古籍版本异文的自动发现
2010-06-05陈小荷
肖 磊,陈小荷
(南京师范大学 文学院,江苏 南京 210097)
1 引言
我国有丰富的文献典籍,这些文献典籍在传抄、引用、印刻、校改过程中往往出现各种讹误或替代,从而造成一种文献的各版本之间或不同文献相关内容之间在字、词、句等方面存在差异,这就是所谓异文。例如:
(1a) 三月公及邾儀父盟于蔑 (《左传·隐公元年》)
(1b) 三月公及邾婁儀父盟于眛 (《公羊传·隐公元年》)
(2a) 循牆而走,亦莫余敢侮 (《左传·昭公七年》)
(2b) 循牆而走,亦莫敢余侮 (《史记·孔子世家》)
大量的异文为语言学、文献校勘、史学等方面的研究提供了丰富的材料。(1)中“邾”和“邾婁”,“蔑”和“眛”两处异文,音韵学家和历史地理学家都感兴趣。(2)是对同一鼎銘的引用,“莫余敢侮”和“莫敢余侮”这处异文显示了从上古汉语到中古汉语的语法变化。
版本异文是同—文献的不同版本之间在本应相同的字句上出现的差异,例如(1)。其他统称为非版本异文,例如(2)。版本异文和非版本异文的信息处理有所不同。研究版本异文,首先需要尽可能地找出各版本之间的不同之处,于大同中求小异。研究非版本异文,则首先需要尽可能地找出相关文献中的相似部分,在这些相似部分发现有意义的差异。本文主要研究版本异文的信息处理,关于非版本异文的信息处理,我们将另文探讨。
我国异文研究历史悠久,古人对经传的注疏中就发掘了许多异文。近现代也有不少学者系统研究专书的版本异文[1-2]。语文学家的异文研究,主要依靠他们深厚的文献功底以及“博闻强记”的个性特征。先天的才能可遇而不可求。后天的努力人人可以做到,但皓首穷经实在代价太大。上世纪九十年代以来,学者们已经提出古籍和古汉语信息处理的任务[3-5],但尚未有人着手版本异文的信息处理。如果能够让计算机先列出异文候选,然后加以人工甄别,则可以收到事半功倍的效果。更进一步,计算机应该能够对搜罗到的异文按照研究者的要求进行初步的分类和统计,在此基础上对同一文献的各个版本做宏观的比较。
本文只研究异文的自动发现,处理的个案是三传春秋。《春秋》是我国现存最早的一部编年体史书,相传为孔子所著。因其过于简略,故后世诠释之作迭出。据《汉书·艺文志》记载,为《春秋》作传者共五家,现在流传下来的有《左传》、《公羊传》、《谷梁传》。三传仍按年代顺序,先列某年的春秋经,然后以经文为纲详述该年的重要历史事件或阐释经文的含义。三传所列的春秋经大体相同,但也有不少差异,可看做是《春秋》的三个不同版本。实验中所用的三传春秋经电子版均为GBK编码的繁体文本,来自香港中文大学中国文化研究所中国古籍研究中心开发的汉达文库*http://www.chant.org/。
本文以下部分的结构:第2节概述版本异文的特点,由此得出基本的处理步骤;第3节讨论句珠配对算法,句珠配对的评价函数为句珠相似度;第4节讨论异文配对算法,异文配对的评价函数主要是“同文”长度;第5节是简短的结论以及对古籍信息处理特点的认识。
2 版本异文的特点
版本异文的特点是文献的各个版本大同小异,具体来说有以下几个方面:
(一) 篇章结构大体相同,因此应该以篇章为单位进行处理,以免异文配对发生跨越篇章界限的错误。有时某个版本可能多出一些篇章,例如《红楼梦》有八十回版本与一百二十回版本。《公羊传》和《谷梁传》所列春秋经均截止于鲁哀公十四年“西狩獲麟”,《左传》所列春秋经则记述至鲁哀公十六年“孔丘卒”,显为后人所加。对于多出的篇章,不加比较也就是了。《春秋》的一个篇章就是其中所记述的一年,从隐公元年到哀公十四年,共242篇。
(二) 篇章内句子个数大体相同且基本对应,因此原则上可以根据标点分割句子,逐句进行比较。但是标点系后人所加,各个版本的断句或有不同*《左传》中的经与传有清楚的分隔。《公羊传》和《谷梁传》的经与传时有交错,这也是导致各版本的春秋经断句不同的原因之一。。当然,完全忽略这些标点也不可取,可能导致篇章范围内的异文配对错误。我们的做法是先按标点分割句子并隐去所有标点,接着将各版本中的句子拼接为“句珠”,寻找两版本之间相似度最大的句珠配对,然后在句珠中发现异文。
(三) 大多数句珠的文本是完全相同的,只需关注那些文本不完全相同的句珠。我们的基本方法是从句珠中去掉相同文字,遇到异文时再向后搜索相同文字以确定异文的右边界并输出异文,如此循环直至句珠遍历完毕。
篇章分割比较简单。本文只讨论句珠配对算法和异文配对算法。
3 句珠配对
“句珠”(sentence bead)这个术语是从机器翻译双语对齐研究中借用的。本文用这个术语指文献的两个版本中内容对应的句子*本文中句珠配对类似于双语的句子对齐,而异文发现则类似于双语的词汇对齐,但对齐方法有很大不同。。如果两个版本中的句子个数相同并且一一对应的,则无需配对。实际上两个版本断句常有不同,断句有粗有细,需要将一版本的几个短句拼接起来与另一版本的一个长句进行配对。除了“一对多”的情况之外,还可能有“多对多”等各种复杂情况。
句珠配对算法的目标是遍寻篇章内相似度最大的句珠,并输出所有包含异文的句珠(以下简称“异文句珠”)。
设两版本某篇章的句子序列分别为SA和SB,句子个数分别为为m和n,当前等待配对的第一个句子分别为SA[i]和SB[j],配对中最后一个句子分别为SA[p]和SB[q],则句珠配对的任务可表示为:
Bead(i,p;j,q)*
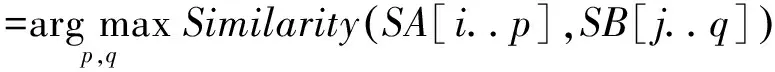
其中,i≤p≤m,j≤q≤n,SA[i..p]和SB[j..q]是句珠,Similarity是句珠的相似度函数,取值范围是0~1。相似度的计算方法在3.2节中讨论。本算法的任务就是要在所有可能的配对中找出相似度最大的句珠Bead(i,p;j,q)*。
3.1 句珠配对算法
算法的输入是来自版本A和版本B中对应篇章的句子序列SA[1..m]和SB[1..n]。所允许的配对类型为x:y,x和y最小值均为1,最大值为K。算法在SA[i..i+K-1]和SB[j..j+K-1]范围内寻找相似度最大的句珠SA[i..max_p]和SB[j..max_q],若相似度小于1则为异文句珠并输出之。在时间复杂度为O(K2) 的搜寻过程中,若发现将要添加的两个句子完全相同,则终止搜寻,这样不仅可以节省一些时间,而且可以使得到的句珠较短。句珠配对算法GetBeads伪码如下:
GetBeads(SA[1..m], SB[1..n]) {
for(i=1, j=1; i<=m and j<=n; ) {
max_simi=0; max_p=max_q=0;
