基于高性能云的分布式数据并行处理机制
2010-01-15桂兵祥
桂兵祥,何 健
(武汉工业学院计算机与信息工程系,湖北武汉 430023)
基于高性能云的分布式数据并行处理机制
桂兵祥,何 健
(武汉工业学院计算机与信息工程系,湖北武汉 430023)
描述了一个基于高性能云的分布式数据并行处理机制,该机制简化了数据并行处理操作,且能实现数据尽可能在同一个地点处理而无需移动;重点对相关的存储云和计算云基本的框架结构设计思想进行了简要的介绍;实验结果表明,该数据并行处理机制能用于高性能广域网络连接的计算机集群所产生的大型分布式数据集的数据并行处理,实验数据显示,其性能较其它系统 (如 Hadoop)有显著的提高。
高性能云;存储云;计算云;分布式计算;并行处理机制
目前应用于计算机集群、分布式计算机集群和网格的数据并行处理系统都是基于“CPU资源不足而共享”的假设之上。当获得 CPU,数据就移动过来,计算开始,然后返回计算结果。这种方式在实际应用时,大部分时间被消耗在数据传输过程中了。
而基于云计算的分布式高性能数据并行处理机制,它永久性存储数据,尽可能在同一个地点处理数据,数据在本地等待计算任务或查询,大大减少了数据传输时间开销。
目前关于云计算已有了一些应用实例:如Google File Systerm (GFS),Amazon's S3存储云,S impleDB数据云,EC2计算云和开源 Hadoop系统等。MapReduce和 Hadoop及其基本的文件系统GFS和 HDFS是专门为具有数据中心的计算机集群系统而设计的[1],它们使用集群信息将数据文件以数据块的形式存放,是具有中央控制主机节点的耦合度紧密系统,但这种方案对耦合松散的分布式环境使用效果并不好。而存储云正好弥补上述不足,且以文件为单位处理数据,粒度更大。
与传统的数据并行处理机制完全不同,该分布式高性能数据并行处理机制是基于高性能数据云的设计:存储云设计充分利用高性能广域网络,为大型数据集提供永久性存储服务,其通过分布式索引文件对分散的数据文件及其部分实施管理,且通过复制数据以确保数据的长久性,为并行计算机制创造条件;计算云设计用来执行用户所定义的并行计算函数,用数据流的处理形式对存储云所管理的数据进行处理。这就意味着用户所定义的计算函数能应用于任何存储云所管理的数据集内任何数据记录,且数据集的每个部分都能独立操作,从而提供了一个自然的并行机制。这个高性能数据并行处理系统设计实现了数据尽可能在同一个地点被频繁处理而无需移动。下面对相关的存储云和计算云的结构设计思想做简要介绍。
1 存储云结构设计
存储云是为计算云提供持久的数据存储服务、并为计算云的运算管理数据,它本身不是文件系统,但必须依靠本地文件系统来提供服务。为了数据文档的安全,存储云在必要时能随时随地复制数据文件并每天监控其数量,这样就确保了整个文件系统数据的一致性。
存储云结构设计如图1所示。主管服务器(master server)维持系统内的元数据和文件索引、支持文件系统查询、提供目录服务、控制所有从属节点的运行、响应用户的请求等。主服务器还应用 SSL连接与安全服务器通讯,从属节点、客户端和用户提供验证功能;安全服务器 (Security server)维护用户账号、密码和数据文件存取等信息,它也维护已授权的从属节点 IP地址列表,使非法的计算机不能接入系统,防止扰乱系统正常运行。为了提供更好的可靠性,容许使用多个主服务器连接同一个安全服务器;从属节点 (Slaves)是指那些存储数据文件、基于存储云客户端的请求而处理数据的节点,它们通常运行在分布式数据中心的计算机平台上。这些从属节点仅仅接收来自主服务器的指令,所有客户端-从属节点和从属节点自身间的数据传输必须由主节点协调进行。
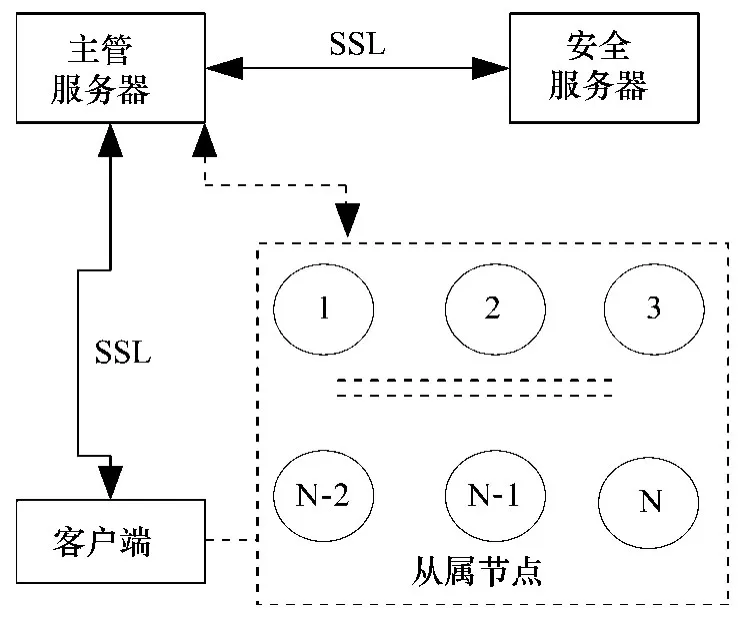
图1 存储云结构设计示意图
