归一化的邻接变化数方法在中文分词中的应用
2010-06-05何赛克王小捷张韬政
何赛克,王小捷,董 远,3,张韬政,白 雪
(1. 北京邮电大学 信息与通信工程学院,北京 100876;
2. 北京邮电大学 计算机科学与技术学院,北京 100876;
3. 法国电信北京研发中心,北京 100190)
1 前言
词是自然语言处理(NLP)中的基本单元,因为它为进一步进行处理提供了词汇层面的基础。由于中文文本中缺少定界符,如空格,这使得中文分词(CWS)变成一项有趣而又具有挑战性的任务。
目前,机器学习方法已被成功应用于自然语言处理的各个领域。由于中文分词可被看作一个简单而有效的序列标注问题,条件随机场(CRFs)[1]成为中文分词的一个主流方法。虽然,条件随机场对已登录词(Known Words,在测试语料和训练语料中均出现的词)有着较高的准确率,但是,中文分词系统的性能在很大程度上受制于其对未登录词(Unknown Words,在测试语料中出现,而未在训练语料中出现)的处理能力。因此,如何对未登录词进行切分,成为中文分词中的一个亟待解决的问题。
本文基于我们在第四届国际中文自然语言处理(Bakeoff-4)*第一届中国中文信息学会汉语处理评测(CIPS-CLPE)暨第四届国际中文自然语言处理Bakeoff (Bakeoff-4)http://www.china-language.gov.cn/bakeoff08/参赛的中文分词系统,引入了一种无监督的学习方法(Unsupervised Learning)。这种方法最初源于对语音流的切分[2],并且已被成功的用于分词[3]及词语提取[4]任务。针对这种无监督方法在训练数据过少时的不足,本文提出了一种改进的方法。最后给出实验数据及结果分析。
2 中文分词系统(CWS)的架构
在自然语言处理领域,CRFs是用于中文分词的一项主流技术。根据前人的工作[5],本文使用一阶线性链式CRFs作为中文分词系统的基本架构。
2.1 条件随机场(CRFs)
对于序列标注问题,条件随机场较产生式模型(如HMMs)及判别式模型(如MEMM) 有着明显的优势。CRFs基于一个无向图:G=(V,E),其中V是随机变量集合:Y={Yi|1≤i≤n},代表输入文本序列中的每个字符。E是边集合:E={(Yi-1,Yi) |1≤i≤n},这些边组成一条线性链。在给定输入序列:(o1,o2,…,on) 的条件下,状态序列:(s1,s2,…,sn) 的条件概率定义如下:
(1)
其中,fk为特征函数;λk为其对应特征函数的权重;Z0是个归一化因子,用于保证概率的归一性。现在,原问题可被看作是一个最优化问题:使用迭代算法,如L-BFGS[6],使得整个句子的条件概率PΛ(s|o)最大化。
2.2 标记集
前人的工作[3-4]表明,6-tag 标记集能够使CRFs达到更好的性能。因此,本文中的CWS系统也采用此种标记集,即:B,B2,B3,M,E 以及S。
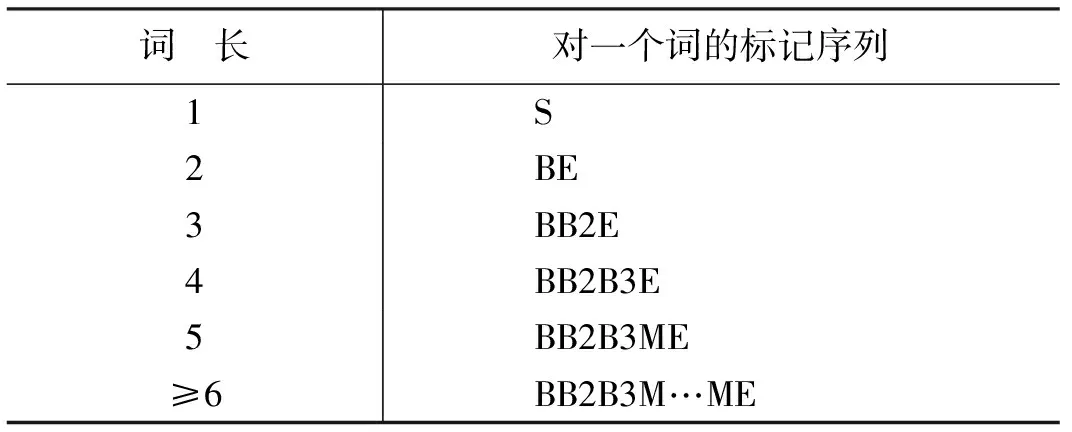
表1 6-tag范例
2.3 特征模板
表2描述了CWS系统中使用的特征,其中C代表字符,下标n代表特征相对于当前字符的位置。Pun指示当前字符是否为标点符号。T为当前字符的类别属性:数字为第一类;时间和日期为第二类;英文字符为第三类;标点符号为第四类;其他字符为第五类。

