对话行为信息在口语翻译中的应用
2010-06-05周可艳宗成庆
周可艳,宗成庆
(中国科学院 自动化研究所 模式识别国家重点实验室,北京 100190)
1 引言
对话行为(Dialog Act)是指对话语句(Utterance)的言外力(Illocutionary force)[1],属于浅层话语结构的范畴[2]。具体地讲,对话行为反映了对话语句及对话人的意图,例如陈述、疑问、许诺、解释等。对话行为为口语对话的理解提供了语用方面的重要信息,因此在自然语言处理领域有着广泛的应用,如自动语音识别[3],口语对话系统[4],自动摘要[5]和口语翻译系统[6-10]等。
从20世纪90年代以来,陆续有一些研究人员试图将对话行为信息应用到口语翻译系统中,并取得了一定的成果。在语音翻译系统中,文献[7]将对话行为信息应用于语音识别和信息抽取模块,从而间接地提高了翻译系统的性能。在基于中间语言的翻译系统中,源语言首先被解析为抽象的语义概念,继而被转化为目标语言[6]。对话行为信息作为语义概念的表示形式之一,既参与到口语解析,也涉及到口语句子的生成[8-9]。在目前主流的统计机器翻译中,如何将包括对话行为在内的语义和语用信息与翻译模型相融合,也一直是研究人员试图解决的难点之一。Sridha 等人提出了一种基于对话行为的短语翻译对抽取方法[10],将其应用到基于短语的统计翻译系统中。但是受对话行为自动识别正确率的限制,Sridha的方法在实验结果上只获得了有限的提高。
我们认为,在口语翻译系统中,对话行为信息不仅可以通过优化翻译引擎来提高翻译系统的性能,也可以辅助人来理解机器翻译的结果。源语言和目标语言的对话行为标签应该是一致的。但是在翻译过程中,由于翻译方法本身的局限性,常常造成部分信息的缺失。如表1中所示,如果不能识别出对话行为标签为“是非问”,而翻译引擎又未能正确的构造疑问句式,那么翻译结果将成为陈述句,就不能准确地表达源语言句子的含义。因此,对话行为标签所传递的信息是对翻译结果的有益补充。

表1 对话行为与翻译结果
本文首先对对话行为理论进行简要的介绍,并介绍了一个中文对话行为标注语料库CASIA-CASSIL。然后给出我们利用对话行为信息提高口语机器翻译系统性能的方法。在汉英口语翻译评测数据上的实验证明,对话行为信息的加入使翻译系统的性能得到了有效的提高。
2 对话行为理论简介
言语行为(Speech Act)理论首先由Austion提出[1],后经Searle[11]等人的完善逐渐成熟[12]。言语行为,即话语的言外之力体现了说话人的意图,是人类交际的基本单位。言语行为的分类划分通常以下面三点为依据:1)言语行为的目的; 2)言语行为带来的后果; 3)言语行为所反映的说话人的态度及信息状态。例如,Searle给出的基本分类包括“阐述”、“指令”、“承诺”、“表达”、“宣告”。
在计算语用学的研究中,通常把某些类别的言语行为称为对话行为(Dialog Act),例如请求、主张等类别[13]。对话行为的识别被认为是对话语句解析的关键问题。虽然对话行为已经成功应用于多个系统,但是其定义的细化以及跨领域标准化问题一直没有得到解决。目前对话行为的标注并没有统一的标注规范,而是由标注人员根据对话语料的领域及研究的目的进行制定。表2中给出了一种层次化的对话行为标注形式。其第一层标注普通标注(是非问、陈述等)反映对话语句的基本形式;第二层标注特殊标注(询问、肯定答案、请求确认等)反映话语的功能或特性,是对普通标注的补充。

