银行反洗钱系统的研究
2010-05-14徐宏宁李代平何利明熊建斌
徐宏宁,李代平,何利明,熊建斌
(广东工业大学 计算机学院,广东 广州 510006)
在金融业,反洗钱不仅是一个世界性难题,也是一个公众持续关注的话题。洗钱这一犯罪活动给社会管理带来极大障碍,影响了社会的稳定,扰乱了金融秩序,阻碍了经济发展。为了打击违法犯罪的洗钱活动,近几年来,我国制定了相关法律法规,成立了反洗钱监测分析中心,展开反洗钱业务工作。随着反洗钱工作的深入,洗钱的新渠道层出不穷,而相关反洗钱的法律法规不健全不完善,这给反洗钱工作带来巨大压力。一个银行每天交易的数据量非常大,用人工的方式统计数据向中国人民银行上报已不再可能,必须建立一个集中式管理的反洗钱数据报送系统。数据挖掘技术是反洗钱系统中应用的核心技术。
1 系统结构及主要功能
反洗钱法的确立,使相关的反洗钱数据报送管理办法及反洗钱现场、非现场监管办法等监管制度成为银行反洗钱系统设计的依据,这些依据说明了大额特征、可疑特征、报送数据格式、报送方式及报文处理流程等。根据监管部门对反洗钱数据报送工作的要求,一个银行的反洗钱系统还必须结合本行的实际情况建立一套集中式管理的反洗钱数据报送系统。在采购人现有反洗钱数据报送系统的基础上实现大额交易及可疑交易的自动统计分析、筛选和及时报送,提供数据补正、人行回执处理及补正、相关的数据统计、查询、复核、打印等功能,才能满足反洗钱数据报送的要求和监管要求。
银行反洗钱系统在银行网络总体架构中的位置如图1所示。一个银行有多个业务系统,而这些系统的所有数据都是反洗钱系统的数据源,反洗钱系统负责从这些数据源中挖掘出大额交易与可疑交易数据并以报文形式上报给中国人民银行上报系统。

图1 反洗钱系统位置图
反洗钱系统分为两部分:数据处理部分和应用管理部分。数据处理部分结构如图2所示,该部分负责从银行不同业务系统数据库中提取原始账户数据、交易数据、客户数据等,并对这些数据进行预处理,最后根据可疑交易与大额交易特征规则挖掘出大额交易数据与可疑交易数据。原始数据集是以增量方式从分布在不同业务系统数据库提取出来的数据集,用统一形式存储。应用管理部分中一次性柜台录入的当天所有数据存储到原始数据集中;错误数据集是错误的数据信息的集合,需要通过应用管理部分中补录模块对该信息补正并审批,审批通过的数据迁移到整合数据集中。原始数据集只存储当天数据,整合数据集存储固定时间内的数据,挖掘数据库中的表增加了特征化属性,由挖掘引擎提取的数据为大额交易与可疑交易数据,大额交易与可疑交易数据上报给人行后转移到已上报数据中,上报成功的数据迁移到归档数据中备份。
应用管理部分完成错误信息的补录审批功能、一次性柜台录入、参数录入、报文管理、报表监管等功能,当然还有权限管理、日志管理、信息发部等其他应用功能。

图2 数据处理部分结构图
2 关键技术分析
2.1 分步挖掘思想
传统的数据挖掘系统基于预处理数据,也就是说在对所有数据进行数据清理、数据转换、特征化后,再通过数据挖掘引擎来挖掘有用的知识。本文鉴于具体的挖掘规则提出了分步挖掘的思想,不仅减少了挖掘引擎的压力和系统中的数据流量,同时提高了部分大额交易与可疑交易数据的上报速度。根据大额交易与可疑交易特征,部分大额与可疑交易数据可直接在原始数据集中挖掘,如图2中挖掘引擎1所示。错误信息通过应用管理部分更正后同样可直接挖掘部分大额交易与可疑交易数据,如图2中挖掘引擎2所示。比如单笔人民币交易20万美元以上或者外币交易值1万美元以上的现金缴存、现金结售汇、现钞兑换、现金汇款、现金票据解付及其他形式的现金收支,只需要对单笔交易的金额、币种、交易方式等属性进行判断即可。
