面向统计机器翻译的重对齐方法研究
2010-06-05李天宁陈如山朱靖波王会珍
肖 桐,李天宁,陈如山,朱靖波,王会珍
(东北大学 自然语言处理实验室,辽宁 沈阳 110004)
1 引言
词对齐是统计机器翻译的重要组成部分[1]。通常情况下高质量的词对齐结果可以带来统计机器翻译系统翻译性能的提高[2-3]。现在大多数统计机器翻译系统都是利用IBM models[4]来进行词对齐。但是在IBM models中一个源语言单词最多只允许对应一个目标语单词。因此IBM models生成的词对齐一般也被称作非对称的词对齐。为了获得对称的词对齐,需要利用IBM models得到源语言→目标语言(正向)和目标语言→源语言(反向)双向对齐的结果,之后在双向对齐的基础上自动得到对称的词对齐结果。在这个过程中,一个关键的问题就是解决双向对齐的不一致性。图1展示了一个在真实数据中由IBM models生成的双向词对齐的实例。在这个实例中,源语言单词“欧盟”和目标语单词“Europe”在正反双向词对齐中均被对应上,于是我们称双向词对齐在“欧盟”和“Europe”之间的对齐上是相交的或一致的。相反,“欧盟”和“Union”在反向词对齐中被对应上,而在正向词对齐中却没有被对应上。这时我们称双向词对齐在“欧盟”和“Union”之间的对齐上是有歧义的或不一致的。对于这种情况,我们需要判断“欧盟”和“Union”是否在最终的词对齐结果中被对齐。在本文中,我们称片断对(“欧盟”, “Europe Union”)有相交型歧义,而(“欧盟”, “Europe Union”)被称为相交型歧义块。
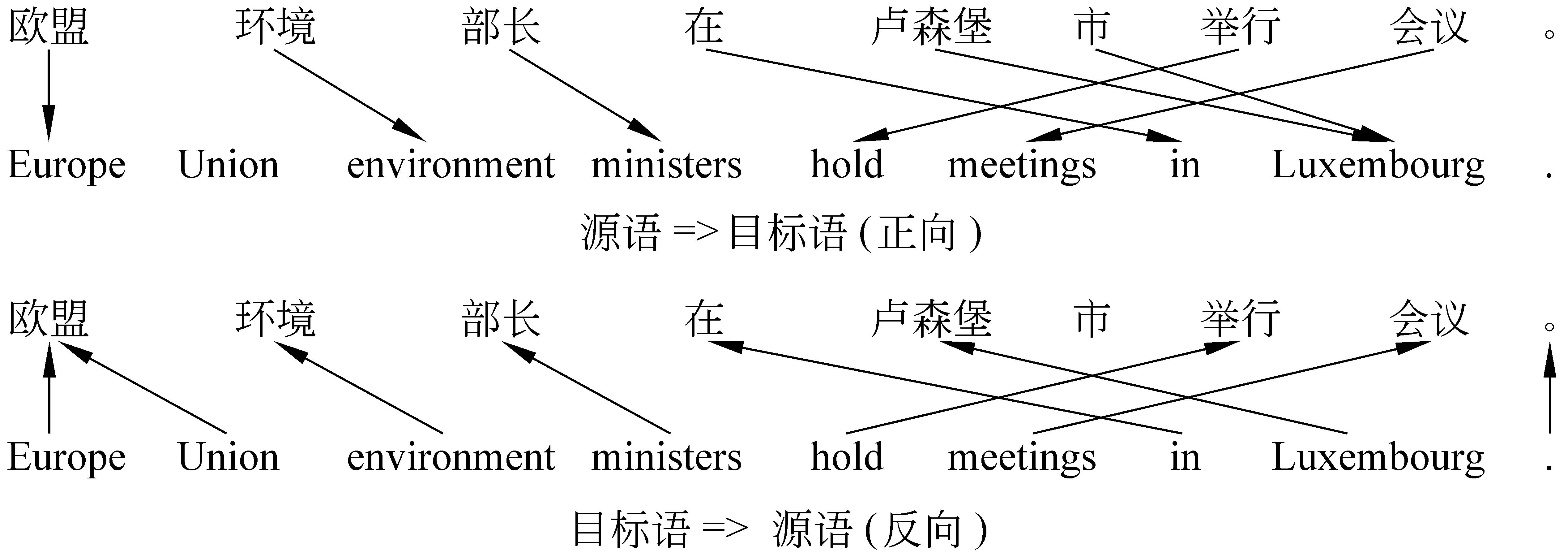
图1 正反双向词对齐实例
通常情况下,不一致的词对齐是频繁出现的(比如在我们的汉英翻译实验中有超过50%的词对齐链接在双向词对齐中是不一致的),因此提高相交型歧义块中的词对齐的准确率将会有助于最终词对齐准确率的提高。对于这个问题,现在广泛采用的解决办法是,利用启发信息来判断有歧义的对齐的正确性[1-2]。但是由于这个方法只考虑了锚点(比如:双向对齐的交集部分)和对齐点的相对位置信息,它更适用于翻译顺序相对一致的语言对,如:法语英语。而在语序差异极大的语言之间,经常会出现翻译的远距离调序现象,比如:汉语英语之间的远距离调续。这时仅使用启发信息并不能得到很好的对齐结果。针对这个问题,本文提出了一个对相交型歧义块进行重新对齐的方法。它使用了翻译概率,扭曲度概率和产出率概率等多个特征共同作用来得到对称化的词对齐结果。此外,本文还对这个方法进行了改进,使它能够利用大规模单语语料得到更好的词对齐结果。
为了检验本文提出的方法的有效性,我们把它应用到基于短语的统计机器翻译系统中。在汉英翻译任务上的实验结果表明,本文提出方法要优于现在广泛使用的基于启发信息的方法。此外,我们的实验结果还表明使用单语语料有助于进一步提高词对齐的性能。
2 问题描述
2.1 词对齐形式化描述
假设f=f1f2…fJ和e=e1e2…eI分别表示源语和目标语词序列,其中J和I表示序列长度。f和e之间的词对齐可以表示为一个函数a:J×I⟹(0,1),对于任意(j,i) (1≤j≤J∧1≤i≤I)有:当fj和ei之间有对齐关系,a(j,i)=1;否则a(j,i)=0。在本文中我们称a(j,i)为对齐函数。对于任意一个(j,i),如果a(j,i)=1,我们称(j,i)为一个对齐链接。如果有两个对齐函数a1和a2满足对任意的(j,i),都有a1(j,i)≤a2(j,i),我们称a1⊆a2*这里我们借用了集合的饱含关系的表示方法。这里我们把一个对齐函数中满足a(j, i)=1的所有(j, i)看成一个集合。。考虑词对齐的方向,我们使用af→e(j,i)表示从f到e的词对齐函数(正向词对齐),ae→f(j,i)表示从e到f的词对齐函数(反向词对齐)。在此基础上,我们定义正反双向词对齐的并集为aunion,它满足aunion(j,i)= 1 iffaf→e(j,i) = 1∨ae→f(j,i)=1;正反双向词对齐的交集为ainter,它满足ainter(j,i)=1 iffaf→e(j,i)=1∧ae→f(j,i)=1。