表2 CWS系统中使用的特征集
3 无监督的分词
除了上面的N元语法特征外,本文还将使用一种称为邻接变化数的无监督分词(Unsupervised Segmentation)结果作为辅助特征,这样可以从统计上捕获更多的关于词的边界信息,从而进一步提升系统的性能。
3.1 邻接变化数方法(Accessor Variety)
在中文文本中,句子中的每一个字串都可以成为一个潜在的词,然而只有那些能够表达特定含义的子串可以形成一个真正意义上的词。邻接变化数方法(AV)[4]反映子串在上下文语境中的灵活程度。如果子串的灵活性越强,那么它就更加有可能是一个词。一个字串s的邻接变化数定义如下:
AV(s)=min{Lav(s),Rav(s)}
(2)
其中, Lav(s) 是子串s的左邻接变化数,它被定义为子串s的不同前驱字符的数目,加上它在不同句首出现的次数; Rav(s) 为子串s右邻接变化数,它被定义为子串s的不同后继字符的数目,加上它在不同句尾出现的次数。
在本文中,针对邻接变化数方法在训练数据过少时表现出的不足(Bakeoff-4中的数据就是如此),提出了一种改进的方法。在此将采用一种改进版本的邻接类别方法——归一化的邻接变化数(Normalized Accessor Variety, NAV)来作为无监督的分词标准,下面将做详细介绍。
3.2 目标函数
给定句子中某个特定字串的邻接变化数计算公式,分词问题就可被看作是一个优化问题,即:使得定义在一个句子上所有子串AV值的目标函数(target function)最大化。一个由n个中文字符构成的句子s,其切分结果S可表示为由m个词构成的词串:
s=c1c2c3…ci…cnS=w1w2w3…wi…wm
(3)
其中ci代表字符,wi代表切分后的一个词。此时,目标函数F的定义为:
(4)
其中,f(wi)为AV函数,其定义为:
f(w)=|w|c×ACd(w)
(5)
|w|为子串w的字符数,参数c取值为整数。尽管AV函数有很多种定义方式,但是,在此我们采用多项式形式的AV函数,这在前人的工作[4]中被证实十分的有效。通常情况下,可获得的训练数据十分有限,因此对于那些具有较多字符的字串和具有极少字符的字串,在使用公式(5)计算子串w的AV值时,就会存在一些波动,进而导致AV值不具有很强的统计意义。比如:仅由单个汉字构成的子串,如助词“的”,或疑问词“吗”往往会被赋予较低的AV值,从而使得它们与其临近词造成“粘连”,尽管它们被当做单个词来看可能会更好一些;而对于那些由较多汉字构成的子串,虽然它们不能表达任何的实际意义,仅仅由于它们的共现频率很高,往往会被赋予一个较高的AV值。因此,我们有必要对上述两种子串进行区别对待。然而,公式(5)中隐含的这个潜在问题,在过去的研究[3-4]中均被忽略了(至少没有被详细的阐述过)。为了解决这个问题,我们提出了一种归一化的AV函数f(Normalized Accessor Variety, NAV)来减弱在AV值计算时产生的波动,归一化的AV函数f*的定义如下:

(6)
