数据挖掘在学生就业指导中的应用
2010-03-20童冰
童 冰
数据挖掘在学生就业指导中的应用
童 冰
(漳州职业技术学院 计算机工程系,福建 漳州 363000)
通过数据挖掘技术分析与学生就业相关的因素,能够为学生就业指导工作提供指导依据。本文探讨了数据挖掘技术在学生就业指导中的应用。
数据挖掘;学生就业指导;数据预处理;频繁项挖掘
1 引言
在学生工作管理中,学生就业指导是一个非常重要的方面。如何对学生就业进行有效的指导,是当前高等院校面临的一个重要课题。就业指导人员可以通过本系统对漳州职业技术学院往届毕业生相关数据进行挖掘,获得一些有指导意义的信息,并且根据这些信息有针对性地对学生进行就业指导。举个例子,假如我们从以往的毕业生的相关数据中挖掘出某专业的学生去某地就业机率高而且薪酬不错,我们就可以根据这个信息,有针对性地组织学校的该专业学生去该地找工作,这样就大大减少了就业的盲目性,节约了找工作的成本并提高了就业率。
2 系统需求分析
学生就业是学生工作的重要组成部分,有必要对影响学生就业的相关因素进行量化分析,这为学生工作者在就业指导方面提供数据,也能为学校管理者在招生和专业设置等方面提供决策依据。
基于以上的需求分析,与学生就业相关的数据挖掘如下:a)挖掘学生源地信息与学生就业率的关联关系;b)挖掘学生的性别与就业情况的关联关系;c)挖掘学生成绩与学生就业情况的关联关系;d)挖掘学生考勤与就业情况的关联关系。