for(p=i; p<=min(i+K-1, m); p++) {
for(q=j ; q<=min(j+K-1, n); q++) {
if(p>i and q>j and SA[p]==SB[q]) goto OUTPUT;
simi=Similarity(SA[i..p], SB[j..q]);
if(simi> max_simi) {
max_simi =simi;
max_p=p; max_q=q;
}
if(max_simi==1.0) goto OUTPUT;
}
}
OUTPUT:
if(max_simi <1.0) Output(SA[i..max_p], SB[j..max_q]);
i=max_p+1; j=max_q+1;
}
}
对于本文所研究的个案,设K=3。
本算法没有设置相似度阈值,因此即使是两个毫不相干的句子序列也能完成句珠配对,最坏情况是每个句珠的相似度均为0,且每个句珠中都只含一个句子。
3.2 句珠相似度计算
句珠相似度的计算方法有以下几种选择:
(一) 句珠中两个句子的相同字符个数与两个句子的字符总数之比。这种方法简单易行,但忽略了字符的排列顺序,例如下面两个句子将被认为是完全相同:
(3a) 宋人以齊人蔡人衛人陳人伐鄭 (《左传·桓公十四年》)
(3b) 宋人以齊人衛人蔡人陳人伐鄭 (《公羊传·桓公十四年》)
(二) 句珠中两个句子的共同前缀、共同后缀的长度之和与两个句子的字符总数之比。共同前缀是指两个句子开头的相同子串,共同后缀是指两个句子末尾的相同子串。例如,(3a)与(3b)的共同前缀是“宋人以齊人”,共同后缀是“人陳人伐鄭”。这种方法考虑了字符的排列顺序,大多数情况下是适用的。但如果异文恰好出现在句子的开头或结尾,计算结果就显得不够合理。例如,下面两个句子将被认为毫不相似:
(4a) 五月丙午及齊師戰于奚 (《公羊传·桓公十七年》)
(4b) 夏五月丙午及齊師戰于郎 (《谷梁传·桓公十七年》)
(三) 用1减去句珠中两个句子的编辑距离与最大长度之比。赵作鹏等提出了一种改进的编辑距离算法,拓展了交换操作,能够更精确地计算编辑距离[6]。但算法的时间复杂度较高,而且当其中一个句子拼接了下一句再进行比较时,需要重新计算编辑距离。
(四) 句珠中两个句子共有的bigram个数与两个句子的bigram总数之比。这里bigram是指两个相邻字符或只相隔一个位置的两个字符,这种方法的好处是既考虑了字符的排列顺序又能将子串相似性较为充分地表达出来。例如,(3a)与(3b)共有的bigram为“宋人、人以、宋以、以齊、人齊”等等,相似度为0.87,(4a)与(4b)的相似度为0.83. 当其中一个句子拼接了下一句再进行比较时,只需对添加的部分抽取bigram。因此,我们采用这种方法来计算句珠相似度。当两个句子长度均小于3时,无法抽取到足够的bigram,因此相似度定义为1.0(完全相同时)或0.5(共同前缀或共同后缀长度为1时)。
3.3 句珠配对结果
根据原有标点,《左传》春秋经1 834句(已去掉多出部分),《公羊传》春秋经1 761句,《谷梁传》春秋经1 825句。若忽略配对方向,例如1:2和2:1合并为1:2,则各种配对类型的频次统计如下:
