基于K-近邻的局部懒惰式决策树分类模型
2010-01-14卢润彩时志素
卢润彩,庞 超,时志素
(1.石家庄信息工程职业学院,河北石家庄050035;2.石家庄学院,河北石家庄050000)
0 引言
分类是数据挖掘和机器学习的一项重要基本任务。一般地,分类是依据某种分类模型,在具有类标的数据集合上学习出一个分类函数,即通常所说的分类器。该函数能够给由属性值序偶集所描述的待分类实例指派一个最适合的类标,从而可以应用于数据分类和预测[1]。研究者们已经提出了许多分类方法和技术,例如,朴素贝叶斯方法[1]、贝叶斯网络[1]、决策树[2,3]、决策表[3]、神经网络、K-近邻[4]以及支持向量机等。这些方法从学习策略上可以分为基于懒惰式学习策略的分类方法和基于急切式学习策略的分类方法。
其中基于懒惰式学习策略的分类方法在给测试实例分类时才去访问训练实例集合来做出预测,在分类精确度上有明显的优势。本文所提出的Local-LDtree分类模型属于基于懒惰式学习策略的分类方法,在给测试实例分类时,首先根据K-近邻算法[4]的思想选择出与该测试实例最近的部分训练实例,然后利用Lazy DT[5]模型在局部训练实例的集合上来给测试实例分类。Local-LDtree分类模型在大多数数据集合上取得了较高的分类精确度。
1 Local-LDtree的关键问题
Local-LDtree分类模型需要解决2个关键问题:①根据K-近邻算法的思想,选择与测试实例最近的部分训练实例形成局部训练实例集合时,如何进行实例间距离的计算;②在形成局部训练实例集合后,Local-LDtree分类模型采用什么算法在其上对测试实例进行分类。
1.1 实例间距离的计算
K-近邻算法是基于实例的学习方法中的一种。当给特定测试实例分类时,K-近邻算法计算该测试实例到训练实例集合中的每一个实例的距离,选择距离测试实例最近的K个训练实例,然后将这K个训练实例的最普遍的类值作为测试实例的类值。K-近邻算法的分类精确度较高,但是如果能更有效地确定K个训练实例的最普遍的类值,就会得到更高的分类精确度。
利用K-近邻算法的思想建立Local-LDtree分类模型时,首先要解决实例间距离的计算问题。本文采用欧氏距离来定义实例间的距离。假定所有的实例对应于n维欧氏空间 ℛn中的点。任意的实例 x表示为下面的特征向量:
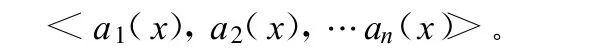
式中,ar(x)为实例x的第r个属性值。那么2个实例xi和xj间的距离定义为:
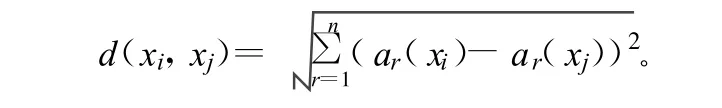
利用欧氏距离来定义实例间的距离比较容易理解,在实验中也取得了较好的效果。
1.2 局部分类算法的选择——Lazy DT
Local-LDtree模型在局部训练实例集合上采用懒惰式决策树算法算法(Lazy DT)。Lazy DT分类算法像许多懒惰式算法一样,推理过程的第一部分(建立分类器阶段)是不存在的,所有的工作都在给一个特定实例分类的过程中完成。
Lazy DT分类算法从概念上为每一个待分类实例建立一棵最优的树。建树过程中选择分裂属性时,采用了信息增益的标准,选择信息增益值最大的属性作为最佳分裂属性。
Lazy DT分类算法为一个给定测试实例分类的过程是:首先,判断训练集合中的所有实例是否具有相同的类值,如是则测试实例的类属性值就是这个相同的类值;如不是,判断训练集合中的所有实例是否具有相同的属性值,如果是,则测试实例的类属性值为训练实例中占最大比率的类属性值;如上述2种情况都没有满足,则选择一个信息增益最大的属性X作为根节点,将所有X属性值与测试实例的X属性值相等的训练实例值划分为一个子集合,将此子集合作为下一次选择分裂属性的训练集合,来建立为测试实例分类的路径。重复以上的过程,直到得到测试实例的类属性值。
Lazy DT实际上只需建立一条针对测试实例的路径和一个使算法变快的缓冲表,在小的数据集合上,分类精确度较高。可以应用于局部训练实例集合来给测试实例确定最合适的类标。
2 Local-LDtree分类模型
Local-LDtree分类模型是采用K-近邻算法和Lazy DT分类算法相结合而建立新的分类模型,是基于懒惰式学习策略的分类方法。它给测试实例分类时,首先根据K-近邻算法的思想选择出与该测试实例最近的部分训练实例,然后利用Lazy DT模型在局部训练实例的集合上来给测试实例分类。Local-LDtree分类模型像许多懒惰式算法一样,建立分类器的阶段几乎不做什么工作,大部分的工作都是在给一个特定的测试实例分类时进行的。其具体算法为:输入:带有类标的训练数据集合 T,一个无类标的待分实例x;输出:实例 x的类标:
①对于 T中每个训练实例t,计算x到t的距离d(x,t);
②在T中选择出与x距离最近的K个训练实例,记为x1,x2,…,xk,将这K个训练实例放入数据集合SUBT中;
③将SUBT和x作为Lazy DT的输入,调用Lazy DT算法,得到 x的类标;
④返回利用Lazy DT得到的x的类标;
在Local-LDtree算法中,将K设置为可以取不同值的参数,例如可以取K=30或K=50等。K取不同的值会引起分类精确度的轻微变动。
算法的关键是:①选择适当的距离计算标准,并针对测试用例计算它到每个训练实例的距离;②在利用懒惰式决策树在局部训练实例上给测试实例x分类时,算法要正确在选择分裂属性和与x对应的训练实例集合。
算法运行的过程中,实例间距离的计算一般不会出现异常情况,但调用Lazy DT算法在局部训练集合上分类时会遇到一些特殊问题,如连续属性的处理、缺损属性的处理等。对于这些特殊问题在算法上进行了如下改进:
①连续型属性的处理:对于连续型属性不是进行预处理,而是采用2路分裂,将其进行离散化;
