统计机器翻译中多分词结果的融合
2010-06-05马永亮赵铁军
马永亮,赵铁军
(哈尔滨工业大学 教育部—微软语言语音重点实验室,黑龙江 哈尔滨 150001)
1 引言
汉—英统计机器翻译中:中文语料是由一个个以字为基本单位的句子组成。这与大多数欧洲语言不同,它们的句子是由自然切分的单词组成的。有研究人员进行了实验[1],基于单个字切分的汉语语料不能使统计机器翻译获得最好的性能。对于实际的汉—英统计机器翻译系统,常常需要使用中文分词工具对汉语语料进行预处理。
中文分词的方法较多, 最早有一些基于最大匹配或者基于词典的方法 , 随后出现了基于层次隐马尔可夫的中文分词方法[2]。最近,许多state-of-the-art 机器学习算法被广泛应用在自然语言处理领域,比如最大熵,支持向量机,条件随机域等。基于这些机器学习算法,研究者提出了相应的中文分词方法[3-5]。除了众多的中文分词方法,中文分词还使用了几种不同的中文分词标准,比如CTB,PKU,MSR等等。这些标准定义了不同的分词原则,这使得同样的中文语料在使用不同标准的分词工具处理后分词结果也有较大的差别。例如,图1给出一个简单句对的两个分词结果和相应的词对齐结果。

图2 复杂句对的分词结果和词对齐
无疑这两种分词结果都是正确的,但是某些情况下我们更希望是第一个分词结果。因为,在这种情况下我们能够从句对中获得词对齐信息“煎—Fried”。再给出一个对中文分词来说更加难以面面俱到的例子。我们的目标是翻译“能把腰部弄短吗?”,当翻译结果是“Can you shorten the waist ?”,图2(a)中的分词和对齐结果没有问题。但是,如果翻译结果是“Can you make the waist a little shorter?”, 我们更倾向于使用图2(b)中的中文分词结果。我们认为基于不同方法和分词标准的中文分词工具产生的结果尽管不同,但是在特定的上下文和语义中他们都可能是正确而有用的。
这些通用中文分词方法并不是为统计机器翻译量身定做的,他们的分词结果对统计机器翻译而言也就不可能是优化的。近些年许多研究者对中文分词在统计机器翻译中的影响进行了广泛而深入的研究。文献[1,6]将中文分词集成到统计机器翻译系统的模型训练和解码过程中,Chang[7]等的研究表明分词的一致性和分词的粒度对统计机器翻译是重要的, 并且提出了一种直接针对统计机器翻译对分词的粒度进行优化的方法。Zhang等[8]进行了比较综合的研究。 在文献[8]中, 作者对中文分词和统计机器翻译的关系进行了细致的分析, 包括分词标准、未登录词、切分错误等对SMT的影响。
在文献[1,6]和文献[7]中,作者的主要目的是针对统计机器翻译来优化中文分词方法。总的来说,他们要找到单一的一种中文分词方法,从而尽可能使分词结果适合统计机器翻译。但是从我们的观点考虑,我们可以利用基于不同分词方法和不同分词标准的分词工具的结果,从中获得对统计机器翻译而言有用的信息。我们研究的出发点与文献[8]中融合多个不同分词结果训练的模型是一致的。通过进一步研究,我们给出了更一般的结论。
2 层次短语翻译模型
从Brown等人提出统计机器翻译方法[9],统计机器翻译已经逐渐成为机器翻译的主流技术。多年来,基于短语的统计机器翻译[10]、log-linear模型[11]、最小错误率训练[12]等较大地提高了统计机器翻译系统的性能,基于句法的统计机器翻译也逐渐发展起来。
本文使用的统计机器翻译系统是新近兴起的一种基于句法的统计机器翻译系统[13]——层次短语翻译模型,该模型建立在上下文无关文法的基础之上。给定源语言句子f和一个同步上下文无关文法,则存在有多种推导得到源语言端的f,因此也就对应着会有多种可能的翻译结果e。在log-linear模型框架下,可以对每种推导如下建模:

(1)


(2)
