基于树剪枝的典籍文本快速切分方法研究
——以《茶经》的翻译为例
2010-06-05汪榕培
姜 欣,姜 怡 ,方 淼,汪榕培
(1. 大连理工大学 外语学院、电信学院,辽宁 大连 116024;
2. 东北大学 秦皇岛分校 电子信息系,河北 秦皇岛 066004)
1 引言
中国浩瀚典籍是中华文化的瑰宝,亟待向世界传播。可典籍中大量的术语、典故、专有名词等造成了典籍在阅读、理解和翻译上的困难。以茶文化典籍为例,从唐代陆羽《茶经》至清朝的《续茶经》已有几十部作品,可由于茶文化中一些专业术语的存在使得读者难以准确迅速地阅读、理解甚至翻译,而这构成了目前茶文化对外传播与交流的瓶颈。因此,如何对典籍文本的自动切分就成了关键问题。
目前,典籍文本的汉语词语自动切分方法大致可以分成三类:基于词典的方法[1-4],基于统计的方法[5-9]和混合的方法[10-13]。基于词典的方法主要借助于词典,遵循一定的匹配原则对文本进行扫描,进而进行文本词句的划分,可遗憾的是由于受到词典的限制,基于词典的方法难以处理词典未登录词,因此就会存在语句理解上的歧义。为了解决这种局限性,有学者借助于统计模型,利用词语的概率分布进行文本的切分,不受领域和词典的限制,但是却需要大量的训练文本,其训练文本的质量决定着切分的性能。ICTCLAS作为国内外权威的现代汉语分词工具,使用词典和统计结合的方法,不需要受到词典的限制,也不需要训练文本,通过计算两个词语的出现是否独立推断两个字是否能够形成一个词语,能够有效地从原始语料中获取术语、典故和专有名词。但是由于多词单元的存在,统计相关度量很难自动确定词语的边界。因此,在课题组使用ICTCLAS对《茶经》和清朝文人陆廷灿的《续茶经》进行切分的过程中,虽然能得到一些合理的结果,但是因为受到自身词典词语覆盖面的限制,因而在处理茶典籍中的术语、典故和专有名词等问题的时候效果仍不理想。
为了解决上述问题,本文作者基于树剪枝的相关理论,以《茶经》的翻译为例提出了一种新的典籍文本快速切分方法。其基本思想就是利用统计量似然比λ来计算相邻两个词之间的相关度,然后逐步向多词单元扩展,形成二字乃至多字的候选,然后使用快速的树剪枝算法寻找典籍文本全局最优的划分,即在全局范围内确定词语的边界,进而对典籍文本进行合理的翻译。理论分析及实例表明,该方法可以有效地进行典籍文本的快速切分以改善典籍文本翻译的质量。
2 相关度量和扩展计算
2.1 统计相关度量
统计相关度量有很多种,如t分布,χ2,似然比λ等。然而,由于似然比λ不需要严格遵循正态分布并且适合处理稀疏矩阵的特点,能克服数据庞大、信息量不易提取的瓶颈,因此在典籍文本的快速切分中具有良好的应用前景。为了更好的开展研究,首先给出似然比λ的相关概念定义[14]。
规则1设二元组w1w2为相邻出现的两个词,规定
假设1:如果w2的出现和其前面w1的出现是独立的,则p(w2|w1)=p=p(w2|w1)
假设2:如果w2的出现和其前面w1的出现不是独立的,则p(w2|w1)=p1≠p2=p(w2|w1)。
根据规则1,用c1,c2和c12分别表示语料库中w1,w2和w1w2出现的次数,就可以使用最大似然估计的方法计算p,p1和p2,计算公式如下:
(1)
则在假设1的条件下,实际观测到的w1,w2和w1w2的似然值满足
L(H1)=b(c12;c1,p)b(c2-c12;N-c1,p)
(2)
在假设2的条件下,实际观测到的w1,w2和w1w2的似然值满足
L(H2)=b(c12;c1,p1)b(c2-c12;N-c1,p2)
(3)

那么,似然比λ的定义如下:
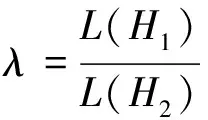
(4)
表示参数空间最大似然估计与全参数空间最大似然估计的比值。
对式(4)两边同时取对数,得到:
试验日粮根据试验设计要求的饲养标准参考NRC(1998)进行饲粮的配制(见表1)。4个组的基础日粮配方完全相同,对照组不添加苏氨酸,试验1~3组的苏氨酸水平分别为0.6%、0.8%、1.0%,4个组赖氨酸水平均为1.20%。
(5)
其中,L(k,n,x)=xk(1-x)n-k。
