流数据管理降载技术研究综述
2009-12-25潘静于宏伟
潘 静 于宏伟
[摘 要] 流数据作为一种新的数据形态快速流行,但由于其连续快速不可预测的特点,当输入速率超过系统处理能力时,系统会产生过载。降载是解决该问题的有效途径。本文讨论了流数据管理降载的关键技术,分析了目前有代表性的流数据系统所采用的降载技术,同时给出了降载技术的研究趋势。
[关键词] 流数据;降载;流数据管理系统
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2009 . 21 . 009
[中图分类号]TP393 [文献标识码]A[文章编号]1673 - 0194(2009)21 - 0033 - 04
1 引 言
流数据在电信数据管理、金融分析、网络入侵检测等多个领域中有着广泛应用,流数据管理也成为近年来数据管理的研究热点之一。
流数据源大量快速实时的特性,使之经常呈现突发性和波动性。当流数据输入率超过流数据管理系统的处理能力时, 流数据管理系统不能处理所有的输入流数据,也不能与流数据到达率保持一致,此时只能卸掉部分负载。降载就是处理掉系统容纳不了的负载。本文分析介绍了主要降载技术,总结了当前主流流数据管理系统的降载方法,讨论了流数据管理降载的进一步研究趋势。
2流数据管理降载主要技术
2.1 流数据管理降载方式
根据目前提出的各种降载技术研究, 主要可以将流数据管理中的降载方式分为两种:随机降载和语义降载,同时也有文献认为还有一类是自适应性降载的。
随机降载通过在网络的某点随机地选择丢弃元组的比例进行丢弃,当用这个方法来使整个系统的效用损失达到最小时,却不能控制由于删除元组而产生的对应用语义的影响。
语义降载运用可控的方法来丢弃元组,它是使用过滤技术丢弃相对不重要的元组,而不是随机地丢弃元组。最常用的有两种策略是葡萄酒策略和牛奶策略。葡萄酒策略认为旧数据比新数据更重要,丢弃数据时首先丢弃新数据;与此相反,牛奶策略则认为新数据比较重要,必要时首先丢弃旧的数据。
2.2 流数据管理降载的核心问题
文献[1]提出了降载需要解决的3个问题:降载的时间、降载的位置以及降载的数据量。
2.2.1降载时间
流数据的速度经常不断变化,数据的处理速度必须要超过数据输入的速度,一旦超载就应尽快检测到,丢弃部分数据,降低系统负载,保证系统正常运行。各种系统检测负载的方法不同,有利用公式的,有利用代价模型的,也有用统计器评估计算的,根据采用的不同方法会确定不同的检测时间。
2.2.2降载的位置
如果判断出系统处于过载状态,要及时插入降载操作进行降载。降载位置的确定至关重要,如果插入到过早的位置,会影响到多个输出(单一查询除外),如果插入到过晚的位置,就会达不到降载的效果。所以合理确定降载操作应该插入的位置,对系统的性能有直接的影响。
通常,如果在查询中没有共享操作,优先的方案是在每个查询的查询路径中第一个操作前面插入降载操作,且降载操作的抽样比与该查询的抽样比相同。如果查询中有共享操作,这时要插入降载操作较为复杂,应通过预先设置的规则来确定降载的位置和数量。
2.2.3 降载数据量
因为是将尚未处理的元组丢弃,会对查询结果的正确性产生不利的影响,所以产生的是近似结果。文献[2]中提出的目标是将所有查询的最大相对误差最小化,同时证明了在最佳解决方案中,所有查询的相对误差是相等的。通过设计的自顶向下的算法和负载方程,可得到相对误差的值,可确定降载的位置和数量。文献[1]保证在插入降载操作符,丢弃掉一部分元组之后,系统的收益应大于其损失,即单位时间内获得的周期数应大于降载操作符本身的代价。可见,降载的数量与系统提出的降载目标关系密切,降载目标通常包括降载后输出速度最大、对结果精确度影响最小等。
3流数据管理系统降载分析
由于流数据系统降载策略与实际应用联系密切,本部分主要分析当前流行的流数据管理系统的降载策略。
3.1 STREAM系统
STREAM[3]是由斯坦福大学设计实现的,是以关系为基础的流数据管理系统,完成内存管理和近似查询。STREAM把降载作为一个优化问题来处理,目标函数是查询结果不准性达到最小,其降载集中在聚集查询上,并提出了相应的降载算法。
STREAM的降载策略最主要研究流数据的滑动窗口聚合操作,并假设所有的查询一样重要,在查询计划中引入随机抽样操作,每个降载器以一个采样概率p将元组传递给下一个操作,为了补偿由于元组删除带来的损失,系统计算出聚集值的适当比例从而产生无偏近似结果。
