邻Proxy(如B)的缓存,这些缓存的目录摘要用Bloom filter表示,如果A及其近邻Proxy的缓存目录摘要里有文档信息,则向相应的近邻Proxy请求以获取文件,如果没有,就直接向上级服务器发送请求。
4.2 Bloom filter的网络资源
[35]是Bloom filter源代码的下载地址,该源码用Java语言实现,该源码由Indiana大学的Liu Hongbin和Jerzak提供,它实现了两种Bloom filter:一个是标准的Bloom filter,它用BitSet表示;另一个是支持删除元素的Counting Bloom filter,它用一个数组表示。HashFactory(m,k)是生成BF的接口,其中需要给出两个参数m和k(即BF的长度和哈希函数的个数),其中可供选择的哈希函数个数k共有10个(即k不能超过10,当然自己可以根据需要扩展)。
5 总结与展望
使用Bloom filter可达到两方面的性能:压缩数据和高查询效率 (时间为计算哈希函数的时间)。只要在具体应用中需要Bloom filter的任何性能,并能够容忍较小的错误率,都可以引入Bloom filter。
Bloom filter虽然根据不同应用需求具有了很多变体,但是其仍有很多应用需要改进,主要有以下3方面。
(1)网络传输中压缩型Bloom filter的实现
由于Bloom filter及其变体被广泛应用于分布式数据库、Proxy的Cache、对等网等网络环境中,在网络传输中如何进行压缩是一个问题。参考文献 [20]从理论上提出了CBF,但文中没有给出具体的实现。另外,在DCF的推理中用到了极限熵进行压缩编码,我们知道一般编码是很难达到极限熵的,对特定数据集能够达到极限熵编码,对其他数据未必就能达到极限熵编码,例如常见的哈夫曼编码就是一个例子。因此,Bloom filter网络传输问题的压缩编码算法还有待研究。
(2)Bloom filter结构在海量数据问题中的扩展
在对等网、信息检索领域中,所涉及的数据量非常大,并且没办法估计数据量的大小,或者考虑到数据量是渐增和动态变化的,没必要一开始就建立一个很大的Bloom filter,在数据量渐增和动态变化的过程中需要能够建立一种能够动态伸缩的Bloom filter。
(3)并行 Bloom filter的需求
在网络Cache和一些信息安全领域用到Bloom filter时,需要Bloom filter具有快捷的速度。这种情况下,需要将Bloom filter做到硬件中,并且最好能够提供并行计算的功能,目前Bloom filter的变体基本上都不支持并行计算的功能。Bloom filter的并行性需求有待我们去研究。
总之,自从Burton Bloom在1970年提出Bloom filter之后,Bloom filter就被广泛用于拼写检查和数据库系统中。随着网络的普及和发展,Bloom filter的研究和应用迅猛发展,新的Bloom filter变种和新的应用不断出现。可以预见,随着互联网的不断发展,Bloom filter的新变种和应用将会继续出现。
参考文献
1 Bloom B H.Space/time trade-offs in hash coding with allowable errors.Communications of the ACM,1970,13(7):422~426
2 Mcilroy M D.Development of a spelling list.IEEE Transactions on Communications,1982,30(1):91~99
3 Valdurez P,Gardarin G.Join and semijoin algorithms for a multiprocessor database machine.ACM Transactions on Database Systems,1984,9(1):133~161
4 MackettL F,Lohman G M.Roptimizer validation and performance evaluation for distributed queries.In:Proc of the VLDB,Kyoto,Japan,August 1986
5 Mullin J K.Optimal semijoins for distributed database systems.IEEE Transactions on Software Engineering,1990,16(5):558~560
6 Fan L,Cao P,Almeida J,et al.Summary cache:a scalable wide-area Web cache sharing protocol.ACM Transactions on Networking,2000,8(3):281~293
7 Reynolds P,Vahdat A.Efficient peer-to-peer keyword searching.In:Proc of Middleware,Riode Janeiro,Brazil,June 2003
8 Chen H H,Jin H,Wang J L,et al.Efficient multi-keyword search over P2P web.In:Proc of the WWW,Beijing,China,April 2008
9 肖明忠,代亚非.Bloom Filter及其应用综述.计算机科学,2004,31(4):180~183
10 Broder A,Mitzenmacher M.Network applications of bloom filters:a survey.Internet Mathematics,2005,1(4):485~509
11 谢鲲,文吉刚,张大方等.布鲁姆过滤器查询算法.软件学报,2009,20(1):96~108
12 Bonomi F,Mitzenmacher M,Panigrahy R,et al.An improved construction for counting bloom filters.In:Lecture Notes in Computer Science,Zurich,Switzerland,September 2006