表2 对话行为标注例子
3 国内外口语语料标注现状
20世纪90年代,统计自然语言处理技术兴起以后,对话行为理论的研究和应用也得到了飞速发展,带动了大规模真实口语对话语料的收集和标注工作。目前国际上已经有若干成熟的英文口语对话行为标注语料库,如Switchboard-DAMSL电话录音语料[2]、ICSI-MRDA多人会议[3]和AMI Meeting Corpus[14]等。
Switchboard-DAMSL语料由1 115段平均时长约5分钟的电话录音组成,每段对话平均有144个话轮(Turn),271个语句(Utterance),共包含约205 000个语句,140万词汇。其中,共有220个对话行为标注标签。由于其中多数标注出现次数较少,因此研究人员通常在前期处理中将其聚类为42种。
ICSI-MRDA多人会议语料是由美国ICSI(The International Computer Science Institute)收录并标注的真实多人会议语料,包括75个会议,平均每个会议有6人参与,平均长度大约为一小时。其对话行为的标注信息包括语句边界的切分、对话行为和邻接对(Adjacency Pairs, APs)的标注。ICSI-MRDA将Switchboard-DAMSL的单层标注标签扩展为多层标注标签。即每个语句对话行为标注的包含且仅包含一个普通标签,用于描述语句的基本形式;同时可以包含若干个特殊标签,作为普通标签的补充,用于描述语句的功能或特性。ICSI-MRDA的标注集包括11个普通标签和40个特殊标签。
AMI Meeting Corpus包含约100小时的多媒体会议数据。其标注集不仅包括对话行为标注、命名实体标注、主题切分和摘要提取,也包括基于FeelTrace*http://www.dfki.de/~schroed/feeltrace/标注工具所标注的二维情感表示,以及对话人的手势、姿态等信息。
目前国际上还没有公开的中文对话行为标注语料。口语语料标注的任务存在很多困难,一方面,口语对话语料的收集需要消耗大量的人力物力,并且真实场景下的口语语料往往噪声很大,更增加了语料挑选和整理工作的难度;另一方面,国际上没有统一的对话行为标注规范,标注规范的制定要结合所收集语料的领域特点。
在对已有英文口语标注语料充分调研的基础上,我们创建了中文口语对话标注语料库CASIA-CASSIL[16]。CASIA-CASSIL是一个基于旅游信息领域的大规模真实场景电话录音语料库,包含语音、情感、对话行为、口语现象、主题等多层标注信息。本文中,我们用到的385段中文口语对话语料,涵盖五个领域,各领域语料的规模统计见表3。其中,旅馆预订领域为人工转写的真实电话录音语料,其他领域的语料摘录自旅游手册。在制定对话行为标注规范的过程中,我们参考了ICSI-MRDA语料标注规范[3],并针对所收集的中文语料中的特殊现象进行了修改,修改内容主要涉及两方面:1)增加了中文对话中常用的语句类型,如祈使、感叹。2)对口语现象进行了归类处理,如增加了插入语类。