STREAM的降载处理主要是由系统输入、统计管理器和降载管理器3部分构成,示例结构如图1所示。其中,系统输入包括流数据:S1,…,Sm;流数据上的查询集合Q1,…,Qn;查询操作集合O1,…,Ok。统计管理器对参数值进行估值,对处理元组的个数、操作的输出和总的操作处理时间进行统计报告。降载管理器是在统计的基础上,系统对操作的选择率、操作的处理开销和流数据的速率进行估值。当流的到达速率和数据特征发生变化时,相应的负载要脱落,确定降载的位置。

STREAM降载算法分成两步:
(1)在所有查询之间平均分布误差;
(2)获得适当的输出速率并满足负荷等式,考虑公共查询子表达式共享的情况,确定在数据流图的哪个位置进行降载。
由于STREAM系统作降载决策所用的参数随流数据的波动而变化,需周期性地重新估计这些参数,并改变降载策略,这将会导致系统的开销增大。另外,系统采用了随机丢弃策略,没有考虑流数据项的语义。
3.2 Telegraph CQ系统
Telegraph CQ[4]是美国加州大学伯克利分校构建的流数据管理系统。Telegraph CQ系统中使用的是数据筛余的降载框架,思想是在数据源和查询处理器的中间放置筛余队列。
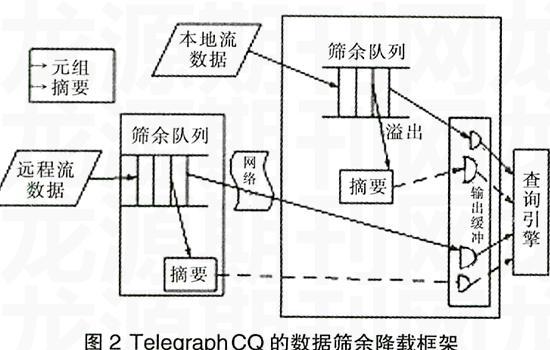
降载要求用低的等待时间来产生准确的查询结果。由于突发期间包含较多的潜在有用信息,所以降载不能简单地丢弃过载的数据,有必要捕捉丢失数据的特性。图2中的筛余队列,把流数据转换成系统的内在格式。如果查询引擎不能处理以一定速率进入筛余队列的元组,系统会建立过量元组的摘要。
正常的操作过程是数据源向各自的队列输入元组,查询处理器按需要从队列的后面获取元组。如果流数据的输入速率超出了查询处理器处理数据的能力,筛余队列填满。当筛余队列超出空间,系统使用一个丢弃策略从队列中去掉不是很重要的数据,而且使用摘要捕捉已删除元组集的相似特性。在连续查询的每个时间窗口,筛余子系统把这些摘要传到查询引擎,并计算查询结果的一个近似答案。最后,准确和近似的结果合起来组成一个窗口的查询结果。
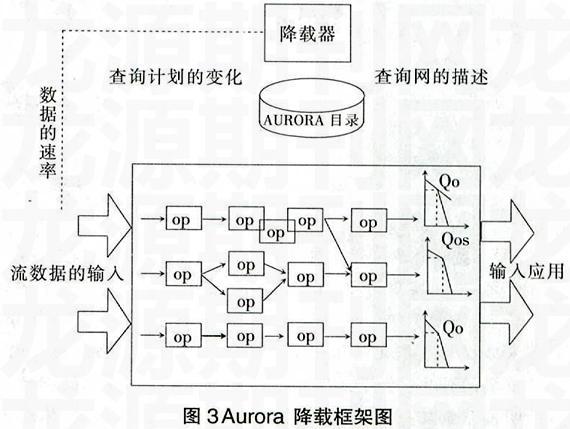
3.3 AURORA系统
AURORA[5]系统是由布朗大学、布兰代斯大学和麻省理工大学联合开发的,核心是一个巨大的触发器网络,目标是专门处理流式监控,是一个面向工作流的系统,连续查询根据由盒子、箭头构成的数据流图来定义,构成查询网络。AURORA中的降载组件在数据输入上接受速率信息,从目录中读取整个查询网络的描述,检测系统的负荷,通过在运行的查询网络中插入负荷减少的降载操作来降低负载。降载器能决定降载操作在什么时间执行,降载框架如图3所示。
AURORA系统实施降载是在查询网络中插入降载操作符,是基于窗口降载的,降载组件连续监测查询网络的CPU负荷。若过载,将窗口删除器插入到查询网络中。该删除器使用查询计划的下游聚合的窗口属性,如窗口尺寸和滑动幅度,逻辑上将流以窗口为单位进行划分,并根据一定概率删除整个窗口。
3.4 分布式流数据管理降载技术
Borealis[6]系统是布朗大学、布兰代斯大学和麻省理工大学研制的分布式流处理引擎,可以跨越不同的处理单元,大至服务器,小到传感器。Borealis的主要目标在于使系统对分布式流数据的处理提高可测量性和实用性,已逐渐代替AURORA系统。
分布式流数据处理系统的负载问题主要是负载的均衡和共享问题,在流数据以一定速率到达而产生负载波动的情形下,即使某一节点的平均负载不是很高,但在峰值期间,一个节点将会遇到暂时的负载峰值,其数据处理的等待时间将受到影响。
Borealis系统把操作负载描述为固定长度的时间序列。两个时间序列的关联是通过关联系数来度量的,关联系数是[-1,l]之间的实数。当两个时间序列有正的相关系数时,如果某个下标的一个时间序列的值相对它的平均值是相对大的,那么另一个有同样下标的时间序列的值也往往是相对大的。相反,当相关系数是负数时,如果一个时间序列的值是相对大的,那么另一个的值往往是相对小的。系统算法通过观察两个操作的负载时间序列的相关系数是否为小的值来激励。当对操作的分配进行决策时,尽量对不同节点间的静态负载相关系数最大化,只要两个节点的负载时间序列有大的相关系数。
4结束语
针对流数据管理系统和实际应用系统的特点,可以看出降载技术进一步的研究趋势有:
(1)研究扩展的语义降载;
(2)研究如何尽可能降低实施降载的额外开销;
(3)构建良好降载策略,以适应多重目标;
(4)研究如何进一步提高降载的自适应性,能处理高度波动流数据,能自适应调整降载策略;
(5)用户可以根据实际应用自定义多重降载目标;
(6)降载策略的适应范围要更加广泛,要能适应多种查询运算。
主要参考文献
[1]Tatbul N,Cetintemel U,Zdonik S, et al. Load Shedding in a Data Stream Manager[C]//Proceedings of the 29th International Conference on Very Large Databases (VLDB'03), 2003.
[2]Babcock B,Datar M,Motwani R.Load Shedding for Aggregation Queries over Data Streams[C]//Proceedings of the 20th International Conference on Data Engineering,2004.
[3]A Arasu,B Babcock,et al.STREAM:The Stanford Stream Data Manager[C]//Proceedings of the 2003 ACM SIGMOD International Conference on Management of Data,2003.
[4]Chandrasekaran S ,Deshpande A, et al. TelegraphCQ: Continuous Dataflow Processing for an Uncertain World[C]//Proceedings of the CIDR Conference,2003.
[5]Carney D,Cetintemel U,Cherniack M,et al. Monitoring Streams A New Class of Data Management Applications[C]//Proceedings of the 28th International Conferenceon Very Large Database(VLDB),2002.
[6]Abadi D, Ahmad Y, Balazinska M, et al. The Design of the Borealis Stream Processing Engine[C]//Proceedings of the CIDR Conference,2005.
Load Shedding Techniques in Data Stream Management
PAN Jing1, YU Hong-wei2
(1.School of Economics and Management,University of Science and Technology Beijing,Beijing 100083,China;
2.Jilin Teachers' Institute of Engineering & Technology,Changchun 130052,China )
Abstract:Data stram is rapid popular as a new data form that is continous,fast and unpredictable.When input rates exceed the system processing capacity,the system will become overloaded.Load shedding is a way to solve this problem.This paper discussed the key load shedding technniques,analyzed the load shedding strategies of exsiting representative system,and introduced the study trends.
Key words:Data stream;Load shedding;Data Stream Management System