②缺损属性值的处理:缺损属性值的处理包括2种情况:测试实例具有缺损属性值的处理和训练实例具有缺损属性值的处理。当给定测试实例具有缺损属性值时,对所有训练实例和测试都删除该属性,然后再进行针对给定测试实例进行分类。当训练实例具有缺损属性值时,将训练实例缺损属性值赋值为给定测试实例的该属性值,这样将不会影响分类时其他属性对测试实例预测类标的支持;
③属性最大信息增益为零时的处理:当属性的最大信息增益为零时,选择训练集合中占最大比例的类属性值作为给定测试实例的预测类属性值;
④有未分类实例问题的处理:在Local-LDtree分类模型调用Lazy DT算法时,如果Lazy DT运行中当前层的训练实例数为零,就会出现有未分类实例。此时将上一层的训练集合中占最大比例的类属性值近似地认为是测试实例的预测类属性值即可消除未分类实例,同时还可提高分类器的分类精确度。
3 实验数据及结果分析
本文采用来自UCI的数据集合,分别是音频(Audio)、动物园(Zoo)、SF(Solarflare)、退火(Anneal)、平衡 度 (Balance-Scale)、超 声心电 图(Echocardiogram)、玻璃(Glass)、葡萄酒(Wine)、国际橡棋(Chess)、TTT(Tic-Tac-Toe)、鸢尾花(Iris)、SF-M(Solarflare-M)。表1描述了所使用的实验数据的特征,分别列出了每个数据集合的实例个数、类属性值个数、属性个数以及属性的取值特征(R为属性值取数值型属性值;N为属性值取名称型属性值)。

表1 实验数据描述
在所有的数据集合上评估分类器的性能所采用的方法都是10重交叉验证的方法,运行分类器时采用的都是默认参数。
实验的主要目的是对Local-LDtree、一般决策树和朴素贝叶斯分类器在12个数据集合上比较它们的分类精确度。每个分类器采用10重交叉验证估计分类器的精确度。每一个数据集合被分成10个没有交叉数据的子集,所有子集的大小大致相同。分类器训练和测试总共10次;每一次分类器使用去除一个子集的剩余数据作为训练集,然后在被去除的子集上进行测试。把所有得到的精确度的平均值作为评估精确度,即10重交叉验证精确度。对一般决策树分类器,本文采用经典的C4.5算法,J48是在Weka实验平台下它的具体实现程序。在运行J48和朴素贝叶斯2种分类器时候,均采用其默认参数。
表2列出了朴素贝叶斯、J48和Local-LDtree这3种分类器在12个实验数据上分类精确度的对比。其中,w代表在12个实验数据上Local-LDtree的分类精确度比当前列对应的分类器的分类精确度高的实验数据的数目;t代表Local-LDtree的分类精确度等于当前列对应的分类器的分类精确度的实验数据的数目;l代表Local-LDtree的分类精确度比当前列对应的分类器的分类精确度低的实验数据的数目。

表2 3种分类器的实验结果比较
实验结果可以看出,Local-LDtree在大部分实验数据集上取得了最好的分类性能。在12个实验数据集合上,Local-LDtree的平均分类精确度为88.007 6;朴素贝叶斯的平均分类精确度为81.723 1;J48的平均分类精确度为84.437 8。对音频(Audio)、动物园(Zoo)、SF(Solarflare)、退火(Anneal)、葡萄酒(Wine)、玻璃(Glass)和 TTT(Tic-Tac-Toe)8个数据集合,Local-LDtree的分类精确度均比朴素贝叶斯分类器和J48高。
在本文的实验中判断是否采用Lazy DT方法进一步给测试实例分类时,所取的K值为30,即Local-LDtree的最近邻居的数目取为30。实际上,K取值的变动均会引起Local-LDtree分类器分类精确度上下浮动。
4 结束语
Local-LDtree的实现中,采用的是欧式距离。研究中还有其他实例间距离计算方法,如可以将实例之间取不同属性值的属性的个数作为实例之间的距离等。是否采取其他计算距离的方法会得更好的分类效果,是需下一步研究的问题;Local-LDtree中调用Lazy DT算法时,采用信息增益标准来选择最佳的分裂属性,是否还有其他更好的分裂标准,需进一步进行研究;算法中K取不同的值会引起分类精确度的轻微变动,本文中实验结果数据是K=30时的结果,K选择什么值会使算法得到的分类精确度最优,也需要再加以研究。
[1]SIMOVICID A,SZY MON J.A Metric Approach to Buildingdecision Trees Based on Goodman-Kruskal Association Index[C].Australia :PAKDD,2004:181-190.
[2]ATKESON C G,MOORE A W,SCHAAL S.Locally Weighted Learning for Control[J].Artificial Intelligence Review,1997,11(5):75-113.
[3]AHA D W,LER D K,ALBERT M K.Instance-based Learning Algorithms[J].Machine Learning,1991,6(1):37-66.
[4]CLEARY J G,TRIGG L E.An Instance-based Learner Using an Entropic Distance Measure[C].CA:Proc.12th International Conference on Machine Learning,1995:108-114.
[5]FRIEDMAN J H,KOHAVI R,YEOGIRL Y.Lazy Decision Trees[C].Portland:AAAI-96,1996:717-724.