由于全空间(p1,p2)是关于w1先出现时w2出现的概率p1和其他词先出现时w2出现的概率p2的两维空间,p1=p2是一个特殊的子空间,则可以根据观测数据分别计算子空间和全空间的最大似然值,然后计算似然比λ。另外,由于-2logλ是渐进逼近χ2分布的,因此通过查询统计分布表,就可以在给定置信水平α下验证拒绝H1还是拒绝H2。以《茶经》的“隽”“永”两个单字的翻译为例,给定置信水平α=0.005,则通过计算和查表得知可以拒绝H1,接受H2,即认为两者非独立出现,临界值是7.88(自由度为1)。这说明两个字很可能构成一个词,在文章的翻译的过程中译成“隽永”的可能性比较大。
2.2 扩展计算
从前述分析可以看出,统计相关度量能度量两个字之间的相关度,并由此确定两词的词义。然而在处理三个字或者更多字组成的词语翻译的时候,这个度量值的精确度却会大大降低,而在典籍文献中经常会出现三个字或者更多字组成的词语,为了计算三字以上字串的统计相关度量的大小,更合理的对典籍进行翻译,就需要对似然比的概念定义进行扩展。
设三个字(w1w2w3)的情况,计算其λ值可以考虑如下两种情形:w1w2先结合,然后再与w3计算λ值;或者w2w3先结合,然后再与w1计算λ值。由此可见,二者可能相同,也可能不同,定义最大的一个λ值作为w1w2w3的似然比。
同理,对于四个字(w1w2w3w4)的情况有三种结合方式,即:w1w2w3作为整体与w4结合,计算其λ值;w1w2与w3w4结合,计算其λ值;w1与w2w3w4结合,计算其λ值。最终,取大的一个λ值作为w1w2w3w4的似然比。以此类推,五个字(w1w2w3w4w5)的情况也采用类似的计算方法。
在实际应用中发现,典籍文本中五个字以上的词语中已经很少有单独的词语,大多数都是组合的词语,即使是三个字、四个字的后选中都有不少是组合的词语。因此,如果仅仅使用统计值来推断是否是词语或者构成术语、专有名词等,在典籍文本的划分过程中就会出现偏差。因此,为了解决这些候选出现的时候典籍文本的正确翻译的问题,需要结合以上的计算模型,从全局上考虑最佳的切分。以下就是针对这个问题进行论述。
3 基于树剪枝的快速切分方法及流程图
在中国古典文献中,常常出现一些文言虚词,这些文言虚词基本不能明确地表示意义,而只能组织实词使句子结构完整,是构成文言句子不可或缺的部分。如果它们与其他实意字之间有很强的相关性,只会对结果造成干扰,因此排除这些词以及由它们构成的多词单元。
这两部茶典籍中常见的文言虚词共有32个,即“安, 而, 尔, 夫, 盖, 故, 何, 乎, 或, 即, 既, 莫, 乃, 其,且, 然, 若, 虽, 所, 为, 惟, 焉, 也, 以, 矣, 已, 因, 于, 哉, 则, 者, 之”。因此,在对古文句子进行切分的过程中首先排除这些文言虚词,然后再计算全局频繁模式的最佳统计值λ。其基本算法如下[15]:
设一个字串w1w2w3…wn-2wn-1wn是一个短句,可能的切分如w1/w2/w3/ … /wn-2/wn-1/wn,所有可能的切分是共有2n-1种。设任意一种切分w1/w2/w3/ … /wn-2/wn-1/wn的关联度量为λ(w1/w2/w3/ … /wn-2/wn-1/wn),计算采取如下规则:如果两个字的串形成一个切分为w1w2,则λ(w1w2)=-2logλ,即前面所求的w1w2关联度量;如果两个字的串所形成的切分为w1/w2,由于-2logλ是渐进逼近χ2分布的,则假设λ(w1/w2)=7.8,以最大化两词独立的情况。
故而,典籍文本的切分问题就形式化为求解一个最大切分关联度量值的切分,即:
(6)
求解过程可以用一个树修剪的方式进行,其算法如下:
扩展步:字串w1w2…wn的切分可以看作是以w1开始,不断扩展的过程。w1与w2连接的切分有两种方式w1w2和w1/w2,可以看作w1扩展w2之后生成两个节点。w1w2w3的切分方式有四种:w1w2w3,w1w2/w3,w1/w2w3,w1/w2/w3,分别由上面的两个节点生成。以此类推。把w1作为根节点,w2扩展了一个字之后形成了字串w1w2,而形成两种切分w1w2和w1/w2,相当于生成了两个子节点。同时,节点w1w2也可以再扩展一个字w3,生成两个切分节点w1w2w3和w1w2/w3。另外,w1/w2也生成两个节点w1/w2w3和w1/w2/w3,即每个节点又生成两个子节点。以此类推,待扩展到wn的时候可以形成一棵满二叉树,共有n层,如图1所示,叶节点共有2n-1个,即2n-1种切分。其中,定义生成左子树的扩展为左向扩展,生成右子树的扩展为右向扩展。
