Web使用挖掘在网站优化中的应用研究
2009-12-25武森吴庆海
中国管理信息化 2009年21期
关键词:Apriori算法
武 森 吴庆海



[摘 要]针对互联网用户访问Web服务器产生的日志,结合Web使用挖掘相关理论,采用Apriori算法挖掘用户的频繁访问模式。首先进行数据预处理以保证数据的质量及提高挖掘的效率;然后对预处理后的数据采用Apriori算法进行关联规则挖掘,找出其中的频繁访问模式;最后分析结果,总结规则,提出建议。
[关键词]Web使用挖掘;数据预处理;Apriori算法;网站优化
doi : 10 . 3969 / j . issn . 1673 - 0194 . 2009 . 21 . 001
[中图分类号]F224.6;TP39[文献标识码]A[文章编号]1673 - 0194(2009)21 - 0004 - 03
1引 言
Web使用挖掘是应用数据挖掘技术从Web数据中发现用户访问模式的过程[1],从而可以为用户提供个性化服务,改进系统,优化站点。本文通过对网站服务器日志进行挖掘,找出其中存在的频繁访问模式并提出网站改进意见。
2Web使用挖掘日志预处理方法
2.1数据源
Web使用挖掘主要的数据源有3种:Web服务器日志(Web server log)、代理服务器日志(Proxy log)和用户浏览网页所留下的Cookie文件。在这3种数据中,Web服务器日志是最常用也是最直接的数据源,可以直接在Web服务器上生成;对于代理服务器日志文件来说,由于用户分布很广泛,网站用户可能通过大量的代理访问该网站的网页,所以收集使用代理所留下的日志文件比较困难;而对于单个用户来说,由于涉及隐私问题,所以在用户机上收集信息也会存在问题。鉴于以上考虑,一般的Web使用挖掘大多采用Web服务器日志,所以Web使用挖掘通常也称为Web日志挖掘。
2.2 Web日志预处理过程
Web日志预处理是在Web日志挖掘前,对Web日志数据进行清理、过滤以及重新组合的过程,其目的是剔除日志中对挖掘过程无用的属性及数据,并将Web日志数据转换为挖掘算法可识别的形式。通常,Web日志数据的预处理过程主要包括:数据清理、用户识别、会话识别、路径补充、事务识别5个过程[2]。预处理过程的输入数据有服务器日志、站点拓扑结构和其他可选择信息,输出数据有用户会话文件和事务数据库。
数据清理指删除Web服务器日志中与挖掘算法无关的数据,合并某些记录。Web日志记录中大部分是网页自动产生的图片记录,用户访问网页的主要目的在于网页内容而非图片(专门提供图片的网站除外),所以需要剔除这些记录。此外,用户请求失败的记录和访问网站时自动生成的Java脚本记录也不是挖掘所需,需要剔除。所以,在数据清理中需要剔除图片记录、脚本记录和请求失败的记录以及其他需要剔除的记录。
用户识别就是区分不同的用户。由于防火墙和代理服务器的存在以及不同用户使用相同设备上网等原因,可能造成用户的不一致,一般采用基于启发式的规则[3]来识别用户:
(1)不同的IP地址代表不同的用户;
(2)当IP地址相同的时候,以不同的浏览器或者操作系统来区分不同的用户;
(3)在IP地址相同、用户使用的操作系统和浏览器也相同的情况下,判断每一个请求访问的页面与访问过的页面之间是否有链接,如果一个请求访问的页面与上一个已经访问过的所有页面之间并没有直接链接,则假设在访问Web站点的机器上同时存在着多个用户。
会话识别的目的在于区分同一用户在不同的时间所进行的不同会话,用户会话S是一个二元组
PS包含用户请求页面的标识符Pid和请求时间,则用户会话S可以表示为公式(2.1)所示的元组:
S=
time k-time 1≤T (2.2)
否则认为该用户进行了不少于一次的会话。一般的应用中将时间阈值设定为30分钟,但是L .Catledge和J.Pikow[4]由经验数据得出时间阈值设为25.5分钟更好。本文中采用30分钟作为时间阈值。
由于本地缓存和代理服务器缓存的存在,使得服务器日志会遗漏一些重要的页面请求。路径补充的任务就是将这些遗漏的请求补充到用户会话当中。如果两个页面之间没有直接的超链接关系,则很可能用户采用了浏览器的“后退”功能,而由于本地缓存的存在,日志中没有记录相关的信息,这时就需要进行路径补充。路径补充需要将日志记录与网页的拓扑结构相结合进行。
