非参数估计方法
2010-05-29张煜东王水花吴乐南
张煜东,颜 俊,王水花,吴乐南
(1.东南大学信息科学与工程学院,江苏 南京 210096;2.哥仑比亚大学精神病学系脑成像实验室,纽约州 纽约 10032)
0 引 言
函数估计[1]是一个经典反问题,一般定义为给定输入输出样本对,求未知的系统函数[2].传统的方法为参数方法,即构建一个参数模型,再定义某个误差项,通过最小化误差项来求解模型的参数[3].
参数方法尽管较为简单,但不够灵活.例如参数模型假设有误,则会导致整个求解流程失败[4].因此学者们发展出不少新技术,非参数估计就是其中一项较好的方法.该方法无需提前假设参数模型的形式,而是基于数据结构推测回归曲面[5].
本文首先研究了经典的2种参数回归方法:最小二乘法与内插函数法,分析了它们的不足,然后主要讨论8种非参数回归方法:核方法、局部多项式回归、正则化方法(样条估计)、正态均值模型、小波方法、过完全字典、前向神经网络、径向基函数网络,尤其详细介绍了其间的相关性与继承性.最后,研究了高维情况下面临的计算维数诅咒与样本维数诅咒.
1 回归模型
考虑模型
yi=r(xi)+εi
(1)
式(1)中(xi,yi)为观测样本,假定误差ε具有方差齐性,则r=E(y|x)称为y对x的回归函数,简称回归.一般地,可以假设x取值在[0,1]区间内.定义“规则设计”为xi=i/n(i=1,2,…,n).并定义风险函数为
(2)

回归一词源于高尔顿(Galton),他和学生皮尔逊(Pearson)在研究父母身高和子女身高的关系时,以每对夫妇的平均身高为x,取其一个成年儿子的身高为y,并用直线y=33.73+0.512x来描述y与x的关系.研究发现:如果双亲属于高个,则子女比他们还高的概率较小;反之,若双亲较矮,则子女以较大概率比双亲高.所以,个子偏高或偏矮的夫妇,其子女的身高有“向中心回归”的现象,因此高尔顿称描述子女与双亲身高关系的直线为“回归直线”[6].
然而,并非所有的x-y函数均有回归性,但历史沿用了这个术语.更为精确的表达是“函数估计”.
2 传统方法
理论上描述一个函数需要无穷维数据,因此函数估计本身也可称为“无穷维估计”[7].传统的估计方法有下列两种极端情形.
2.1 最小二乘法
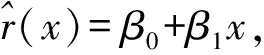
(3)

(4)
这里Y=(y1,y2,…,yn)T.L=X(XTX)-1XT称为帽子矩阵[9].以5个样本点的一维规则设计矩阵为例,此时

(5)
L满足L=LT,L2=L.另外,L的迹等于输入数据的维数p,即trace(L)=p.这里输入数据是一维的,所以trace(L)=1.
2.2 内插函数法

(6)
2.3 两种方法的缺陷
图1给出了这两种极端拟合的示意图,数据是被高斯噪声干扰的正弦函数,采用上述两种方法拟合,结果表明:最小二乘法过光滑,未展现数据内部的关系;而内插函数法忽略了噪声影响,显得欠光滑.
从帽子矩阵也可看出,式(5)表明最小二乘法对每个数据的估计都利用了所有样本,这显然导致过光滑,且x值越大的数据权重越大,这明显与经验不符;反之,式(6)表明内插函数法仅仅利用了最邻近的样本数据,这显然导致欠光滑.