最终制定的对话行为标注规范包括普通标注集、中断标注集和特殊标注集。普通标注集描述话语的基本形式,如陈述、疑问、感叹等,共有10种标签。中断标注集描述口语中的中断现象,包括话语被打断或省略,共3种标签。特殊标注集描述话语的功能或特性,是对普通标注的补充,如赞同、感谢、命令等,共38种标签。普通标注与特殊标注以“^”隔开。每一个对话行为的标注包括一个普通标注,可能包括一个或多个特殊标注,当话语不完整时,对话行为的标注包含中断标注。表4给出了CASIA-CASSIL的一段标注实例。表5给出了普通标注集和中断标注集在CASIA-CASSIL中的统计数据。
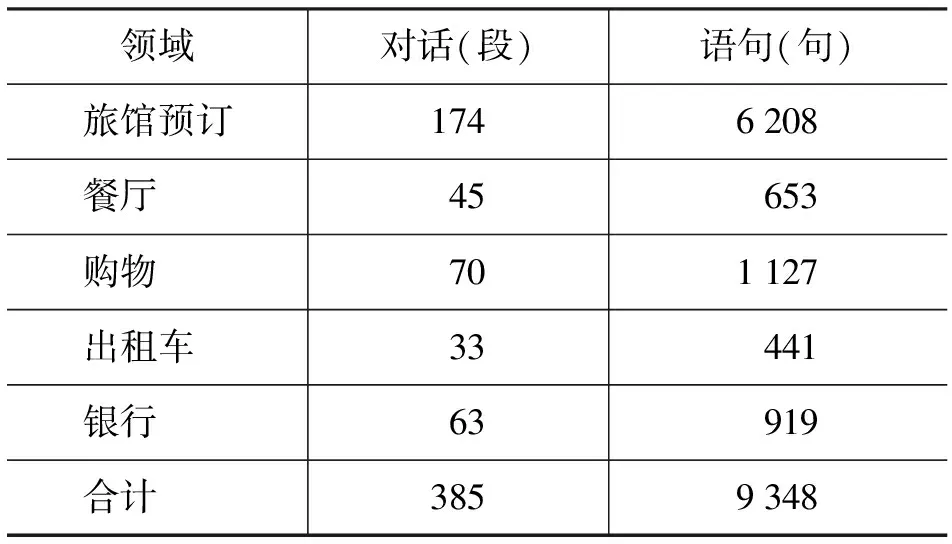
表3 各领域对话语料规模统计

表4 CASIA-CASSIL标注实例
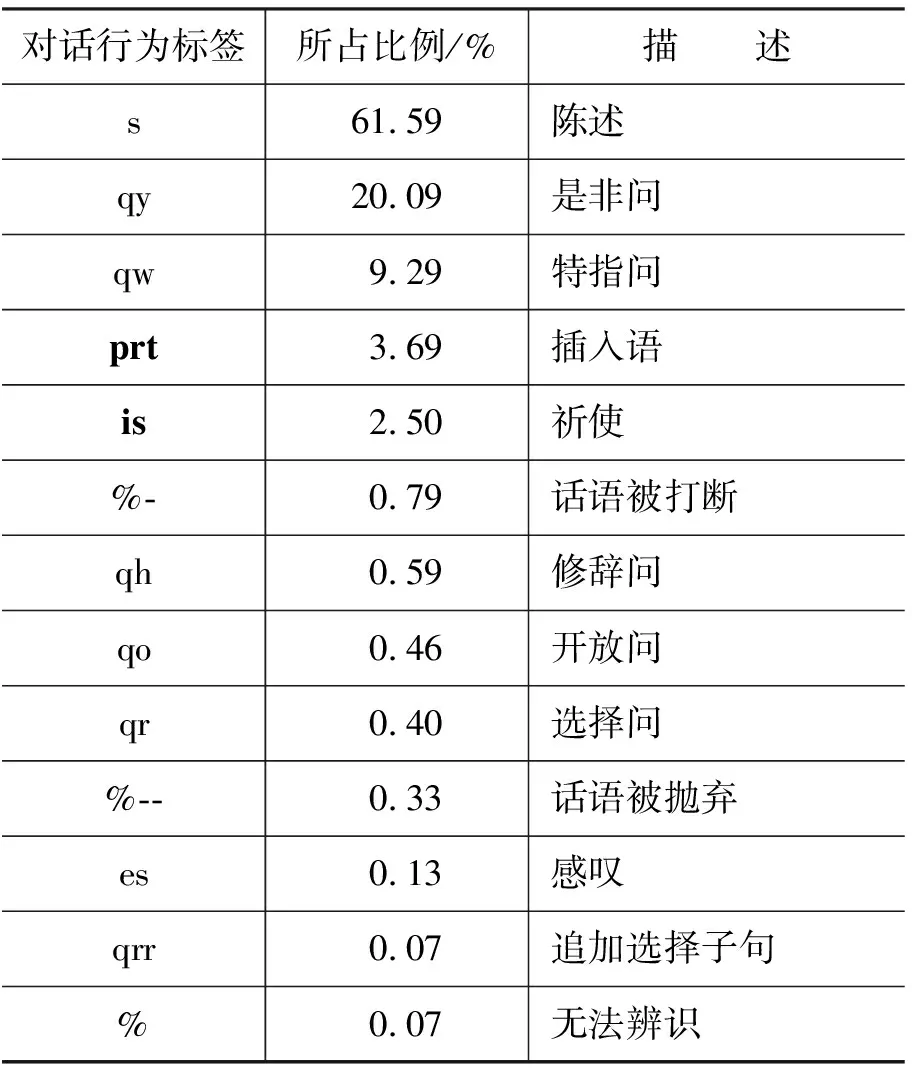
表5 CASIA-CASSIL对话行为标注集统计数据
4 对话行为在口语翻译中的应用
随着对话行为理论的发展和成熟,先后有一些学者试图将这种对对话意图的描述应用到机器翻译中去。相关的研究工作分别以JANUS系统[6]、Verbmobil系统[7]和Sridhar等的研究[10]为代表。
JANUS是基于中间语言的翻译系统,用于实现德语到英语以及德语到日语的翻译。在基于中间语言的翻译系统中,源语言的语义首先被解析成独立的中间语言,然后再从中间语言转换成目标语言,从而实现多种语言之间的互译。JANUS系统采用C-STAR*http://www.c-star.org/(Consortium for Speech Translation Advanced Research international)所定义的中间转换格式(interchange format, IF),而对话行为正是IF格式的重要组成之一。因此,对基于中间语言的翻译系统来说,对话行为作为语义表示之一直接参与到翻译过程中。文献[16-17]也曾进行过面向IF的口语理解工作研究。近年来随着统计翻译方法的快速发展,由于IF定义、转换、生成等具体实现问题的复杂性,基于IF的翻译方法正在逐渐被冷落[18]。
Verbmobil是上世纪90年代德国联邦教育部(BMBF)所资助的语言技术研究项目。在其研发的Verbmobil语音翻译系统中,对话行为主要应用在三个模块中:(1)语音识别模块,通过对话行为的预测,对语言模型进行动态的过滤,从而提高词汇的语音识别正确率。(2)语义评价模块,通过已知的对话行为信息聚焦算法以确定下一语句的对话行为。(3)上下文信息抽取模块,用于为Verbmobil各模块提供上下文信息,以取得更好的翻译结果。实际上在Verbmobil里,对话行为并未直接应用于翻译模块本身。
Sridhar等[10]提出了一种对话行为与基于短语的统计翻译模型相结合的方法。其基本思路是首先基于源语言的对话行为将训练语料分为若干类,然后对每类语料分别训练翻译模型。出于对数据稀疏问题的考虑,Sridhaer等人将基线系统所训练出的短语翻译概率表也加入到基于对话行为分类语料训练出的短语翻译概率表中,并加入参数对短语概率进行数据平滑操作。最终的短语对翻译概率表即为基于对话行为的翻译模型。这种方法通过对短语概率表的分类训练,实现了对话行为信息在统计翻译系统中的应用。