用户会话是Web使用挖掘中唯一具备自然事务特征的元素,但是,要想更好地进行有效的挖掘,就必须将其分割为更小的事务,这里只是借用了事务的“说法”,也称作片段识别(Episode Identification)。常用的事务分割方法是最大向前引用路径(Maximal Forward Reference Path)方法[5],该算法的主要思想是把一个最大向前引用路径看成一个片段:如果用户在浏览过程中再次浏览已经浏览过的页面(即使用“后退”功能),则认为向前引用终止,得到一个最大向前引用路径;如果用户浏览完成也得到一个最大向前引用路径。
2.3数据采集及预处理
本文采用的数据是原版英语小说网[6]在2009年5月7日00:00~23:59的服务器日志,日志以文本形式保存在TXT文件中,共247M,总记录条目约100万条。
为方便,将Web日志导入MySql数据库中,采用前文所述的方法进行数据处理。首先将日志中不符合要求的记录清除,清除的日志条目主要是以下几类:
(1)图片记录,即以jpg、jpeg、gif、JPG、GIF、JPEG、png等后缀名结尾的记录;
(2)网站自动生成的Java脚本文件,即以js、css等后缀名结尾的记录;
(3)请求方法不是GET的记录;
(4)响应值不等于200的不成功的请求记录;
(5)广告条目记录,即URL以/ad开头的记录。
使用Sql语句将数据中不需要的条目清除。在剩余的数据中,有一部分是搜索网站的网络蜘蛛自动抓取时留下的记录,这些记录对于研究用户浏览模式没有直接的联系,可以将其删除,整个数据清理过程结束之后得到430 865条记录。采用前文介绍的用户识别、会话识别方法进行识别,总计得到5 693个独立用户,6 298个独立会话,最后进行事务识别,得到7 254条事务记录。
3挖掘模型的建立
3.1关联规则
关联规则是指大量数据中项集之间有趣的联系,Web日志挖掘的关联规则就是描述一个用户会话中用户的各浏览行为同时出现的规律,其目的在于找出Web日志访问记录中隐含的联系。一般来讲,关联规则的发现要经过以下4个步骤[7];
(1)进行数据清理、集成、转换、聚集等数据准备。在Web使用挖掘中,数据预处理工作完成了第一步——数据准备。
(2)根据实际情况,确定最小支持度和最小可信度。在Web使用挖掘中可以根据网站使用的实际情况,如用户的点击量、点击率等确定。
(3)利用数据挖掘工具提供的算法发现关联规则。
(4)可视化显示、解释、评估关联规则,即Web使用挖掘中的最后一步——模式分析。
在关联规则发现算法中,Apriori算法是一种最具有影响的挖掘布尔关联规则频繁项集的算法,最早由Rakesh Agrawal等人[8]提出。
3.2 Web使用挖掘实验
实验采用的挖掘算法是关联规则中的Apriori算法,使用的挖掘工具是马克威分析系统[9],输入的数据是通过前文数据预处理之后的事务记录数据。首先,将处理好的事务元组存入数据表中,为了挖掘方便,统一将浏览路径补全,缺少项使用X代替,得到事务文件。
数据输入后采用关联规则挖掘功能,选择使用Apriori算法,建立挖掘模型,设置支持度、可信度等参数。考虑到浏览该网站固定用户较少,且浏览内容分布广泛,用户浏览的所有网页之间存在的关联性较小,因此在设置参数时将最小支持度和最小置信度分别设为10%和15%。在实际应用中应该考虑具体的情况调整参数的设置,进行总体挖掘。
在总体挖掘结束之后,为了进一步了解网站各版块的具体情况,基于网站的主要内容并结合网站管理员的意见,根据网站主要版块的浏览情况进行再次挖掘。网站主要包括Article(文摘)、fiction(小说)和yingyu(英语学习)3个版块。
在针对主要版块进行的再次挖掘中,为了更好地挖掘出关联规则,将挖掘参数中最小支持度调整为5%,置信度不变,仍旧为15%。
4挖掘结果分析
4.1 总体挖掘结果分析
进行总体挖掘得到如表4.1所示的强关联规则。
从表中数据分析得知:
(1)浏览了Article版块的用户中有12.81%的用户浏览了Psycology子版块,置信度为24.75%。
(2)浏览了fiction版块的用户中有23.80%的用户浏览了Fiction子版块,置信度为95.83%。
在Psycology子版块中的主要内容是有关于健康、激励、成功等内容,通过挖掘可以看出,这部分内容比较受到读者的欢迎;而在Fiction子版块主要是在线小说和杂志,包括《哈利·波特》、《时代》等内容,通过挖掘发现在fiction板块中浏览在线小说的用户较多。
4.2 Article版块挖掘结果分析
Article版块的挖掘情况如表4.2所示。
结合网站内容和挖掘结果可知,在Article这一板块中,用户的主要兴趣点在Fashion、Employment、Motivation和Success 4个方面,而编号为61210的内容页面在这一天的点击量最大。