2.2 相交型歧义块定义
在给出相交型歧义块的定义之前,我们先给出块(block)的定义。假设fj1…fj2和ei1…ei2分别是f和e中的两个词序列,aunion为(f,e)之间正反双向词对齐的并集,如果
(1)
我们称序偶(fj1…fj2,ei1…ei2)是一个翻译对或块,并把它表示成B(fj1…fj2,ei1…ei2)。这个定义意味着(fj1…fj2,ei1…ei2)中没有词被对齐到(fj1…fj2,ei1…ei2)以外。可以看出这个定义本质上与基于短语的统计机器翻译[1]中的短语对的定义是一致的。
给定正反双向词对齐af→e,ae→f和一个块B(fj1…fj2,ei1…ei2),如果有一个(j,i) (j1≤j≤j2∧i1≤i≤i2)满足af→e(j,i)=1∧ae→f(j,i)=1,我们称af→e(j,i)和ae→f(j,i)在(j,i)上是相交的或一致的。如果af→e(j,i)≠ae→f(j,i),我们称fj和ei之间的对齐链接有(相交型)歧义。如果B(fj1…fj2,ei1…ei2)包含歧义链接,而且B(fj1…fj2,ei1…ei2)中没有其他块包含歧义链接,我们就称B(fj1…fj2,ei1…ei2)为相交型歧义块(Overlapping Ambiguous Block,OAB),并把它记为OAB(fj1…fj2,ei1…ei2)。实际上,OAB的定义保证了任意一个OAB不能嵌套地包含其他OAB,而且与其他任何OAB都不相交。例如,在图1中所示的对齐实例中包含两个OAB:OAB(“欧盟”,“Europe Union”)和OAB(“卢森堡市”, “Luxembourg”)。
2.3 重对齐
在本文中,重对齐是指根据正反双向词对齐的结果重新对双语句对进行对齐,以得到完整的对称化的词对齐结果。显然,对于双语句对中的非OAB的部分来说重对齐是比较简单的,因为我们只需把双向词对齐的交集部分作为最终的对齐结果即可。而对于OAB来说,重对齐任务要难得多,因为我们要对其中的每个歧义链接进行消歧。而本文的工作也正是集中在对OAB的重对齐任务上。在这个任务中有如下两个问题需要解决:
a) 给定双语句对(f,e)和它们之间的正反双向词对齐结果,如何得到所有的OAB。
b) 如何定义OAB上最优的词对齐,如何高效地搜索最优词对齐。
我们把第一个问题称作相交歧义块识别问题,把第二个问题称作OAB的重对齐问题。
3 相交歧义块识别
根据OAB的定义,我们给出了一个能够得到所有OAB的OAB快速识别算法。

输入: 双语句对(f, e)和正反双向词对齐结果af→e和ae→f输出: (f, e)包含的所有OABStep1: 得到所有歧义链接,把它们保存在ambilink[0…l]中Step2: fork=0 to l-1 do if Checked(f[ambilink[k].j]) do next FSegStart=FSegEnd=ambilink[k].j ESegStart=ESegEnd=ambilink[k].i FoundOABFlag=false while notFoundOABFlagdo Step2.1: 根据ae→f,ESegStart,ESegEnd和e更新FSegStart和FSegEnd Step2.2: 根据af→e,FSegStart,FSegEnd和f更新ESegStart和ESegEnd Step2.3: 如果无更新,把FoundOABFlag设为true 把B(FSegStart, FSegEnd, ESegStart, ESegEnd)存入OABList 把f[FSegStart...FSegEnd] 标记为“checked”Step3: fori=0 to OABList.length-1 do if OABList[i]没有被OABList中的其他元素覆盖do输出OABList[i]