3 系统数据库设计
3.1 数据库建模
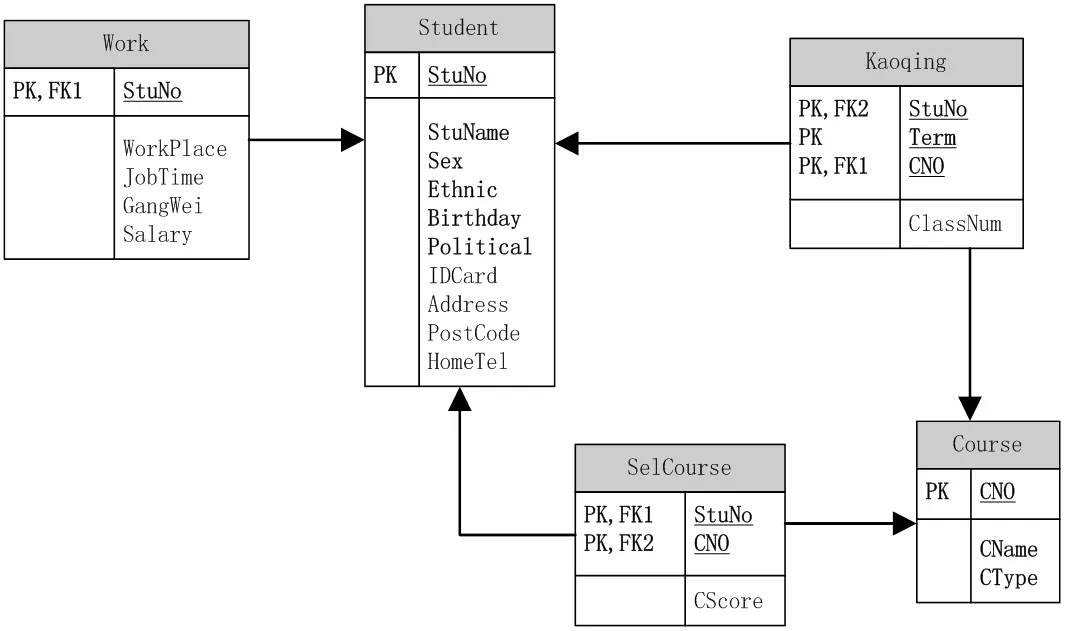
图1 学生就业指导系统数据库建模
3.2 数据库逻辑设计
(1)学生基本情况表
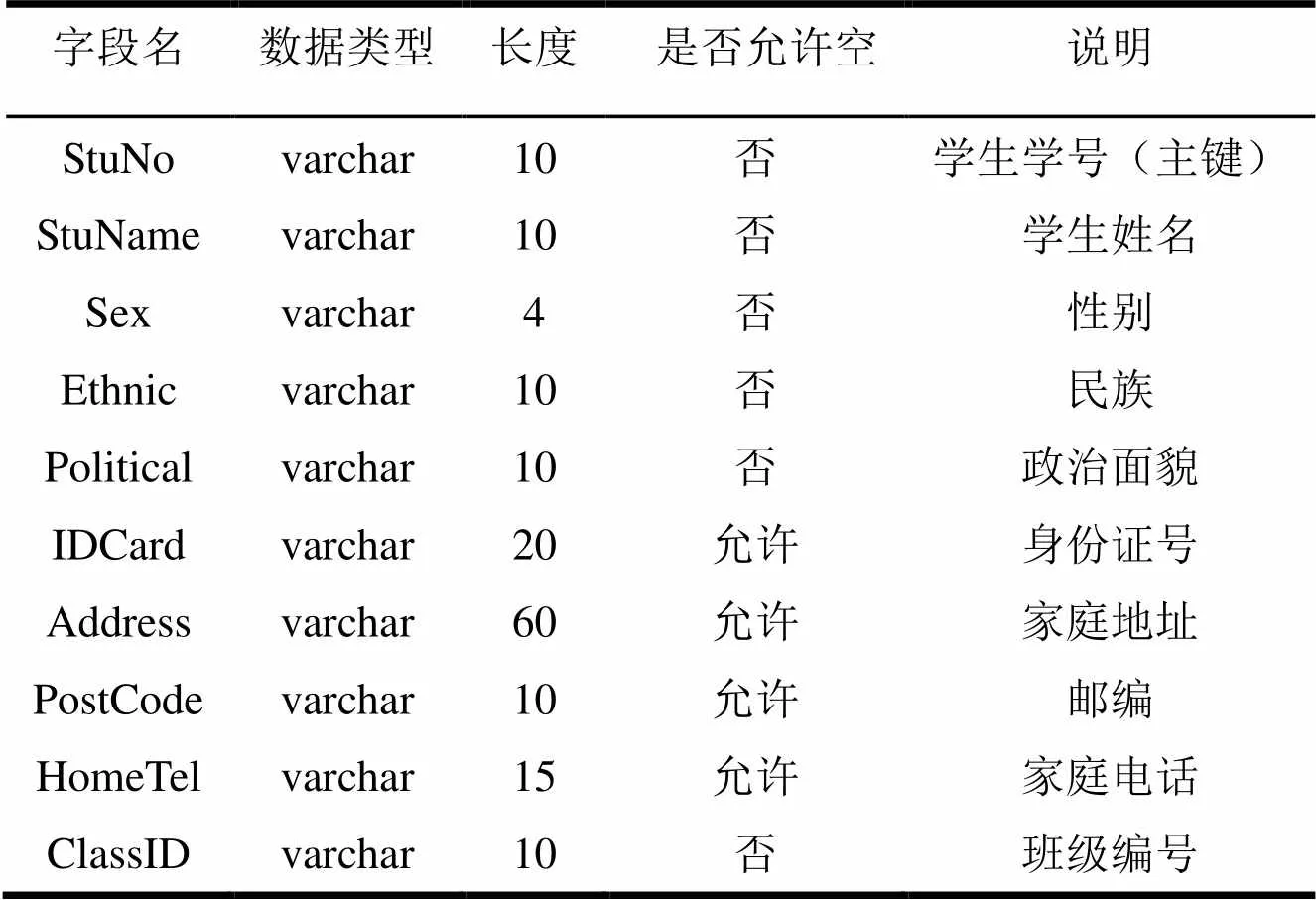
表1 学生基本情况表(Student)
(2)学生课程表
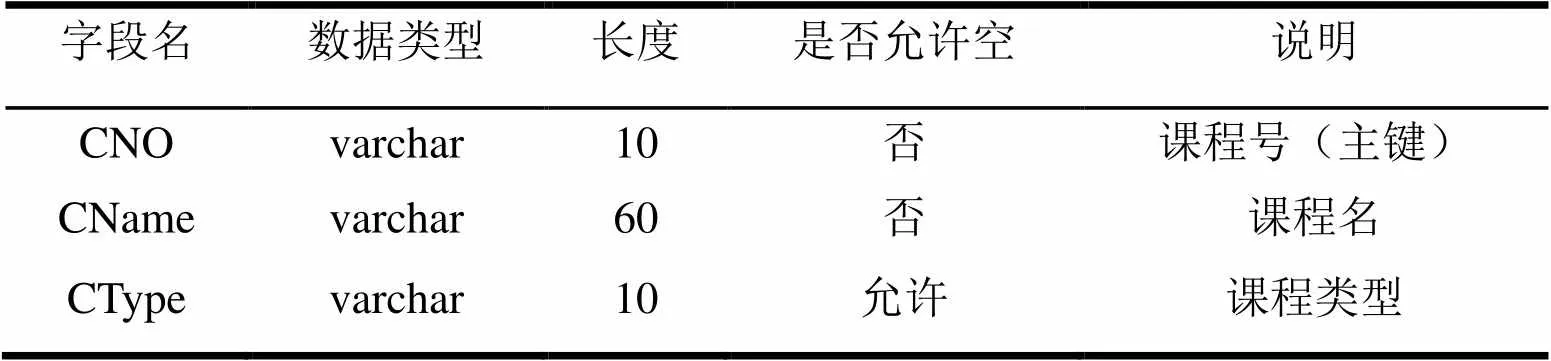
表2 学生课程表(Course)
(3)学生成绩表

表3 学生成绩表(SelCourse)
(4)学生就业情况表
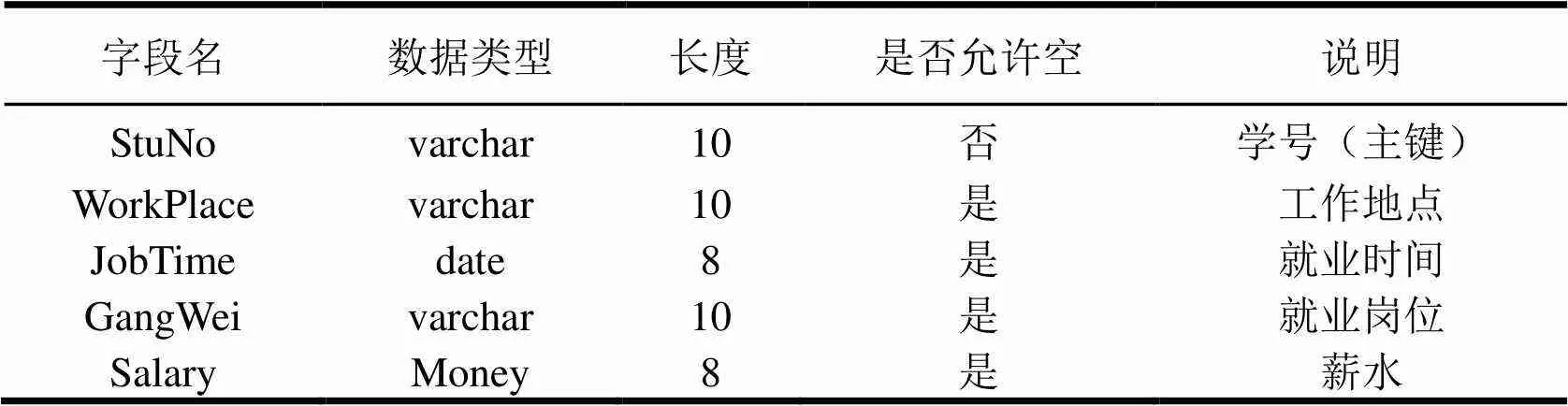
表4 学生就业情况表(Work)
(5)学生考勤表

表5 学生考勤表(Kaoqing)
4 功能设计
本系统的页面表示层功能采用基于.NET技术的ASP. NET来完成,以SQL server 2005作为后台数据库服务器。在系统中设置学生就业统计分析功能:点击“学生就业统计分析”功能按钮,将出现下拉列表,列表内容如下:
a)挖掘学生源地信息与学生就业率的关联关系;b)挖掘学生的性别与就业情况的关联关系;c)挖掘学生成绩与学生就业情况的关联关系;d)挖掘学生考勤与就业情况的关联关系。