此前,有关存储云的研究工作都是基于分布式计算机集群之间的带宽相对较小的假设。而在此描述的存储云是为高性能广域网络 (如 10Gb/s)而设计的,并使用了专用的 UDT协议[2],以便能充分利用广域高性能网络 (10Gb/s),同时也支持不同的路由和网络协议。因其将路由、传输与接口进行分层栈式结构设计,且相互之间有定义良好的 API,这样存储云使用其它的路由或网络协议就相对直接些。
存储云还能高速缓存数据连接,避免了同一对节点间频繁的数据传输需要建立多次连接。其安全机制是通过存取控制列表 (ACL)实现的。当数据读取操作处于开放状态时,数据写入存储云系统操作将由 ACL控制,为了给那些特定的服务器加载数据,客户端的 IP地址必须出现在服务器的 ACL内。
存储云中,数据的组织和处理方式如下:大型数据集按存放记录被组织分为多个文件,为了随机存取数据文件中的某一记录,存储云的每个数据文件附有一个索引文件,二者同时存在于相同的节点;当存储云复制数据文件时,索引文件同时被复制。索引包含数据文件的每个记录的起始地址和末端地址,还有偏移量和尺寸大小等。对于没有索引的数据文件,计算云只能以文件为单位对其进行处理,用户必须编写特定函数以解析文件、提取数据。
该存储云版本支持大型分布式数据集,它们是通过高性能广域网络连接起来的、管理松散的分布式计算机集群系统。此外还使用了 P2P路由协议(the Chord Protocol),以便网络节点能自如地加入系统或从系统撤出。
2 计算云结构设计
此计算云结构基于如下设想:一个计算云数据集是由一个或多个物理文件组成的;用户定义函数在计算云内执行计算;计算云运算器输入一个计算云数据流,计算产生另一个数据流作为输出;计算云数据流能分解为更多的数据片以供计算云服务器处理,这个过程称为计算云处理引擎 (缩写为 CCPE)。计算云数据片可以是一个数据记录及其集合,也可是一个完整的文件。当一个计算云函数处理一个数据流时,所得结果能返回到存储云起始节点,也可写入本地节点或移动到其它节点,取决于如何定义数据流的输出。
计算云结构设计如图2所示。CCPE是计算云最主要的服务,它由一个计算云服务器发起,以响应来自计算云客户端请求。每个 CCPE以用户所定义的函数为基础,此函数称为计算云运算器,作为计算云运算器动态库存储在服务器的本地磁盘上,由存储云服务器对其管理。因考虑安全因素,加载这些库文件到存储云服务器操作受到一定限制。只有当计算云客户端程序写入特定的存储云服务器或服务器拥有者自愿下载文件,库函数文件才能驻留存储云服务器。
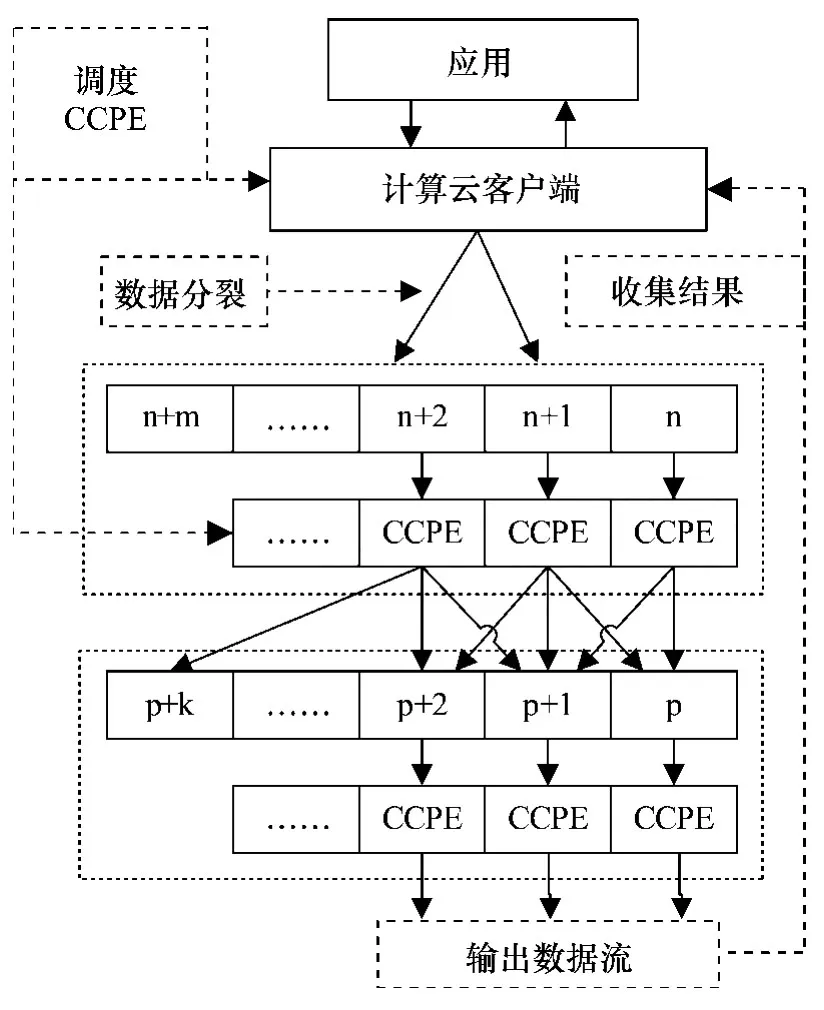
图2 计算云模式结构图
一旦计算云服务器接收到来自客户端的请求,便发起一个 CCPE并与本地计算云运算器绑定,循环执行如下操作。
(1)CCPE接收来自客户端的新数据片,包含文件名、偏移量、所处理的行数和其它参数。
(2)CCPE从本地磁盘或远程磁盘读取这些存储云管理的数据片及其记录索引。
(3)计算云运算器处理这些数据片并将结果写入临时缓冲区,周期性地就处理进展情况给客户端发送确认信息。
(4)当数据片处理完毕,CCPE给客户端发送确认信息并将结果作为输出流写入适当的目的端。如果不再有数据片要处理,客户端将关闭并释放与CCPE的连接。
计算云为数据流分配 CCPE之前,首先必须将数据流分成大小适合 CCPE处理的数据片,然后才能将这些数据片尽可能地分配给同一台机器上的CCPE。注意,除非 CCPE出于空闲状态,否则来自相同文件的数据片不能同时处理。
计算云设计与存储云一起使用,使用数据流编程模型,使某些专用的但频繁发生的分布式计算操作执行起来十分简单。假设计算云所处理的大数据集被分解为多个文件。并行机制以如下两种方法执行:①单个文件能并行处理;②存储云复制文件且能并行处理。计算云的重要好处是数据无需频繁移动,能在同一地方得以处理。
3 实验结果及分析