图1 两种极端拟合
2.4 非参数回归的优势
非参数回归(non-parametric regression)作为最近兴起的一种函数估计方法,是一种分布无关(distribution free)的方法,即不依赖于数据的任何先验假设.与此对应的是参数回归(parametric regression),通常需要预先设置一个模型,然后求取该模型的参数.非参方法的本质在于:模型不是通过先验知识而是通过数据决定.需要注意的是,“非参数”并不表示没有参数,只是表示参数的数目、特征是可变的(flexible).
由于非参方法无需数据先验知识,其应用范围较参数方法更广,且性能更稳健.其另一个优点是使用过程较参数方法更为简单.然而,它也存在缺点,一般结构更复杂,需要更多的运算时间.
2.5 线性光滑器
需要说明的是,最小二乘法、内插函数法、核方法、正则化方法、正态均值模型均是线性光滑器.定义为:若对每个x,存在向量l(x)=[l1(x),…,ln(x)]T,使得r(x)的估计可写为
(7)

3 核回归
核方法[12]定义为
(8)
权重li由式(9)给出
(9)
这里h是带宽,K是一个核,满足K(x)≥0,以及
(10)
常用的核函数见表1.

表1 常用的核公式
以boxcar核为例,帽子矩阵为

(11)
显然,这可视作最小二乘法与内插函数法的折中.
为了估计带宽h,首先必须估计风险函数,一般可采用缺一交叉验证得分
(12)
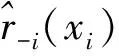
(13)
这里Lii是光滑矩阵L的第i个对角线元素.另一种方法是采用广义交叉验证法,规定
(14)
这里v=tr(L).
4 局部多项式回归
采用核回归常会碰到下列2个问题[13]:1)若x不是规则设计的,则风险会增大,称为设计偏倚(design bias);2)核估计在接近边界处会出现较大偏差,称为边界偏倚(boundary bias).为了解决这2个问题,可采用局部多项式回归.

(15)
利用高等数学知识,可以看出解为
(16)
可见式(16)正好是核回归估计.这表明核估计是由局部加权最小二乘得到的局部常数估计.因此,若利用一个p阶的局部多项式而不是一个局部常数,就可能改进估计,使曲线更光滑.定义多项式
(17)
则局部多项式的思想是:选择使下列局部加权平方和
(18)

(19)
当p等于0时,等于核估计;当p=1时,称为局部线性回归(local linear regression)估计[15],由于其算法简单且性能优越,较为常用.
5 基于正则化的回归
为了描述方便,这里假设数据点为[(x0,y0),(x1,y1),…(xn-1,yn-1)].在风险函数(2)后增加一项惩罚项,一般设为r(x)的二阶导数
(20)
为了加速计算,将数据点重新排序,假设a,b为样本点x的上下界,令a=t1≤t2≤…≤tn-1=b,这里t是x重新排序后的点,称为结点.可用B样条基(B-spline basis)[16]作为该三次样条的基,即
(21)
Pi称为控制点,共n-m个,形成一个凸壳.n-m个B样条基可通过如下计算,首先初始化:
(22)
然后对i=1,逐步+1,直到i=m-1,重复迭代下式:
(23)
若结点等距,则称B样条是均匀的(uniform),否则称为不均匀.如果两个结点相等,计算过程会出现0/0情况,此时默认结果为0.

P=(BTB+λΩ)-1BTY
(24)
可见,样条也是一个线性光滑器.
(25)
式中,f(x)是x的密度函数.
(26)
(27)
显然,若样本x是规则设计,则f(x)=1,h(x)=(λ/n)1/4=h,li(x)∝K[(xi-x)/h],即此时样条估计可视作形如式(27)的渐近核估计.
6 正态均值模型

(28)
则随机变量Zj是正态分布,且均值与方差满足:
E(Zj)=θjV(Zj)=σ2/n
(29)


(30)

