开源工具在机器学习教学中的应用
2009-03-17高明霞方娟毛国君
高明霞 方 娟 毛国君
文章编号:1672-5913(2009)02-0100-03
摘 要:机器学习是一门以算法和学习理论为主的计算机专业基础课程,单纯的算法分析和理论讲解很难引起学生的学习兴趣。为了激发学生的兴趣,循序渐进的完成教学目标,本文探讨了在课堂讲授、课程作业和毕业设计三个基本教学环节中应用开源机器学习工具——WEKA的教学方法。
关键词:机器学习;WEKA;算法
中图分类号:G642
文献标识码:B
1 引言
机器学习课程是很多大学为计算机科学与技术专业的高年级学生和研究生开设的专业基础课程。它主要讲授目前机器学习中各种实用的理论和算法,包括概念学习、决策树、神经网络、贝叶斯学习、基于实例的学习、遗传算法、规则学习、基于解释的学习和增强学习等。机器学习教学的主要目标有两个:一是掌握典型的机器学习算法并利用这些技术解决实际问题;二是根据实际应用改进现有方法,发展新的机器学习技术。目前机器学习的教学内容主要集中在典型算法和学习理论,现有教材中使用的实例和现实应用差距很大,如果教师的课堂教学中过多的采用算法分析和伪码演示,很难激发学生的学习兴趣。实际上,机器学习方法已经有了十分广泛的应用,被成功的运用到了生物特征识别、搜索引擎、医学诊断等各个领域。如果在教学过程中,让同学们看到、感受到、甚至于自己参与到这些机器学习的应用实例中,必定能大大激发学生的学习兴趣。
为此,我们设计了一个包括课堂讲授、课程作业和毕业设计三个教学环节的教学过程,并在每个教学环节中,应用了一个开源的机器学习工具——WEKA。首先,教师利用WEKA的可视化界面在课堂教学上展示了经典算法和实例的运行效果;其次,教师应用WEKA的多种算法实现,在课程作业环节,为学生布置了一些现实应用,并要求他们借助WEKA自己解决;最后,在毕业设计环节,教师针对机器学习技术的最新发展,要求有能力、感兴趣的学生自己实现某个新算法,并借助WEKA的可视化接口,和原有算法进行性能对比分析。借助WEKA,应用这种循序渐进的教学过程,可以引导学生了解机器学习课程的作用,并培养他们利用所学知识解决实际问题的动手能力和发现问题、解决问题、评估问题的研究能力。
下边首先简单介绍一下开源工具——WEKA。接着讲述其在教学演示,课程作业和毕业设计方面的应用。最后是对本文的简要总结。
2 WEKA简介
WEKA[1]的全名是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis),它的源代码可通过http://www.cs.waikato.ac.nz/ml/WEKA得到。由于WEKA的主要开发者来自新西兰,所以使用了一种新西兰的鸟名命名这个工具。2005年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的WEKA小组荣获了数据挖掘和知识探索领域的最高服务奖,WEKA系统得到了广泛的认可,成为现今较完备的数据挖掘工具之一。WEKA 3.5.8能够提供四种操作环境:SimpleCLI、Explorer、Experimenter、knowledgeflow。四种操作环境的基本原理都大同小异,只是提供的界面不一样。SimpleCLI适合于直接使用代码的用户;Knowledgeflow倾向于喜欢图标的实验者;explorer和experimenter通常更适用于功能形控制。WEKA作为一个开源的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法,包括对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化。WEKA提供了通用的接口文档和插件模式的系统结构,供机器学习研究人员方便的实现自己的算法并集成到WEKA环境中进行深入研究。
3 WEKA在教学演示方面的应用
讲解某个机器学习算法时,除了从理论上进行阐述外,使用一个真实问题,借助WEKA为学生演示该算法解决这个真实问题的整个步骤,并根据算法特点和知识点,在演示过程中设置问题和学生交互更能激发学生的兴趣,加深他们对算法的认识。下边是针对教材中通用的天气(weather)数据集(5个属性,14个样例)讲解决策树算法ID3时WEKA—Explorer在教学演示方面的应用。