这个算法的核心思想是,根据每个歧义链接进行扩展,直到得到包含它的OAB。算法中的Step2.1和Step2.2实际上就是对当前得到的含有歧义链接的块进行判断,如果在这个块的外部仍有歧义链接对应到块中的某些词(源语词或者目标语词)就更新块的范围使其包含这个歧义链接。当这个块无法被更新时,表示得到OAB,退出循环。这个算法的时间复杂度为Θ(I·J)。相比最直接的遍历方法(时间复杂度为Θ(I2·J2)),它具有更高的运行效率。
4 重对齐模型
4.1 模型1
首先,为了简化OAB的重对齐问题,我们假设:
a)OAB中的词对齐是上下文无关的。对于一个OAB,其他OAB不会影响它的对齐结果。
b)OAB中的词对齐 与双向词对齐的并集aunion是兼容的,即a⊆aunion。
根据这两个假设,我们定义OAB(fj1…fj2,ei1…ei2)上最优的词对齐为:
abest=arg maxa⊆aunionScore(a,OAB)
(2)
其中Score(a,OAB)是一个函数用来评价对齐a的好坏程度。由于直接在整体上对OAB中的词对齐进行评价是比较困难的,我们把Score(a,OAB)定义为如下形式:
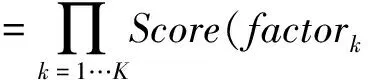
(3)
其中{factor1(a,OAB),…,factorK(a,OAB)}表示影响词对齐的各个因素的集合。沿用经典的IBM models[4]的思路,本文定义了三个影响OAB中的词对齐的因素,它们是:翻译概率(Translation Equivalent Probabilities),扭曲度概率(Distortion Probabilities)和产出率概率(Fertility Probabilities)。于是我们得到,
(4)
其中,
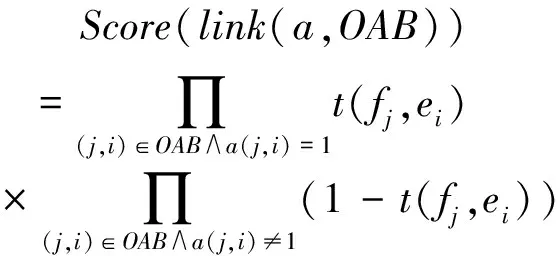
(5)

(6)
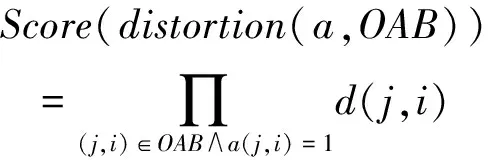
(7)
这里Score(link(a,OAB))表示整个词对齐所对应的翻译概率, 表示fj和ei互为翻译的联合概率。Score(fertility(a,OAB))表示OAB生成一定数量链接的概率,这里n(φw|w)表示一个单词w对应φw条链接的概率。Score(distortion(a,OAB))表示词对齐所对应的整体调序概率,这里d(j,i)表示源语言第j个词与目标语上第i个词之间有链接的概率。
对于模型的参数估计,我们直接使用IBM model 3得到n(φw|w)的估计。而对于t(fj,ei),我们在训练语料的aunion上,使用极大似然估计(Maximum Likelihood Estimation, MLE)的方法对其进行估计,即:t(fj,ei)=count(fj和ei之间有链接)/count(fj和ei共现)。对于d(j,i),我们采用了一个简单的估计方法(或者说定义),d(j,i)=α|i-I·j/J|。这里|i-I·j/J|表示在对齐矩阵中(j,i)与对角线的相对距离,距离越远表示调序的程度越大。α<1.0是调解因子,在本文中我们通过实验的方法得到α的最优值0.9。
4.2 模型2
在语言的使用中,我们常常会用多个连续的词来表达一个概念,比如汉语和英语中的名词短语。如果一个连续的词序列频繁地共现,那它们很有可能在集中描述一个概念,在对齐中被作为一个单元的可能性就越大。比如,如果源语言句子中的某个词序列中的每个词都对应到目标语句子的相同部分,这个词序列就很有可能构成一个对齐单元。如果我们能很好的度量一个词或词序列表达同一个概念的可能性大小,那么这个信息就可以帮助我们得到更好的词对齐结果。基于这个想法,我们在模型1的基础上引进了一个新的单语特征,用它来度量在对齐中每个对齐单元的好坏程度。定义如下:
(8)
其中,
(9)
这里a(w)表示所有与w有对齐关系的词的集合,|a(w)|表示与w有对齐关系的词的数量。m(a(w))是对a(w)作为一个对齐单元可靠性的度量。本文中,我们把m(a(w))定义为(以m(a(fj))作为实例,对于m(a(ei))可以同理推得),
(10)
这里Pr(ek)和Pr(ep…eq)表示ek和ep…eq在单语(目标语)中出现的概率,它们可以直接通过MLE方法在单语语料上进行估计。
4.3 搜索
对于一个OAB,如果它包含l个aunion的链接,那么搜索最优对齐的搜索空间为2l。对于大部分OAB来说,l都是一个比较小的值,这时我们可以直接使用全搜索的方法来得到abest。而对于l比较大的情况(l≥lmax),我们使用了一个基于栈的解码器来搜索abest。它联合使用了翻译概率和扭曲度概率作为启发函数来对abest进行搜索。这里lmax是一个阈值,我们用它来限定需要剪枝处理的链接数的下限。
此外,还可以利用ainter来进一步缩小搜索空间。通常ainter包含的都是准确的词对齐,因此可以把它作为对齐锚点。这样,在提高搜索效率的同时,可能会进一步提高性能。利用ainter作为锚点后搜索空间可以被进一步限制在ainter⊆a⊆aunion范围内。
5 实验
5.1 测试方法及实验用数据
我们把本文提出的方法应用到实际的汉英统计机器翻译系统中来验证它的有效性,并使用大小写不敏感的BLUE4做为翻译质量的评价指标。
实验所使用的训练和测试数据是SSMT2007官方提供汉英机器翻译任务用数据,包括:训练语料约80万句对,开发集500句(每句4个参考译文),测试集1 002句(每句4个参考译文)。在使用前,我们首先用东北大学自然语言处理实验室所开发的中文分词工具*http://www.nlplab.com/对中文句子进行分词,并用一个基于规则的tokenizer对英文句子进行切分,此外我们还去掉了英文单词的大小写信息。我们使用了部分LDC提供的语料作为训练重对齐模型2所使用的源语和目标语的单语语料,包括大约180万句的中文和180万句英文单语语料。
5.2 基准系统
本文采用基于短语的统计机器翻译系统moses*http://www.statmt.org/moses/作为实验的基准系统。其中,我们用基于IBM models的GIZA++*http://www.fjoch.com/GIZA++.html获得了正反双向词对齐结果。为了对比本文提出的方法,我们采用了三种基于启发信息的词对齐对称化方法“intersection”,“union”和“refined”作为从正反双向词对齐获得对称的词对齐的baseline方法[2]。这里“intersection”“union”和“refined”分别是指:双向对齐的交集,双向对齐的并集,在双向对齐的交集的基础上利用启发信息进行扩展并考虑对齐矩阵中对角线位置的信息这三种方法*“refined”方法是moses工具包所使用的缺省方法。它也被称作“intersect-diag-grow”方法。。此外我们利用SRLIM工具在实验用的英文单语语料上训练了5-gram语言模型。对于短语抽取和decoder,我们都使用了moses工具包所提供的程序,并采用缺省设置。此外,我们使用了最小错误率训练来对参数进行优化。
5.3 Baseline vs.重对齐
在进行重对齐之前,我们首先进行了双向词对齐,之后识别出了训练语料中所有的OAB。表1给出了相关的统计信息。可以看出,平均每个句对包含大约1.65个OAB。这表明OAB在汉—英机器翻译中的词对齐任务中是很常见的。此外我们在实验中还发现绝大多数的OAB(>80%)包含的链接数小于等于15。因此,在随后的所有实验中我们均设置lmax=15来对包含链接数大于15的搜索进行剪枝。