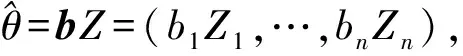
①b=(b,b,…,b),称为常数调节器(constant modulator),此时令式(30)最小的 称为James-Stein估计;
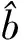
③b=(b1,b2,…,bn)满足1≥b1≥b2≥…≥bn≥0,称为单调调节器(monotone modulator),该方法理论最优,但是需要的运算量太大,几乎不实用.
7 小波方法
小波方法[19]适用于空间非齐次(spatially inhomogeneous)函数,即函数的光滑程度随着x会有本质性的变化.它可视作正态均值模型的推广,但存在两点区别:一是采用小波基代替传统的正交基,因为小波基较一般的正交基具有局部化的优点,能实现多分辨率分析;另一点是采用了一种称为“阈”的收缩方式.
不妨假定父小波为φ,母小波为ψ,同时规定下标(j,k)的意义如下:
fj,k(x)=2j/2f(2jx-k)
(31)
为了估计函数r,用n=2J项展开来近似r,
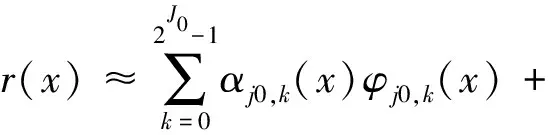
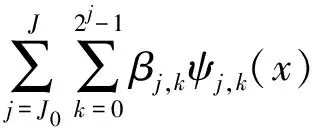
(32)
这里J0是任取常数,满足0≤J0≤J.α称为刻度系数,β称为细节系数.那么如何估计这些系数?首先计算
(33)
(34)
Sk、Djk分别称为经验刻度系数与经验细节系数,可知Sk≈N(αj0,k,σ2/n),Djk≈N(βj,k,σ2/n),可估计方差为

|∶k=0,…,2J-1-1)/0.6745
(35)
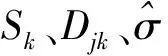
(36)
β的估计形式稍许复杂,采用硬阈与软阈的方式分别为
(37)
(38)
之所以采用阈的形式,是因为稀疏性(sparse)的思想[20]:对某些复杂函数,在小波基上展开时系数也是稀疏的.因此,需要采用一种方式来捕获稀疏性.然而,传统的L2范数不能捕捉稀疏性,相反,L1范数与非零基数能够较好地捕捉稀疏性.例如,考虑n维向量a=(1,0,…,0)与b=(1/n1/2,…,1/n1/2),有‖a‖2=‖b‖2=1,可见,L2范数无法区分稀疏性.反之,‖a‖1=1,‖b‖1=n1/2,因此,L1范数能提取稀疏性;另外,若令非零基数为J(θ)={#(θi≠0)},则J(a)=1,J(b)=n,因此,非零基数也能提取稀疏性.最后,在正则化估计中若惩罚项分别为L1范数或非零基数,则最优估计恰好对应着软阈估计与硬阈估计.
最后,需要解决阈估计中λ的计算问题,这里介绍两种最简单的方式:一是通用阈值(universal threshold),即对所有水平的分辨率阈值均一致,
(39)
另一种是分层阈值(level-by-level threshold),即对不同分辨率采用不同阈值,一般是通过最小化下式求得
(40)
式中nj=2j-1为在水平j的参数个数.
8 超完备字典
小波基较标准正交基的改进在于更加局部化,因此能实现对跳跃的捕捉.然而,虽然小波基非常复杂,但面对各种复杂的函数还是不够灵活.这种缺陷的根源在于:小波基是标准正交基,任意两个基函数之间正交,这保证了基函数简单完整的同时,也丧失了灵活性.
基追踪(basis pursuit)方法[21]的思想是采用一种超完备(overcomplete)的基,例如对“光滑加跳跃”的函数,传统的傅立叶基能够捕捉光滑部分,但是难以捕捉跳跃部分;采用小波基能轻易捕捉跳跃部分,但是描述光滑部分较为困难.此时若将“傅立叶基”与“小波基”合并成一个新的基,则显然这种基能够轻松地估计“光滑加跳跃”函数.
但是,这种新的基不再正交,它以牺牲正交性来获得更好的灵活性[22],故此时用“字典”来描述更精确,而本文为了简便统一仍采用“基”表述.
9 前向神经网络
以一个双层神经网络为例,记网络的输入神经元个数为m, 隐层神经元个数为n, 输出层神经元个数为q,则网络结构如图2所示.