在计算机集群和网格环境下,数据并行算法编程的最通用方法是使用消息传递机制,或使用 Grid Libraries和 Services,比如用 Globus-Url-Copy来分发、收集数据和编程,Globus-Job-Run运行程序。在GFS和 HDFS存储云上执行计算的最通用的方法是使用MapReduce,其首先使用通用的映射操作在多节点并行地提取相关数据,然后传递这些数据到其它指定节点,最后使用还原操作在多节点处理这些数据,产生结果数据集。而本文所描述的计算云容许用户任意定义操作取代映射和还原操作,且和存储云一样也使用专用的 UDT协议,因此计算云的用户定义函数所指定的任何数据都能在高性能广域网络上有效传输。
该计算云测试环境使用了 TeraSort benchmark[3],并和 Hadoop[4]进行了性能比较。TeraSort是一个好的用以测试计算云的标准,因为其兼有高强度密集的数据和计算。实验所用的测试平台包含 4个测试台,32个节点,外加 1个 NFS服务器、1个头节点和 30个计算从属节点。头节点配置一个Dell 1950,两个 dual-core Xeon 3.0 GHz,16 Gb RAM。计算节点配置一个 Dell 1435s,single dual core 2.0 GHz,4 Gb RAM,1Tb single disk。4个测试台分布式放置,每个节点由 10 Gb/s网络相连接。
实验针对 4个分布式数据中心的测试台上的300 Gb,600 Gb,900 Gb和 1.2 Tb的数据就 30,60,90,和 120个节点做了排序比较测试,测试结果表明:该计算云性能比 Hadoop快 2倍左右。而且,测试台越多,性能越好。进一步分析表明,如此优越的性能获益于多重因素,例如最优化的数据流管理、高效的数据传输协议 (UDT)等。
关于处理时间的影响,我们使用了 10μs、100 μs和 1 ms等不同时间区间,测试使用了 1到 10个CCPE。实验结果表明:当时间区间是 1 ms时,性能随 CCPE个数稳定增加。这符合预期,因为数据 I/O额外开销最小且计算被分布到多个 CCPE,由CCPE引起的额外开销也可以忽略不计。而随着时间区间的降低,随 CCPE数量的增加,计算云的额外开销变得越来越大,性能并不是呈线性增加,而是当CCPE为 7时,性能最大,而后性能有所降低。
数据片段的数量对该计算云性能也有类似的影响,因为只要总的处理时间比 CCPE额外开销具有更为重要的作用,计算云就将能通过使用更多的CCPE来获得更好的并行处理性能。当数据片段数量相对较小时,不足以供应 CCPE运算,可能促使计算云性能不稳定,因为一个 CCPE处理完一个数据片后,不再有数据需要处理而处于空闲状态。在实际应用中,期望数据片段大大多于 CCPE数量。
最后,讨论该计算云的容错特性。试验中,在数据片段处理完成之前,停止运行某个 CCPE,这就强迫计算云寻找一个新的 CCPE来继续完成那个中断的计算任务。实验结果显示:计算云能很好地处理这类问题,性能没有大的改变。而且数据集规模越大,系统过度越平滑。
4 结束语
给出了一个基于高性能云的分布式数据并行处理机制,其支持更为简单的数据平行处理应用,并对其结构框架设计进行了简要的描述。该机制实现了由高性能网络(10 Gb/s)连接起来的分布式计算机集群和数据中心的数据使用数据流式处理。在某些应用场景,这个云计算数据流处理方式比Map Reduc更简单、直接和高效。实验结果表明:这个计算云性能比 Hadoop高 2倍左右。与传统的并行计算相比,这个计算云是面向分布式数据的,而网格调度系统是面向分布式任务的。
近几年来,计算机集群使用已十分普遍;未来几年,10 Gb/s高性能广域网络将把这些集群连接起来,人们将面临一个全新的时代:那些存储在磁盘上的大型分布式数据集,需要高性能的计算来处理,而不要或尽量少移动数据,以减少大量的数据移动而增加额外开销。而这里给出的这个基于高性能云的分布式数据并行处理机制正好为解决这一难题提供了有效的途径。
