一种主题爬虫文本分类器的构建
2010-06-05宋继华
姜 鹏,宋继华
(北京师范大学 信息科学与技术学院,北京 100875)
1 引言
近年来随着媒体技术、网络技术的高速发展,新型信息资源(包括多媒体信息资源、电子出版物、网络信息资源等)大量出现,极大丰富了传统意义上的对外汉语教学资源,与此同时,由于资源本身存在数量规模大、形式多样、属性复杂等特点,资源的获取显得异常困难。同时我们也注意到,对外汉语领域相关的大部分资源通常集中分布在领域性非常强的少数网站以及部分论文中,自动获取资源的关键在于资源的分类识别问题。因此,本课题针对对外汉语资源在互联网分布的特点,提出将文本自动分类器植入网络爬虫,使得网络爬虫在互联网上爬取资源的时候可以自动的采集主题相关度高的网页,丢弃相关度低甚至不相关的网页,从而达到资源自动获取的目的[1]。
在线进行文本分类的难点之一在于文本的特征提取,特征空间维度太高势必消耗大量的计算资源,维度太低又无法正确表示目标文本,从而有可能丢弃大量具有较高相关度的文本资源。另一个难点在于在线进行分类对于效率的要求,如何提高分类效率,从而迅速判定目标文档与主题是否相关是整个研究的关键[2]。有鉴于此,针对该命题的研究就显得十分必要。本文从文本特征抽取和文本向量表示、基于标题和正文相结合的分类器构建、实验设计及结果分析、实验结论等方面进行了阐述。
2 文档向量模型的构建
2.1 文档频率
文档频率(Document Frequency)是指在训练语料中出现该词条的文档数。采用DF作为特征抽取的方法是从语料库中统计包含该词条的文档数,如果该DF值低于某个预先设定的阈值,则认为该词条是低频词,它不含或含有较少的类别信息。将这样的词条从原始特征空间中移除,能够降低特征空间的维数,还有可能提高分类的精度。
文档频率简单易行,能够容易地被用于大规模语料统计。但是其缺乏一定的理论依据,并且根据信息论,某些DF值低的词条往往具有较多的信息量,对分类具有重要意义,不应该将它们完全移除。
2.2 χ2统计量
χ2统计量(CHI)度量的是词条t和文档类别c之间的相关程度,并假设t和c之间符合具有一阶自由度的χ2分布[3]。词条对于某类的χ2统计值越高,它与该类之间的相关性越大,携带的类别信息越多,反之越少。其计算方法如下:
χ2(ti,Cj)
(1)
其中N表示训练语料中的文档总数,Cj为某一特定类别,ti表示特定的词条,A表示属于Cj类且包含ti的文档频数,B表示不属于Cj类但是包含ti的文档频数,C表示属于Cj类但是不包含ti的文档频数,D是既不属于Cj也不包含ti的文档频数。则ti对于Cj的CHI值。