式中f(D)是推导D对应的源语言句子,e(D)是推导D对应的目标语言句子。
在我们的系统中,我们使用了7个特征,短语翻译概率, 反向短语翻译概率, 词汇化权重, 反向词汇化权重,词汇惩罚,规则惩罚,Glue规则惩罚和目标语言语言模型。这些特征的权重通过最小错误率训练进行优化[12]。
3 多分词结果融合
3.1 三个中文分词工具
HIT中文分词系统[14]的基本方法是基于词典的。为了获得更高的分词精度,HIT 中文分词系统在全切分的基础上加入了多步处理策略。ICTCLAS[3]是基于层次隐马尔可夫模型的中文词汇分析系统。ICTCLAS可以同时提供中文分词,词性标注,中文命名实体识别。Stanford Chinese Word Segmenter[7]是基于条件随机域模型的中文分词系统。模型除了使用字符、字形、字符复现等特征外,还加入了词汇化特征。
3.2 翻译模型特征插值
我们将不同分词结果对应的训练语料看成训练数据的几个部分,然后对应每个部分训练一个模型,最后根据目标调整各个模型的权重。通常可以通过两种方式完成这样的工作。
第一种方式是线性的,在实际应用中被广泛采纳,可以表示为:
p(x|h)=∑cλcpc(x|h)
(3)
式中p(x|h)是混合后的模型,pc(x|h)是从部分c上训练的模型,λc是对应的权重。
第二种是log linear模型,可表示为:
(4)
式中ac可以通过全局优化得到。本文使用了与Zhang等[7]相同的方法, 采用线性的方式对多分词结果进行融合,称为翻译模型线性插值。
翻译模型的特征插值就是对相同类型的特征进行线性插值计算。使用前面提到的3个中文分词工具对汉英平行语料中的中文部分进行分词处理,由此得到对应的3个经过分词的汉英平行语料。然后这3个平行语料分别用于训练各自的层次短语翻译模型。特征插值的计算可以描述如下:
λipi(x|h)
(5)

3.3 翻译模型特征插值
在文献[8]中, 特征融合被用于与特征插值进行比较。特征融合首先要定义一个主模型,除主模型外的其他模型被定义为辅助模型。然后,将在辅助模型中的翻译条目加入到主模型中。与特征插值不同的是,只有那些在主模型中没有的翻译条目才从辅助模型中加入到主模型中,并且每个翻译条目的各个特征值不变。文献[8]中的实验结果显示特征插值要比特征融合性能更好,但是并没有进一步深入研究这一原因。本文继续使用文献[8]中对特征融合的定义,我们的研究重点是如何利用多分词结果提高统计机器翻译性能。我们认为翻译模型的特征融合是比翻译模型的特征插值更有潜力的方法,因为这种方法基于一个明显的事实:更多的信息会有效地扩大模型的空间,如果能够有效地控制模型空间增长带来的噪声问题,那么翻译模型的特征融合技术就有希望获得较好的性能。我们在文章中只探讨两个模型的特征融合。
3.4 特征融合的策略
除去翻译模型中的特征值,模型中的翻译条目由两部分组成源语言部分f和对应的目标语言部分e。我们将辅助模型分为4部分:
•f|||e,f是源语言部分,e是对应的目标语言部分。它们已经在主模型中成对出现。


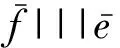
此外,文献[15]中提出将特征插值和特征融合的方法结合起来。实验结果表明,将特征插值和特征融合结合并不能获得更好的性能。
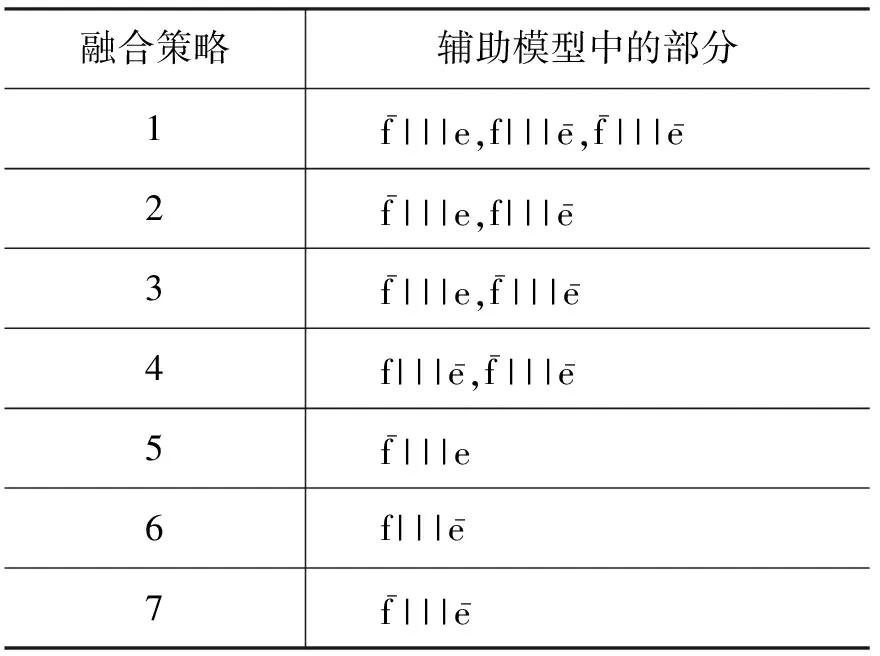
表1 特征融合的策略
4 实验
4.1 系统
我们的实验平台是一个用C++实现的层次短语翻译系统[13]。训练过程中使用GIZA++获得词对齐,使用SRI Language Modeling Tookit[16]训练modified-KN平滑的3-gram语言模型。
4.2 训练集和测试集