修剪步:由于在一次扩展后会产生2n-1个节点,例如在第二层上共有两个节点,w1w2和w1/w2,如果λ(w1w2)>λ(w1/w2),则w1w2的右向扩展总是比w1/w2的右向扩展的似然比λ大,那么w1/w2的右向扩展将没有意义,则将w1/w2的右向扩展预先修剪掉,只保留w1w2的右向扩展。
搜索:为了实现高效搜索,采用队列数据结构来存储中间切分串,即广度优先遍历全局的二叉树,在第k层进行扩展的时候,把扩展结果存入待扩展队列中。扩展完成之后计算扩展后的k+1层上节点的λ值,取最大λ值的节点下一步进行双向扩展,其余节点只进行左向扩展。如果一个节点的切分后最后一个串等于最长的词长,将只进行右向扩展。如w1…/wi-L+1wi-L+2…wi(其中,L为最大词长)将不再进行左向扩展。
图1显示了整个算法的基本流程。由整个扩展过程可以看到,由于在每一层上都进行预修剪和根据词长修剪,将不再搜索整个二叉树上的所有节点,而只需要计算1+2+3+L+L+…+L=nL-L(L-1)/2,计算的时间复杂度为o(LN),L为词长常数。相对于计算所有节点算法的时间复杂度为o(n2) 来说,算法的空间复杂度变得更为简单。
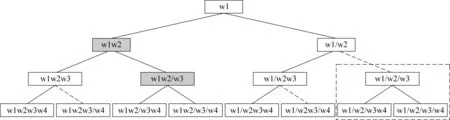
图1 字串切分扩展图
4 实例分析
为了验证本文所构建典籍文本切分方法的合理性和有效性,课题组选取了《茶经》《续茶经》和其余28篇茶文,共158 687个汉字来进行分析说明。
首先,使用这些语料计算二元组、三元组、四元组和五元组候选,共产生候选数目如表1所示。
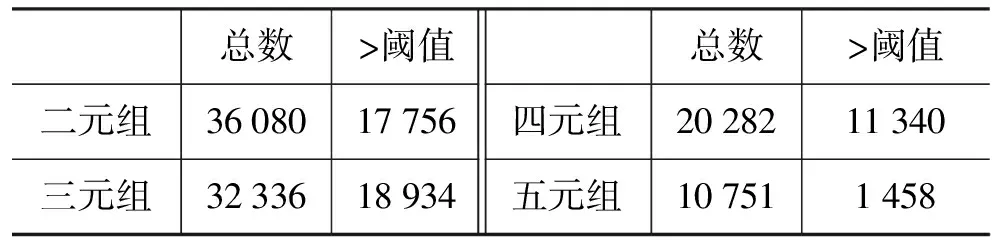
表1 候选组数及阈值
分别采用树剪枝方法和ICTCLAS对《茶经》文本进行了切分,切分结果的准确性采用准确率(precision)、召回率(recall)、调和值(F-score)以及切分效率(Effectiveness)进行衡量,如表2所示。

表2 典籍文本切分对比结果
表2表明,典籍文本的树剪枝切分方法能有效解决典籍领域的词语切分问题,和ICTCLAS方法相比,在准确率、召回率和F值上其效能分别提升了17%、8%、13%,而在切分效率上提升了7%。这说明,本文所提出的典籍文本的切分方法不仅可以提升典籍文本翻译的效率,而且具有良好的应用价值及应用前景。
5 结论
为了解决典籍文本中大量的术语、典故、专有名词等造成的典籍阅读、理解和翻译上的困难,本文作者基于树剪枝的相关理论和思想,以《茶经》的翻译为例提出了一种新的典籍文本快速切分方法:在采用统计似然比计算两字、多字单元的候选集合的基础上,使用树剪枝算法快速求解全局最优切分,并以《茶经》为例进行了算例分析。理论分析及实例表明,该方法不仅可以有效地进行典籍文本的快速切分以改善典籍文本翻译的质量,降低了算法的复杂度,能较好的解决典籍文本在阅读、理解和翻译上的文本切分问题。
然而,在典籍文本中存在一些韵脚用字的相似度问题,而这对于典籍文本的自动切分会造成一些信息量的耦合问题,如何对这样的问题进行深入分析,是需要进一步研究的问题。笔者正在做这方面的研究,由于篇幅问题,将另文给出。
[1] 张春霞, 郝天永. 汉语自动分词的研究现状与困难[J].系统仿真学报.2005,(1):138-143.
[2] Robert Dale, Herman Moisl, Harold Somers. Handbook Of Natural Language Processing[M]. New York:Marcel Dekker, Inc. 2000.
[3] David D. Palmer. A trainable rule-based algorithm for word segmentation[C]//Proceedings of the 35th annual meeting of the association for computational linguistics, 321- 328.