综上所述,在翻译系统中,对话行为信息既可应用于语音识别等模块以间接提高翻译系统的性能,也可直接应用于基于中间语言和基于短语的统计翻译模型。在目前流行的基于短语的统计翻译系统中,文献[10]只给出了一种应用形式,其他的应用,比如:基于对话行为的开发集选取、n-best翻译结果的重排序等,包括对话行为分类本身所涉及的诸多问题,比如分类器和特征选取等,文献[10]中没有进行研究。
5 本文的思路
本文的基本思路是通过对话行为的分类,使训练语料—测试语料、开发集—测试集、源语言—目标语言的一致性得到提高,从而提高翻译系统的性能。
基于短语的翻译系统其主要翻译过程包括:根据均匀分布的假设将源语言句子划分为短语,利用预先抽取的短语翻译对表将每一个源语言短语翻译成目标语言短语,然后利用重排序模型对目标语言短语进行重排序得到目标语言句子。
其中,短语翻译对表的构建关系到翻译知识的获取,是基于短语的翻译系统研究的关键技术。此外,为实现翻译结果的自动打分最优,翻译系统还引入了最小错误率训练,以获得相对于开发集最优的n-best列表。受各种因素的干扰,n-best列表排名第一的结果并不一定是最优结果,因此翻译n-best结果的重排序也是影响翻译结果的问题之一。
我们在以下三个阶段引入对话行为信息:A. 短语翻译概率表及调序表的获取,保证训练语料与测试语料的一致性;B. 基于开发集的最小错误率参数训练,保证开发集与测试集的一致性;C.n-best翻译候选结果的重排序,保证源语言与目标语言的一致性。参见图1。

图1 对话行为与基于短语的翻译过程
我们以“DAi”表示经过对话行为分类后属于第i类的语料,“ALL”表示未经分类的全部语料集合。这三种应用形式的具体实现如下:
A.对全部训练集进行训练得到短语翻译概率表P(ALL)和调序表R(ALL)。对训练集进行对话行为分类后,分别训练得到短语翻译概率表P(DAi) 和调序表R(DAi)。若P(ALL)中存在与P(DAi)相同的短语对,则以P(DAi)中该短语对的概率替换P(ALL)。同样地,实现R(ALL)与R(DAi)的替换。
B.基于对话行为的开发集选取。由于开发集与测试集的一致性可能影响到最小错误率训练的效果。因此,针对DAi类别的测试集,我们采用相应类别的开发集为其训练参数。
C.n-best翻译候选结果的重排序。我们认为一对源语言和目标语言其对话行为标签应保持一致。因此对于n-best翻译候选结果我们选取与源语言对话行为标签最为接近的翻译结果。
6 实验
6.1 语料及翻译系统
中文对话行为分类的训练语料采用我们收集标注的CASIA-CASSIL对话行为标注语料,英文对话行为分类的训练语料我们采用Switchboard-DAMSL[2]。
翻译系统所采用的语料为IWSLT’07的训练集开发集和测试集[19]。基于短语的统计翻译系统采用Moses工具包*http://www.statmt.org/moses/。翻译结果的评价采用BLEU打分。
6.2 对话行为分类