对于多类问题,分别计算ti对于每个类别的CHI值,再用下式计算词条ti对于整个语料的CHI值,分别进行检验:
(2)
其中M为类别数。从原始特征空间中移除低于特定阈值的词条,保留高于该阈值的词条作为文档表示的特征[4]。
2.3 DF与CHI统计量相结合的方法
鉴于以上提到的两种方法各自存在的缺陷,可以参考文献[5]中提到的将二者相结合的方法进行特征提取。具体做法是先针对语料库中出现的全部词条计算其文档频率DF,删除DF值低于某个预先设定阈值的词条,认为其为噪声数据。余下的词条对类别计算其CHI统计量,选取CHI统计量高的词条作为构建文档特征向量的候选词条。
在实验中,我们构建的分类器为主题分类器,所面临的是两类问题,即只须判断是否与目标主题相关。因此在构建文本向量时,我们首先利用DF方法过滤掉DF值较低的词条,然后利用公式(1)分别计算文档标题和正文中出现词条的CHI统计量,最后得出标题和正文的特征向量,其中标题特征相量维度取50,正文部分特征向量维度取200。部分结果如表1所示。
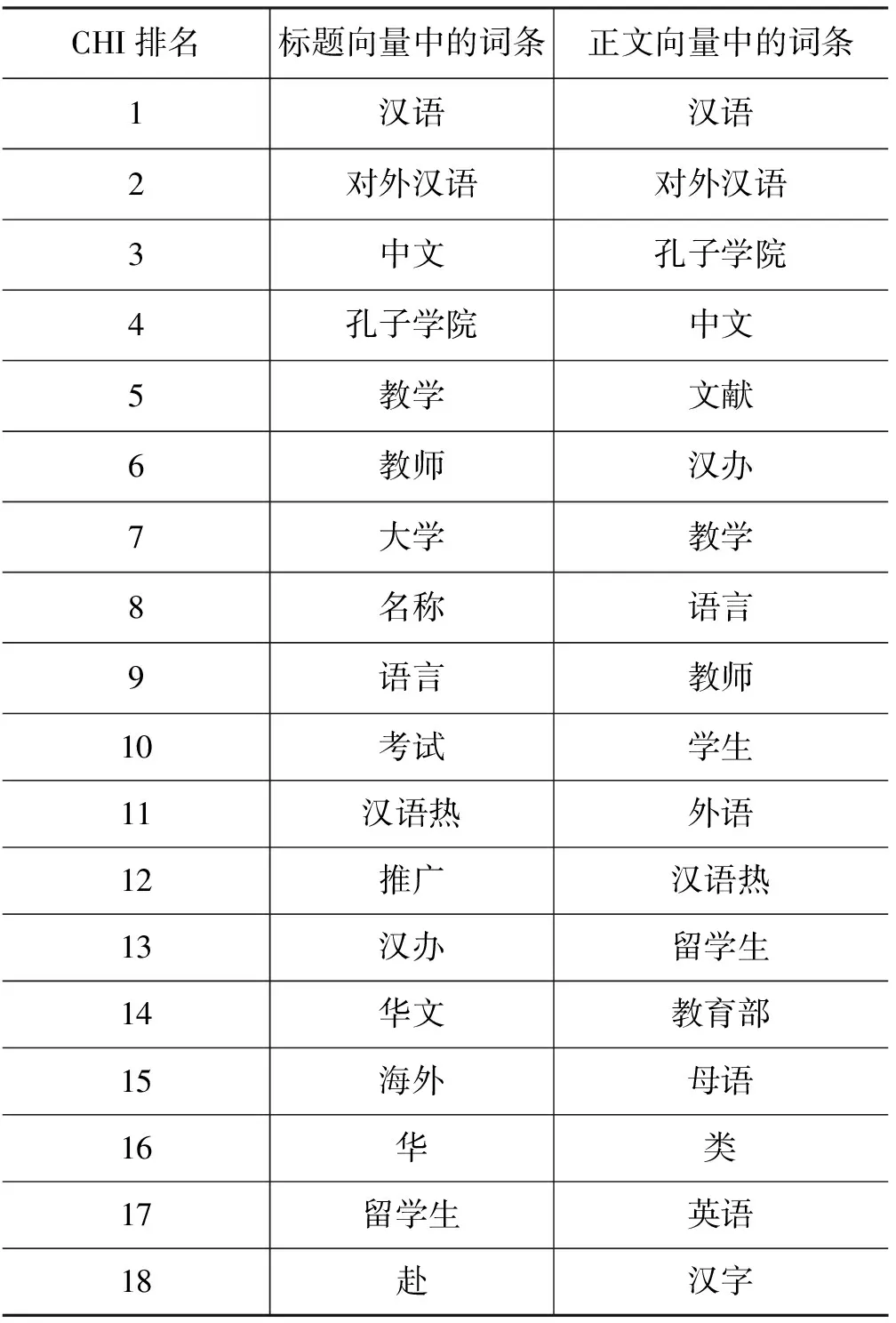
表1 DF与CHI相结合的方法针对标题与正文统计出的对外汉语高度相关的词条
作为对比试验的传统的文本分类法同样采用DF与CHI相结合的方法选取特征向量,向量维度取200,与标题与正文相结合的文本分类法相同。选取的部分特征如表2所示。
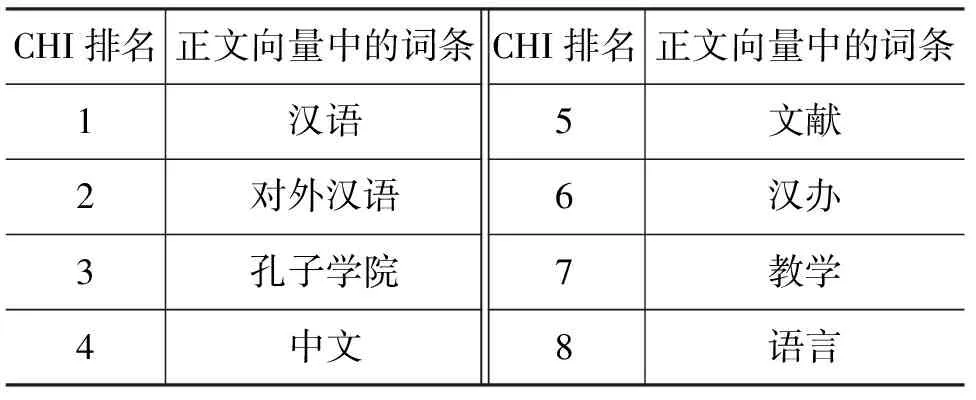
表2 DF与CHI相结合的方法针对全文统计出的对外汉语高度相关的词条

续表
3 基于标题与正文相结合的分类器构建
3.1 文档表示
实验过程中需要将文档转变为计算机可计算的形式,这里采用了目前较为通用的文档向量模型(VSM)表示法,在该方法中文档被表示成向量形式,向量中每个分量的具体值为该特征项在文档中的权重。
权重的计算在本文中采用了TFC的计算方法。该方法为对文本长度进行规一化处理后的TF-IDF方法,具体的计算公式如下:
(3)
其中wij表示特征项ti在文本Dj中的权重;tfij表示特征项ti在文本Dj中出现的频数;ni为训练集中出现ti的文档数,N为训练集中总文档数。
3.2 分类器的构建
分类器的构建采用了类中心向量法。该方法为著名的Rocchio分类器的一个特例,其基本思想是首先为每个训练文本C创建一个特征向量,然后利用同一个类中的全部训练文本建立该类的类向量。当待分类文本输入后,计算待分类文本与各个类向量之间的距离,然后根据计算出的距离值决定待分类文档的类别[6]。本文中涉及的分类问题为两类问题,即只需要判断是否与主题相关,向量的计算方法为:
(4)
其中wj为类向量的第j个分量,nC为属于类别C的文本数,xij为类别C中第i个文档的第j个分量。
这里的距离计算我们采用了向量夹角的余弦值法,计算方法为:
(5)
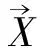
我们针对主题类别构建了两个类向量:一是类标题特征向量,一是类正文特征向量。二者都通过DF与CHI统计量相结合的方式选取。当目标文档输入后,首先提取其标题信息并做出主题相关度判定,对于无法判定的网页在对其正文部分进行主题相关度判定,并得出判定结果。模型如下:
Sim(D,T)
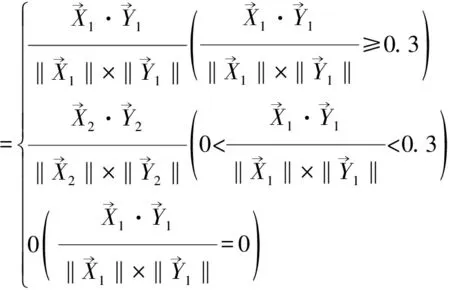
(6)

在阈值的选取过程中,我们采用了F1评价指标作为其选取标准,在整个训练集上训练时,随着首次分类标题阈值和二次分类正文阈值的变化,F1指标在标题阈值取0.3,同时正文阈值取0.2时达到最大为0.928,此时P值为0.925,R值为0.931,均达到一个极大值水平,故在此,我们将首次分类标题阈值大于0.3的文本判定为主题相似,对于首次分类不能判定的文本,即标题相似度介于(0,0.3)的文本进行二次分类,如果计算得出的正文相似度大于0.2,则判定为主题相似,至此,分类过程结束。阈值训练数据如表3所示。
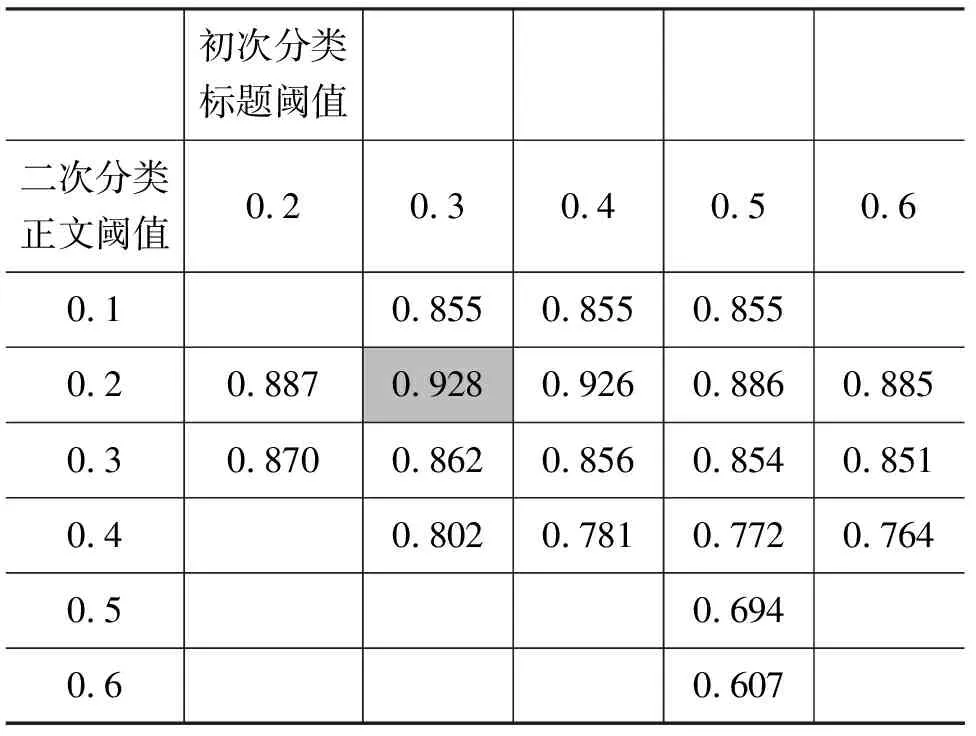
表3 两阶段分类阈值训练结果
3.3 实验数据
实验数据样本采用了复旦大学自然语言处理实验室提供的公开语料,其数据规模为8 264个文本文件,其中包括艺术、文学、教育、哲学、历史、航空航天、能源、电子、通信、计算机、矿产、交运、环境、农业、经济、法律、医疗卫生、军事、政治、体育共20个领域的内容,这部分数据在整个样本集中主要构成反例数据。对外汉语领域相关的正例数据主要摘自于国家对外汉语网、国际汉语教育学会网、北京语言大学、国家汉办、对外汉语论坛、北京大学中文论坛以及对外汉语教师之家的951个文本文件,涉及新闻、论文、书籍介绍等对外汉语相关的题材。整个样本集规模为9 215个文本文件,分别从正反例文本集中按各类别所占比例均匀选取其中1 702个文本构成测试集,余下的7 513个文本构成训练集。对训练集、测试集中的文本提取出标题数据后,标题和正文形成一一对应关系,最后形成的数据集中,训练集数据包括标题正例集767个文本、标题反例集6 746个文本以及正文正例集767个文本、正文反例集6 746个文本,共四个部分,测试集包括标题集1 702个文本和正文集 1 702个文本两部分数据。