1) 数据预处理:Explorer的选项卡“Preprocess”提供了对样例数据的多角度观察和大数据集的属性实例过滤操作等数据预处理方法。在这个过程中,以可视的形式给学生展示了数据预处理,数据格式等和算法相关的知识。由于ID3算法只能处理离散值属性,原始实例中的两个属性(temperature和humidity)值范围是实数,为了满足ID3算法,需要对这些属性值进行各种离散化处理。借助这一选项卡对各种离散化方法进行展示,并比较结果和使用范围。
2) 属性选择方法:Explorer的选项卡“Select attributes”提供了多种方法用于选择分类属性,例如信息增益(information gain),信息增益比(gain ratio)等。通过多种属性选择方法对天气数据集中的五个属性进行实时处理和可视化结果对比,为学生展示了属性选择对ID3算法的重要性。
3) 树模型形成:Explorer的选项卡“Classify”提供了各种测试形式用于形成树模型,包括带训练集(use training set)、交叉验证(cross-validation)、比例分割(percentage split)等测试形式。通过自由选择可以实时演示不同测试形式的模型学习结果和详细评估指标,通过对比可以了解不同测试形式的优缺点以及适用范围。特别是带源码的模型结果输出,除了形象的展示了形成的模型树外,还以面向对象编程的思想展示了ID3算法的JAVA语言实现,这些真实程序和伪代码结合讲解,可以培养学生的实际动手能力和算法抽象能力。
4) 结果指标的图形化演示和处理:除了选项卡“Classify”提供的分类器输出(Classifier Output)用于显示结果指标,WEKA对结果的一些特殊指标提供了图形化演示和文件导出的灵活功能,可以通过右键获得。
4 WEKA在课程作业方面的应用
上节借助WEKA演示机器学习算法的过程可以帮助学生掌握典型的机器学习方法,本节结合教学过程中的课程作业布置重点阐述借助WEKA培养学生利用所学机器学习方法解决实际问题的能力。
由于机器学习方法在实际领域中得到了广泛的应用,我们可以将这些领域中的现实问题提出作为课程作业布置给学生,要求他们利用所学的机器学习方法来解决。如果没有WEKA对经典算法的实现,就需要学生自己花费大量时间完成算法实现、输入数据标准化和输出格式图形化这些复杂、繁琐的编程工作。这将大大降低学生学习机器学习方法和利用这些方法解决现实问题的兴趣。WEKA作为一个数据分析平台,提供了大量经典机器学习算法的实现,并提供了方便的数据输入、结果输出和可视化功能,它能简化利用机器学习技术解决现实问题的过程。使得学生集中关注有助于提高他们解决问题能力的如下问题点:现实问题到机器学习实例的形式化,所用机器学习算法的优缺点和数据要求,那些算法适用这一现实领域等。
下边以自然语言处理领域中一个识别自然语言问题所处领域的现实需求为例,说明利用WEKA解决这一现实问题的简化过程。问题领域识别是问题分类[2]的一种,可以看作是典型的文本分类问题,通常需要特征提取,模型训练,和新问题预测三个阶段。课程作业所用样本问题搜集于MadSci Circumnavigator站点1996至2005年间用户提交的真实问题,包括计算机领域的709个问题和医疗领域的2142个问题,纠正了原始问题中包含的语法和拼写错误,分别得到570个计算机类和1928个医疗类问题。
特征提取可以参考文本分类[3]中所用特征向量,将同领域中的所有样本问题包含的核心词作为特征,并以要分类问题中是否出现这些核心词为这些特征定义两个取值{0,1},分别表示不出现和出现。这一阶段主要完成现实问题到机器学习问题的形式化,所用技术和自然语言处理领域密切相关,和WEKA关系不大。
定义了特征后,模型训练和新问题领域预测两个阶段可完全借助WEKA—Explorer实现。模型训练需要选择合适的问题作为正负样例,并根据特征取值和所属领域将他们转换为特征向量,表示成WEKA可识别的数据格式,用WEKA提供的各种分类器训练模型。要完成这一步骤,需要了解WEKA使用的数据格式。WEKA存储数据的格式是一种ASCII文本文件ARFF(Attribute-Relation File Format)。表1中的ARFF文件就是部分计算机领域的WEKA数据样例集。以“%”开始的行是注释行,处理过程中被忽略。除去注释后,整个ARFF文件可以分为头信息和数据信息两个部分。头信息(Head information),包括对关系和属性的声明。