对话行为识别是典型的分类问题,通过学习对话语句的韵律、词法、句法及上下文结构信息等知识,采用最大熵、决策树、图模型、支持向量机(SVM)等方法进行自动分类。其中SVM的方法易用性强,正确率高,是目前最为流行的机器学习方法之一,在对话行为的识别中效果也优于其他模型[20]。文献[21]采用SVM方法进行对话行为的分类,而文献[22]基于SVM分类器从词汇层、句法层和约束信息的角度探讨了各种特征对对话行为分类的影响。在本文中,我们采用SVM分类器进行对话行为的分类,SVM分类器采用libsvm工具*http://www.csie.ntu.edu.tw/~cjlin/libsvm。本文采用的特征包括unigram、bigram以及频率FQ=200的约束条件。采用SVM分类器及五组交叉验证,这一特征在中文对话行为标注语料上的识别正确率为87.11%,而仅采用unigram特征的识别正确率仅为77.05%[22]。
以CASIA-CASSIL部分对话行为标注语料为训练语料,我们分别对IWSLT07的训练集、开发集和测试集进行了分类。虽然训练标注集包括普通标注集和中断标注集共计13类,由于IWSLT’07测试集上的自动分类结果仅包括其中的5类,所以最终的分类结果为5类,分别是DA1(陈述),DA2(是非问),DA3(特指问),DA4(感叹),DA5(祈使)。分类结果见表6。在分类过程中,我们认为一对源语言和目标语言共享同一个对话行为标签。基于分类后的IWSLT训练集,我们分别进行了短语对的抽取,所抽取的短语对个数见表6。

表6 IWSLT07语料的对话行为分类结果
对于生成的10-best翻译候选结果,我们以Switchboard-DAMSL为训练语料对齐进行对话行为分类。因CASIA-CASSIL语料与Switchboard-DAMSL语料的对话行为标注规范存在差异,我们对于英文的分类结果,只选取中英文定义一致的DA3类别的数据。
6.3 翻译系统实验结果
表7给出了对训练集和开发集进行分类并分别训练后,翻译结果的BLEU打分。基线系统指采用全部训练集和开发集训练出的翻译模型。A(短语表)、A(调序表)分别指对短语翻译概率表和调序表进行概率替换。B指对开发集进行对话行为分类。以对话行为类别为单位,我们分别给出了每一类测试集的BLEU得分。“DAi”表示属于第i类对话行为的测试集,“ALL”表示全部测试集集合。

表7 翻译结果的BLEU得分
由实验结果可以看出,A(短语表)对短语翻译概率表进行替换以后,总测试集ALL的BLEU得分有所提高。对每个类别测试集的实验结果进行研究,我们发现BLEU得分的提高与否和分类后训练集的大小有关。分类后若训练集规模过小,则按类别训练出的短语概率表概率值的可信度降低,从而影响到替换以后的翻译效果。参照表6,规模最小的DA2和DA4经过短语概率替换以后,BLEU值有所下降;而规模较大的DA1、DA3、DA5均得到了不同程度的提高。
开发集进行对话行为分类(B)以后,对于DA2~DA5,由于开发集规模的大幅减小,BLEU得分也明显下降,从而引起了ALL得分的下降。但是DA1类别分类后开发集规模变化不大,翻译结果得分最终有所提高。这说明提高开发集和测试集的吻合程度,即使开发集规模略微减小,也会对系统的性能有所帮助。
同时对短语表和调序表的概率进行替换,BLEU得分较基线系统有了明显提高提高,提高较大的为中英文语序差异较大的对话行为类别,如DA2(是非问),DA3(特指问),DA4(感叹)。
