面向计算机集群系统的FP-Growth算法的并行计算
2009-09-07陈敏
陈 敏
[摘 要]FP-Growth是频繁模式挖掘的经典算法,能够在不产生候选集的情况下生成所有的频繁模式,效率与Apriori算法相比有巨大提高, 然而FP-Growth算法在挖掘频繁模式过程中需要递归构建大量的条件FP-tree,并分别针对这些条件FP-tree进行挖掘,时间及空间效率不高,在实际应用中存在很大局限性。计算机集群是由多台普通计算机设备通过特定方式结合在一起构成的并行处理系统,属于分布式计算环境,具有计算能力强大、性价比高、灵活等优势。本文提出一种面向计算机集群的并行挖掘算法Gridify FP-Growth, 该算法以FP-Growth为基础,通过任务划分的形式,将计算任务分配到计算机集群中各个计算节点上执行,充分利用各个节点的计算资源,最后汇总各节点的计算结果。实验证明Gridify FP-Growth算法不会牺牲计算的准确性,并可以大幅度缩短计算时间,有效缓解计算大规模数据库时的内存压力。
[关键词]频繁模式;FP-Growth;并行计算;计算机集群
doi:10.3969/j.issn.1673-0194.2009.15.011
[中图分类号]TP301.6[文献标识码]A[文章编号]1673-0194(2009)15-0036-03
频繁模式挖掘是关联规则[1]、相关分析[2]、序列模式[3]等数据挖掘工作的重要基础。根据在挖掘过程中是否产生候选集,频繁模式挖掘算法分成两大类,前者以Apriori算法[1]为代表,需要多次扫描数据库并产生大量候选集,效率低下;后者以FP-Growth算法[4]为代表,只需两次扫描数据库,能够在不产生候选集的情况下产生所有的频繁项集,效率比Apriori算法相比有巨大提高[4]。然而在挖掘频繁模式时, FP-Growth算法需要递归生成大量条件FP-tree, 存储并挖掘这些条件FP-tree,对计算系统的时间和空间都有较高的要求,不仅速度慢而且内存容易溢出。所以在实际应用中,当面临海量数据库时,FP-Growth算法的串行算法已经难以满足计算需求,面向计算机集群系统的并行计算是解决计算速度及存储压力的有效途径。
计算机集群是使用特定的连接方式,将多台普通的计算机设备结合起来,提供与超级计算机性能相当的并行处理系统。相对于共享内存的并行计算系统来说,其对并行算法的要求更高,尤其面对FP-tree这样复杂的数据结构时,各计算节点之间很难协调统一地执行计算任务。文献[5]采用基于数据划分的形式,分割数据库并将其分配到集群中的各个计算节点分别执行FP-Growth算法,最后汇总各计算节点的结果,开创了面向计算机集群FP-Growth并行计算的先河。但这种方法存在一个难以克服的缺点:数据库内的数据必然存在千丝万缕的联系,强行划分数据库可能会牺牲结果的准确性。
本文提出了一种基于任务划分的,面向计算机集群的新的频繁模式挖掘算法——Gridify FP-Growth, 将建立FP-tree后彼此独立的频繁模式挖掘任务划分到集群中所有的计算节点上共同执行,不但能够提高计算效率,而且当数据库规模不断增加时该算法具有良好的延展性。
1 相关概念介绍
1.1 频繁模式挖掘
设I = {i1, i2,…, in}是n个不同项目的集合。设D为事务集,其中的每个事务为TI的项集,每个事务有唯一标识,称作TID。对于项目集XI,若XT,则认为事务T 支持X。 X在D中的支持数是指D中支持X的事务数。X在D中的支持度是指D中包含X的事务的百分比。如果X的支持度不小于用户给定最小支持度阈值Min_Support, 则称X为D中的频繁项集,项集中项目的个数称为频繁项集的维数或长度。仅含有一项的频繁集称作频繁一项集。频繁模式挖掘的任务就是找出给定数据集D中支持度超过给定最小支持度阈值的所有频繁项集。
1.2 FP-Growth算法
FP-Growth算法属于深度优先搜索,将挖掘长频繁模式的问题转换成递归地发现一些短模式,然后连接后缀形成。仅需要两次扫描数据库,第一次扫描产生频繁一项集;第二次扫描建立全局FP-tree。从挖掘步骤来看,可以分成两步:
第一步,建立FP-tree:把数据库中的频繁集压缩进一棵频繁模式树 (FP-tree),同时保留其中的关联信息。
第二步,对FP-tree进行频繁模式挖掘:由于FP-tree蕴含了所有频繁项集,所以频繁模式挖掘的工作仅在FP-tree上进行。根据频繁一项集将FP-tree分化成一些条件模式库,针对这些条件模式库分别建立条件FP-tree,递归地进行挖掘。
建立FP-tree 及对FP-tree 进行挖掘的具体实现过程在文献[4]中有详细介绍,在此不赘述。值得注意的是,在第二步中,根据每个条件FP-tree递归地挖掘的过程,是彼此独立的[5]。根据这一特点,可以将这些独立的挖掘过程分配到计算机集群中不同的计算节点分布执行。这是本文中将提到的并行算法的理论基础。
2 计算机集群系统
计算机集群(PC Cluster)是指一组相互独立的计算机,利用高速通信网络组成的计算机系统,每个节点(即集群中的每台计算机)都是运行其自己进程的一个独立服务器,这些进程可以彼此通信,同时集群中的各个节点是平等的。从某种意义上说,计算机集群形成了一个单一系统,可被看作是一台计算机,协同起来向用户提供应用程序、系统资源和数据,并以单一系统的模式加以管理。
计算机集群不仅能够提供强大处理能力,且性价比远远优于超级计算机,最重要的是其具有很强的可伸缩性:在系统的处理能力需要增加的时候,可通过简单地增加集群中的节点数,即通过向集群添加新的计算机节点,完成系统计算能力的扩容,这在对大规模数据库进行频繁模式挖掘时,具有重要的应用价值。