2.2 数据预处理
数据挖掘的数据通常是从不同的数据库中收集在一起的数据,因此挖掘系统应该可以分析不完整的、含噪音的、并且不一致的数据。所以首先要对数据进行预处理,添加一些必要的感兴趣的属性,去除不感兴趣的属性,修正错误值,去掉重复记录和重复值等。
2.2.1 属性过滤
根据大额交易与可疑交易特征分析相关属性,添加一些与反洗钱业务特征有关的属性,去掉已有的与反洗钱业务特征没有任何关系的属性。比如对大额交易特征进行分析得出以下感兴趣的属性:交易方式、交易币种、账户类型、交易金额、当天交易总额、交易日期、固定时间内交易次数等,其中固定时间内交易次数、当天交易总额是交易表中没有的属性,而这些属性恰是感兴趣的属性。
2.2.2 数据清理
数据清理例程通过填写缺失的值、光滑噪声、识别或删除离群点并解决不一致性来清理数据[1]。在反洗钱系统中将未发生交易的客户、账户信息去除,对于客户号相同的客户根据系统优先级进行重复。将原始数据集中错误及重复客户数据导入客户错误信息表及客户重复信息表中,提供给应用管理部分中补录模块由补录人员进行修正。
2.2.3 数据特征化
在反洗钱系统中有很多感兴趣的属性值在数据库中不能直接取得,需要对目标数据特征化。数据特征化是目标类数据的一般特性或特征的汇总[1]。基于数理统计的方法是数据特征提取的主要方法,分布式度量与代数度量是必不可少的度量,通常在预计算中保留分布式度量值作为感兴趣属性值,再运用这些分布式度量值来计算代数度量值,总数统计量xi与个数统计量都是分布式度量。均值是代数度量,代数公式为:
在应用中有些度量对应于关系数据库中提供的内部聚集函数,如 sum()、count()、avg()等。 均值代数度量可通过代数公式avg()=sum()/count()来计算。反洗钱系统中度量数据的计算举例如下:(1)当日累计人民币大额交易数据的提取。需要统计所有账号当日交易的总金额,SQL语句表示为:SELECT SUM(交易额)AS交易总额 FROM交易表GROUP BY账号WHERE交易日期=当天日期。(2)集中转入分散转出和分散转入集中转出账号的提取。首先统计出一个账号在当日前有限日内的贷记交易次数与借记交易次数,再计算两者的比值,最后将此比值与根据可疑特征分析得出的比值的阈值进行比较,区分是否为分散转入集中转出还是集中转入分散转出或是正常资金周转。(3)对连续频繁交易账号的提取。首先统计出当日前固定时间内该账号发生交易的次数,再计算平均每天交易次数,最后将平均每天的交易次数与根据可疑特征分析得出的阈值进行比较,判断是否为频繁交易。
2.3 基于规则分类法
分类方法在反洗钱系统中是必不可少的方法,规则是表示知识与信息的有效手段,也是分类器的一种表示方法。本文以单笔大额交易特征为例说明基于规则分类算法的应用,基本步骤如下:
(1)根据人民银行规定的大额交易特征进行相关属性分析,确定属性名称与值的表示方式,为了论文写作的方便与信息保密性对其作了一些调整,制作成表1。如果对当日累计形成大额交易特征的记录进行筛选应将交易金额换为当日累计金额。
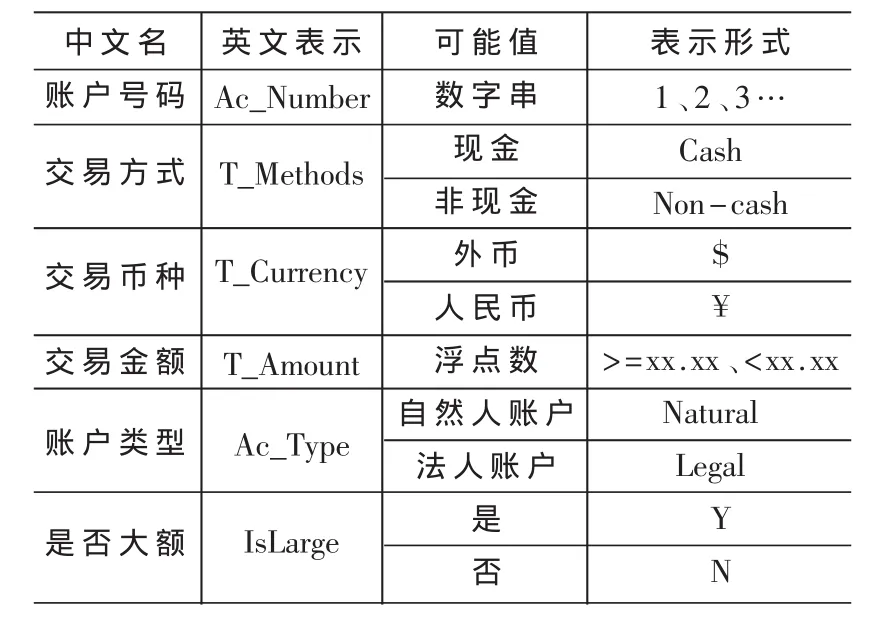
表1 属性及属性值表示形式表
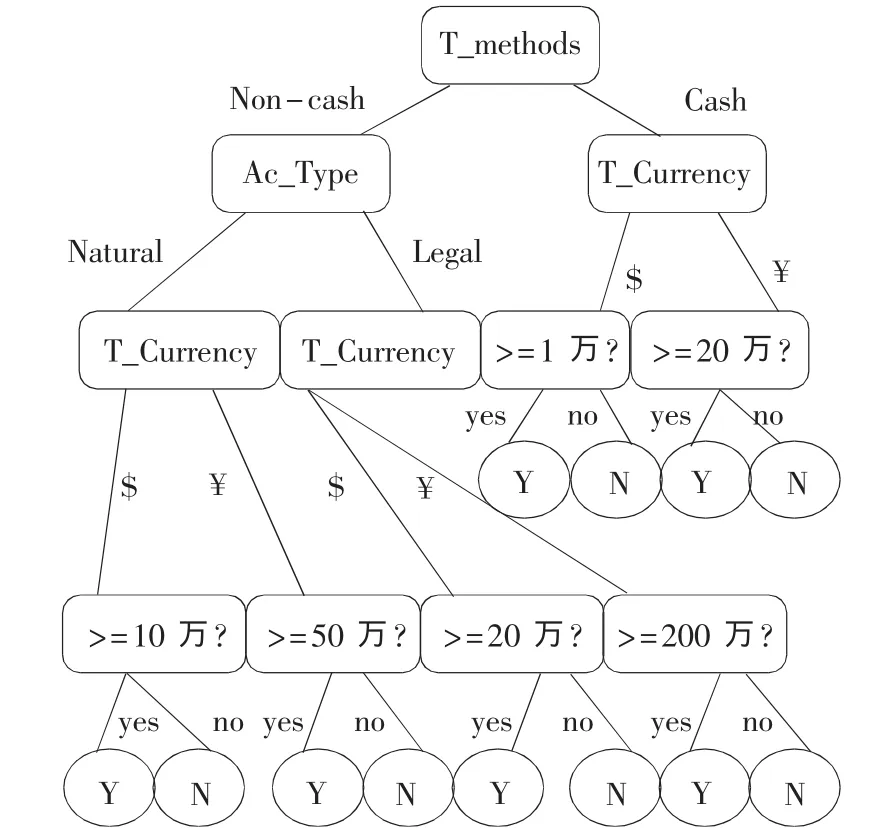
图3 单笔大额交易决策树
(2)构造分类器。分类器是分离数据类的映射或函数,通常该映射用分类规则、决策树或数学公式的形式提供。单笔大额交易特征可表示成一些规则,这些规则相当于一个分类器。与大额交易相关的属性之间有一种相互依赖关系,比如不同的交易方式形成大额交易的交易金额阈值不一样,用不同币种核算的交易其交易金额阈值不同,如果是非现金方式的交易还要考虑账户类型,法人账户与自然人账户构成大额交易的交易金额不同。根据这些依赖关系选择分裂属性,制作一棵如图3所示的决策树,决策树的每条分枝是一条规则,每个规则之间蕴含着析取(逻辑OR),也是互斥的和穷举的。用IF_THEN规则表达形式如下:

(3)编码实现。为了提高算法执行的效率,用数据库语言编写分类算法。
算法:SetIsLarge.
输入:Attribute_list,候选相关属性集合
输出:属性IsLarge的值
方法:

对算法SetIsLarge的调用方法如下:
①For从数据表中取得交易数据记录。
② 得到交易记录的相关属性值。
③ 设置交易数据记录islarge的值为算法SetIs-Large的执行结果,其中算法SetIsLarge的输入参数为第②步中取得的值。
(4)分类结果。分类算法准确率是由相关属性分析的准确率与完整性所决定的。如果能完整提取大额交易与可疑交易的所有相关属性,只要对这些属性设置一个阈值就能对交易数据进行准确分类。本反洗钱系统采用以上分类步骤与算法对交易数据的分类准确率达到100%。
本系统提供功能齐全、界面友好的应用管理功能模块,方便用户作业,同时实现自动运作的数据处理功能。系统不仅能满足上报功能,而且能与银行的其他业务系统融合。
后续研究可考虑以下改进思路:(1)采用在线联机分析处理技术提高从不同系统数据库抽取源数据的速度。(2)实现实时监控挖掘技术,首先对实时抽取的数据进行数据清理,确保一致性与信息的准确性。其次,以交易数据的相关属性值作输入参数调用不同的挖掘算法,其中有的算法除了能实现分类功能外还可实现数据特征化处理功能。
[1]HAN Jia Wei,KAMBER M.Data Mining Concepts and Techniques[M].Morgan Kaufmann Publisher, 2000:10-200.
[2]中国人民银行.银行业大额交易和可疑交易报告数据报送接口规范 (2008修订版)[DB/OL].http∶//www.pbc.gov.cn/fanxiqian/.
[3]张焱,欧阳一鸣,王浩,等.数据挖掘在金融领域中的应用研究[J].计算机工程与应用,2004(18):208-211.
[4]陶维,马吉明,张素智.决策树算法分析及应用[J].电脑知识与技术,2009(5):3352-3354.
[5]刘琼瑶.我国金融业反洗钱现状分析及对策研究[J].华南金融电脑,2009(7):96-97.