在C(n-best翻译候选结果的重排序)的实验中,只针对源语言分类为DA3的语句,若10-best翻译候选的分类结果中存在类别为DA3的翻译结果,则选取DA3概率最大者为最终的翻译结果。若10-best翻译候选分类的分类结果类别为DAi且i≠3,则按以下两种情况分别讨论:(1)始终选取DA3概率最大者(SVM- DA3);(2)选取DAi概率最大者(SVM-TOP)。
C的实验结果见表8。两种方法的实验结果均较基线系统有大幅提高,SVM-DA3的方法使翻译结果与源语言的对话行为尽量保持一致,而SVM-TOP的方式有助于修正源语言端的分类错误,使BLEU得分有了进一步的提高。如表9所示,源语言的对话行为原本为DA1,却被错误地识别为DA3,而SVM-TOP的方法成功修正了这一错误,得到了正确的翻译结果。而这两种方法不能解决的问题是当存在多个翻译结果对话行为标签相同时,概率最大者并不一定是最优结果,如果再引入词性、长度、词语对齐等信息,将会有助于得到更好的重排序结果。

表8 DA3 n-best翻译结果的重排序

表9 不同重排序方法的翻译结果
7 结束语
本文介绍对话行为理论和口语标注语料的基础上,提出了将对话行为这一语用信息应用于统计机器翻译过程的三种方式。以基于短语的统计机器翻译系统为应用对象,本文提出的方法利用对话行为的自动分类,使训练语料—测试语料、开发集—测试集、源语言—目标语言的一致性得到提高,提高了系统的性能,使最终的翻译结果可以更准确地反映源语言所要表达的对话意图。
在训练集和开发集上的实验结果表明,通过对话行为的分类,使训练语料—测试语料的一致性得到了提高,从而提高了系统的BLEU值,而分类后的训练集、开发集的规模大小也与系统的得分有关。在n-best结果重排序的实验上,我们在使翻译结果与源语言保持一致的基础上,也避免了源语言端的分类错误,使BLEU值得到了较大的提高。
此外,我们认为基于n-gram正确率的BLEU打分并不能完全反映对话行为对翻译结果的影响。因此,下一步工作中我们将尝试在真实口语对话中,以人工打分的评价方式进一步研究对话行为在口语翻译中的应用。
[1] J. L. Austin. How to do Things with Words[M]. Oxford:Clarendon Press, 1962.
[2] D. Jurafsky, L. Shriberg, and D. Biasca. Switchboard SWBD-DAMSL Labeling Project Coder’s Manual, Draft 13[R]. Technical Report 97-02, University of Colorado Institute of Cognitive Science. 1997.
[3] R. Dhillon, S. Bhagat, H. Carvey, et al. Meeting Recorder Project:Dialog-act Labeling Guide[R]. ICSI Technical Report TR-04-002. International Computer Science Insitute. 2004.