3 面向计算机集群的FP-Growth算法的并行计算
本文以FP-Growth算法为基础,提出了适用于计算机集群系统的并行算法,由于计算机集群系统中的各节点形象地构成了一个计算网格,本文把算法命名为Gridify FP-Growth,简称GFP-Gowth算法。
3.1 GFP-Growth算法主要思想
GFP-Growth算法继承了FP-Growth算法的第一步,即生成全局FP-tree的过程;并行计算集中在频繁模式挖掘这一阶段。
为了保证第一次建立的全局FP-tree的完整性与准确性,建立全局FP-tree的过程在单机上执行,另外实验证明,当数据库规模在10k以上时,建立全局FP-tree消耗的时间与后续频繁模式挖掘时间相比,一般相差3个数量级以上,对整个计算时间的影响很小,所以建立全局FP-tree的过程不采用并行计算。
在频繁模式挖掘阶段,当数据库规模较大的时候,FP-Growth算法会递归生成海量条件模式库,并需要根据这些条件模式库生成一一对应的条件FP-tree。然而,正如我们在介绍FP-Growth算法的时候提到的,根据每个条件模式库生成条件FP-tree,进行频繁模式挖掘的过程,彼此间是完全独立的。这一互相独立的特点,能够将串行算法的劣势转换为并行算法的优势:将根据每一个条件模式库挖掘频繁模式的过程分配到集群中的计算节点上分别执行,不仅会提高计算效率,而且不会牺牲算法的精度,这是GFP-Growth算法的主要思想。
3.2 GFP-Growth算法主要步骤
计算机集群中的各节点之间是平等的,可以随机指定一台计算机为中央节点。首先在中央节点上,根据数据库生成全局FP-tree,这一单机实现的过程与FP-Growth算法相同;生成FP-tree之后,中央节点根据频繁一项集将全局FP-tree分化成一些条件模式库,并行计算开始,主要步骤如下:
第一步,对任务进行划分。
中央节点根据众多条件模式库将统一计算任务Task划分为多个子任务Jobs,每一个条件模式库对应一个子任务,即根据每一个条件模式库进行频繁模式挖掘的工作就是一个Job。
第二步,对任务进行分配。
由中央节点将Jobs分配到集群中的各个计算节点(包括它自身在内),每个节点需要负责一至几个Jobs;在计算过程中根据各节点的计算能力进行负载动态调整。
第三步,分别执行任务,集群中的每个计算节点分别执行分配给自己的子任务Jobs。
对Jobs对应的各条件模式库建立相应的条件FP-tree,递归地对每个条件FP-tree进行频繁模式挖掘。
第四步,对结果进行汇总。
计算节点完成Jobs之后,需将计算结果传递给中央节点。
这里采用异构的通讯方式,即各个节点不是同时开始通讯的,而是每当有节点完成计算任务,立刻会向中央节点提交运算结果。由中央节点将全部的计算结果汇总,并输出统一计算结果。
4 算法实现与比较
为了验证集群计算的灵活性与便利性,实验所用设备为3台普通PC机,且配置不同,CPU和内存分别为1.73 GHz(双核), 2.87 GB ;1.60 GHz(双核),1.87 GB;2.39 GHz(双核), 2.99 GB。采用一般的无线网络来连接计算节点,带宽54 Mbps;编程工具和运行环境为JDK 1.6。选择配置中等的计算机1.73 GHz(双核), 2.87 GB为中央节点。两台计算机的实验,所采用的计算机为1.73 GHz(双核), 2.87 GB ;1.60 GHz(双核),1.87 GB。
4.1 算法有效性实验
数据集采用http://archive.ics.uci.edu/ml/datasets.html上提供的Mushroom相对密集型的蘑菇数据库来进行实验。该数据库有8 124条记录,记录了蘑菇的23种属性,虽然是一个很小的数据库,却非常稠密,项集之间的相关性很强,即使在最小支持度阈值较大时,也存在大量频繁模式,并且随着支持度的减小存在严重的组合爆炸问题[6] 。
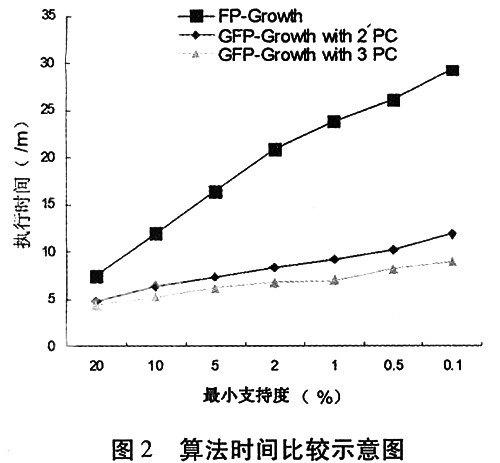
实验设定频繁项集长度为15,从图2看出随着最小支持度的增大,GFP-Growth算法的速度较FP-Growth算法有显著提高,在支持度小于2%的情况下,在3台计算机上实现的GFP-Growth算法执行时间少于FP-Growth算法的1/3。
4.2 算法伸缩性实验
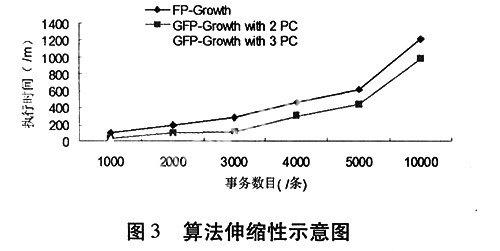
分别采用1 000条、2 000条、3 000、4 000、5 000、10 000条事务数据集来实验,项目数为200,平均事务长度为50,最小支持度为4%,频繁项集长度为4。实验结果如图3所示,在数据量相等的情况下, GFP-Growth算法无论在2台或3台计算机上的执行时间始终少于FP-Growth算法,且在3台计算机上实现的GFP-Growth算法执行时间少于2台计算机上实现的GFP-Growth算法,差距随数据量增大而增大,说明集群系统具有良好的伸缩性。
5 结 论
本文提出了一种基于FP-Growth的频繁模式挖掘并行算法——GFP-Growth,能够在计算机集群系统中实现并行计算。从算法的角度来看,GFP-Growth算法能够有效地提高计算速度并具有良好的伸缩性。从计算环境来看,计算机集群系统价格低廉,却具有大型服务器的计算功能,并具有很强的延展性。实验证明,数据库规模越大,利用计算机集群进行并行计算的优势越明显。
主要参考文献