我们在小规模口语汉英平行语料上进行了实验。实验的语料采用IWSLT2004的训练集和测试集。实验采用自动翻译评价,使用了大小写相关的BLEU-4自动翻译评价指标[17]。 训练集的英语部分用来训练语言模型。为了优化系统的特征权重,使用最小错误率训练来最大化系统在开发集上的BLEU得分。最后,系统将使用不同的模型在测试集上进行测试。训练集和测试集的详细信息见表2。
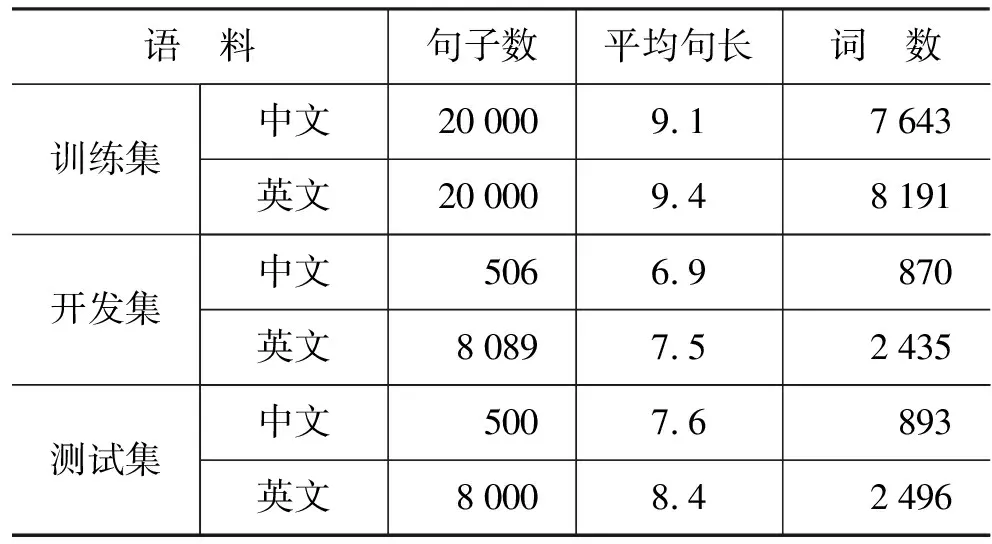
表2 IWSLT2004语料
4.3 实验结果
实验中,我们使用没有加入任何模型优化方法的层次短语翻译系统作为Baseline系统。在Baseline系统的实验中,所有中文语料均使用HIT中文分词系统进行分词。表3给出了Baseline系统的实验结果。表4给出了用Stanford和ICTCLAS分词系统对所有中文语料进行分词后系统的实验结果。

表3 Baseline实验结果

表4 Stanford和ICTCLAS实验结果
我们对所有7个特征融合策略进行了两组实验。第一组实验使用HIT中文分词系统处理的训练语料作为主模型的训练语料,Stanford中文分词系统处理的训练语料作为辅助模型的训练语料;第二组实验使用HIT中文分词系统处理的训练语料作为主模型的训练语料,ICTCLAS分词系统处理的语料作为辅助模型的训练语料。两组实验中的开发集和测试集均由HIT中文分词系统进行分词。表5给出了第一组实验结果,表6给出了第二组实验结果。
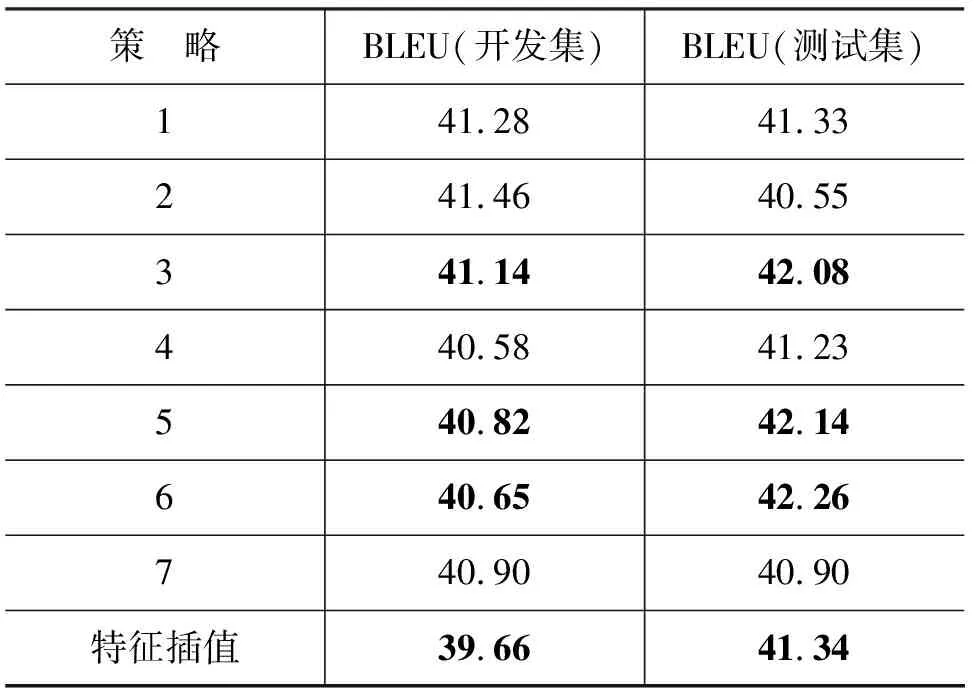
表5 HIT+Stanford实验结果

表6 HIT+ICTCLAS实验结果
最后,我们使用Paired Bootstrap Resampling[18]对系统性能差异的统计显著性进行衡量。结果显示,在p=0.05的条件下,HIT+Stanford组中的策略6和HIT+ICTCLAS组中的策略2对Baseline系统、特征差值策略、HPBT(Stanford)和HPBT(ICTCLAS)的BLEU分数提高都具有统计显著性。
5 实验结果分析
实验结果显示。相对于Baseline系统,两组实验分别获得了1.76和1.89的BLEU分数增长。
我们观察Baseline系统和使用特征融合方法的系统的输出,发现特征融合在改进系统性能方面最为显著的表现就是将Baseline系统无法翻译的未登录词进行了正确的翻译,而这些翻译知识正是从辅助模型中获得的。例如,Baseline中的翻译结果“I can’t see 屏幕.”改进为“I can’t see screen very well.”“How 按摩 脊背?”改进为“Have massage 脊背?”“一共 is 八十七 dollars.”改进为“八十七 is all together dollars.”等。
前面这种类型的改进可以通过融合多分词结果中合适的分词结果获得正确的词对齐并产生原本存在于汉—英句对中的对应翻译项。借助正确的词对齐,我们可以获得更准确的短语翻译。这些通过融合多分词结果获得的新翻译知识是十分有意义的。这种改进可以通过观察系统输出、分析训练和解码过程方便的认识到,但是我们猜测翻译模型融合方法不会只通过这种方式改进系统性能,其他复杂、深入的原理还不能通过我们的实验直观地反映出来。
因为辅助模型的各个部分之间以及辅助模型的各个部分与主模型之间的相互影响复杂,对应不同中文分词系统的组合,对于固定的训练和测试语料,最优特征融合策略并不固定。因此,将这样的方法应用到大规模语料的处理必须首先确定一个最优的策略。在没有好的、确定的方法前,这样的工作比较耗时。
6 结论与展望
本文提出的方法直接利用已有的中文分词系统的分词结果,采用多策略特征融合技术得到复合的翻译模型,使用复合翻译模型的统计机器翻译系统性能得到了显著的提高。