当选择上述列表a项时,将出现条件选择界面,在两个下拉列表框中分别选择年级(可选择某届毕业生或所有历届的毕业生)和专业后,点击确定按钮,将列出所有符合条件的学生生源地与学生就业率统计数据的关联关系的列表。
当选择上述列表b项时,将出现条件选择界面,在两个下拉列表框中分别选择年级(可选择某届毕业生或所有历届的毕业生)和专业后,点击确定按钮,将列出所有符合条件的学生性别与学生的就业情况的关联关系的列表。
当选择上述列表c项时,将出现条件选择界面,在两个下拉列表框中分别选择年级(可选择某届毕业生或所有历届的毕业生)和专业后,点击确定按钮,将列出所有符合条件的学生成绩与学生就业情况的关联关系的列表。
当选择上述列表d项时,将出现条件选择界面,在两个下拉列表框中分别选择年级(可选择某届毕业生或所有历届的毕业生)和专业后,点击确定按钮,将列出所有符合条件的学生考勤与就业情况的关联关系的列表。
5 功能实现
根据学生就业管理的需求分析,结合数据挖掘的专业知识,这个模块的共分为数据预处理,频繁项挖掘,关联规则分析三个部分。如图2所示。
5.1 数据预处理[1]
从前面的数据设计来看,该子系统存在5个数据表。由于就业信息跟学生的其他信息是分布在不同的数据表中的,如果不进行处理,就无法对其进行挖掘。如果我们要挖掘学生的生源地跟学生就业信息的关联就必须先使用结构化查询语言把学生的基本情况表跟学生就业情况表先进行连接,生成一个新的数据库表。数据预处理流程如图3所示。