图2 前向神经网络
与上面几节线性方法不同的是,神经网络属于非线性统计数据建模(nonlinear statistical data modeling),其隐层暗含了“特征提取”的思想,且可视作输入数据在一种“自适应的非线性非正交的基”上的映射.同样地,此时基牺牲了正交性、线性、不变性,增加了计算负担,但换来了更加强大的灵活性[23].
简而言之,前向神经网络采用了类似基追踪的方法[24],但基是自适应变化的、非线性的,因此更加灵活.前向神经网络与基追踪相似之处在于,两者的基都不是正交的,都是根据给定数据而自适应选取的最佳基.前向神经网络的优势在于无不需预选字典,字典在算法中自动生成,并可作为特征选择的一种方法.
10 径向基函数网络
首先观察径向基函数(RBF)神经元如图3所示.

图3 RBF神经元图
图中输入向量p的维数为R,首先p与输入层权值矩阵IW相减,然后求距离函数dist,再与偏置b1相乘,最后求径向基函数radbas(n)=exp(-n2),得到神经元的输出为
a=radbas(‖IW-p‖b1)
(41)
整个RBF网络由两层神经元组成,第1层为S1个如图3所示的RBF神经元,第2层为S2个线性神经元,如图4所示.在第2层开始时,第1层的输出a首先经过线性层权值矩阵LW后与偏置b2相加,再通过一个纯线性(purelin)函数purelin(n)=n,得到网络输出y为
y=purelin(LW×a+b2)
(42)
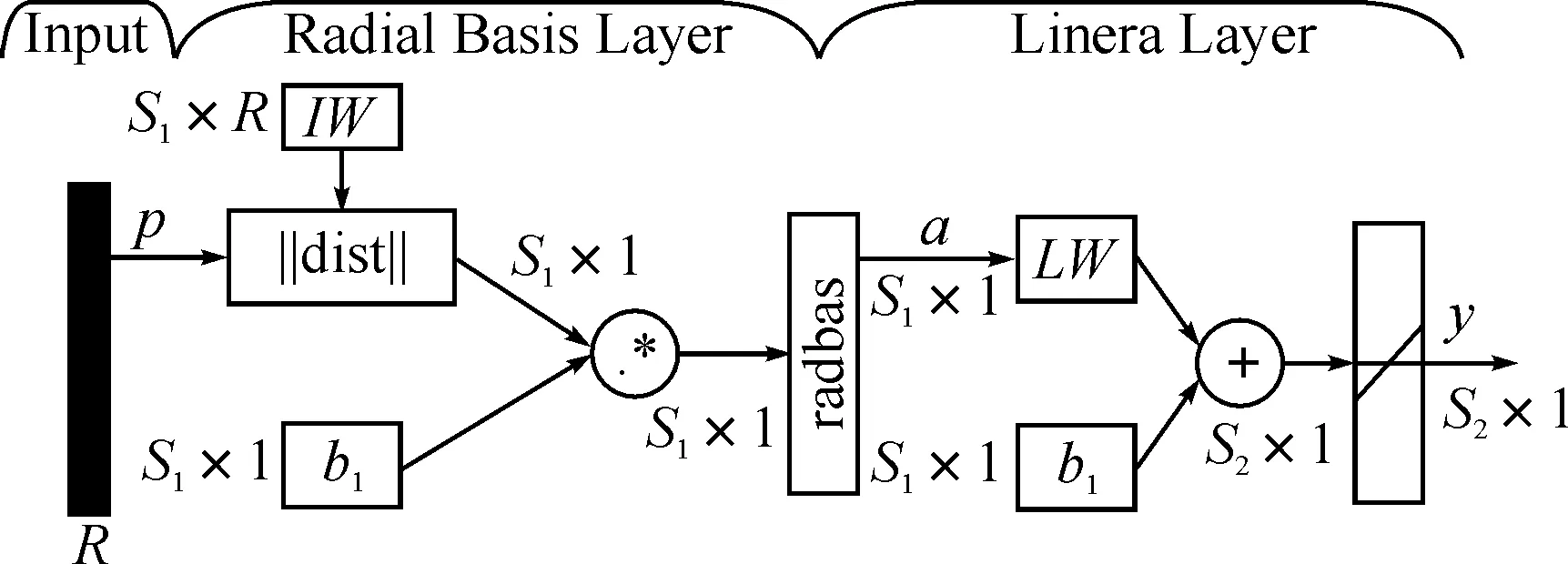
图4 RBF神经网络结构图
比较式(41)与式(9)可见,RBF网络与核方法非常类似,不同之处在于RBF网络的LW需要通过求解一个方程组,而核方法的权重是直接通过归一化计算求得,因此RBF网络预测结果更为逼近完全内插函数估计(注意不是未知函数r),而核方法计算更为简便[25].
11 维数灾难
将函数估计推广到高维,则会碰到维数诅咒(curse of dimensionality)[26](图5),它意味着当观测值的维数增加时,估计难度会迅速增大.维数诅咒有两层含义:
一是计算的维数诅咒,指的是某些算法的计算量随着维数的增长而成指数增加.解决方法通常采用优化算法,例如遗传算法、粒子群算法、蚁群算法等[27].
二是样本的维数诅咒,指的是数据维数为d时,样本量需要随着d指数增长.在函数估计中,第二层含义更为重要,这里给予详细解释.