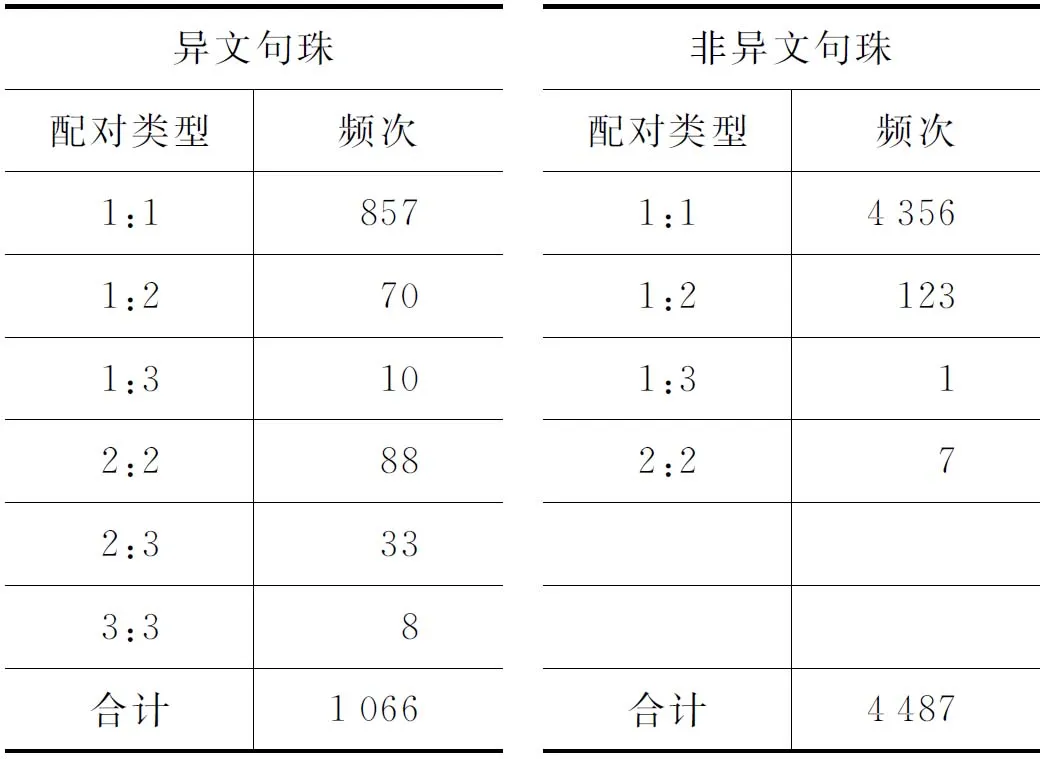
总共1 066个异文句珠中,见于《左传》与《公羊传》春秋经428个,见于《左传》与《谷梁传》春秋经255个,见于《公羊传》与《谷梁传》春秋经383个。从这个角度看,《左传》与《公羊传》春秋经的差异最大,《左传》与《谷梁传》春秋经差异最小。
下面(5a)两句处于篇末,(5a)第一句与(5b)第一句、前两句、全部三句的相似度依次为0.28,0.59,0.78,(5a)全部两句与(5b)第一句、前两句、全部三句的相似度依次为0.23,0.50,0.68:
(5a) 鄭伯髡頑如會未見諸侯丙戌卒于鄵 (《左传·襄公七年》)
陳侯逃歸
(5b) 鄭伯髡原如會 (《谷梁传·襄公七年》)
未見諸侯
丙戌卒于操
由此得到配对类型为1:3的异文句珠:
{“鄭伯髡頑如會未見諸侯丙戌卒于鄵”,“鄭伯髡原如會未見諸侯丙戌卒于操”}
下面(6a)与(6b)各有两句,都处于篇末。(6a)第一句与(6b)第一句、全部两句的相似度依次为0.86,0.68,(6a)全部两句与(6b)第一句、全部两句的相似度依次为0.72,0.87:
(6a) 十有二月己丑公及晉侯盟 (《左传·文公十三年》)
公還自晉鄭伯會公于棐
(6b) 十有二月己丑公及晉侯盟還自晉 (《公羊传·文公十三年》)
鄭伯會公于斐
由此得到配对类型为2:2的异文句珠:
{“十有二月己丑公及晉侯盟公還自晉鄭伯會公于棐”,“十有二月己丑公及晉侯盟還自晉鄭伯會公于斐”}
4 异文配对
这里从信息处理的角度将异文定义为:句珠中完全不同的两个子串。允许其中一个子串是空串,但不能都是空串。例如,“衛人蔡: 蔡人衛”不是一个异文,因为其中含有相同子串“人”,需分解为“衛:蔡”和“蔡:衛”两个异文。
按照这个定义得到的异文绝大多数是单字对单字,也有些是空串对单字、空串对多字、单字对多字、多字对多字,等等。例如:
(7a) 庚寅我入祊 (《左传·隱公八年》)
(7b) 庚寅我入邴 (《谷梁传·隱公八年》)
(8a) 邾人伐我南鄙 (《左传·襄公十五年》)
(8b) 邾婁人伐我南鄙 (《公羊传·襄公十五年》)
(9a) 戊子晉人及秦人戰于令狐晉先蔑奔秦 (《左传·文公七年》)
(9b) 戊子晉人及秦人戰于令狐晉先眛以師奔秦 (《公羊传·文公七年》)
(10a) 九月紀裂繻來逆女 (《左传·隱公二年》)
(10b) 九月紀履緰來逆女 (《公羊传·隱公二年》)
从语言学或历史地理学角度来看,(8)中的异文都应该是“邾:邾婁”,按本节的定义,这个异文是“◇:婁”,因为简单的字符串匹配并不能确定应把“邾婁”看做一个词还是把“婁”看做衍文。类似地,(9)中的异文本应是两处,“先蔑:先眛”和“◇:以師”,这里被当做是一处。可以考虑在本节异文发现算法的基础之上用统计方法得到更具语言学或文献学意义的异文数据。(10)中的异文该怎么算,可能依研究兴趣而有所不同。从文献学角度来说,应该认为“紀裂繻:紀履緰”是异文,从音韵学角度来说,应该认为有“裂:履”和“繻:緰”两处异文。
4.1 异文配对算法
异文配对算法的基本思想是:先去掉两个句子的共同前缀,使得异文出现在串首,然后从两个句子的串首开始搜索相同子串。与“异文”相对,相同子串可称之为“同文”。同文之前的便是异文*之所以要从串首开始搜索同文,是因为异文的某一方可能是空串。。如果句珠中有多处异文,则重复上述过程。