数据信息(Data information),即数据集中的实际样例,从“@data”标记开始。将要处理的数据表示成WEKA的存储格式后,就可以利用Explorer 的选项卡“Classify”提供的不同分类器和训练方式来训练模型。该选项卡的作用很清晰,面板上的操作类型也很明确,我们可以按照要求选择并完成模型训练,右边的分类器输出(Classifier Output)对该模型的具体情况做了详细说明。表2是选择WEKA中提供的NaiveBayes、RBFNetwork、VotedPerceptron、SMO四种分类算法和它们的默认参数,对训练样本集进行了4-fold的交叉验证后得到的模型精度结果。

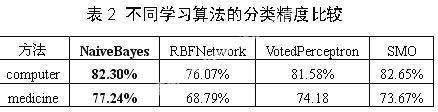
由于目前的应用实例只考虑了两个领域,所以新问题预测只能预测该问题是否属于某个(计算机或医疗)领域。例如要预测问题“should I gargle salty water against mouth infection?”是否属于医疗领域。只需要将新问题根据医疗领域的特征字典和取值表示成特征向量,并将最后一个属性值result置空,使其成为一个要预测问题的ARFF文件(medicine-new.arff)。从表2可知要选择第一个分类器(Naïve Bayes)和医疗训练数据形成的学习模型预测,在这个模型结果列表上重新选择测试形式(Test options)为 “Supplied test set”,并且“Set”成你得到的要预测问题的数据集,这里是“medicine-new.arff”文件。现在,右键点击选择的模型,选择“Re-evaluate model on current test set”进行预测。并通过点击右键菜单中的“Visualize classifier errors”,将弹出的一些有关预测误差的散点图保存成一个Arff文件。打开这个文件可以看到在倒数第二个位置多了一个属性(predictedpep),这个属性上的值就是模型对新问题领域的预测值。
5 WEKA在实践环节的应用
不同的机器学习算法有不同的特点和应用领域,随着大量新问题和新领域的出现,研究人员在不断的开发新的算法和改进已有算法的应用范围。对于那些对机器学习技术有兴趣,想深入学习的学生,为他们提供机器学习领域内合适的毕业设计题目可以锻炼他们的实践能力和科研能力。例如让他们实现一个新的机器学习算法并通过实验分析比较它的性能和优缺点。WEKA提供了插件体系模式和通用接口,供研究人员方便的集成自己的算法到他的环境中。所以,学生可以借助WEKA的这些功能,实现这一算法并集成在WEKA的环境中,利用WEKA平台方便快捷的分析、比较新算法和已有典型算法的各种性能。
6 结论
为了更好的达到机器学习教学的两个目标,激发出学生学习机器学习课程的兴趣,我们在机器学习的教学过程中应用了一个开源工具——WEKA,并借助它的可视化环境、典型算法实现和通用接口说明,在课堂上为学生演示实际问题解决过程,在课程作业布置上有意识的选择特定领域得真实问题并要求学生应用WEKA和所学知识解决这些问题,在课程设计上鼓励学生以WEKA提供的通用接口实现新算法和改进现有算法并集成到它的环境中。通过这些教学步骤,让学生循序渐进的做到了解机器学习方法,掌握典型算法,利用机器学习方法解决问题,提出、实现新的机器学习方法,并最终实现机器学习教学的两个目标。
参考文献:
[1] I. Witten, E. Frank. WEKA Machine Learning Algorithms in Java[D]. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations, Morgan Kaufmann Publishers, 2000.
[2] J. Pomerantz. A Linguistic Analysis of Question Taxonomies[J]. Journal of the American Society for Information Science and Technology, 2005,56(7).
[3] C. Zhalaing, P. L. Khanh, M. Ashesh, et al. Feature Extraction for Learning to Classify Questions[J]. AI 2004, 2004, LNAI 3339.