[4] 孙茂松, 左正平, 黄昌宁. 汉语自动分词词典机制的实验研究[J]. 中文信息学报.2000,14(1):1-6.
[5] 吴胜远. 获取最新 一种汉语分词方法[J].计算机研究与发展.1996,(4):306-311.
[6] Richard Sproat, Chilin Shih, Willian Gale, et al. A stochastic Finite State word segmentation algorithm for Chinese[J]. Computing Linguist, 1996,(3):377-404.
[7] 李家福, 张亚非. 一种基于概率模型的分词系统[J].系统仿真学报. 2002, (5):544-550.
[8] Dai Yubin, Loh Teeck Ee, Khoo Christopher. A new statistical formula for Chinese text segmentation incorporating contextual information[C]//Proceedings of the 22ndannual international ACM SIGIR conference on research and development in information retrieval, pp.88-89,1999.
[9] Utiyama Masao, Isahara Hitoshi. A statistical Model for domain independent text segmentation[C]//The annual meeting of the association for computational linguistics and 10thconference of the European chapter of the association for computational linguistics, pp.491-498, 2001.
[10] 赵铁军, 吕雅娟,等. 提高汉语自动分词精度的多步处理策略[J].中文信息学报. 2001,15(1):13-18.
[11] Zhang Huaping,Yu Hongkui, Xiong Deyi, Liu Qun. HHMM-based Chinese lexical analyzer ICTCLAS[C]//The 2ndSIGHAN workshop in the 41stmeeting of the association for computational linguistics, 2003:184-187.
[12] Christopher D. Manning, Hinrich S., Foundations of statistical natural language processing, MIT press[M]. 1999.
[13] Dunning Ted. Accurate methods for statistics of surprise and coincidence[J]. Computational Linguistics, 1993,1:61-74。
[14] J. Omura and T. Kailath, Some Useful Probability Distributions’ Stanford Electronics Laboratories Stanford[C]//CA, Tech. Rep. No. 7050-6, 1965.
[15] Mingyu Zhong,Michael Georgiopoulos,Georgios C. Anagnostopoulos.A k-norm pruning algorithm for decision tree classifiers based on error rate estimation [J]. Machine Learning, 2008, 71(1):55-88.