搜索同文时可能存在多个解。例如:
(11a) ……薛人杞人小邾人城成周
(11b) ……邾人薛人杞人小邾人城成周
此时同文有许多解,例如位置2:2上的“人”,依此得到异文“薛:邾”;位置4:4上的“人”,依此得到异文“杞:薛”,等等。其中同文最长的是最优解,因为同文越长,则左边的文字差异就越可靠。对于这个例子来说,位置1:3是最优解,因为从这个位置上开始的同文“薛人杞人小邾人城成周”最长,由此得到异文“◇:邾人”。
如果存在多个最长同文,则选择位置之差最小者。为便于观察,将例(3)重列于下:
(3a) 宋人以齊人衛人蔡人陳人伐鄭 (《公羊传·桓公十四年》)
(3b) 宋人以齊人蔡人衛人陳人伐鄭 (《谷梁传·桓公十四年》)
去掉共同前缀之后变为:
(3′a) 衛人蔡人陳人伐鄭
(3′b) 蔡人衛人陳人伐鄭
搜索到最长同文“人陳人伐鄭”,左边是“衛人蔡: 蔡人衛”。如前所述,其中含有同文“人”,不符合我们的定义,需要递归调用异文发现算法来处理。对此,向后搜索最长同文时有三个解,长度均为1,即2:2(“人”)、1:3(“衛”)和3:1(“蔡”),其中第一个解同文位置之差为0,故确定第一处异文“衛:蔡”。去掉共同前缀之后,可得到第二处异文“蔡:衛”。
异文配对算法的输入是句珠中的两个句子A和B,输出是句珠中的至少一处异文。
异文配对算法GetDiff描述如下:
GetDiff(A, B) {
while(!Empty(A) and !Empty(B) {
n=ComonPrefix(A, B); //求A和B的共同前缀的长度;
if(n>0) { Delete(A, 1, n); Delete(B, 1, n); }
if(Empty(A) and Empty(B)) return;
if(Empty(A)) { Output(“◇”:B); return; }
if(Empty(B)) { Output(A:“◇”); return; }
GetMaxCommonSubstr(A, B, startA, startB, ML); //搜索最长同文
if(ML==0) { Output(A:B); return; }
AL=Left(A, startA-1); BL=Left(B, startB-1); //获取串首的异文AL和BL;
if(AL和BL中含有相同字符) GetDiff(AL, BL); //递归处理
else Output(AL:BL);
Delete(A, 1, startA+ML-1); Delete(B, 1, startB+ML-1);//去掉异文和最长同文
}
}
GetMaxCommonSubstr的功能是从串首开始搜索最长同文在A和B中的起点startA和startB,最长同文的长度为ML,详后。
4.2 搜索最长同文
采用穷尽搜索方法来搜索最长同文。设串A和串B的长度分别为m和n, startA、 startB和ML是三个输出参数。若有多个长度相等的最长同文,取起点距离差最小者。如果串A或串B的剩余子串长度小于已经得到的ML,则尽早退出。
GetMaxCommonSubstr(A,B,&startA,&startB,