在识别OAB之后我们分别利用本文提出的重对齐模型1和模型2进行了重对齐,并把得到的对齐结果用于基准统计机器翻译系统中。在实验中,我们并没有利用锚点ainter对搜索进行剪枝。实验结果如表2所示。可以看出在三种Baseline方法中,“refined”方法取得了最好的性能,其次是“union”方法。不过,“intersection”方法却取得了比前两种方法差很多的性能。这主要是由于,“intersection”方法会产生非常稀疏的对齐结果,这会导致短语表中噪声的增加,并最终降低翻译质量。相比Baseline方法,本文提出的方法得到了更高的BLUE值。重对齐模型1和模型2比最高的Baseline方法分别高出0.59和0.68个点。这说明了本文提出的方法的有效性。此外,模型2比模型1取得了更好的性能,这也说明了使用单语语料也可以进一步改善词对齐的质量,并间接提高统计机器翻译系统的性能。

表1 词对齐统计信息

表2 Baseline及重对齐模型性能

表3 使用锚点信息后的性能
5.4 锚点信息的使用
根据4.3节的论述,我们可以使用ainter作为锚点来缩小搜索空间。表3给出了模型1和模型2使用锚点信息后的翻译性能。有趣的是,对于模型1,锚点信息的使用带来了翻译性能的进一步提高,相比5.3节的实验结果又提高了0.09个点。而模型2在使用锚点信息之后翻译性能却下降了0.02个点。这个实验结果说明,在OAB中,模型的最优解abest不一定总包含ainter。虽然在整体上ainter中的对齐准确率较高,但它并不一定能带来OAB重对齐性能的提高。
5.6 单语语料规模大小对性能的影响
在最后一组实验中,我们对单语语料规模大小对重对齐模型2的性能的影响进行了研究。我们分别用20%,40%,60%,80%和100%的单语语料训练,得到了模型2的对齐结果。除了在40%时性能略有下降外,翻译性能基本上是随着单语语料数量的增大而提高。但最大的提高只有0.2个点。这说明虽然我们可以利用单语语料来提高模型2的性能,但性能提高的幅度有限。我们还发现,当单语语料规模达到一定大小后(比如实验用单语语料的80%)翻译性能趋于平稳。这表明,在我们的方法中,单纯地增大单语语料规模并不能有效地提高翻译翻译准确性。
6 相关工作
Koehn等人[1]以及Och和Ney[2]研究了利用双向非对称的词对齐得到对称的词对齐的方法。在他们的方法中,首先把正反双向词对齐的交集部分固定,之后利用启发信息来扩展固定部分。但是这种基于启发信息的方法更倾向于含有局部调序的对齐,而对于语序相差很大的语言间的对齐的性能并不是很好。Liang等人[5]提出了一种利用最大化正反双向对齐的一致部分的似然概率的方法来得到更好的词对齐结果。与Liang等人工作不同,我们的工作集中在正反双向对齐不一致的部分。也就是说我们更关心重新对齐那些正反双向训练下IBM modes不能达成一致的对齐。
还有其他一些工作主要集中在利用判别模型来进行词对齐[6-9]。他们把词对齐转化为有指导或半指导的分类任务,并利用多个特征共同作用得到对齐结果。不过,这些方法均需要人工标注的词对齐的训练语料,训练数据的构造代价比较昂贵。
此外,本文工作与其他相关工作的另一个重要不同是,我们提出的重对齐方法可以利用单语语料来进一步提高性能。而这个问题在以前的工作中并没有被很好地讨论过。
7 讨论
在模型的参数估计方面,本文分别对不同的参数采用了不同的估计方法。这么做的好处在于方法简单,而且系统易于实现。实际上,也可以考虑利用EM等无指导的学习方法,来最大化词对齐在整个训练集上的似然概率(可以把目标函数看做词对齐的可能性的度量),同时得到更好的参数估计结果。