图5 样本的维数诅咒示意图
假设一个半径r维数为d的超球,被一个边长为2r维数为d的超立方体所包围,假设超立方体内存在一个均匀分布的点,则由于超球的体积为2rdπd/2/[dΓ(d/2)],超立方体的体积为(2r)d,因此该点同时也落在超球内的概率P为
(43)
令维数d由2逐步增长到20,则对应的概率P如图6所示.显然,当d=20时,P仅为2.46×10-8.因此,若在2维空间中1个样本在半径r的意义下能逼近一个正方形,则在20维空间内,则需要1/2.46×10-8=4.06×107个样本才能在半径r的意义下逼近超立方体.

图6 概率P与维数d的关系
因此,在高维问题中,由于数据非常稀少,导致局部邻域中包含极少的数据点[28],因此估计变得异常困难.目前还没有较好的办法解决.
12 结 语
将文中阐述的方法归结并示于图7.
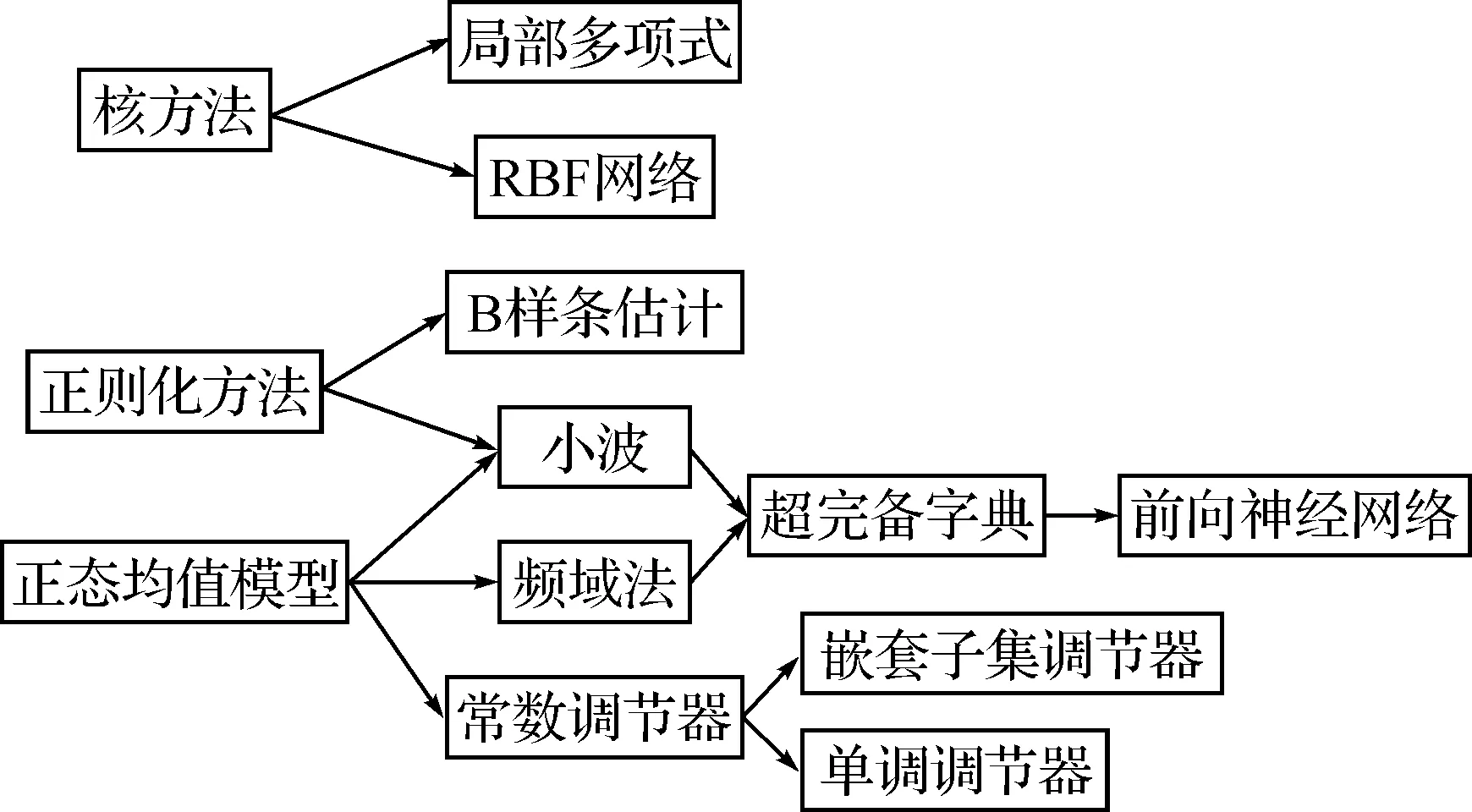
图7 非参数回归方法
不同类型方法的特点总结如下:
a. 核方法、正则化方法、正态均值模型可以视作最基本最原始的方式.另外,正则化方法与正态均值模型可视作一类特殊的核方法.
b. 核方法、局部多项式方法、正则化方法、正态均值模型、小波等方法在大多数情况下均非常类似.这些方法都包含了一个偏倚-方差平衡,所以都需要选择一个光滑参数.由于这些方法均是线性光滑器,所以均可以采用第4节中基于CV、GCV的方法.
c. 小波方法一般面向空间非齐次函数.如果需要一个精确的函数估计,而且噪声水平较低,则小波方法非常有效.但若面对一个标准的非参数回归问题,而且感兴趣于置信集,则小波方法并不比其它方法明显更好.
d. 超完备字典缺陷是丧失了基的正交性,因此估计系数变得复杂;优点是更为灵活,能够采用稀疏的系数描述复杂函数.
e. 前向神经网络与RBF神经网络是基于不同的模型独立推导出来的,二者不可混淆.另外,神经网络方法的缺点是一般不考虑置信带,并常用训练误差代替风险函数,容易过拟合;优点是面向应用、思想简单且设计灵活.
f. 理论上,这些方法没有大的差别,特别在用置信带的宽度来评价时.每种方法都有其拥护者与批评者,没有哪一种方法目前获得应用上的优势.一种解决方案是对每个问题都利用所有可行的方法,如果结果一致,则选择简单者;如果结果不一致,则必须探讨内在的原因.
g. 所讨论的方法能够用于高维问题,然而,即使通过智能优化算法解决了计算的维数诅咒,仍然面对样本的维数诅咒.计算一个高维估计相对容易,然而该估计将不如一维情况下那么精确,其置信区间会非常大.但这并不表示方法失效,而是表示问题的固有困难.
参考文献:
[1]Neumeyer N.A note on uniform consistency of monotone function estimators [J]. Statistics & Probability Letters,2007,77(7):693-703
[2]Sheena Y,Gupta A K.New estimator for functions of the canonical correlation coefficients [J]. Journal of Statistical Planning and Inference,2005,131(1):41-61.
[3]张煜东,吴乐南,李铜川,等.基于PCNN的彩色图像直方图均衡化增强[J].东南大学学报,2010,40(1):64-68.