我们的方法使用了多策略翻译模型融合,每个策略对应使用辅助模型的一部分信息。这些策略并不能都在测试集上得到性能的显著提高,但是一些策略在实验中表现出了对Baseline系统较明显的性能优势和对特征插值的优势。实验结果显示统计机器翻译中有效地利用多分词结果能够显著的提高汉英统计机器翻译系统的性能。同时,我们也认识到我们提出的方法在处理大规模统计机器翻译时存在效率问题。在未来的工作中,我们将进一步研究在我们提出的方法中融合策略选择的问题,并且进一步深入发掘来自不同分词结果的各个模型的内部以及它们之间的作用机制,进一步减小噪声在复合模型中的影响。希望更多的研究者能够从中文分词入手,解决中文分词在统计机器翻译中存在的问题,进一步提高与汉语相关的统计机器翻译的性能。
[1] Jia Xu, Richard Zens, and Hermann Ney. Do we need Chinese word segmentation for statistical machine translation? [C]//ACL SIGHAN Workshop 2004, 2004:122-128.
[2] Hua-Ping Zhang, Hong-Kui Yu, De-Yi Xiong, and Qun Liu. HHmm-based chinese lexical analyzer ICTCLAS[C]//Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, 2003:184-187.
[3] Nianwen Xue and Libin Shen. Chinese word segmentation as LMR tagging[C]//Proceedings of the Second SIGHAN Workshop on Chinese Language Processing, 2003:176-179.
[4] Taku Kudo and Yuji Matsumoto. Chunking with support vector machines[C]//Second meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies, 2001:1-8.
[5] Fuchun Peng, Fangfang Feng, and Andrew McCallum. Chinese segmentation and new word detection using conditional random fields[C]//Proceedings of COLING 2004, 2004:562-568.
[6] Jia Xu, Evgeny Matusov, Richard Zens, and Hermann Ney. Integrated Chinese word segmentation in statistical machine translation [C]//Proceedings of IWSLT 2005, 2005:141-147.
[7] Pi-Chuan Chang, Michel Galley, and Christopher D. Manning. Optimizing Chinese word segmentation for machine translation performance[C]//Proceedings of the Third Workshop on Statistical Machine Translation, 2008:224-232.
[8] Ruiqiang Zhang, Keiji Yasuda, and Eiichiro Sumita. Chinese word segmentation and statistical machine translation [J]. ACM Trans. Speech Lang.Process, 2008, 5(2):1-19.