此外,在本文提出的模型中,我们使用了多个特征得分的乘积(或者说是log线形加)的形式来表示一个词对齐的得分。但是这些特征的权重都是相等的(都为1)。实际上,也可以通过调整特征的权重使模型取得更好的性能。不过,我们需要使用少量带有人工标注词对齐的开发集来优化这些权重。
8 结论及未来工作
本文提出了一种重对齐方法,它在IBM models生成正反双向词对齐的基础上,对双向对齐有歧义的部分进行重新对齐,最终得到完整的对称的词对齐结果。此外,这个方法可以利用单语语料来进一步改进词对齐结果,不过性能提高的幅度有限。相比在统计机器翻译中广泛使用的基于启发信息的词对齐对称化方法,文本提出方法可以使统计机器翻译系统得到更高的翻译准确率。在以后的工作中,我们会对重对齐模型的参数估计和模型最优解的搜索等问题做进一步研究。
[1] Philipp Koehn, Franz Josef Och ,and Daniel Marcu. Statistical Phrase-Based Translation [C]//Proc. of HLT/NAACL2003. 2003: 48-54.
[2] Franz Josef Och and Hermann Ney. A systematic comparison of various statistical alignment models [J]. Computational Linguistics, 2003, 29(1):19-51.
[3] Alexander Fraer and Daniel Marcu. Measuring word alignment quality for statistical machine translation [R]. Technical Report ISI-TR-616. ISI/University of Southern California, 2006.
[4] Peter F. Brown, Stephen A. Della Piatra, Vincent J. Della Pietra, and R. L. Mercer. The mathematics of statistical machine translation: Parameter estimation [J]. Computational Linguistics. 1993, 19(2):263-311.
[5] Percy Liang, Ben Taskar, and Dan Klein. Alignment by agreement [C]//Proc. of HLT/NAACL2006. 2006: 104-111.
[6] Yang Liu, Qun Liu, and Shouxin Lin. Log-linear models for word alignment [C]//Proc. of ACL2005. 2005: 459-466.
[7] Alexander Fraer and Daniel Marcu. Semi-Supervised Training for Statistical Word Alignment [C]//Proc. of ACL2006. 2006: 769-776.
[8] Abraham Ittycheriah and Salim Roukos. A maximum entropoy word aligner for Arabic-English machine translation [C]//Proc. of HLT/EMNLP2005. 2005: 89-96.
[9] Ben Taskar, Simon Lacoste-Julien, and Dan Klein. A discriminative matching approach to word alignment [C]//Proc. of HLT/EMNLP2005. 2005: 73-80.