[4]詹锦华.基于优化灰色模型的农村居民消费结构预测[J].武汉工程大学学报,2009,31(9):89-91.
[5]Wasserman L. All of Nonparametric Statistics [M].New York:Springer-Verlag, Inc.
[6]张煜东, 吴乐南, 吴含前.工程优化问题中神经网络与进化算法的比较[J].计算机工程与应用,2009,45(3):1-6.
[7]Hansen C B.Asymptotic properties of a robust variance matrix estimator for panel data when T is large [J].Journal of Econometrics,2007,141(2):597-620.
[8]Pokharel P P, Liu W F, Principe J C.Kernel least mean square algorithm with constrained growth [J].Signal Processing,2009,89(3):257-265.
[9]Kalivas J H.Cyclic subspace regression with analysis of the hat matrix [J].Chemometrics and Intelligent Laboratory Systems,1999,45(1):215-224.
[10]张煜东,吴乐南.基于二维Tsallis熵的改进PCNN图像分割[J].东南大学学报:自然科学版,2008,38(4):579-584
[11]Geçkinli N C, Yavuz D.A set of optimal discrete linear smoothers[J].Signal Processing,2001,3(1):49-62.
[12]Antoniotti M,Carreras M,Farinaccio A,et al.An application of kernel methods to gene cluster temporal meta-analysis [J].Computers & Operations Research,2010,37(8):1361-1368.
[13]Hsieh P F,Chou P W,Chuang H Y.An MRF-based kernel method for nonlinear feature extraction [J].Image and Vision Computing,2010,28(3):502-517.
[14]Katkovnik V.Multiresolution local polynomial regression:A new approach to pointwise spatial adaptation [J].Digital Signal Processing,2005,15(1):73-116.
[15]Baíllo A,Grané A.Local linear regression for functional predictor and scalar response [J].Journal of Multivariate Analysis,2009,100(1):102-111.