在公式(5)的基础上,我们引入了一个实值的归一化因子Norm。公式(6)是基于这样的考虑:一方面,当子串w中包含的字符足够多时,除非其按(5)计算出的AV值很高,否则我们将不认为w为一个词,在公式(6)的计算标准下,w将会得到一个较低的AV值;另一方面,当子串w中包含的字符过少时,除非其按公式(5)计算出的AV值也很低,否则,在公式(6)的计算标准下,w仍然会得到一个较高的AV值。这个度量标准不需要对单字词和多字词进行分别处理,并且在一定程度上缓和了由于训练数据过少而造成的AV值计算上的波动,因此能够更加真实的反映子串在上下文中的灵活程度。
有了上述定义,就可以计算一个句子s的目标函数F(S)了。由于切分后句子中的每个词wi可以被独立的计算,因此F(S)可以通过动态规划的方法来计算求得,这种方法的时间复杂度与句子长度呈线性关系。令fi为每个子句c1c2…ci的目标函数值,wj…i代表词cj+1cj+2…ci(j≤i),那么可以得到下面的动态规划公式:
f0=0;
f1=f(w1…1=c1);
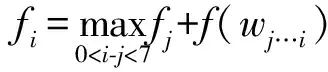
f(S)=fn
(7)
值得注意的是,在每次迭代过程中,最多有N个可能的选择词(我们的实验中最大词长N=6)。
3.3 AV特征
在确定了AV值的计算公式及目标函数的形式后,如何利用AV值有两种选择:(1)将基于AV值的无监督的分词结果(即6-tag标记集)作为CRFs模型的辅助特征。(2)直接将每个字串的AV值作为其特征。在后一种方式中,我们需要定义一个特征函数来对AV值的连续取值空间进行量化,以得到离散的AV值,从而避免数据稀疏(Data Sparsity)的问题。在这里,我们采用如下定义的特征函数[3]:
fn(s)=t, if 2t≤AV(s)<2t+1
(8)
其中,t是一个正整数,用它来对AV值取对数。因为前人研究工作中没有任何证据表明上述两种使用特征的方式中,哪种效果更好一些,因此我们在实验部分做了一组实验来对此给出一个明确的回答。
4 实验结果
本文的实验基于Bakeoff-4中提供的中文分词数据,共来自5个数据集:CITYU, CKIP, CTB, NCC 和 SXU。其中CITYU的数据是繁体中文,而其他数据则是简体中文。
在Baseline CWS系统(仅仅使用有监督的学习)架构中,首先使用三重交叉验证来训练初始的CRFs模型,并用这3个训练好的模型来测试剩下的一份语料,之后transformation-based error-driven learning (TBL)通过比较训练语料和三个初始的CRFs的测试结果来完成训练。表 3 列出了我们在开放测试中分别用于训练CRFs和TBL的语料。
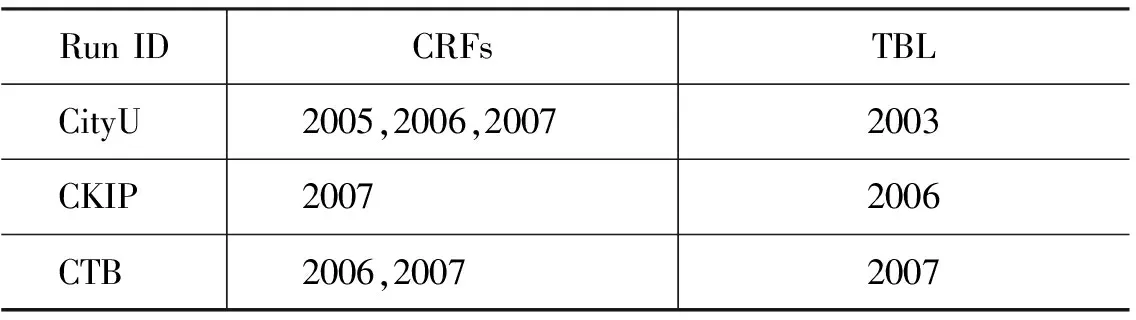
表3 分别用于训练CRFs和TBL的语料
在这个基本架构的基础上,我们引入了NAV来进一步提升分词系统的性能。为了深入的分析NAV对分词系统性能的影响,我们做了一组对比试验,这将在后续的实验中见到。
在后面的实验中,无监督方法中最大的分词长度设为6,因为中文文本中长度大于6的词比较少见;公式(6)中的两个参数c和d分别取值为1和2(这是沿用了在实验中的最佳参数设置)。值得一提的是,所有子串的AV值都是基于全部语料计算得到的,即:全部训练语料和测试语料。
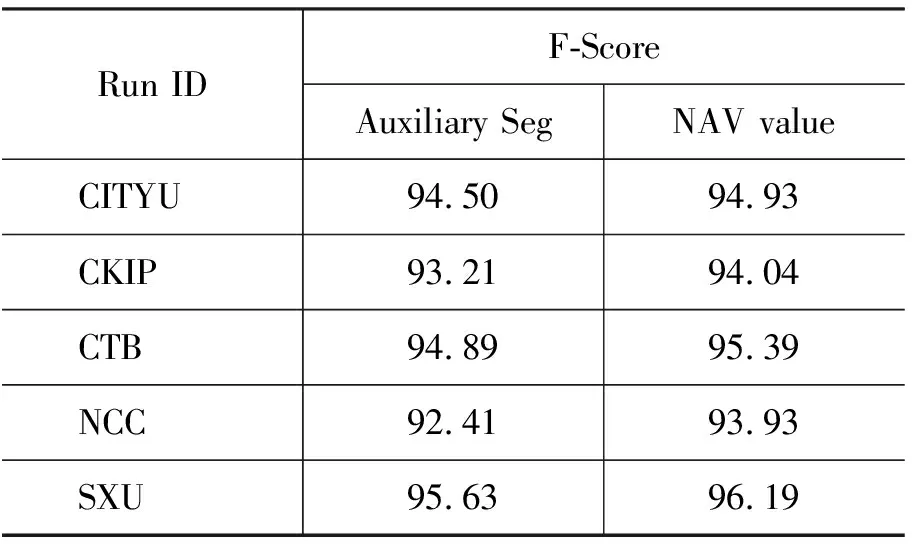