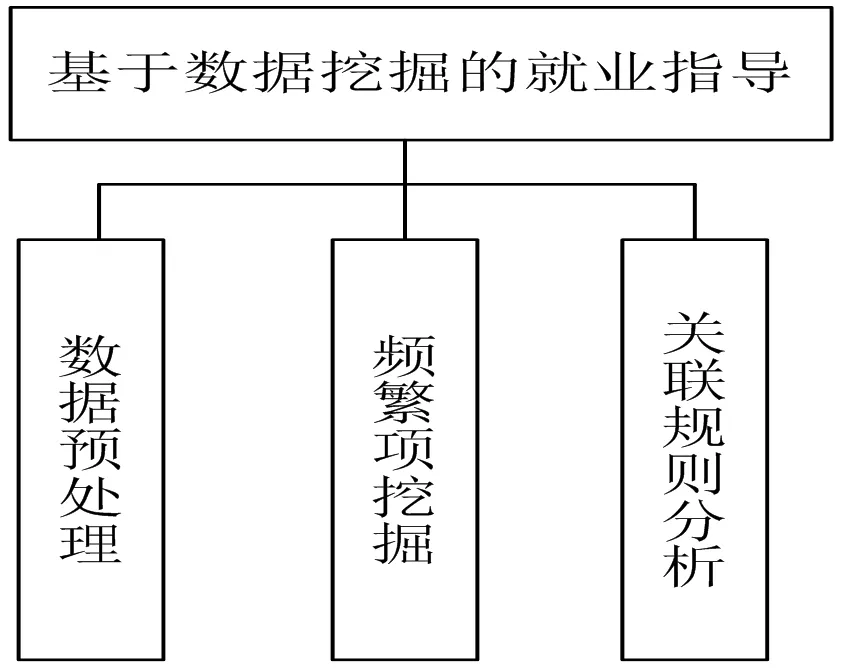
图2 学生就业指导系统模块组成
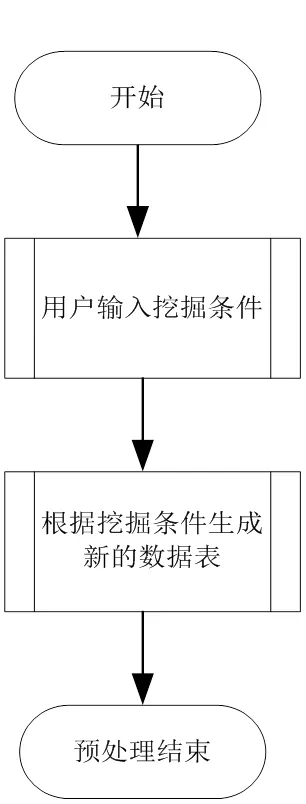
图3 数据预处理流程
5.2 频繁项挖掘[2]
频繁项挖掘的方法有很多,在实现的过程采用了时间和空间效率较高FP-growth算法进行挖掘。它的基本思想是: 首先将数据库中的所有频繁项集压缩到一颗频繁模式树(FP-Tree),但仍保留项集关联信息,然后以长度为1的频繁项为基础,形成条件模式基,挖掘出包含该长度为1的频繁项所有频繁模式项。整个算法的实现过程如下:
(1)扫描整个数据库,统计得到所有长度为1的频繁项的支持数,然后按支持数的降序对长度为1的频繁项进行排序。
(2)将数据表中的每一条记录当作一个数据挖掘的一个事务,将再对每个事务中的每个数据项按第(1)步里的顺序进行排序。
(3)再将上面排序好的事务更新到FP-tree上,FP-tree 结构如下:
a.它由一棵根节点为null 的和一系列代表频繁项的节点构成的树, 以及一个数据项头表组成。
b.树上的节点都包含三个属性: 项名(item_name), 计数器(count), 以及节点链(node_link)。其中, 项名是指该节点所代表的项; 计数器用于记录经过此节点的事务的数目;节点链指向具有相同项名的下一个节点, 如果没有下一个节点就为空。