[16]Zhang J W,Krause F L.Extending cubic uniform B-splines by unified trigonometric and hyperbolic basis [J].Graphical Models,2005,67(2):100-119.
[17]张煜东,吴乐南,韦耿,等.用于多指数拟合的一种混沌免疫粒子群优化[J].东南大学学报,2009,39(4):678-683.
[18]Chaudhuri S,Perlman M D.Consistent estimation of the minimum normal mean under the tree-order restriction [J].Journal of Statistical Planning and Inference,2007,137(11):3317-3335.
[19]Labat D.Recent advances in wavelet analyses:Part 1.A review of concepts[J].Journal of Hydrology,2005,314(1):275-288.
[20]Kunoth A.Adaptive Wavelets for Sparse Representations of Scattered Data[J].Studies in Computational Mathematics,2006,12:85-108.
[21]Donoho D L, Elad M.On the stability of the basis pursuit in the presence of noise[J].Signal Processing,2006,86(3):511-532.
[22]Malgouyres F.Rank related properties for Basis Pursuit and total variation regularization [J].Signal Processing,2007,87(11):2695-2707.
[23]张煜东,吴乐南,韦耿.神经网络泛化增强技术研究[J].科学技术与工程,2009,9(17):4997-5002.
[24]屠艳平,管昌生,谭浩.基于BP网络的钢筋混凝土结构时变可靠度[J].武汉工程大学学报,2008,30(3):36-39.
[25]Zhang Y D,Wu L N,Neggaz N, et al.Remote-sensing Image Classification Based on an Improved Probabilistic Neural Network[J].Sensors,2009,9:7516-7539.
[26]Aleksandrowicz G,Barequet G.Counting polycubes without the dimensionality curse [J].Discrete Mathematics,2009,309(13):4576-4583.
[27]张煜东,吴乐南,奚吉,等.进化计算研究现状(上)[J].电脑开发与应用,2009,22(12):1-5.
[28]王忠,叶雄飞.遗传算法在数字水印技术中的应用[J].武汉工程大学学报,2008,30(1):95-97.