4 实验结果及分析
为评价分类效果,我们采用了比较通用的性能评价方法:召回率R(Recall)、准确率P(Precision)和F1评价。召回率为被分类器正确识别的文档数占整个测试集中正例文档总数的比率。准确率为正确分类的文档数与被分类器识别文档总数的比率。F1度量为二者相结合的一个评价指标,其计算方法为:
(7)
测试集1 702个文本中,包含正例数据184个,反例数据1 518个。试验过程中,为争强对比性,传统的文本分类法与标题与正文相结合的文本分类法采用相同的特征维度以及权重统计方法(均为归一化的tf×idf法),试验结果如表4所示。
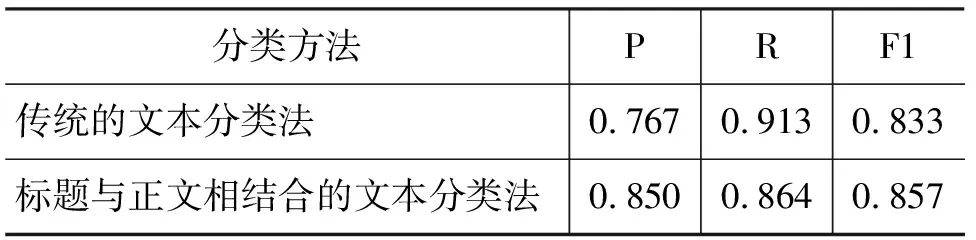
表4 在测试集上的测试结果
在测试过程中我们发现与传统的文本向量法相比,本文中提出的方法P值比传统的文本分类方法有一定的提高,R值略逊于传统方法,F1值也比传统方法要好,总体而言P值和R值较为平衡,要好于传统的分类方法。同时,我们注意到,传统方法在测试集上测试时耗时36 672ms,而改进后的新算法仅用时3 250ms,用时仅为传统方法的十分之一,性能上有了非常显著的提高,出现这种情况的原因主要是新算法在首次分类过程中处理了1 464个文本,占整个测试集文本数的86%,由于标题部分文本较小,处理起来非常快,故整个算法的效率得到了显著的提升,而效率问题对于在线主题爬虫而言是至关重要的,新算法在不牺牲准确率和召回率的前提下,极大的提升了在线分类的效率,因而有着极高的实用价值。
5 结论
本文针对主题爬虫在线爬取主题相关的网页时面临的文本分类问题构建了在线文本分类器,设计了先标题再正文的两阶段文本分类模型。实验结果表明该分类器较传统的分类方法在召回率和效率上都有明显的提高,并且经过适当的扩展就可以直接用于多类文本的分类问题。目前,基于该分类器,我们已经构建了对外汉语领域主题爬虫,通过该爬虫动态获取、分析互联网上对外汉语领域相关资源,大大拓展了对外汉语领域相关数据来源的广度,并极大的提高了获取数据的效率和质量,为大规模教学资源库的构建打下了良好的基础。
以此同时,本课题将为对外汉语教学资源的积累提供新的出路,通过资源的动态获取、分析,大大降低了对外汉语教材编者、教师和本领域的专家学者教材编著过程中那些机械性、重复性的劳动,并为其教学、研究提供了广泛、实时的数据支持,从而更有利于发挥其创造才能,帮助其更好的实现自身价值。