c. 在数据项头表中的每一个条目由两个域组成, 即项名(item_name)和节点链头, 其中节点链头指向FP-Tree树中具有相同项名的节点链中第一个节点。
(4)根据FP-tree挖掘得到频繁项。整个过程如下: 首先从数据项头表中找出每个长度为1 的频繁模式,在通过FP-tree构造它的条件模式基, ,然后构造它的(条件) FP-tree ,并递归地对该树进行挖掘。
该过程的流程图如图4所示。
5.3 关联规则分析
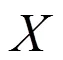
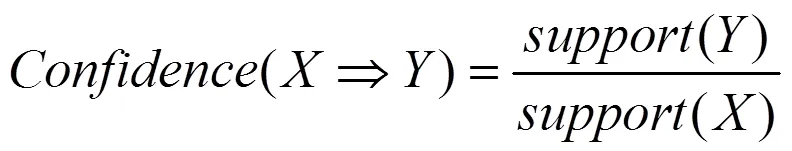

关联规则分析的流程图如图5所示。
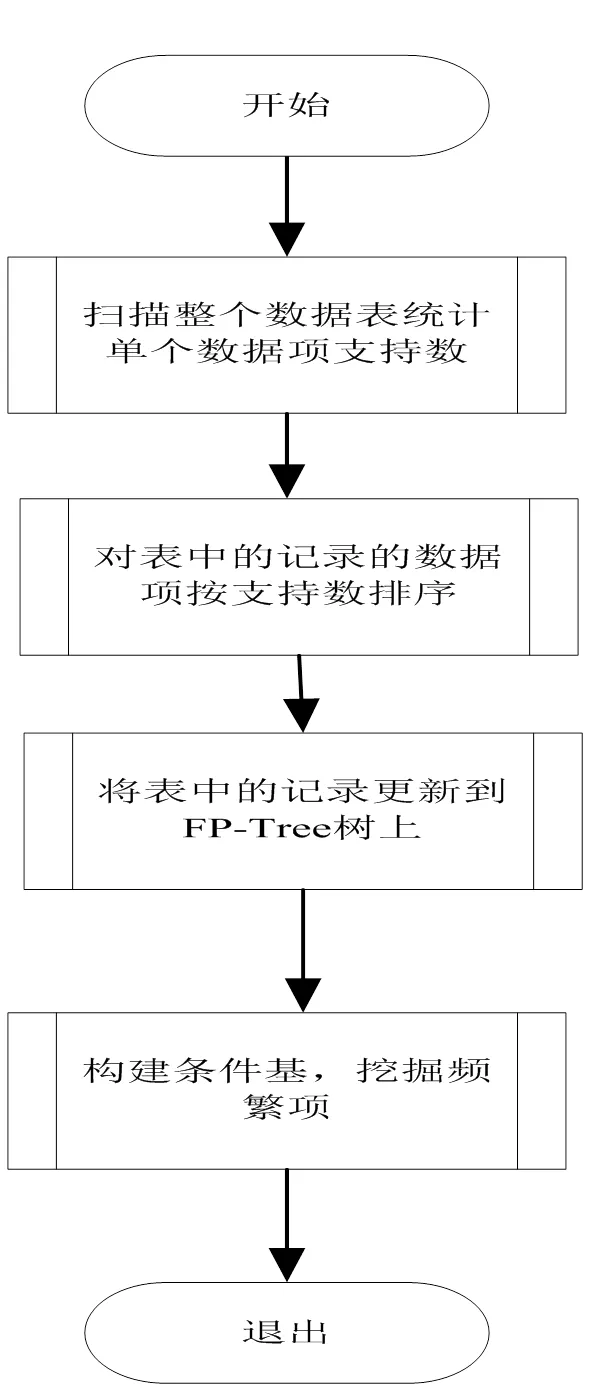
图4 频繁项挖掘处理流程
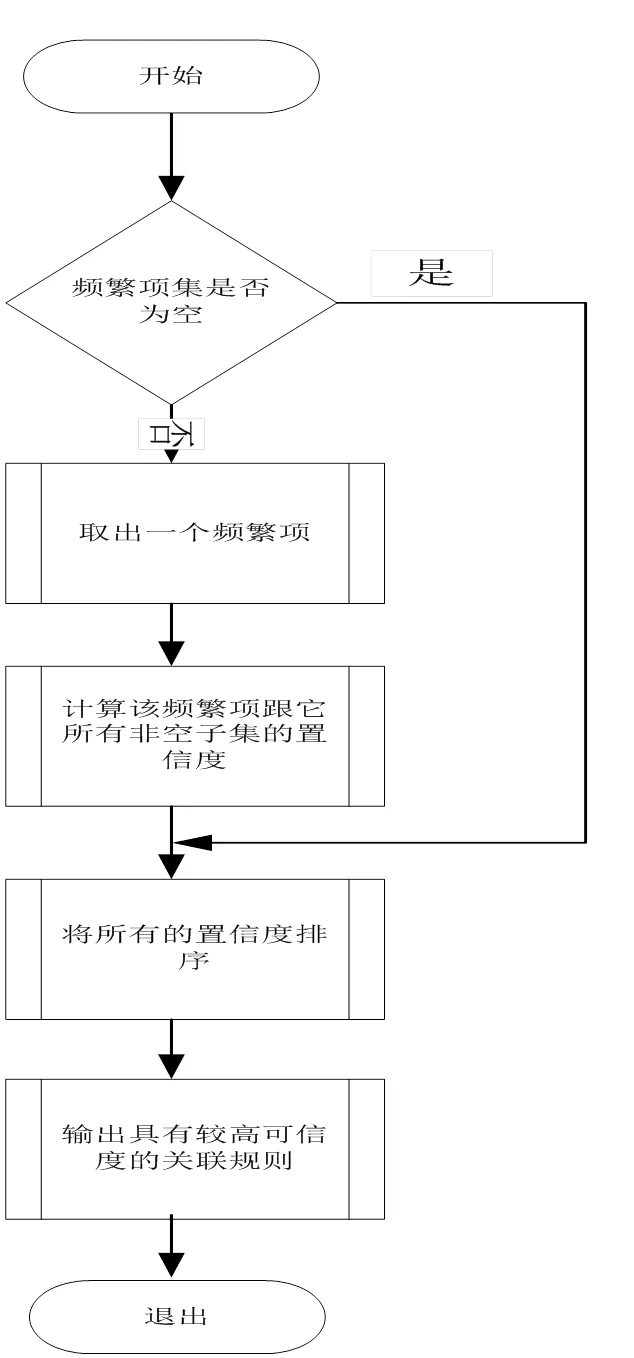
图5 关联规则分析的流程图
5.4 挖掘学生生源地信息与学生就业率关联关系的实现
5.5 挖掘学生性别与学生就业情况关联关系的实现
5.6 挖掘学生成绩与学生就业情况关联关系的实现
6 结束语
本文以开发学生就业指导系统为例,阐述了数据挖掘技术在学生就业指导中的应用。表明将数据挖掘技术应用在高校信息化建设的各个方面具有参考意义与实用价值。
[1]邓纳姆(Dunham,M.H.),郭崇慧,田凤占,靳晓明.数据挖掘教程[M].北京:清华大学出版社,2005.
[2]苏新宁,等.数据仓库和数据挖掘[M].北京:清华大学出版社,2006.
Implementation of Data Mining in Employment Guidance
TONG Bing
(Computer Department of Zhangzhou Institute of Technology, Zhangzhou 363000,China)
The factors related to graduates’ employment analyzed by data mining technique give the basis for graduates’ employment guidance. The article is about how data mining technique work in graduates’ employment guidance.
data mining, employment guidance;data preprocessing;mining of frequent items
2010-07-20
童冰(1979-),女,浙江嵊州人,助教,华中科技大学在职硕士研究生,研究方向:计算机应用技术。
TP274
B
1673-1417(2010)03-0011-06