[9] Peter F. Brown, John Cocke, Stephen A. Della Pietra, Vincent J. Della Pietra, Fredrick Jelinek, John D. Lafferty, Robert L. Mercer, and Paul S. Roossin. A statistical approach to machine translation [J]. Computational Linguistics, 1990,16(2):79-85.
[10] Philipp Koehn, Franz Josef Och, and Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of the 2003 Conference ofthe North American Chapter of the Association for Computational Linguistics on Human Language Technology, 2003:48-54.
[11] Franz Josef Och and Hermann Ney. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of 40th Annual Meeting of the Association for Computational Linguistics, 2002:295-302.
[12] Franz Josef Och. Minimum error rate training in statistical machine translation[C]//Proceedings of the 41st Annual Meeting on Association for Computational Linguistics, 2003:160-167.
[13] David Chiang. Hierarchical phrase-based translation [J]. Computational Linguistics, 2007, 33(2):201-228.
[14] 赵铁军,等.提高汉语自动分词精度的多步处理策略[J]. 中文信息学报, 2001, 15(1): 13-18.
[15] Yongliang Ma, Tiejun Zhao. Improving Chinese to English SMT with multiple CWS results[C]//International Conference on Asian Language Processing 2009.
[16] Andreas Stolcke. Srilm - an extensible language modeling tookit[C]//Proceedings of the International Conference on Spoken Language Processing, 2002:901-904.
[17] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2001:311-318.
[18] Philipp Koehn. Statistical significance tests for machine translation evaluation[C]//Proceedings of EMNLP 2004, 2004:388-395.