&ML) {
ML=0;
MXD=100;//MXD是最小距离差
for(i=1; i<=m; i++) {
if(ML>len(A)-i+1) break;
for(j=1; j<=n; j++) {
if(ML>len(B)-j+1) break;
if(A[i]==B[j]) {
LD=Abs(i-j); //LD是距离差
L=CommonPrefix(substrc(A,i),substrc(B,j));
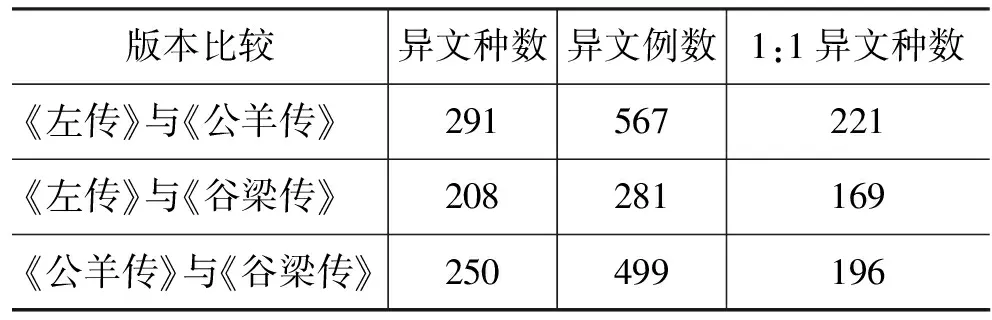
if(L>ML or L==ML and LD startA=i; startB=j; ML=L; MXD=LD; } } } } } 从1 066个异文句珠中,共得到异文共560种,1 347例,其中频率最高的是“婁:◇”126例,“◇:婁”123例。出现10例以上的还有:“鄫:繒”26例,“運:鄆”15例,“鄆:運”15例,“築:筑”15例,“丑:醜”12例,“率:帥”11例,“帥:率”11例,“蒐:搜”10例。 若忽略异文配对方向的差异,560种异文可按字数归纳为7种类型,下表中“3_”表示三字或三字以上: 异文类型异文种数异文类型异文种数0:1661:2100:2171:3_50:3272:2311:1404 三传春秋经两两比较,异文分布情况如下: 版本比较异文种数异文例数1:1异文种数《左传》与《公羊传》 291567221《左传》与《谷梁传》 208281169《公羊传》与《谷梁传》250499196 以上数据进一步表明,《左传》与《公羊传》春秋经的差异最大,《左传》与《谷梁传》春秋经差异最小。 本文首次提出古籍版本异文信息处理的任务,并实现了有关句珠配对和异文配对的算法。句珠配对全部正确,异文配对算法也能够正确发现全部符合定义的异文。 本文定义的异文是“句珠中完全不同的两个子串”,这个定义没有利用任何有关具体文献中的语言知识和其他知识,因此相关的异文发现算法是通用的,可以用于发现任何中文文献的版本异文,包括古代文献和现代文献。 当然,我们关注的重点仍在于古籍信息处理。古籍信息处理的特殊性在于,语料库是封闭的、有限的。拿先秦文献来说,全部传世文献也只有大约260万字。因此,现代汉语文本处理的模式“训练—标注”不很适用,应该主要发展基于规则的方法,使得不需要经过训练即可获得质量较高的处理结果。 [1] 李富孙.春秋三传异文释[M]. 上海商务印书馆,1935. [2] 李索.敦煌写卷〈春秋经传集解〉异文研究[M]. 中国社会科学出版社,2005. [3] 张普. 计算机在古籍整理研究领域中的应用(综述)[M]//张普.汉语信息处理研究.北京语言学院出版社,1992:80-103. [4] 常娥,侯汉清,曹玲. 古籍自动校勘的研究和实现[J]. 中文信息学报,2007, 21(2):83-88. [5] 姜哲,马少平,夏莹.大型中文古籍《四库全书》自动版面分析系统[J]. 中文信息学报,2000,14(2):14-20. [6] 赵作鹏,尹志民,王潜平,等. 一种改进的编辑距离算法及其在数据处理中的应用[J]. 计算机应用,2009,29(2):424-426.4.3 异文配对结果

5 结语