[4] M. Walker, and R. Passonneau. DATE:A Dialog Act Tagging Scheme for Evaluation of Spoken Dialog Systems[C]//Proceedings of HLT 2001, San Diego. 2001.
[5] A. Stolcke, K. Ries, N. Coccaro, et al. Dialog Act Modeling for Automatic Tagging and Recognition of Conversational Speech[J]. Computational Linguistics, 2000. 26(3):339-373.
[6] M. Woszczyna, N. Coccaro, A. Eisele, et al. Recent Advances in Janus:A Speech Translation System[C]//Third European Conference on Speech Communication and Technology. 1993.
[7] N. Reithinger, and E. Maier. Utilizing Statistical Dialog Act Processing in Verbmobil[C]//Proceedings of the 33rdAnnual Meeting of the Association for Computational Linguistics (ACL)MIT, Cambredge, MA. 1995:116-121.
[8] Wenjie Cao, Chengqing Zong, and Bo Xu. Approach to Interchange-Format Based Chinese Generation[C]//Proceedings of the International Conference on Spoken Language Processing (ICSLP). Jeju, Korea. 2004:4-8.
[9] Yuncun Zuo, Yu Zhou and Chengqing Zong, Multi-Engine Based Chinese-to-English Translation System[C]//Proceedings of International Workshop on Spoken Language Translation, Japan, 2004:73-76.
[10] V. K. R. Sridhar, S. Narayanan, et al. Enriching Spoken Language Translation with Dialog Acts[C]//Proceedings of ACL 2008, Short Papers(Companion Volume). Columbus, Ohio, USA, June, 2008:225-228.
[11] JR Searle. Speech Acts:an Essay in the Philosophy of Language[M]. Cambridge University Press:Cambridge, England. 1969.
[12] 何兆熊. 新编语用学概要[M]. 上海:上海外语教育出版社. 2000.
[13] G. Leech and M. Weisser. Pragmatics and Dialogue. The Oxford Handbook of Computational Linguistics[M]. Oxford University Press. 2003:136-156.
[14] J. Carletta, S. Ashby, S. Bourban, et al. The AMI Meeting Corpus:A Pre-Announcement. In Steve Renals and Samy Bengio, editors. Machine Learning for Multimodal Interaction II[M]. Springer-Verlag, Berlin/Herdelberg. 2006. LNCS 3869, Pages 28-39.
[15] Keyan Zhou, Aijun Li, Zhigang Yin, et al. CASIA-CASSIL:a Chinese Telephone Comversation Corpus in Real Scenarios with Multi-leveled Annotation[C]//Proceedings of the seventh International Conference on Language Resources and Evaluation(LREC). May 2010, Malta.
[16] 解国栋, 宗成庆, 徐波. 面向中间语义表示格式的汉语口语解析方法[J]. 中文信息学报. 2002. 17(1):1-6.
[17] 左云存, 宗成庆. 基于语义分类树的汉语口语理解方法[J]. 中文信息学报. 2005. 20(2):8-15.
[18] 宗成庆. 统计自然语言处理[M]. 北京:清华大学出版社, 2008.5.
[19] Y. Zhou, Y. He, and C. Zong. The CASIA Phrase-Based Statistical Machine Translation System for IWSLT 2007[C]//Proceedings of the International Workshop on Spoken Language Translation (IWSLT), Trento, Italy. October 15-16, 2007.
[20] Dinoj Surendran, and Gina-Anne Levow. 2006. DA Tagging with Support Vector Machines and Hidden Markov Models[C]//Proceedings of Interspeech, Pittsburgh, PA.
[21] K. Zhou, C. Zong, H. Wu, et al. Predicting and Tagging DA with SVM and MDP[C]//Proceedings of ISCSLP 2008. Kunming, China. 2008: 293-296.
[22] K. Zhou, C, Zong. Dialog-act Recognition Using Discourse and Sentence Structure Information[C]//Proceedings of IALP 2009. Singapore, 2009: 11-16.