[1] R Agrawal and R Srikant. Fast Algorithms for Mining Association Rules[C]//In Proceedings of the 20th International Conference on VLDB, 1994: 487-499.
[2] S Brin, R Motwani, C Silverstein. Beyond Market Basket: Gener-alizing Association Rules to Correlations[C]// Proc of 1997 ACM-SIGMOD Intl Conf on Management of Data, Tucson, AZ: ACM Press, 1997: 265-276.
[3] R Agrawal, R Srikant. Mining sequential patterns[C]// ICDE95, Taipei, Taiwan: IEEE Computer Society Press, 1995: 3-14.
[4] J Han, Pei ,Y Yin.Mining Frequent Patterns Without Candidate Generation[C]//Proc ACM-SIGMOD, Dallas, TX, 2000.
[5] Iko Pramudiono and Masaru Kitsuregawa.Parallel FP-Growth on PC Cluster[C]//Proc of the International Conference on Internet Computing, 2003.
[6] Artur Bykowski, Christophe Rigotti. A Condensed Representationto Find Frequent Patterns[C]//Proc of the 20th ACM SIGACT-SIGMOD-SIGART Symp on Principles of Database System ( PODS 2001), Santa Barbara, CA: ACM Press, 2001: 267-273.
Parallel FP-Growth Algorithm on PC Cluster
CHEN Min
(School of Economics and Management,University of Science and Technology Beijing,Beijing 100083,P.R.China)
Abstract: FP-Growth is the most popular algorithm for frequent patterns mining, which can produce all frequent patterns without generating candidate item sets. FP-Growth has better performance than previously reported algorithms such as Apriori. Nevertheless, the great amount of conditional pattern base and conditional FP-tree recursively generated during mining frequent patterns limits practical feasibility of FP-Growth algorithm when facing large scale data warehouse. Further performance improvement can be expected from parallel execution. PC cluster is a group of PC connected together through definite ways. It is a distributed computing environment and has some advantages such as great computing ability, flexibility and so on. We propose a new parallel algorithm named Gridify FP-Growth to implement on PC cluster. Gridify FP-Growth is based on FP-Growth algorithm, by allocating jobs to the nodes within the cluster to take full advantage of computing resource of each node. After that, the sub-result from each node will be combined to a total result. Experimental results show that Gridify FP-Growth can dramatically reduce the execution time as well as relieve the space pressure.
Key words: Frequent Patterns; FP-Growth; Parallel Execution; PC Cluster