4.3 Article版块挖掘结果分析
fiction版块的挖掘情况如表4.3所示。
总体而言,在fiction版块,用户的兴趣点集中在Fiction版块中的Erotic和romance两个子版块上,编号为799、59037、59039和59064的内容页面点击量最大。
4.4 yingyu版块挖掘结果分析
yingyu版块的挖掘情况如表4.4所示。
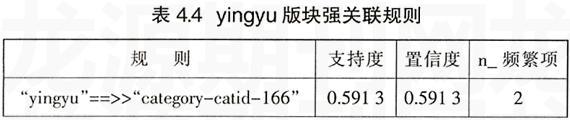
从表4.4中数据可知:浏览了yingyu版块的用户中浏览category-catid-166.html页面的人为59.13%,置信度为59.13%。通过查询网页,页面category-catid-166.html为双语阅读的导航页,由此可以看出,用户主要对这一版块的双语阅读感兴趣。
4.5 主要版块挖掘结果综合分析
综合各版块挖掘结果可以看出,在Article版块,支持度最高的两个浏览模式是
5结 论
本文在研究Web使用挖掘的基础上,采用关联规则挖掘中的Apriori算法对原版英语小说网的服务器日志进行使用挖掘,对网站建设提出了改进建议。另外,通过整个挖掘实验过程,发现Web使用挖掘中的数据预处理是整个挖掘的重点,而数据预处理中的会话识别和事务识别难度较大,是决定整个挖掘成功与否的关键点。
主要参考文献
[1] Srivastava Jaideep, Cooley Robert, Deshpande Mukund, Tan Pang-Ning. Web Usage Mining: Discovery and Applications of Usage Patterns from Web Data[J]. SIGKDD Explorations,2000, 1(2): 12-23.
[2] Robert Cooley, Mobasher Bamshad, Srivastava Jaideep. Data Preparation for Mining World Wide Web Browsing Patterns[J]. Knowledge and Information Systems, 1999, 1(1): 5-32.
[3] Pirolli Peter, Pitkow James, Rao Ramana. Silk from a Sows Ear: Extracting Usable Structures from the Web[C]//Proceedings of 1996 Conference on Human Factors in Computing Systems (CHI-96), Vancouver, British Columbia, Canada, 1996: 118-125.
[4] Catledge Lara, Pitkow James. Characterizing Browsing Behaviors on the World Wide Web[J]. Computer Networks and ISDN Systems, 1995, 27(6): 1065-1073.
[5] Chen Ming-Syan, Park Jong Soo, Yu Philip S. Data Mining for Path Traversal Patterns in a Web Environment[C]//Proceedings of the 16th International Conference on Distributed Computing Systems, 1996: 385-392.
[6] 原版英语小说网.http://www.en8848.com.cn/, 2009.
[7] 武森,高学东,[德]Bastian M.数据仓库与数据挖掘[M].北京:冶金工业出版社,2003.
[8] Agrawal Rakesh, Imielinski Tomasz, Swami Arun. Mining Association Rules between Sets of Items in Large Database[C]// Proceedings of 1993 ACM SIGMOD International Conference on Management of Data,1993: 207-216.
[9] 上海天律信息技术有限公司. 马克威分析系统[CP].http://www.tanly.com/web/index.html.2009.