[1] 刘汉兴,刘财兴. 主题爬虫的搜索策略研究 [J]. 计算机工程与设计,2008,29(12).
[2] Y. Yang. A Comparative Study on Feature Selection in Text Categorization[C]//Proceeding of the Fourteenth International Conference on Machine Learning (ICML 97),412-420,1997.
[3] 彭时名. 中文文本分类中特征提取算法研究[D]. 硕士学位论文.
[4] 宗成庆 统计自然语言处理 清华大学出版社,2008.5
[5] 代六玲,黄河燕,陈肇雄.中文文本分类中特征抽取方法的比较研究 [J].中文信息学报,2004(l):26-33.
[6] 庞剑锋,卜东波,白硕.基于向量空间模型的文本自动分类方法的研究与实现[J].计算机应用研究, 2001:5-6.
[7] F. Menczer, G. Pant, M. Ruiz, and P. Srinivasan. Evaluating topic-driven Web crawlers[C]//Proc. 24th Annual Intl. ACM SIGIR Conf. on Research and Development in Information Retrieval, 2001.
[8] Dekang Lin, An information-theoretic definition of similarity[C]//Proceedings of the 15th International Conf. on Machine Learning, pp.296-304. Morgan Kaufmann, San Francisco, CA, (1998).
[9] Michelangelo Diligenti, Frans Coetzee, Steve Lawrence, C. Lee Giles, Marco Gori. Focused Crawling using Context Graphs[C]//26thInternational Conference on Very Large Databases, VLDB 2000, Cairo, Egypt, pp.527-534, 2000.