为了得到一种更好的AV值的使用方式,表4中给出一组对比试验的实验结果。其中“Auxiliary Seg”是指将基于AV值的无监督的分词结果,即标记集:B,B2,B3,M,E以及S,作为CRFs模型的辅助特征。“NAV value” 是指直接将每个字串的AV值(通过特征函数离散化后)作为其特征。在NAV方式下, 公式(6)中的参数Norm取值为2.5, 这在本文之前的实验中取得了最好的效果。表4中的实验结果表明:采用“NAV”方式的效果较好。这个结论可以解释为 “Auxiliary Seg”中的标记错误在一定程度上干扰了CRFs的学习过程。因此,在后面的实验中,我们将采用“NAV”值赋值的方式来使用AV特征。
为了证实NAV在封闭集上的有效性,表5列出了四种系统在CWS的性能比较。其中“BaseLine”代表我们参加Bakeoff-4的基准系统,它仅仅利用了表2中定义的特征,在后处理阶段,仅仅使用了一致性检测;“+AV”表示在“BaseLine”系统的基础上加入了AV特征;“+NAV”表示在“BaseLine”系统的基础上加入了NAV特征;“Best”代表在相应的封闭测试集上当时最好系统的性能。实验结果表明邻接变化数方法(AV)能够提升基于CRFs架构的CWS系统的性能,而基于NAV的CRFs性能最好。这正是由于NAV缓和了AV值的波动,从而使性能有了进一步的提升。然而,值得指出的是,NAV在CTB数据集上的性能较AV方式略有下降,但仍然高于“BaseLine”系统的性能。一个合理的解释是Norm取2.5对于CTB数据来说可能并不是最佳的参数设置。

表5 四个系统在CWS封闭测试集上的性能比较(未使用TBL)*官方结果可以从以下网址下载:http://www.china-language.gov.cn/bakeoff08/bakeoff-08_basic_chs.html。
表7 列出了四个系统在开放测试集合上的性能比较(Norm=2.5)。在此实验组中引入额外数据训练TBL,此时要验证NAV是否还会带来性能的进一步提升。在开放测试中,由于没有额外的训练数据,因此未对NCC和SXU进行实验。通过比较表5和表6中“BaseLine”系统的性能可以发现,在表6中引入的TBL大幅度地提升了CWS系统的性能,这是因为大量的额外信息被加入到了系统中,从而为系统提供更加丰富的语言学知识。与此同时,这导致AV和NAV能够挖掘的额外的上下文信息变得更加少了,从而使得在开放测试中的性能提升不如封闭测试中那么明显。

表6 四个系统在CWS开放测试集上的性能比较(使用了TBL)
从表7中可以看出,当公式(6)中的参数Norm设为2.5时,NAV的性能较好。另外值得注意的是,当Norm参数取值在[2,3]之间的时候,NAV的性能良好。但是,在本文的实验过程中,当Norm取值超过此范围时,性能会有不同程度的恶化,这是个需要进一步改进的地方。

表7 不同Norm设置下,NAV在 CWS封闭测试任务中的性能
5 结语
在自然语言处理中,中文分词系统的性能在很大程度上受制于其对未登录词的处理能力,而仅仅依靠有监督的学习是无法解决这个问题的。本文提出了一种无监督和有监督相结合的中文分词方法,即:将邻接变化数方法引入基于条件随机场的中文分词系统中,并对邻接变化数方法固有的缺陷进行了改进。实验结果表明:NAV的性能在原有AV方法的基础上,又有了进一步的提升。最后,AV函数的选取及参数的设置对无监督学习部分的性能有着直接影响,这将是NAV方法需要进一步改进的地方。