13 Ficara D,Giordano S,Procissi G.MultiLayer compressed counting bloom filters.In:Proc of the Infocom,Phoenix,AZ,USA,April 2008
14 Saar C,Yossi M.Spectral bloom filters.In:Proc of the SIGMOD,San Diego,USA,June 2003
15 Aguilar-Saborit J,Trancoso P,Muntes-Mulero V.Dynamic count filters.In:Proc of the SIGMOD,Chicago,USA,June 2006
16 肖明忠,代亚非,李晓明.拆分型Bloom Filter.电子学报,2004,32(2):241~245
17 Guo D,Wu J,Chen H,et al.Theory and network applications of dynamic bloom filters.In:Proc of the Infocom,Barcelona,Spain,April 2006
18 Almeida P S,Baquero C,Preguica N.Scalable bloom filters.Information Processing Letters,2007,101(6):255~261
19 Hao F,Kodialam M,Lakshman T V.Incremental bloom filters.In:Proc of the Infocom,Phoenix,AZ,USA,April 2008
20 Mitzenmacher M.Compressed bloom filters.ACM Transactions on Networking,2002,10(5):604~612
21 Mullin J K.Optimal semijoins for distributed database systems.IEEE Transactions on Software Engineering,1990,16(5):558~560
22 Udi M,Sun W.An algorithm for approximate membership checking with application to password security.Information Processing Letters,1994,50(4):191~197
23 Gremillion L L.Designing a bloom filter for differential file access.Communications of the ACM,1982,25(9):600~604
24 James K M.A second look at bloom filters.Communications of the ACM,1983,26(8):570~571
25 Ahmed R,Boutaba R.Plexus:a scalable peer-to-peer protocol enabling efficient subset search. ACM Transactions on Networking,2009,17(1):130~143
26 张一鸣,卢锡城,郑倩冰等.一种面向大规模P2P系统的快速搜索算法.软件学报,2008,19(6):1473~1480
27 Yu H,Mahapatra R N.A memory-efficienthashing by multi-predicate bloom filters for packet classification.In:Proc of the Infocom,Phoenix,AZ,USA,April 2008
28 Kumar A,Xu J,Wang J,Spatschek O,et al.SpaceScode bloom filter for efficient persflow traffic measurement.In:Proc of IEEE Infocom,Hongkong,March 2004
29 叶明江,崔勇,徐恪等.基于有状态Bloom filter引擎的高速分组检测.软件学报,2007,18(1):117~126
30 Yu H,Mahapatra R N.A memory-efficienthashing by multipredicate bloom filters for packet classification.In:Proc of Infocom,Phoenix,AZ,USA,April 2008
31 Sarang D, Haoyu S, Jonathan T, et al. Fast packet classification using bloom filters.In:Proc of the 2006 ACM/IEEE Symp Architecture for Networking and Communications Systems,2006
32 HeeyeolY,Mahapatra R.A memory-efficienthashing by multi-predicate bloom filters for packet classification.In:Proc of the Infocom,Phoenix,AZ,USA,April 2008
33 Locasto M E,Parekh J J,Keromytis A D,et al.Towards collaborative security and P2P intrusion detection.In:Proc of SMC 2005,NY,USA,June 2005
34 Hebden P,Pearce A R.Data-centric routing using bloom filters in wireless sensor networks.In:Proc of ICISIP 2006,Bangalore,India,December 2006
35 Bloomfilter,http://wwwse.inf.tu-dresden.de/xsiena/bloom_filter