[1] Jeffrey Dean,Sanjay Ghemawat.Map Reduce:Simplified data processing on large clusters[C]//Sixth Symposium on Operating System Design and Implementation.Cali:University of California,2004:159-172.
[2] Yunhong Gu,Robert Grossman.UDT:UDP-based data transfer for high-CSPEed wide area network[J].Computer Networks,2007,51(7):777-1799.
[3] Yunhong Gu,Robert Gross man. Sector and Sphere:the Design and Implementation of a High Performance Data Cloud[C]//2008 UK e-Science All Hands Meeting.london:Oxford,2008:259-268.
[4] Dhruba Borthaku.The Hadoop distributed file system:Architecture and design[EB/OL].http://www. lucene. apache. org/Hadoop,2007-12-20.
An distribution data parallelism with high performance cloud
GUI Bing-xiang,HE Jian
(Department of Computer and Information Engineering,Wuhan Polytechnic University,Wuhan 430023,China)
This paper presents an distributed data parallelism with high performance cloud that support simplified data parallel applications,and the design of this cloud causes the data to be processed frequently in one place without moving them.This paper prescribes the structure design of this cloud briefly,including the related storage cloud and compute cloud;The experiment results show that this data parallelism can be used for large distributed data sets over clusters connected with high performance wide area networks.This dada parallelism is about twice as fast as the others(such as Hadoop).
TP 393.02
A
1009-4881(2010)01-0060-04
10.3969/j.issn.1009-4881.2010.01.017
Key wors:high performance cloud;storage cloud;compute cloud;distributed compute;parallelism
2009-05-14.
2009-11-12.
桂兵祥 (1969-),男 ,副教授 ,硕士 ,E-mail:bgxhome@163.com.