[1] J. Lafferty, A. McCallum, and F. Pereira. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data [C]//Proceedings of the 18th ICML, San Francisco, CA. 2001: 282-289.
[2] Zellig Sabbetai Harris. Morpheme within words [C]//Papers in Structural and boundaries Transformational Linguistics, 1970: 68-77.
[3] Hai Zhao and Chunyu Kit. Unsupervised Segmentation Helps Supervised Learning of Character Tagging for Word Segmentation and Named Entity Recognition [C]//The Sixth SIGHAN Workshop on Chinese Language Processing (SIGHAN-6), Hyderabad, India, 2008: 106-111.
[4] Haodi Feng, Kang Chen, Chunyu Kit, and Xiaotie Deng. Unsupervised segmentation of Chinese corpus using accessor variety [C]//K.-Y. Su, J. Tsujii, J. H. Lee, and O. Y. Kwong, editors, Natural Language Processing- IJCNLP 2004, volume 3248 of Lecture Notes in Computer Science, Springer Berlin/Heidelberg. Sanya, Hainan Island, China. 2005: 694-703.
[5] Xinnian Mao, Yuan Dong, Saike He, Sencheng Bao and Haila Wang, Chinese Word Segmentation and Name Entity Recognition Based on Condition Random Fields [C]//The Sixth SIGHAN Workshop on Chinese Language Processing (SIGHAN-6), Hyderabad, India. 2008.
[6] R.H. Byrd, J. Nocedal and R.B. Schnabel. Representations of quasi-Newton matrices and their use in limited memory methods [J]. Mathematical Programming, 1994,(63): 129-156.
